
JetStream
JetStream is a throughput and memory optimized engine for LLM inference on XLA devices, starting with TPUs (and GPUs in future -- PRs welcome).
Stars: 174
JetStream is a throughput and memory optimized engine for LLM inference on XLA devices, starting with TPUs (and GPUs in future -- PRs welcome). It is designed to provide high performance and scalability for large language models, enabling efficient inference on cloud-based TPUs. JetStream leverages XLA to optimize the execution of LLM models, resulting in faster and more efficient inference. Additionally, JetStream supports quantization techniques to further enhance performance and reduce memory consumption. By utilizing JetStream, developers can deploy and run LLM models on TPUs with ease, achieving optimal performance and cost-effectiveness.
README:
![]()

JetStream is a throughput and memory optimized engine for LLM inference on XLA devices, starting with TPUs (and GPUs in future -- PRs welcome).
Currently, there are two reference engine implementations available -- one for Jax models and another for Pytorch models.
- Git: https://github.com/google/maxtext
- README: https://github.com/google/JetStream/blob/main/docs/online-inference-with-maxtext-engine.md
- Git: https://github.com/google/jetstream-pytorch
- README: https://github.com/google/jetstream-pytorch/blob/main/README.md
- Online Inference with MaxText on v5e Cloud TPU VM [README]
- Online Inference with Pytorch on v5e Cloud TPU VM [README]
- Serve Gemma using TPUs on GKE with JetStream
- Benchmark JetStream Server
- Observability in JetStream Server
- Profiling in JetStream Server
- JetStream Standalone Local Setup
make update-and-install-deps
Use the following commands to run a server locally:
# Start a server
python -m jetstream.core.implementations.mock.server
# Test local mock server
python -m jetstream.tools.requester
# Load test local mock server
python -m jetstream.tools.load_tester
# Test JetStream core orchestrator
python -m unittest -v jetstream.tests.core.test_orchestrator
# Test JetStream core server library
python -m unittest -v jetstream.tests.core.test_server
# Test mock JetStream engine implementation
python -m unittest -v jetstream.tests.engine.test_mock_engine
# Test mock JetStream token utils
python -m unittest -v jetstream.tests.engine.test_token_utils
python -m unittest -v jetstream.tests.engine.test_utils
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for JetStream
Similar Open Source Tools
JetStream
JetStream is a throughput and memory optimized engine for LLM inference on XLA devices, starting with TPUs (and GPUs in future -- PRs welcome). It is designed to provide high performance and scalability for large language models, enabling efficient inference on cloud-based TPUs. JetStream leverages XLA to optimize the execution of LLM models, resulting in faster and more efficient inference. Additionally, JetStream supports quantization techniques to further enhance performance and reduce memory consumption. By utilizing JetStream, developers can deploy and run LLM models on TPUs with ease, achieving optimal performance and cost-effectiveness.
JetStream
JetStream is a throughput and memory optimized engine for Large Language Model (LLM) inference on XLA devices, specifically TPUs. It provides reference engine implementations for Jax and Pytorch models, along with documentation for online inference, serving Gemma using TPUs on GKE, benchmarking, observability, profiling, and standalone local setup. Users can easily set up a local server, run tests, and test core modules. JetStream aims to enhance the performance of LLM inference on XLA devices.
langport
LangPort is an open-source platform for serving large language models. It aims to provide a super fast LLM inference service with core features including Huggingface transformers support, distributed serving system, streaming generation, batch inference, and support for various model architectures. It offers compatibility with OpenAI, FauxPilot, HuggingFace, and Tabby APIs. The project supports model architectures like LLaMa, GLM, GPT2, and GPT Neo, and has been tested with models such as NingYu, Vicuna, ChatGLM, and WizardLM. LangPort also provides features like dynamic batch inference, int4 quantization, and generation logprobs parameter.
genassist
GenAssist is an AI-powered platform for managing and leveraging various AI workflows, focusing on conversation management, analytics, and agent-based interactions. It provides user management, AI agents configuration, knowledge base management, analytics, conversation management, and audit logging features. The platform is built with React, TypeScript, Vite, Tailwind CSS, FastAPI, SQLAlchemy ORM, and PostgreSQL database. GenAssist offers integration options for React, JavaScript Widget, and iOS, along with UI test automation and backend testing capabilities.
