Best AI tools for< Improve Speech Quality >
20 - AI tool Sites
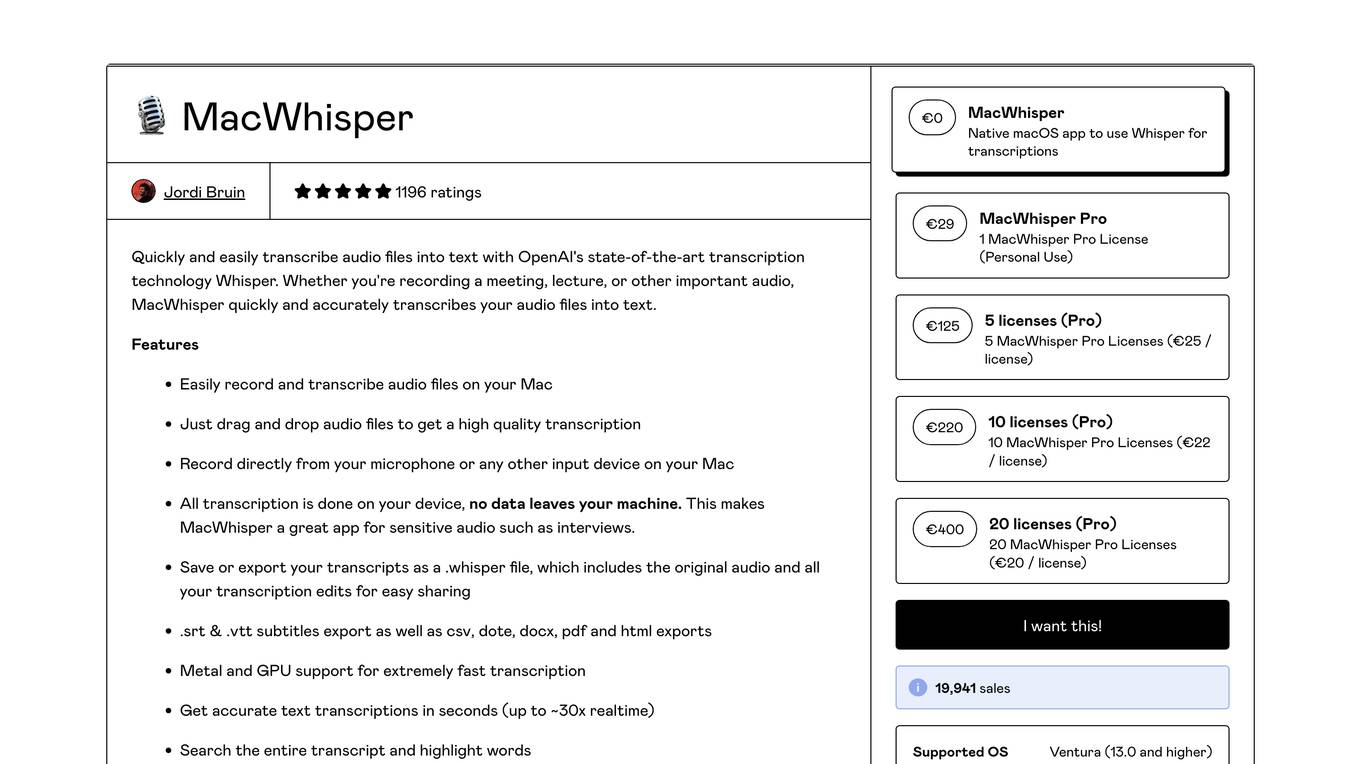
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
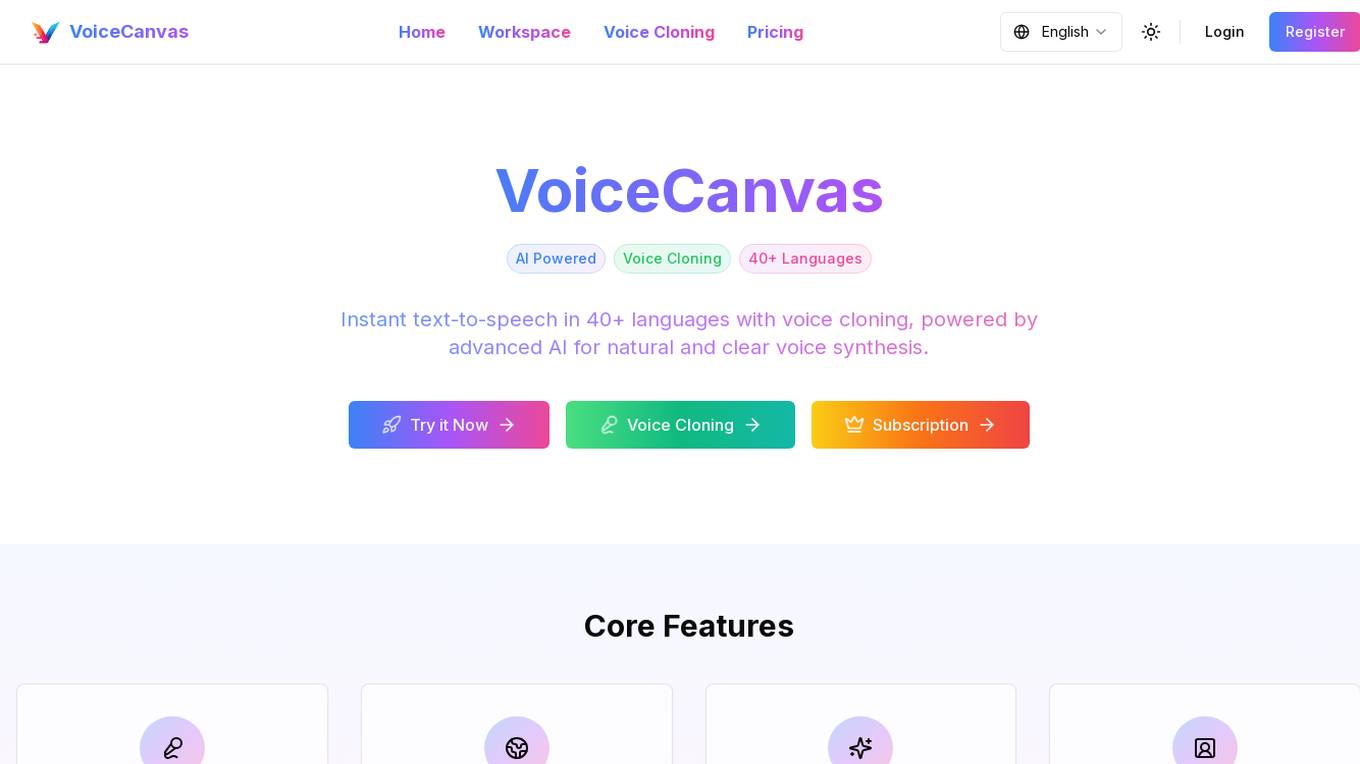
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
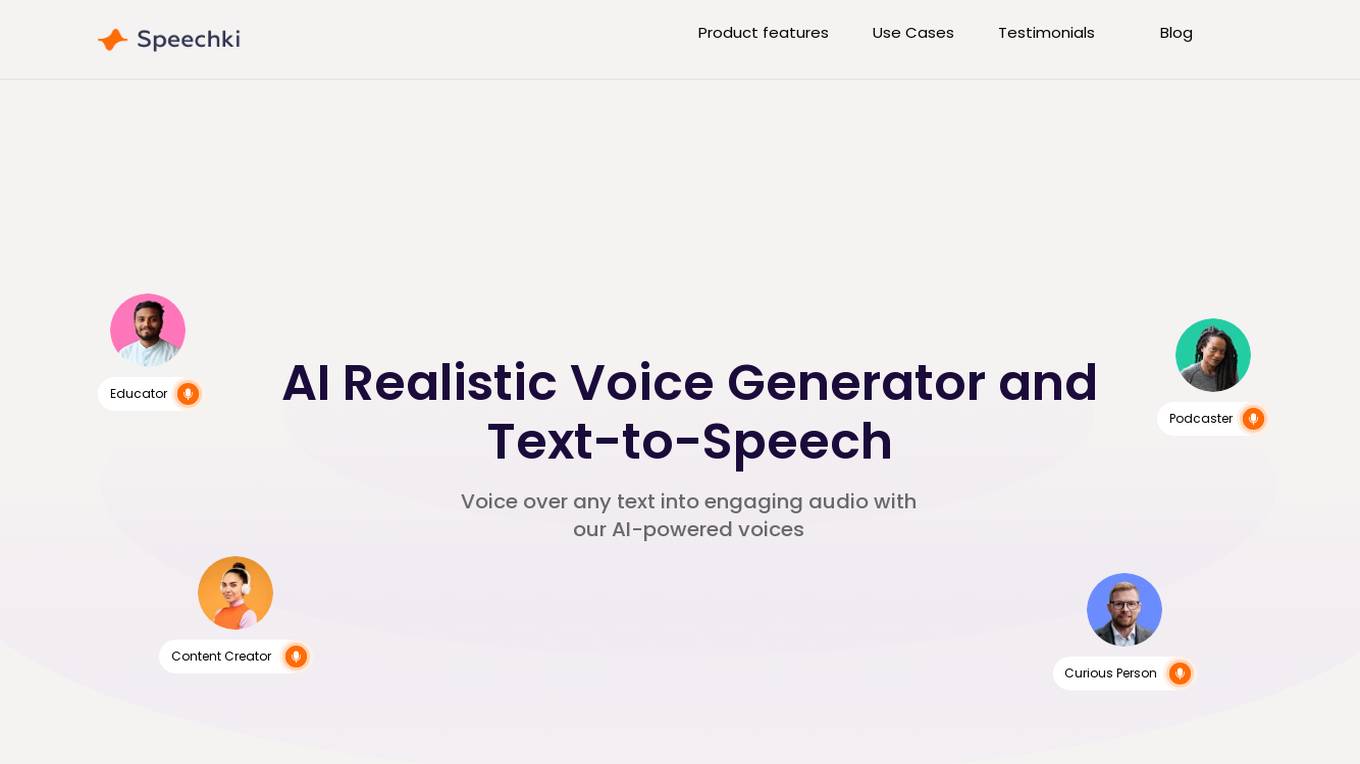
Speechki
Speechki is an AI Realistic Voice Generator and Text-to-Speech Solution offering over 1,100 voices in 80+ languages. It provides a user-friendly platform for converting text into engaging audio with AI-powered voices. The application is designed to cater to various needs such as audiobook production, content creation, podcasting, and more. With features like real-time proof-listening, chapter-like formatting, streamlined role management, precision pause control, and nuanced speech control, Speechki aims to enhance the user experience and deliver lifelike audio output. The tool also offers global reach with multicast and multilanguage support, making it suitable for a diverse audience.
