
text-generation-webui-telegram_bot
LLM telegram bot
Stars: 111
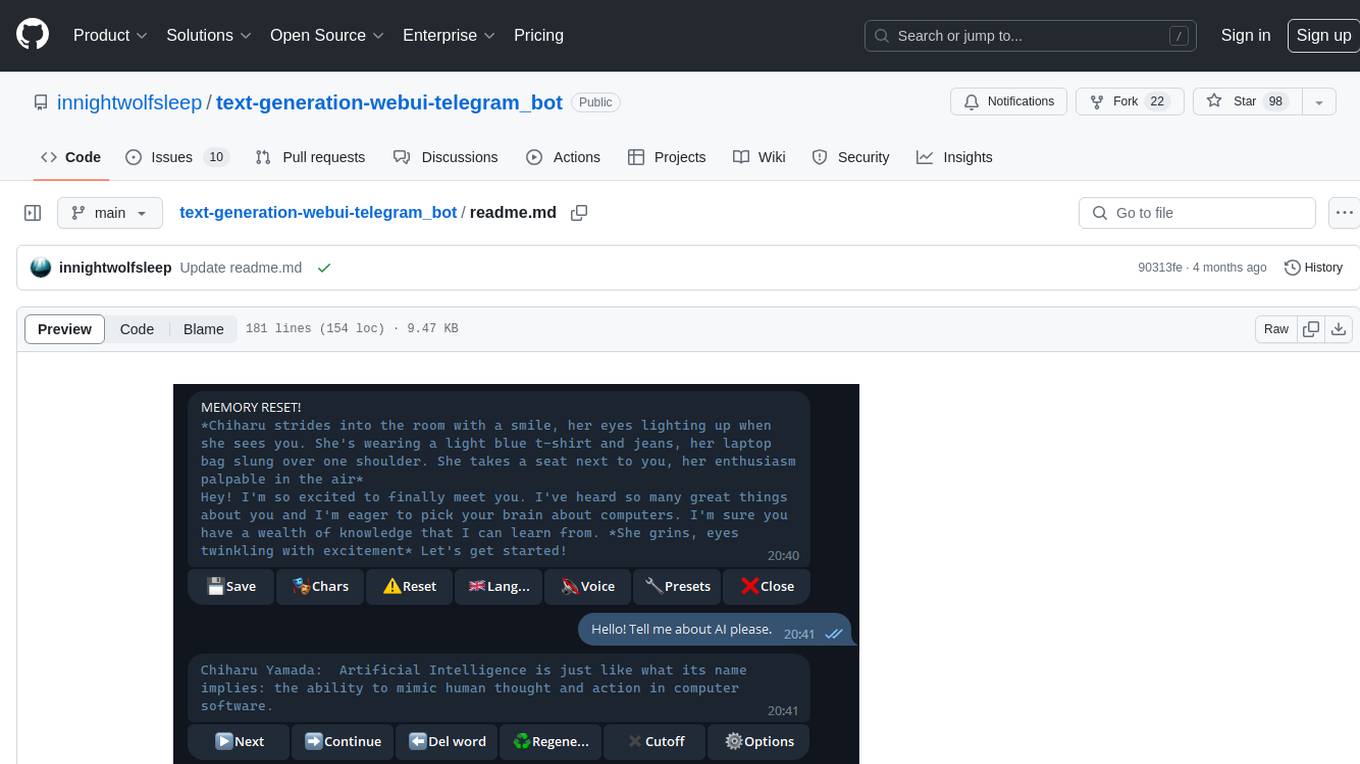
The text-generation-webui-telegram_bot is a wrapper and extension for llama.cpp, exllama, or transformers, providing additional functionality for the oobabooga/text-generation-webui tool. It enhances Telegram chat with features like buttons, prefixes, and voice/image generation. Users can easily install and run the tool as a standalone app or in extension mode, enabling seamless integration with the text-generation-webui tool. The tool offers various features such as chat templates, session history, character loading, model switching during conversation, voice generation, auto-translate, and more. It supports different bot modes for personalized interactions and includes configurations for running in different environments like Google Colab. Additionally, users can customize settings, manage permissions, and utilize various prefixes to enhance the chat experience.