gateway
CentralMind Gateway is an AI-first data gateway that securely connects any data source and automatically generates secure, LLM-optimized APIs. It filters out sensitive data, adds traceability, and optimizes for AI workloads. Suitable for companies deploying AI agents for customer support and analytics.
ai-optimizer
The Oracle AI Optimizer and Toolkit provides a streamlined environment for developers and data scientists to explore Generative Artificial Intelligence (GenAI) and Retrieval-Augmented Generation (RAG) capabilities. It integrates Oracle Database 23ai AI VectorSearch and SelectAI to enhance Large Language Models (LLMs) through RAG.
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.
BodhiApp
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.
AIQC
AIQC is an open source Python package that provides a declarative API for end-to-end MLOps in order to make deep learning more accessible to researchers. It utilizes a SQLite object-relational model for machine learning objects and stacks standardized workflows for various analyses, data types, and libraries. The benefits include a 90% reduction in data wrangling, reproducibility, and no need to install and maintain application and database servers for experiment tracking. AIQC is pip-installable and provides a Dash-Plotly UI for real-time experiment tracking.
mlir-aie
This repository contains an MLIR-based toolchain for AI Engine-enabled devices, such as AMD Ryzen™ AI and Versal™. This repository can be used to generate low-level configurations for the AI Engine portion of these devices. AI Engines are organized as a spatial array of tiles, where each tile contains AI Engine cores and/or memories. The spatial array is connected by stream switches that can be configured to route data between AI Engine tiles scheduled by their programmable Data Movement Accelerators (DMAs). This repository contains MLIR representations, with multiple levels of abstraction, to target AI Engine devices. This enables compilers and developers to program AI Engine cores, as well as describe data movements and array connectivity. A Python API is made available as a convenient interface for generating MLIR design descriptions. Backend code generation is also included, targeting the aie-rt library. This toolchain uses the AI Engine compiler tool which is part of the AMD Vitis™ software installation: these tools require a free license for use from the Product Licensing Site.

mcpm.sh
MCPM is an open source CLI tool for managing MCP servers, providing a simplified global configuration approach to install servers once, organize them with profiles, and integrate them into any MCP client. Features include server discovery, direct execution, sharing capabilities, and client integration tools. It eliminates the complexity of v1's target-based system in favor of a clean global workspace model. The tool is designed to be AI agent friendly with comprehensive automation support and a rich CLI interface.
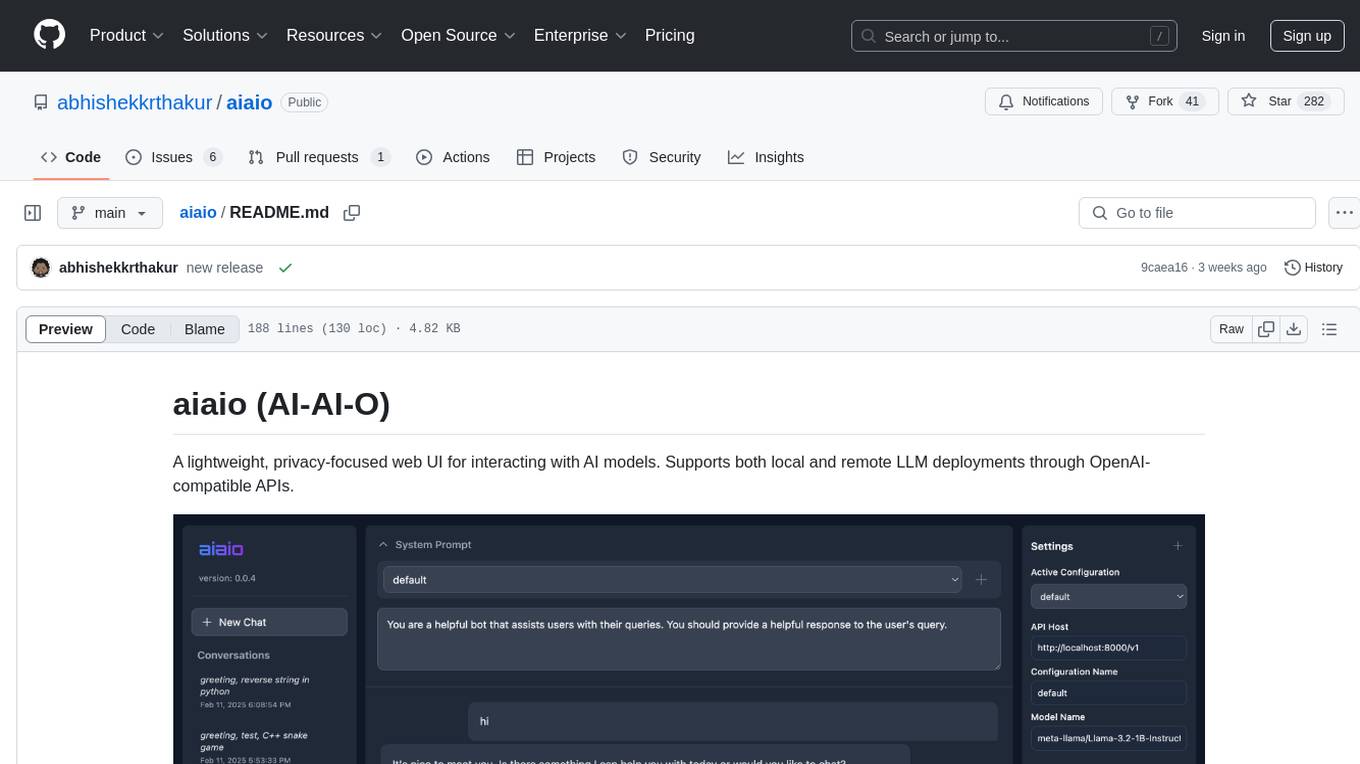
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
NotHotDog