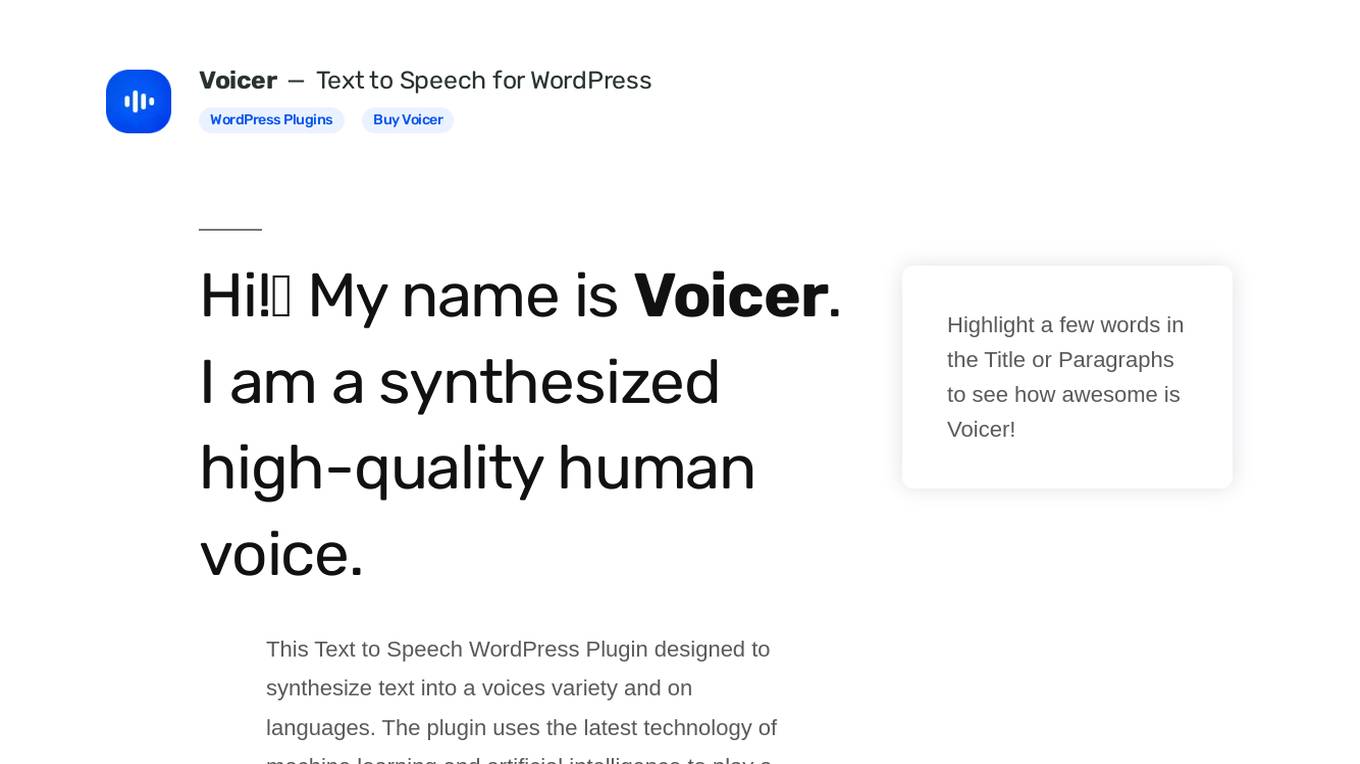
Voicer
Voicer is a Text to Speech WordPress Plugin that utilizes machine learning and artificial intelligence to synthesize text into high-quality human voices across 45+ languages and variants. It offers more than 275 human-like voices, works with all WordPress themes, and is perfect for RTL direction. The plugin applies advanced deep learning neural network algorithms to create lifelike interactions with users, transforming customer service and device interaction.
AI Voice Studio
AI Voice Studio is an innovative online tool that allows users to convert text into lifelike speech using advanced AI technology. With AI Voice Studio, users can easily create high-quality voiceovers for various purposes such as videos, podcasts, and presentations. The tool offers a user-friendly interface and a wide range of customization options to tailor the voice output to specific needs. Whether you are a content creator, marketer, or educator, AI Voice Studio provides a convenient and efficient solution for generating natural-sounding voice content.
Kokoro TTS Online
Kokoro TTS Online is a professional cloud service powered by the Kokoro 82M open-source model. It offers text-to-speech conversion with natural speech synthesis using advanced AI technology. Users can transform text into natural-sounding speech in seconds, choose from multiple voices, and experience superior audio quality. Kokoro TTS is user-friendly, supports American and British English, and is suitable for various applications such as creating voiceovers, podcasts, and learning materials.
AIby.email
AIby.email is an AI-powered email assistant that helps you write better emails, faster. It uses natural language processing to understand your intent and generate personalized email responses. AIby.email also offers a variety of other features, such as email scheduling, tracking, and analytics.