README:
-
wrAPPer for llama.cpp(default), exllama or transformers.
-
wrAPPer for ollama (config example - config/ollama_config.json)
-
an EXTension for oobabooga/text-generation-webui.s
Provide telegram chat with various additional functional like buttons, prefixes, voice/image generation.
HOW TO INSTALL (standalone app):
- clone this repo
git clone https://github.com/innightwolfsleep/text-generation-webui-telegram_bot - install requirements.
pip install -r text-generation-webui-telegram_bot\requirements_app.txt
HOW TO RUN (standalone app):
- get bot token from https://t.me/BotFather
- add bot token to environment (look
.env.example) OR fileconfigs\telegram_token.txt - move your model file to
models\ - set model_path to your model in
configs\app_config.json - start
run.cmd(windows) orrun.sh(linux)
(optional) to use exllama:
git clone https://github.com/turboderp/exllama source\generators\exllama
pip install -r source\generators\exllama\requirements.txt
(optional) to use exllamav2:
git clone https://github.com/turboderp/exllamav2 source\generators\exllamav2
cd source\generators\exllamav2
python setup.py install --user
(optional) to use llama.cpp with GPU acceleration reinstall abetlen/llama-cpp-python by guide: llama-cpp-python#installation-with-hardware-acceleration or this guide for windows
HOW TO INSTALL (extension mode):
- obviously, install oobabooga/text-generation-webui first, add model, set all options you need
- run
cmd_windows.batorcmd_linux.shto enable venv - clone this repo to "text-generation-webui\extensions"
git clone https://github.com/innightwolfsleep/text-generation-webui-telegram_bot extensions\telegram_bot - install requirements
pip install -r extensions\telegram_bot\requirements_ext.txt
HOW TO USE (extension mode):
- get bot token from https://t.me/BotFather
- add your bot token in
extensions\telegram_bot\configs\telegram_token.txtfile or oobabooga environment - add flags to CMD_FLAGS.txt
--api --extension telegram_bot - run appropriate start_OS script. (direct integration is not available now)
HOW TO INSTALL/USE (google collab):
- run notebook at manuals/llm_telegram_bot_cublas.ipynb
- install, set bot token, run
(optional) if you are facing internet issue, change proxy_url at app_config.json into your own proxy. For example: https://127.0.0.1:10808
FEATURES:
- chat templates (see [manuals/custom_prompt_templates.md])
- chat and notebook modes
- session for all users are separative (by chat_id)
- local session history - conversation won't be lost if server restarts. Separated history between users and chars.
- nice "X typing" during generating (users will not think that bot stuck)
- buttons: impersonate, continue previous message, regenerate last message, remove last messages from history, reset history button, new char loading menu
- you can load new characters from text-generation-webui\characters with button
- you can load new model during conversation with button
- "+" or "#" user message prefix for impersonate: "#Chiharu sister" or "+Castle guard". Or even ask bot generate your own message "+You"
- "-" or "!" prefix to replace last bot message
- "++" prefix replace bot name during chat (switch conversation to another character)
- "--" prefix replace you name during chat
- "==" prefix to add message to context
- "📷" prefix to make photo via SD api. Write like "📷Chiharu Yamada", not single "📷". Need to run (StableDiffusion) with --api key first.
- save/load history in chat by downloading/forwarding to chat .json file
- integrated auto-translate (you can set model/user language parameter)
- receiving text files (code, text, etc)
- voice generating (silero), en and ru variants
- translation_as_hidden_text option in .cfg - if you want to learn english with bot
- telegram_users.txt - list of permitted users (if empty - permit for all)
- antiflood - one message per 15 sec from one user
- improved group chatting mode
CONFIGURATION:
app_config.json - config for running as standalone app (run.sh or run.cmd)
ext_config.json - config for running as extension for oobabooga/text-generation-webui
x_config.json
bot_mode=admin
specific bot mode. admin for personal use
- admin - bot answer for everyone in chat-like mode. All buttons, include settings-for-all are avariable for everyone. (Default)
- chat - bot answer for everyone in chat-like mode. All buttons, exclude settings-for-all are avariable for everyone. (Recommended for chatting)
- chat-restricted - same as chat, but user can't change default character
- persona - same as chat-restricted, but reset/regenerate/delete message are unavailable too.