NotHotDog is an open-source platform for testing, evaluating, and simulating AI agents. It offers a robust framework for generating test cases, running conversational scenarios, and analyzing agent performance.
fastapi-langgraph-agent-production-ready-template
A production-ready FastAPI template for building AI agent applications with LangGraph integration. This template provides a robust foundation for building scalable, secure, and maintainable AI agent services. It includes features like FastAPI for high-performance async API endpoints, LangGraph integration, structured logging, rate limiting, PostgreSQL for data persistence, Docker support, security measures like JWT-based authentication and input sanitization, developer-friendly features like environment-specific configuration and type hints, a model evaluation framework with automated metric-based evaluation and detailed JSON reports, and a configuration system with environment-specific settings.
morphic
Morphic is an AI-powered answer engine with a generative UI. It utilizes a stack of Next.js, Vercel AI SDK, OpenAI, Tavily AI, shadcn/ui, Radix UI, and Tailwind CSS. To get started, fork and clone the repo, install dependencies, fill out secrets in the .env.local file, and run the app locally using 'bun dev'. You can also deploy your own live version of Morphic with Vercel. Verified models that can be specified to writers include Groq, LLaMA3 8b, and LLaMA3 70b.
supavec
Supavec is an open-source tool that serves as an alternative to Carbon.ai. It allows users to build powerful RAG applications using any data source and at any scale. The tool is designed to provide a simple API endpoint for easy integration and usage. Supavec is built with Next.js, Supabase, Tailwind CSS, Bun, and Upstash, offering a robust and flexible solution for application development. Users can refer to the API documentation for detailed information on how to utilize the tool effectively.
For similar tasks

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

NeMo
NeMo Framework is a generative AI framework built for researchers and pytorch developers working on large language models (LLMs), multimodal models (MM), automatic speech recognition (ASR), and text-to-speech synthesis (TTS). The primary objective of NeMo is to provide a scalable framework for researchers and developers from industry and academia to more easily implement and design new generative AI models by being able to leverage existing code and pretrained models.
E2B
E2B Sandbox is a secure sandboxed cloud environment made for AI agents and AI apps. Sandboxes allow AI agents and apps to have long running cloud secure environments. In these environments, large language models can use the same tools as humans do. For example: * Cloud browsers * GitHub repositories and CLIs * Coding tools like linters, autocomplete, "go-to defintion" * Running LLM generated code * Audio & video editing The E2B sandbox can be connected to any LLM and any AI agent or app.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.
griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.