Best AI tools for< Speech Researcher >
Infographic
20 - AI tool Sites
Moshi AI
Moshi AI by Kyutai is an advanced native speech AI model that enables natural, expressive conversations. It can be installed locally and run offline, making it suitable for integration into smart home appliances and other local applications. The model, named Helium, has 7 billion parameters and is trained on text and audio codecs. Moshi AI supports native speech input and output, allowing for smooth communication with the AI. The application is community-supported, with plans for continuous improvement and adaptation.
SpeechMap.AI
SpeechMap.AI is a public research project that explores the boundaries of AI-generated speech. It focuses on testing how language models respond to sensitive and controversial prompts across different providers, countries, and topics. The platform aims to reveal the invisible boundaries of AI speech by analyzing what models avoid, refuse, or shut down. By measuring and comparing AI models' responses, SpeechMap.AI sheds light on the evolving landscape of AI-generated speech and its impact on public expression.
TranscribeAudio
TranscribeAudio is an AI-powered transcription tool that enables users to convert audio files into text quickly and accurately. It offers features like speaker identification, insights generation, and secure file handling. The tool is user-friendly, with a simple editor for reviewing and refining transcripts. TranscribeAudio provides a subscription-based service with a generous free tier and simple pricing. It is constantly updated with new features to enhance user experience.
Deepgram
Deepgram is a speech recognition and transcription service that uses artificial intelligence to convert audio into text. It is designed to be accurate, fast, and easy to use. Deepgram offers a variety of features, including: - Automatic speech recognition - Speaker diarization - Language identification - Custom acoustic models - Real-time transcription - Batch transcription - Webhooks - Integrations with popular platforms such as Zoom, Google Meet, and Microsoft Teams
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.
Speak4Me
Speak4Me is a text-to-speech application that converts any text file, including PDFs and websites, into audible content. It enables users to listen to their documents or school materials anytime, anywhere. With features like scanning physical or digital text, reading web pages aloud, and a new ChatWithMe function, Speak4Me aims to enhance reading experiences and improve focus for individuals with reading issues. The application is trusted by over 15,000 people on the App Store and offers a free version for schools, making education more accessible for everyone.
Voicetapp
Voicetapp is a powerful cloud-based artificial intelligence software that helps you automatically convert audio to text with up to 100% accuracy. It supports over 170 languages and dialects, allowing you to quickly and accurately transcribe speech from audio and video files. Voicetapp also offers features such as speaker identification, live transcription, and multiple input formats, making it a versatile tool for various use cases.
OneAudio
OneAudio is an AI-powered tool that allows users to summarize, transcribe, and convert audio files into notes. With features like recording, summarization, and language selection, OneAudio helps users organize and transform their ideas efficiently. The tool leverages OpenAI GPT-4 and GPT-4o models to provide accurate transcriptions and summaries. Users can choose from different pricing plans based on their needs, from a free tier to a premium plan with unlimited features. OneAudio is designed to streamline the process of converting audio content into written notes, making it ideal for students, professionals, and anyone looking to enhance their productivity.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
Free Audio to Text Converter
The Free Audio to Text Converter is an AI-powered tool that allows users to quickly and accurately transcribe audio files into text. It supports various audio formats and offers features like multi-speaker identification, multiple export formats, and precise timestamps. The tool is designed to enhance productivity by providing high-quality transcriptions for a wide range of needs, from content creation to academic research and sales analysis. Users can trust the tool's accuracy and efficiency to save time and improve workflow.
Read It
Read It is an AI-powered tool that allows users to convert newsletters and articles into podcasts effortlessly. By utilizing cutting-edge AI text-to-speech technology, users can listen to their favorite written content on the go. The tool provides users with a personal podcast feed URL upon sign-up, enabling them to add articles through email forwarding or using a bookmarklet. With a user-friendly interface and pay-as-you-go model, Read It offers a seamless experience for turning text-based content into audio podcasts.
Alice
Alice is a fast, accurate AI transcription and recorder application that prioritizes privacy and cost-effectiveness. It allows users to securely record audio and video, transcribe in multiple languages and accents with high accuracy, and offers real-time text streaming. Alice integrates with various tools, supports webhooks, and is trusted by journalists for its reliability and security features. The application is designed to be user-friendly, efficient, and suitable for a wide range of tasks, making it a valuable tool for journalists, freelancers, and anyone in need of transcription services.