- notebook - notebook-like mode. Prefixes wont added automaticaly, only "\n" separate user and bot messages. Restriction like chat mode.
- query - same as notebook, but without history. Each question for bot is like new convrsation withot influence of previous questions
user_name_template=
user name template, useful for group chat.
if empty bot always get default name of user - You. By default even in group chats bot perceive all users as single entity "You"
but it is possible force bot to perceive telegram users names with templates:
FIRSTNAME - user first name (Jon)
LASTNAME - user last name (Dow)
USERNAME - user nickname (superguy)
ID - user Id (999999999)
so, user_name_template="USERNAME FIRSTNAME ID" translatede to user name "superguy Jon 999999999"
but if you planed to use template and group chat - you shold add "\n" sign to stopping_strings to prevent bot impersonating!!!
generator_script=GeneratorLlamaCpp
name of generator script (generators folder):
- generator_exllama - based on llama-cpp-python, recommended
- generator_llama_cpp - based on llama-cpp-python, recommended
- generator_langchain_llama_cpp - based in langchain+llama
- generator_transformers - based on transformers, untested
- generator_text_generator_webui_openapi - use oobabooga/text-generation-webui OpenAPI extension
- (BROKEN) generator_text_generator_webui - module to integrate in oobabooga/text-generation-webui (curently broken:( )
- (OUTDATED) generator_text_generator_webui_api - use oobabooga/text-generation-webui API (old api version)
model_path=models\llama-13b.ggml.q4_0.gguf
path to model file or directory
characters_dir_path=characters
default_char=Example.yaml
default cahracter and path to cahracters folder
presets_dir_path=presets
default_preset=Shortwave.yaml
default generation preset and path to preset folder
model_lang=en
user_lang=en
default model and user language. User language can be switched by users, individualy.
html_tag_open=<pre>
html_tag_close=</pre>
tags for bot answers in tg. By default - preformatted text (pre)
history_dir_path=history
directory for users history
token_file_path=configs\\telegram_token.txt
bot token. Ask https://t.me/BotFather
admins_file_path=configs\\telegram_admins.txt
users whos id's in admins_file switched to admin mode and can choose settings-for-all (generating settings and model)
users_file_path=configs\\telegram_users.txt
if just one id in users_file - bot will ignore all users except this id (id's). Even admin will be ignored
generator_params_file_path=configs\\telegram_generator_params.json
default text generation params, overwrites by choosen preset
user_rules_file_path=configs\\telegram_user_rules.json
user rules matrix
telegram_sd_config=configs\\telegram_sd_config.json
stable diffusion api config
stopping_strings=<END>,<START>,end{code}
generating settings - which text pattern stopping text generating? Add "\n" if bot sent too much text.
eos_token=None
generating settings
translation_as_hidden_text=on
if "on" and model/user lang not the same - translation will be writed under spoiler. If "off" - translation without spoiler, no original text in message.
sd_api_url="http://127.0.0.1:7860"
stable diffusion api url, need to use "photo" prefixes
proxy_url
to avoid provider blocking
generator_params.json
config for generator
sd_config.json
config for stable diffusion
telegram_admins.txt
list of users id who forced to admin mode. If telegram_users not empty - must be in telegram_users too!
telegram_users.txt
list og users id (or groups id) who permitted interact with bot. If empty - everyone permitted
telegram_token.txt (you can use .env instead)
telegram bot token
telegram_user_rules.json
buttons visibility config for various bot modes
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for text-generation-webui-telegram_bot
Similar Open Source Tools
text-generation-webui-telegram_bot
The text-generation-webui-telegram_bot is a wrapper and extension for llama.cpp, exllama, or transformers, providing additional functionality for the oobabooga/text-generation-webui tool. It enhances Telegram chat with features like buttons, prefixes, and voice/image generation. Users can easily install and run the tool as a standalone app or in extension mode, enabling seamless integration with the text-generation-webui tool. The tool offers various features such as chat templates, session history, character loading, model switching during conversation, voice generation, auto-translate, and more. It supports different bot modes for personalized interactions and includes configurations for running in different environments like Google Colab. Additionally, users can customize settings, manage permissions, and utilize various prefixes to enhance the chat experience.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.