Voicepen
Voicepen is an AI-powered tool that converts audio recordings into high-quality blog posts. It uses advanced speech recognition and natural language processing technologies to accurately transcribe and format your audio content into well-written, SEO-optimized blog posts. With Voicepen, you can easily create engaging and informative blog content without spending hours writing and editing.
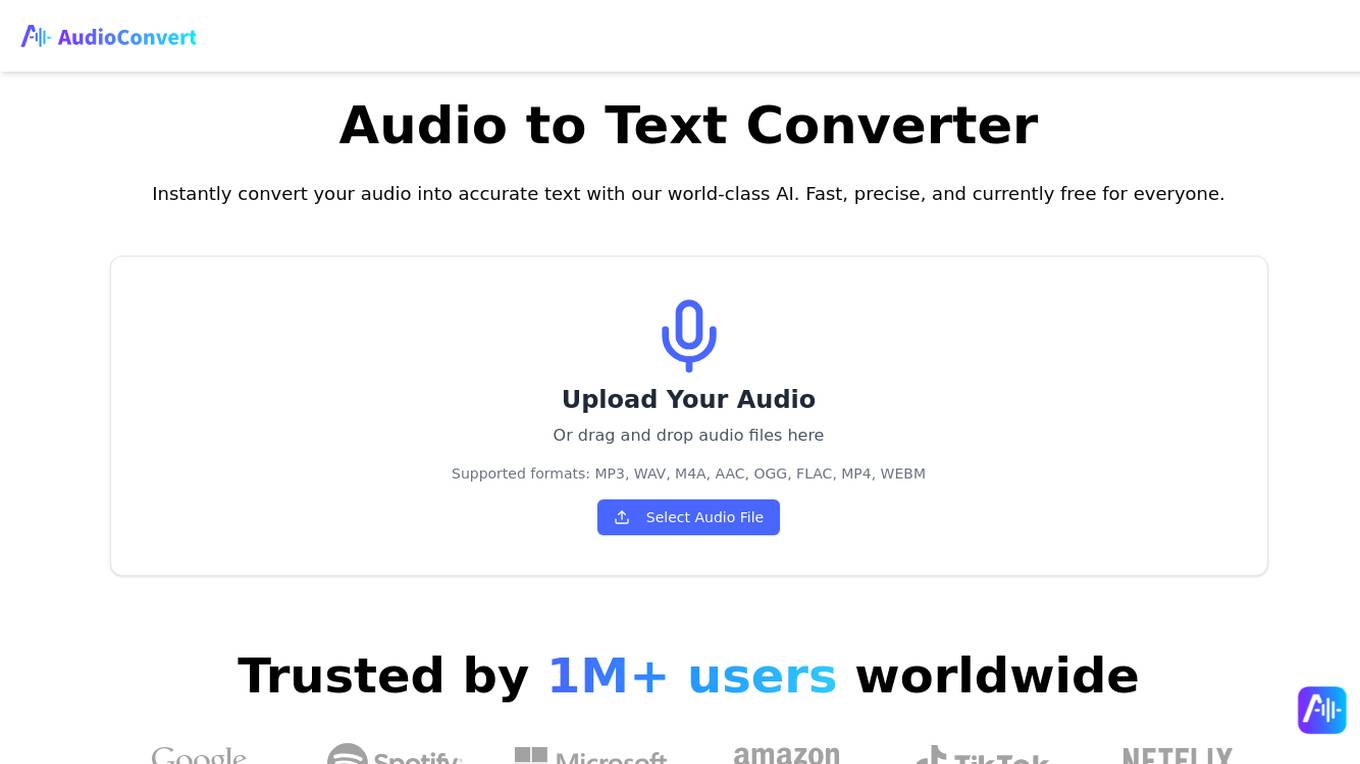
Free Audio to Text Converter
The Free Audio to Text Converter is an AI-powered tool that allows users to quickly and accurately transcribe audio files into text. It supports various audio formats and offers features like multi-speaker identification, multiple export formats, and precise timestamps. The tool is designed to enhance productivity by providing high-quality transcriptions for a wide range of needs, from content creation to academic research and sales analysis. Users can trust the tool's accuracy and efficiency to save time and improve workflow.