WavoAI
WavoAI is an AI-powered transcription and summarization tool that helps users transcribe audio recordings quickly and accurately. It offers features such as speaker identification, annotations, and interactive AI insights, making it a valuable tool for a wide range of professionals, including academics, filmmakers, podcasters, and journalists.
Auri
Auri is an AI assistant that offers a range of writing, communication, and productivity tools. It includes an AI-powered keyboard with features like grammar checking, translation, and paraphrasing, as well as an AI chat, voice recorder and transcriber, and smart notes. Auri is available on iPhone, iPad, Mac, and Apple Watch.
Whisper Web
Whisper Web is a free AI speech recognition tool that offers advanced speech recognition powered by machine learning algorithms. Users can transform voice recordings, audio files, and online audio into accurate text transcriptions with complete privacy protection through local processing in the browser. The tool supports multiple input methods, real-time processing, and export options in various formats, making it ideal for journalists, researchers, students, and professionals who require precise voice-to-text conversion.
Rev
Rev is a leading transcription service provider offering human and AI transcription solutions with high accuracy rates. The platform enables users to transcribe audio and video content efficiently, generate captions and subtitles in multiple languages, and access speech-to-text solutions for various industries such as news organizations, market research, video distribution, and legal services. Rev's AI-powered tools enhance content accessibility, global reach, and audience engagement, making it a versatile and reliable platform for transcription needs.
Sonix
Sonix is a powerful and easy-to-use online audio and video transcription service. It uses advanced artificial intelligence (AI) to convert speech to text quickly and accurately. Sonix supports over 38 languages and offers a variety of features, including automatic transcription, translation, subtitling, and summarization. It is a valuable tool for journalists, researchers, students, businesses, and anyone who needs to transcribe audio or video content.
VideoToWords.ai
VideoToWords.ai is an AI-powered transcription tool that converts audio and video files into accurate written text. It utilizes advanced machine learning algorithms to transcribe files quickly and efficiently, catering to a wide range of users such as journalists, students, researchers, podcast hosts, filmmakers, content creators, marketers, and professionals from various industries. The platform supports multiple languages, offers convenient text editing and export options, and ensures data security and privacy for users.
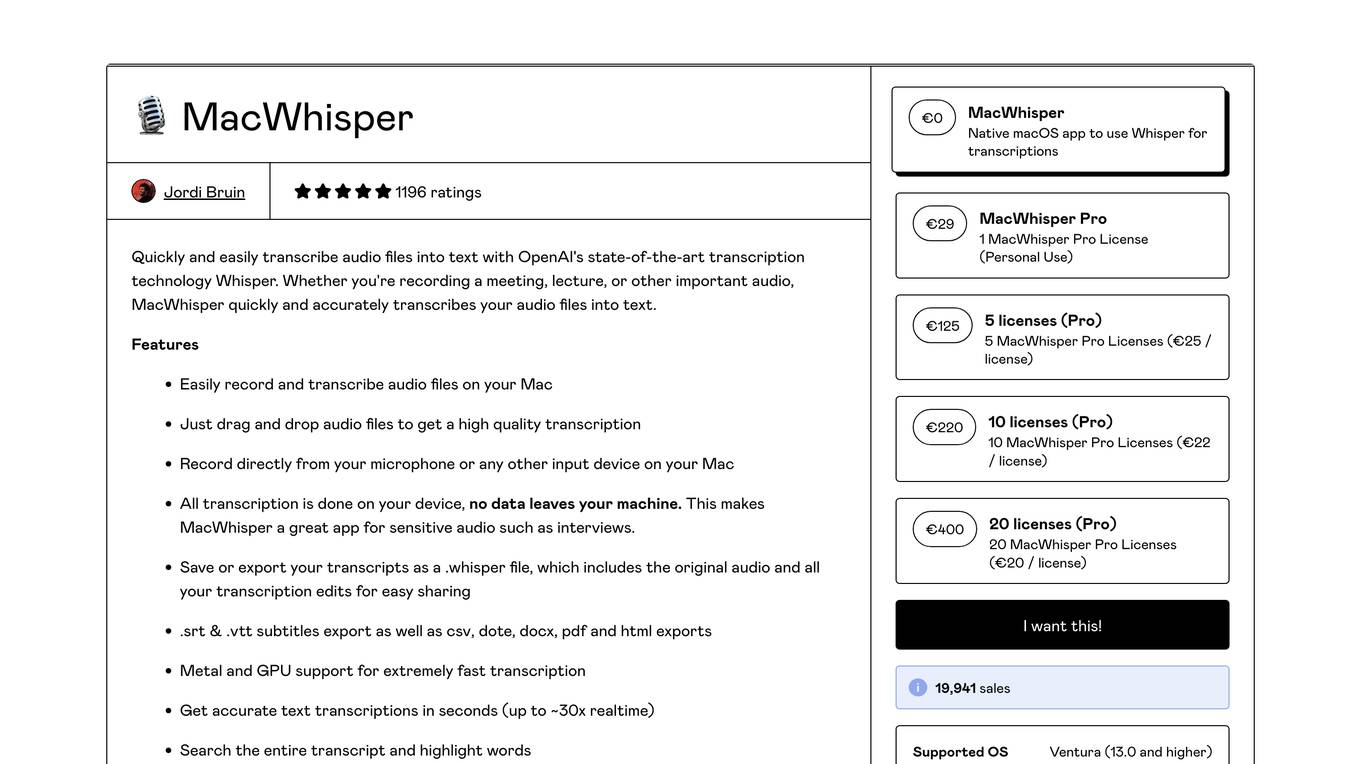
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
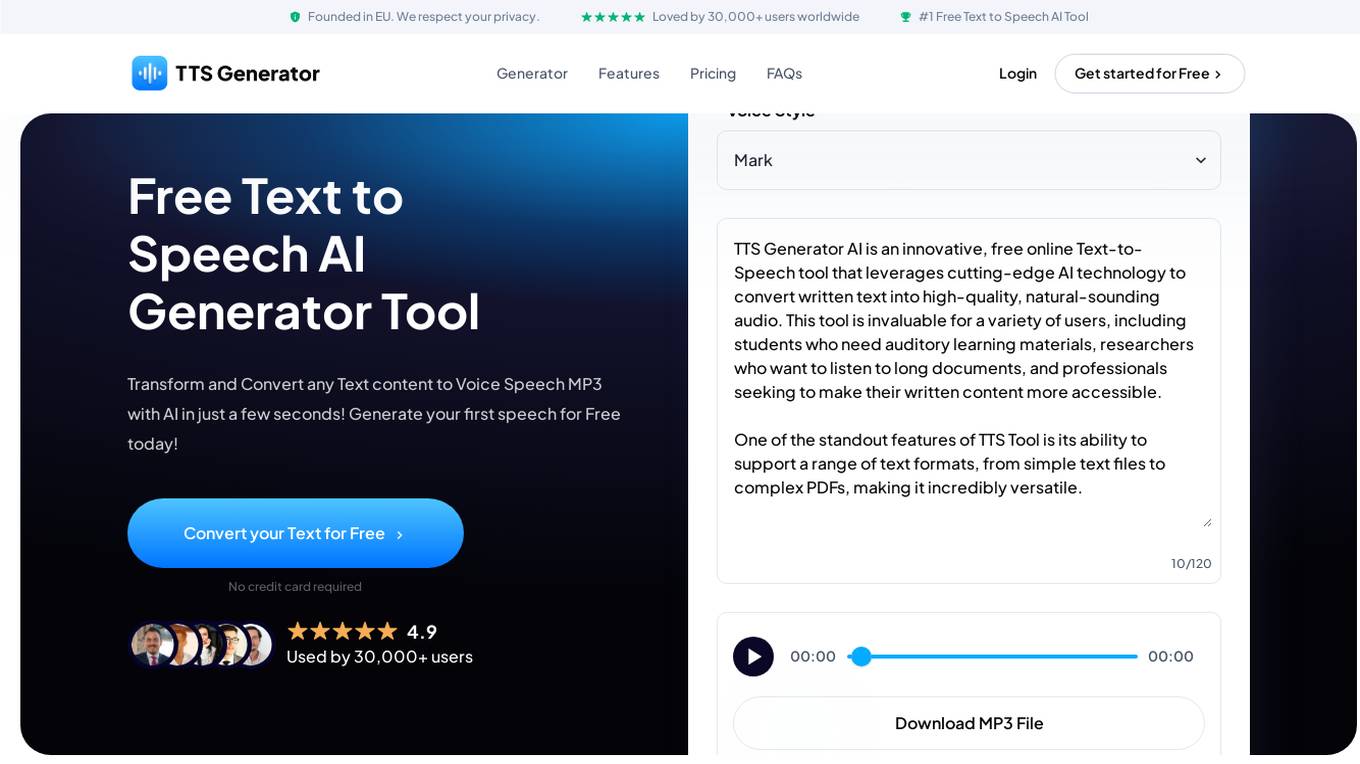
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
8 - Open Source Tools

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.