OpenAI-sublime-text
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.
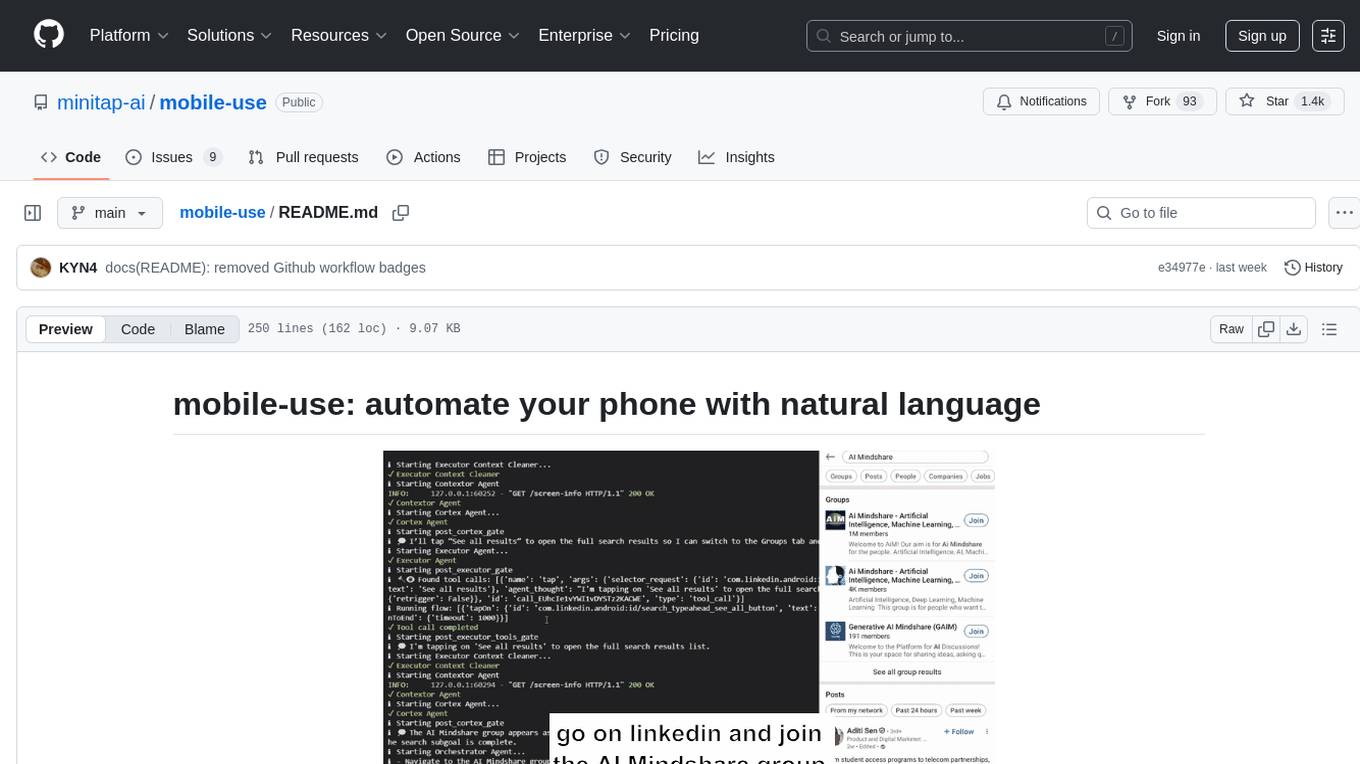
mobile-use
Mobile-use is an open-source AI agent that controls Android or IOS devices using natural language. It understands commands to perform tasks like sending messages and navigating apps. Features include natural language control, UI-aware automation, data scraping, and extensibility. Users can automate their mobile experience by setting up environment variables, customizing LLM configurations, and launching the tool via Docker or manually for development. The tool supports physical Android phones, Android simulators, and iOS simulators. Contributions are welcome, and the project is licensed under MIT.