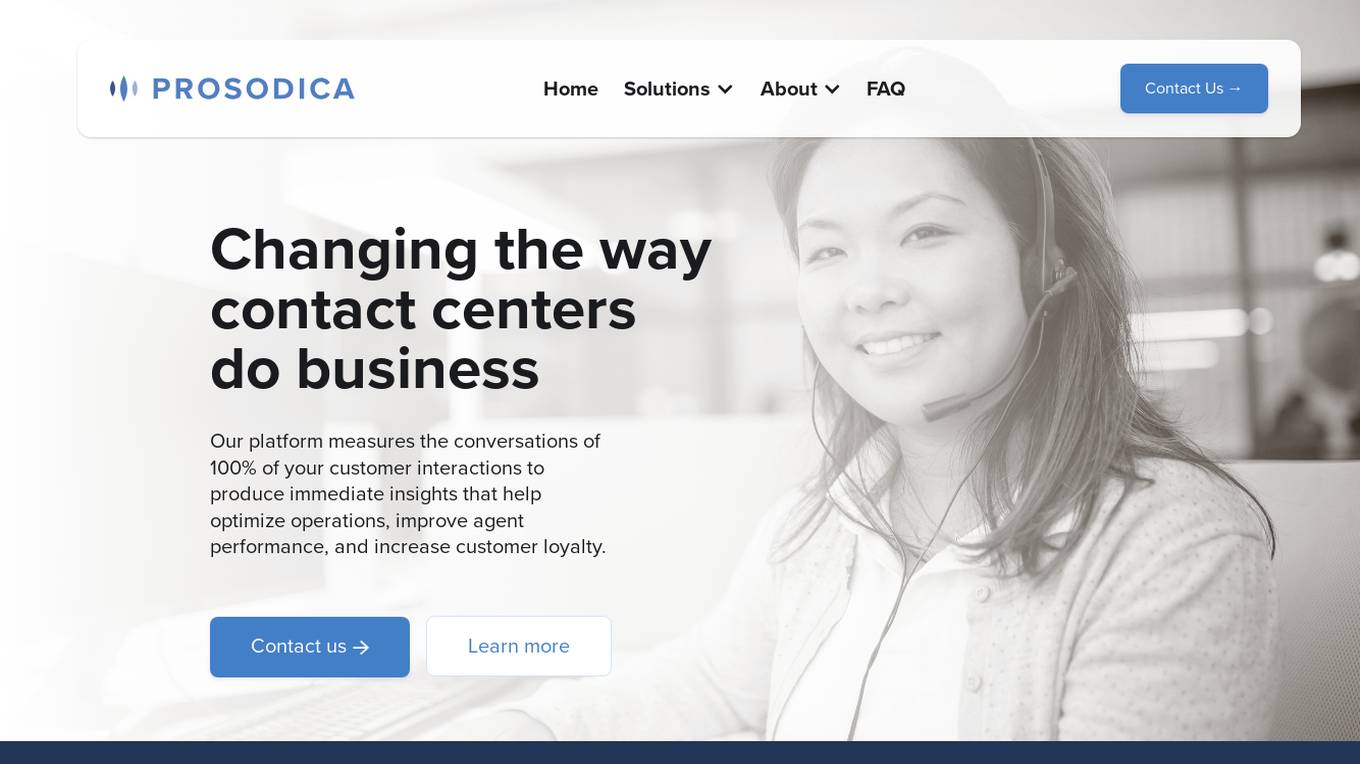
Prosodica
Prosodica is a contact center analytics platform that uses AI and machine learning to analyze conversational speech behaviors and non-verbal measures to provide a human-like perspective of conversational quality. It helps businesses optimize operations, improve agent performance, and increase customer loyalty.
