
ipex-llm-tutorial
Accelerate LLM with low-bit (FP4 / INT4 / FP8 / INT8) optimizations using ipex-llm
Stars: 117
IPEX-LLM is a low-bit LLM library on Intel XPU (Xeon/Core/Flex/Arc/PVC) that provides tutorials to help users understand and use the library to build LLM applications. The tutorials cover topics such as introduction to IPEX-LLM, environment setup, basic application development, Chinese language support, intermediate and advanced application development, GPU acceleration, and finetuning. Users can learn how to build chat applications, chatbots, speech recognition, and more using IPEX-LLM.
README:
English | 中文
IPEX-LLM is a low-bit LLM library on Intel XPU (Xeon/Core/Flex/Arc/PVC). This repository contains tutorials to help you understand what is IPEX-LLM and how to use IPEX-LLM to build LLM applications.
The tutorials are organized as follows:
-
Chapter 1
Introductionintroduces what is IPEX-LLM and what you can do with it. -
Chapter 2
Environment Setupprovides a set of best practices for setting-up your environment. -
Chapter 3
Application Development: Basicsintroduces the basic usage of IPEX-LLM and how to build a very simple Chat application. -
Chapter 4
Chinese Supportshows the usage of some LLMs which suppports Chinese input/output, e.g. ChatGLM2, Baichuan -
Chapter 5
Application Development: Intermediateintroduces intermediate-level knowledge for application development using IPEX-LLM, e.g. How to build a more sophisticated Chatbot, Speech recoginition, etc. -
Chapter 6
GPU Accelerationintroduces how to use Intel GPU to accelerate LLMs using IPEX-LLM. -
Chapter 7
Finetuneintroduces how to do Finetune using IPEX-LLM. -
Chapter 8
Application Development: Advancedintroduces advanced-level knowledge for application development using IPEX-LLM, e.g. langchain usage.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ipex-llm-tutorial
Similar Open Source Tools
ipex-llm-tutorial
IPEX-LLM is a low-bit LLM library on Intel XPU (Xeon/Core/Flex/Arc/PVC) that provides tutorials to help users understand and use the library to build LLM applications. The tutorials cover topics such as introduction to IPEX-LLM, environment setup, basic application development, Chinese language support, intermediate and advanced application development, GPU acceleration, and finetuning. Users can learn how to build chat applications, chatbots, speech recognition, and more using IPEX-LLM.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
LLM-Zero-to-Hundred
LLM-Zero-to-Hundred is a repository showcasing various applications of LLM chatbots and providing insights into training and fine-tuning Language Models. It includes projects like WebGPT, RAG-GPT, WebRAGQuery, LLM Full Finetuning, RAG-Master LLamaindex vs Langchain, open-source-RAG-GEMMA, and HUMAIN: Advanced Multimodal, Multitask Chatbot. The projects cover features like ChatGPT-like interaction, RAG capabilities, image generation and understanding, DuckDuckGo integration, summarization, text and voice interaction, and memory access. Tutorials include LLM Function Calling and Visualizing Text Vectorization. The projects have a general structure with folders for README, HELPER, .env, configs, data, src, images, and utils.
Genesis
Genesis is a physics platform designed for general purpose Robotics/Embodied AI/Physical AI applications. It includes a universal physics engine, a lightweight, ultra-fast, pythonic, and user-friendly robotics simulation platform, a powerful and fast photo-realistic rendering system, and a generative data engine that transforms user-prompted natural language description into various modalities of data. It aims to lower the barrier to using physics simulations, unify state-of-the-art physics solvers, and minimize human effort in collecting and generating data for robotics and other domains.
trulens
TruLens provides a set of tools for developing and monitoring neural nets, including large language models. This includes both tools for evaluation of LLMs and LLM-based applications with _TruLens-Eval_ and deep learning explainability with _TruLens-Explain_. _TruLens-Eval_ and _TruLens-Explain_ are housed in separate packages and can be used independently.
LLM-Planner
LLM-Planner is a tool for few-shot grounded planning for embodied agents using large language models. It includes a high-level prompt generator and kNN dataset, allowing users to generate high-level plans for tasks by bringing their low-level controller and an LLM. The tool has been used in various research projects and provides implementation examples from different conferences. Users can cite the tool using the provided information and the tool is available under the MIT License. For questions or issues, users can contact Luke Song.
MaxKB
MaxKB is a knowledge base Q&A system based on the LLM large language model. MaxKB = Max Knowledge Base, which aims to become the most powerful brain of the enterprise.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.

OmAgent
OmAgent is an open-source agent framework designed to streamline the development of on-device multimodal agents. It enables agents to empower various hardware devices, integrates speed-optimized SOTA multimodal models, provides SOTA multimodal agent algorithms, and focuses on optimizing the end-to-end computing pipeline for real-time user interaction experience. Key features include easy connection to diverse devices, scalability, flexibility, and workflow orchestration. The architecture emphasizes graph-based workflow orchestration, native multimodality, and device-centricity, allowing developers to create bespoke intelligent agent programs.
simple-llm-eval
Simpleval is a Python package for evaluating Large Language Models (LLMs) using the 'LLM as a Judge' technique. It supports various LLM providers such as OpenAI, Google, AWS, Anthropic, Azure, and more. The package includes reports for analyzing and summarizing evaluation results.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking
For similar tasks
ipex-llm-tutorial
IPEX-LLM is a low-bit LLM library on Intel XPU (Xeon/Core/Flex/Arc/PVC) that provides tutorials to help users understand and use the library to build LLM applications. The tutorials cover topics such as introduction to IPEX-LLM, environment setup, basic application development, Chinese language support, intermediate and advanced application development, GPU acceleration, and finetuning. Users can learn how to build chat applications, chatbots, speech recognition, and more using IPEX-LLM.