QodeAssist
QodeAssist is an AI-powered coding assistant plugin for Qt Creator, offering intelligent code completion and suggestions for C++ and QML. It leverages large language models like Ollama to enhance coding productivity with context-aware AI assistance directly in the Qt development environment. The plugin supports multiple LLM providers, extensive model-specific templates, and easy configuration for enhanced coding experience.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.
Loyal-Elephie
Embark on an exciting adventure with Loyal Elephie, your faithful AI sidekick! This project combines the power of a neat Next.js web UI and a mighty Python backend, leveraging the latest advancements in Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) to deliver a seamless and meaningful chatting experience. Features include controllable memory, hybrid search, secure web access, streamlined LLM agent, and optional Markdown editor integration. Loyal Elephie supports both open and proprietary LLMs and embeddings serving as OpenAI compatible APIs.

Stable-Diffusion-Android
Stable Diffusion AI is an easy-to-use app for generating images from text or other images. It allows communication with servers powered by various AI technologies like AI Horde, Hugging Face Inference API, OpenAI, StabilityAI, and LocalDiffusion. The app supports Txt2Img and Img2Img modes, positive and negative prompts, dynamic size and sampling methods, unique seed input, and batch image generation. Users can also inpaint images, select faces from gallery or camera, and export images. The app offers settings for server URL, SD Model selection, auto-saving images, and clearing cache.

refact-lsp