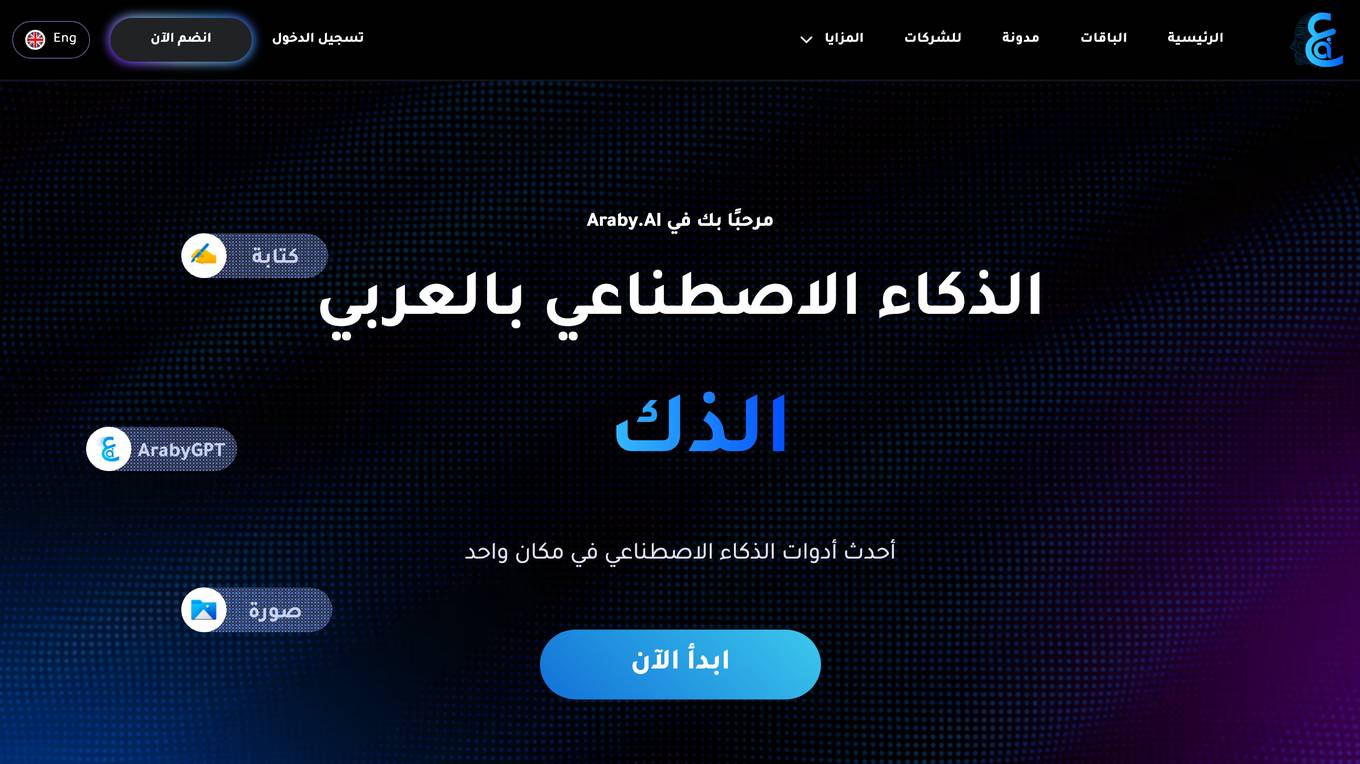
Araby AI
Araby AI is an Arabic platform that offers a wide range of artificial intelligence tools for various creative tasks. It provides tools for voice separation, content writing, website creation, text-to-speech conversion, music creation, logo design, image enhancement, and more. The platform is powered by advanced AI technologies to assist creators in producing high-quality content efficiently.
Ragobble
Ragobble is an audio to LLM data tool that allows you to easily convert audio files into text data that can be used to train large language models (LLMs). With Ragobble, you can quickly and easily create high-quality training data for your LLM projects.