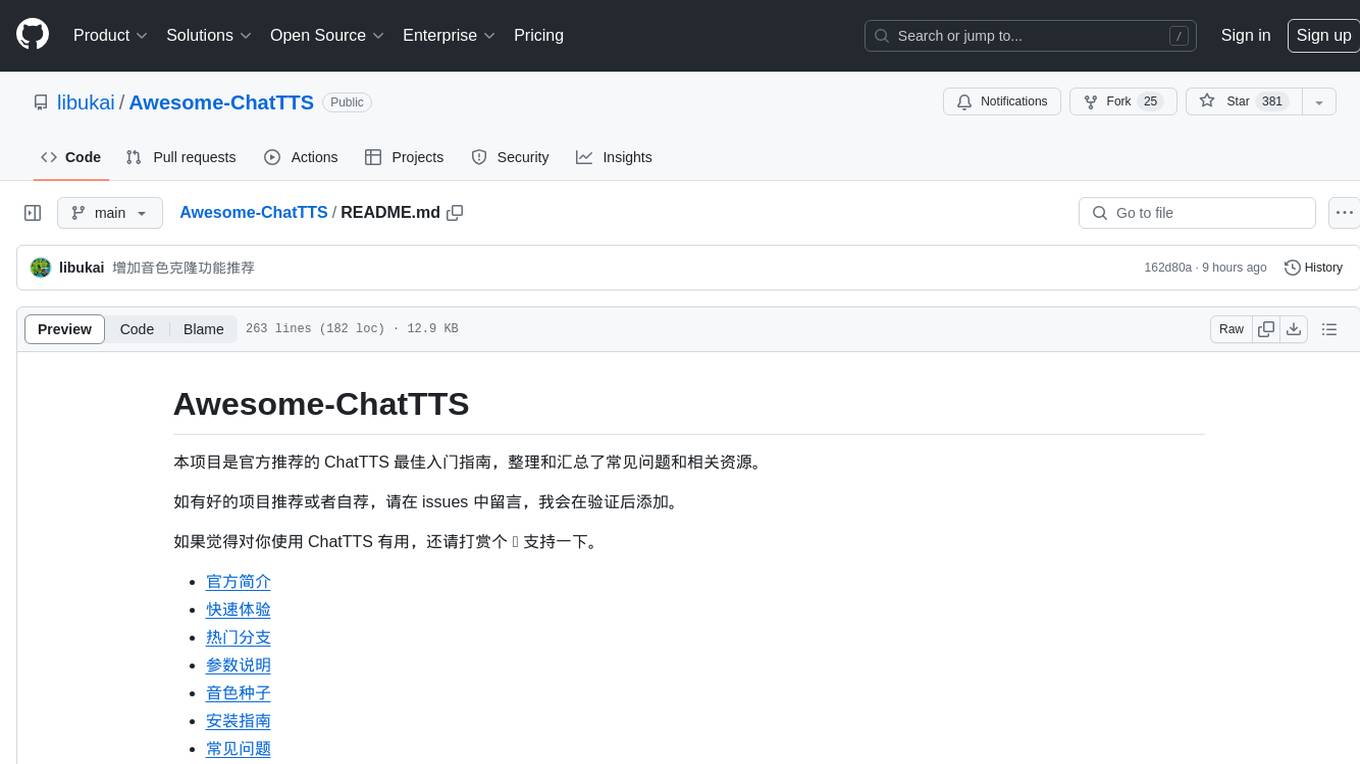
Awesome-ChatTTS
Awesome-ChatTTS is an official recommended guide for ChatTTS beginners, compiling common questions and related resources. It provides a comprehensive overview of the project, including official introduction, quick experience options, popular branches, parameter explanations, voice seed details, installation guides, FAQs, and error troubleshooting. The repository also includes video tutorials, discussion community links, and project trends analysis. Users can explore various branches for different functionalities and enhancements related to ChatTTS.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.