Refact Agent is a small executable written in Rust as part of the Refact Agent project. It lives inside your IDE to keep AST and VecDB indexes up to date, supporting connection graphs between definitions and usages in popular programming languages. It functions as an LSP server, offering code completion, chat functionality, and integration with various tools like browsers, databases, and debuggers. Users can interact with it through a Text UI in the command line.
parllama
PAR LLAMA is a Text UI application for managing and using LLMs, designed with Textual and Rich and PAR AI Core. It runs on major OS's including Windows, Windows WSL, Mac, and Linux. Supports Dark and Light mode, custom themes, and various workflows like Ollama chat, image chat, and OpenAI provider chat. Offers features like custom prompts, themes, environment variables configuration, and remote instance connection. Suitable for managing and using LLMs efficiently.
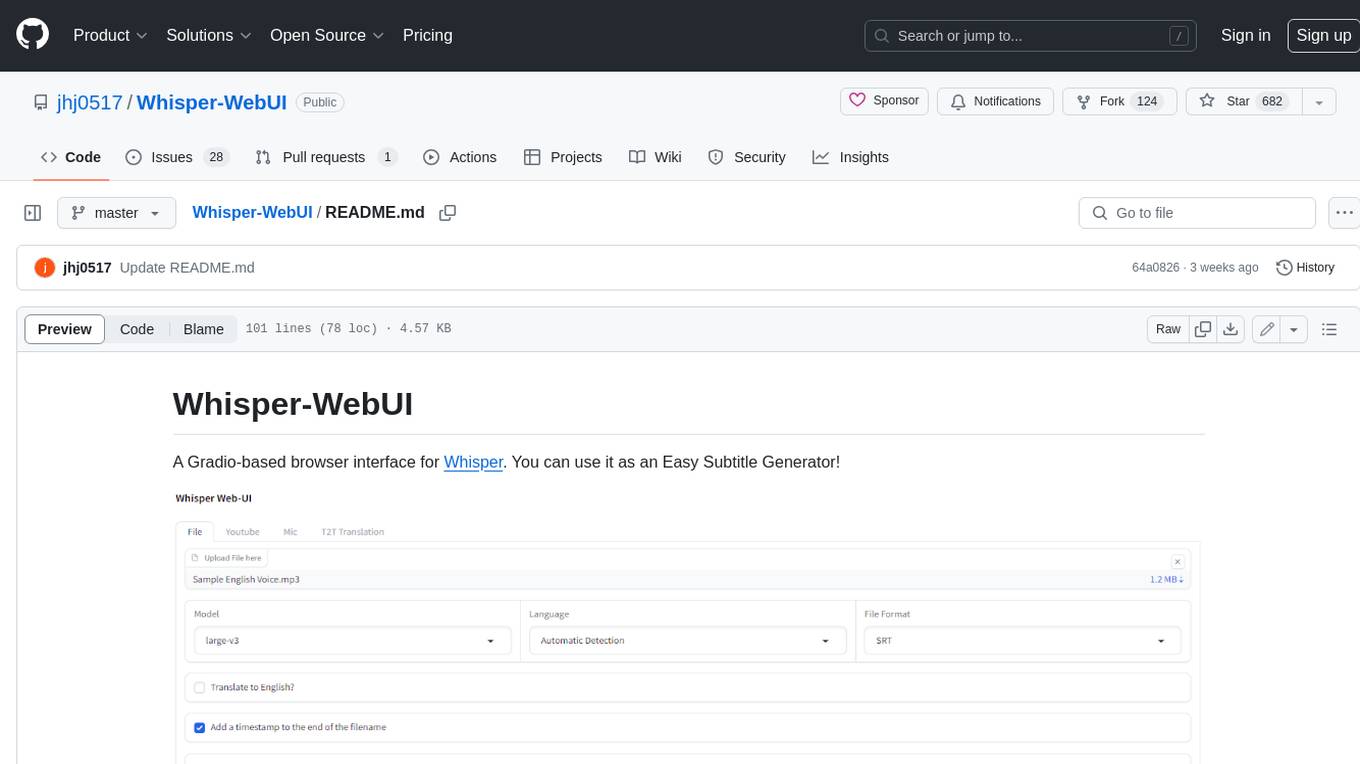
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.
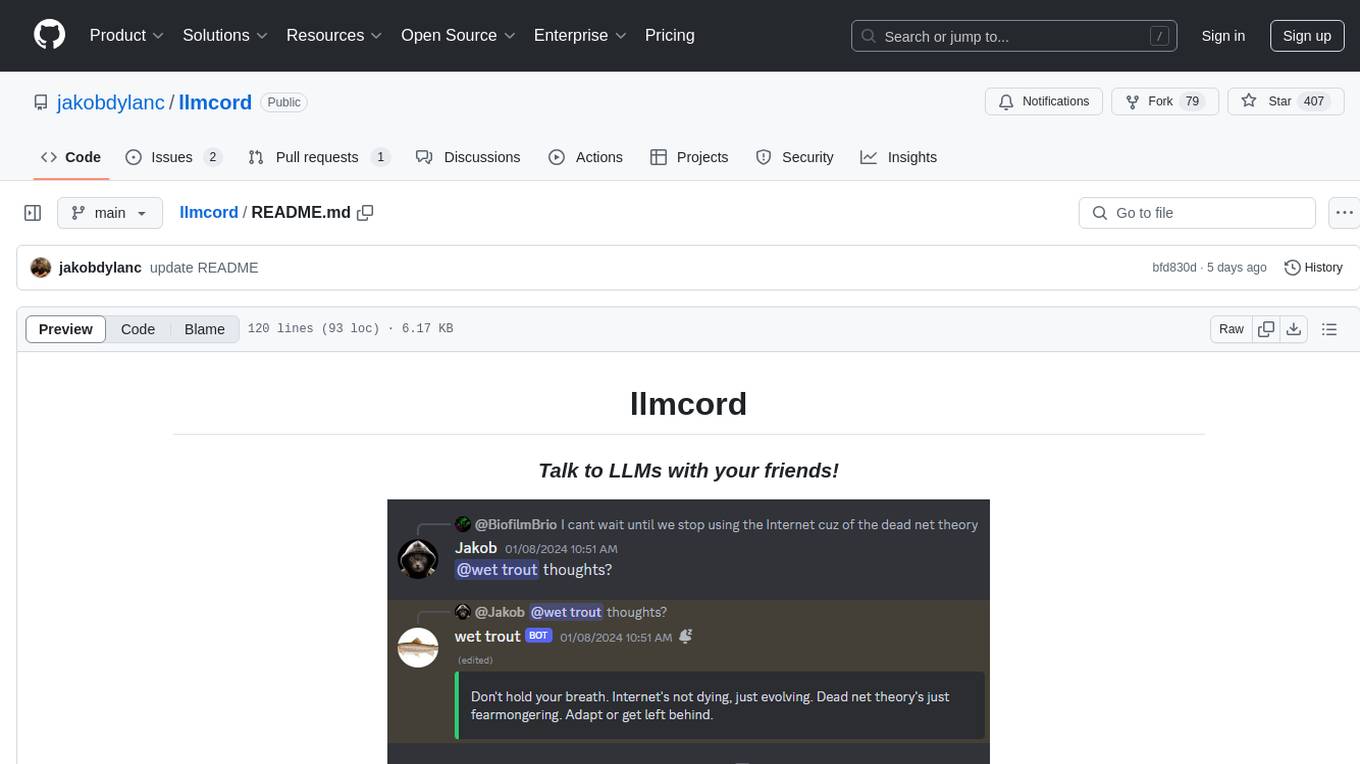
llmcord
llmcord is a Discord bot that transforms Discord into a collaborative LLM frontend, allowing users to interact with various LLM models. It features a reply-based chat system that enables branching conversations, supports remote and local LLM models, allows image and text file attachments, offers customizable personality settings, and provides streamed responses. The bot is fully asynchronous, efficient in managing message data, and offers hot reloading config. With just one Python file and around 200 lines of code, llmcord provides a seamless experience for engaging with LLMs on Discord.