OpenAI
OpenAI is a Swift community-maintained implementation over OpenAI public API. It is a non-profit artificial intelligence research organization founded in San Francisco, California in 2015. OpenAI's mission is to ensure safe and responsible use of AI for civic good, economic growth, and other public benefits. The repository provides functionalities for text completions, chats, image generation, audio processing, edits, embeddings, models, moderations, utilities, and Combine extensions.
PhiCookBook
Phi Cookbook is a repository containing hands-on examples with Microsoft's Phi models, which are a series of open source AI models developed by Microsoft. Phi is currently the most powerful and cost-effective small language model with benchmarks in various scenarios like multi-language, reasoning, text/chat generation, coding, images, audio, and more. Users can deploy Phi to the cloud or edge devices to build generative AI applications with limited computing power.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.
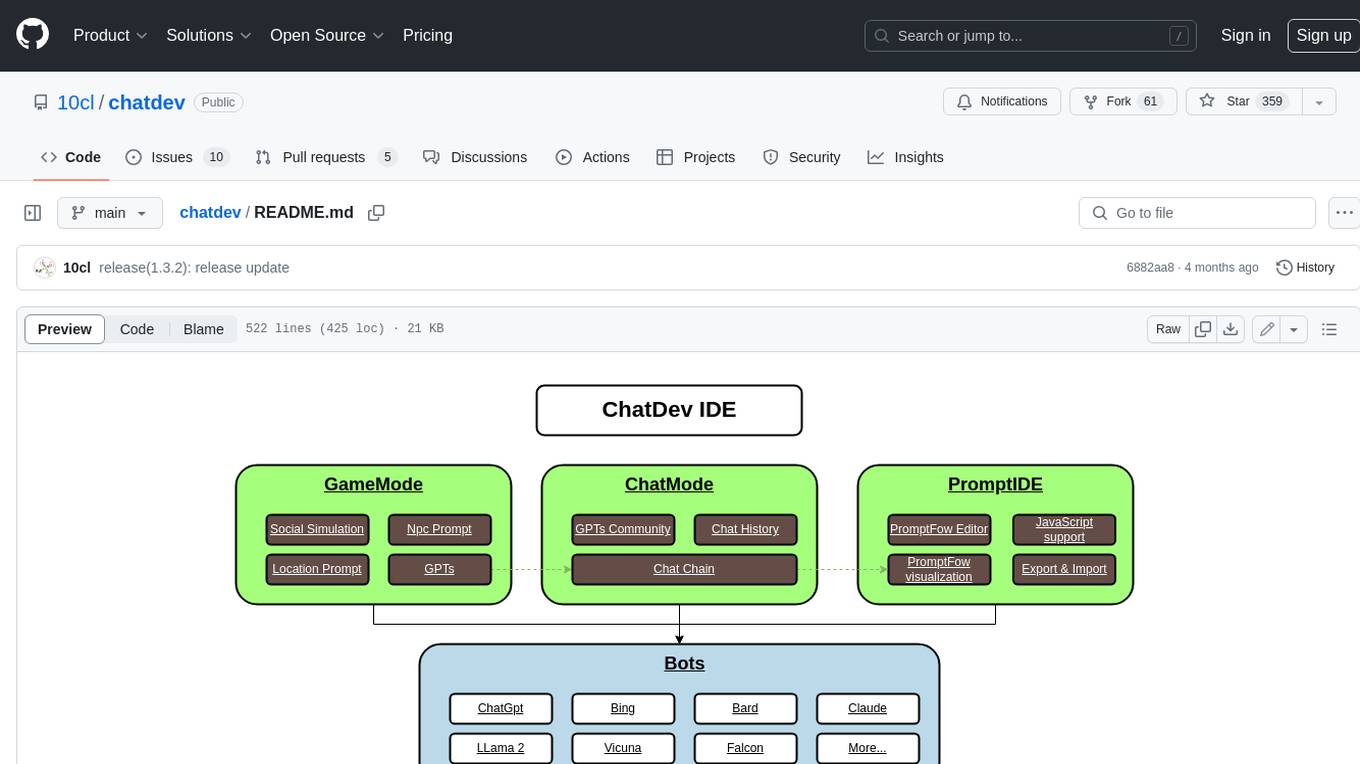
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.
chatgpt-api
Chat Worm is a ChatGPT client that provides access to the API for generating text using OpenAI's GPT models. It works as a single-page application directly communicating with the API, allowing users to interact with the latest GPT-4 model if they have access. The project includes web, Android, and Windows apps for easy access. Users can set up local development, contribute improvements via pull requests, report bugs or request features on GitHub, deploy to production servers, and release on different app stores. The project is licensed under the MIT License.
llms-interview-questions
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.
JamAIBase
JamAI Base is an open-source platform integrating SQLite and LanceDB databases with managed memory and RAG capabilities. It offers built-in LLM, vector embeddings, and reranker orchestration accessible through a spreadsheet-like UI and REST API. Users can transform static tables into dynamic entities, facilitate real-time interactions, manage structured data, and simplify chatbot development. The tool focuses on ease of use, scalability, flexibility, declarative paradigm, and innovative RAG techniques, making complex data operations accessible to users with varying technical expertise.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.
Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.