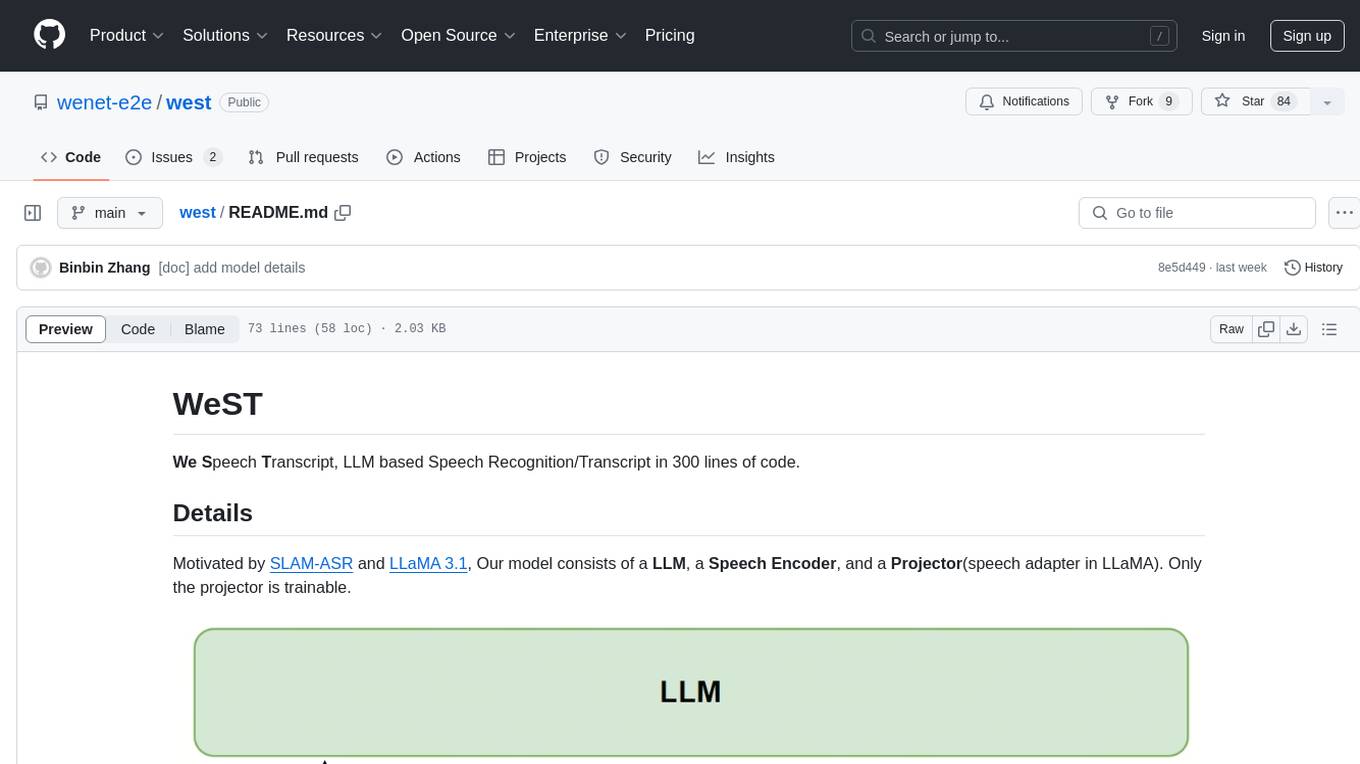
west
WeST is a Speech Recognition/Transcript tool developed in 300 lines of code, inspired by SLAM-ASR and LLaMA 3.1. The model includes a Language Model (LLM), a Speech Encoder, and a trainable Projector. It requires training data in jsonl format with 'wav' and 'txt' entries. WeST can be used for training and decoding speech recognition models.
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.

LLaSA_training
LLaSA_training is a repository focused on training models for speech synthesis using a large amount of open-source speech data. The repository provides instructions for finetuning models and offers pre-trained models for multilingual speech synthesis. It includes tools for training, data downloading, and data processing using specialized tokenizers for text and speech sequences. The repository also supports direct usage on Hugging Face platform with specific codecs and collections.
20 - OpenAI Gpts
Animal Translator
Your expert in translating human speech into animal languages, with a playful and educational twist.
Dialect Detective
Expert in distinguishing language dialects like Castilian vs Latin Spanish, and Parisian vs Canadian French.
Censorship Tolerant Networking
Expert in Earl Oliver's work on internet censorship, providing concise answers
ModiGPT
GPT, drawing inspiration from Narendra Modi, delves into the myriad of government initiatives led by him, alongside insights into his personal journey.

Atatürk'ün Yolu
Atatürk'ün Söylev ve Demeçleri ile Nutuk'u kaynak kabul eden fikir paylaşma aracı