aimeos-laravel
Aimeos Laravel is a professional, full-featured, and ultra-fast Laravel ecommerce package that can be easily integrated into existing Laravel applications. It offers a wide range of features including multi-vendor, multi-channel, and multi-warehouse support, fast performance, support for various product types, subscriptions with recurring payments, multiple payment gateways, full RTL support, flexible pricing options, admin backend, REST and GraphQL APIs, modular structure, SEO optimization, multi-language support, AI-based text translation, mobile optimization, and high-quality source code. The package is highly configurable and extensible, making it suitable for e-commerce SaaS solutions, marketplaces, and online shops with millions of vendors.
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.
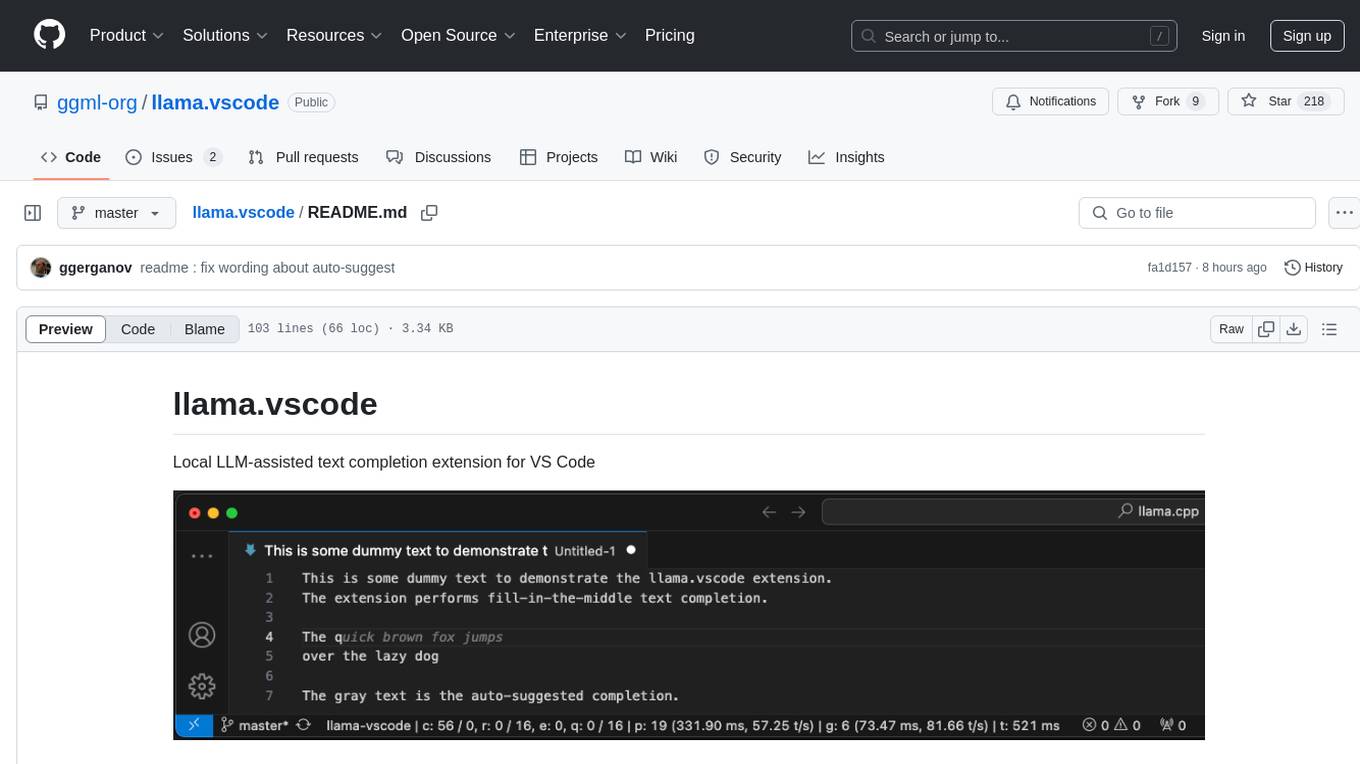
llama.vscode
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.
For similar tasks
LLaMa2lang
This repository contains convenience scripts to finetune LLaMa3-8B (or any other foundation model) for chat towards any language (that isn't English). The rationale behind this is that LLaMa3 is trained on primarily English data and while it works to some extent for other languages, its performance is poor compared to English.
SiriLLama
Siri LLama is an Apple shortcut that allows users to access locally running LLMs through Siri or the shortcut UI on any Apple device connected to the same network as the host machine. It utilizes Langchain and supports open source models from Ollama or Fireworks AI. Users can easily set up and configure the tool to interact with various language models for chat and multimodal tasks. The tool provides a convenient way to leverage the power of language models through Siri or the shortcut interface, enhancing user experience and productivity.
text-generation-webui-telegram_bot
The text-generation-webui-telegram_bot is a wrapper and extension for llama.cpp, exllama, or transformers, providing additional functionality for the oobabooga/text-generation-webui tool. It enhances Telegram chat with features like buttons, prefixes, and voice/image generation. Users can easily install and run the tool as a standalone app or in extension mode, enabling seamless integration with the text-generation-webui tool. The tool offers various features such as chat templates, session history, character loading, model switching during conversation, voice generation, auto-translate, and more. It supports different bot modes for personalized interactions and includes configurations for running in different environments like Google Colab. Additionally, users can customize settings, manage permissions, and utilize various prefixes to enhance the chat experience.
rust-genai
genai is a multi-AI providers library for Rust that aims to provide a common and ergonomic single API to various generative AI providers such as OpenAI, Anthropic, Cohere, Ollama, and Gemini. It focuses on standardizing chat completion APIs across major AI services, prioritizing ergonomics and commonality. The library initially focuses on text chat APIs and plans to expand to support images, function calling, and more in the future versions. Version 0.1.x will have breaking changes in patches, while version 0.2.x will follow semver more strictly. genai does not provide a full representation of a given AI provider but aims to simplify the differences at a lower layer for ease of use.
whetstone.chatgpt
Whetstone.ChatGPT is a simple light-weight library that wraps the Open AI API with support for dependency injection. It supports features like GPT 4, GPT 3.5 Turbo, chat completions, audio transcription and translation, vision completions, files, fine tunes, images, embeddings, moderations, and response streaming. The library provides a video walkthrough of a Blazor web app built on it and includes examples such as a command line bot. It offers quickstarts for dependency injection, chat completions, completions, file handling, fine tuning, image generation, and audio transcription.
pg_vectorize
pg_vectorize is a Postgres extension that automates text to embeddings transformation, enabling vector search and LLM applications with minimal function calls. It integrates with popular LLMs, provides workflows for vector search and RAG, and automates Postgres triggers for updating embeddings. The tool is part of the VectorDB Stack on Tembo Cloud, offering high-level APIs for easy initialization and search.
gemini-api-quickstart
This repository contains a simple Python Flask App utilizing the Google AI Gemini API to explore multi-modal capabilities. It provides a basic UI and Flask backend for easy integration and testing. The app allows users to interact with the AI model through chat messages, making it a great starting point for developers interested in AI-powered applications.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.