Verint CX Automation
Verint CX Automation is an AI-powered platform that helps contact centers lower costs and enhance customer experience by automating workflows with AI-powered bots. The platform offers a range of capabilities such as Agent Copilot to increase agent capacity, Customer Self-Service with AI-powered IVAs, Business Analytics for speech, text, and desktop analytics, and Workforce Engagement to improve employee performance. Verint CX Automation is designed to deliver measurable ROI quickly and efficiently, making it a valuable tool for businesses looking to optimize their customer service operations.
Prosodica
Prosodica is a cloud-based contact center analytics platform that uses AI and machine learning to analyze 100% of customer interactions. It provides real-time insights into agent performance, customer satisfaction, and business trends. Prosodica helps contact centers improve their operations, increase agent productivity, and drive customer loyalty.
Looppanel
Looppanel is a user research analysis and repository tool that uses AI to help researchers save time and improve the quality of their work. It offers a range of features, including automated transcription, AI note-taking, video snipping, and advanced search capabilities. Looppanel is designed to make it easy for researchers to capture, organize, and analyze their research data, so they can focus on what matters most: uncovering insights and making better decisions.
Cluc.io
Cluc.io is an AI-powered content generation and management platform that offers a suite of tools to help businesses create high-quality content quickly and easily. With Cluc.io, users can generate text, images, code, videos, and more, all with the help of AI. The platform also includes a range of features to help businesses manage their content, including a dashboard, payment gateways, and multilingual support. Cluc.io is a valuable tool for any business looking to improve its content marketing efforts.
Easy-Peasy.AI
Easy-Peasy.AI is an all-in-one AI platform that offers a variety of AI tools and solutions to assist users in content generation, copywriting, chatbot creation, image creation, audio transcription, and text-to-speech tasks. The platform provides a user-friendly interface and powerful technology to help users create high-quality content, improve writing skills, and automate various tasks using AI technology.
Vocal Image
Vocal Image is an AI-powered coaching app that offers speech and communication lessons to help speakers and singers boost confidence and enhance the attractiveness of their voice. The app provides voice evaluations, educational content, specialized programs, and challenges designed to improve voice quality and communication skills. Users can record their voice, receive feedback from a community of voice enthusiasts, and engage with AI coach recommendations to achieve their voice goals.
Speechimo
Speechimo is an AI-powered text-to-speech tool that transforms written content into high-quality audio with human-like voices. It offers a user-friendly interface, premium voices, and efficient voice generation, making it a valuable asset for content creators across various platforms. With Speechimo, users can enhance their videos, audiobooks, podcasts, and e-learning materials, elevating the overall quality of their content creation process.
MagicLoop
MagicLoop is a voice survey tool designed to enhance customer feedback by replacing written feedback with spoken responses. It allows users to gather higher-quality responses through voice surveys, capturing emotions, tones, and nuances for a deeper understanding of participants' feelings and intentions. The tool aims to improve participant engagement and provide detailed insights by encouraging genuine responses. MagicLoop offers a modern approach to surveys, addressing the limitations of traditional methods and providing tailored solutions for various use cases such as user research, satisfaction surveys, NPS, feedback collection, market research, and data monitoring. With features like AI analysis, speech-to-text transcription, and custom branding, MagicLoop streamlines the process of generating insights from voice recordings.
1 - Open Source AI Tools
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.
20 - OpenAI Gpts

Dedicated Speech-Language Pathologist
Expert Speech-Language Pathologist offering tailored medical consultations.


AI Phonetics and Reading Coach with Speech
Phonetics and reading coach with interactive voice capabilities, tailored for adult beginners.
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.

Dedicated Occupational Therapist
Empathetic Occupational Therapist offering tailored medical consultations

Your Lingo AI Coach
Welcome! I'm a voice-focused language teacher for interactive speaking practice. To enable voice, download the app and tap the headphone button next to my chat window. Then choose your preferred voice. When you're ready, tell me what language you'd like to learn. It's FREE!


English Pronunciation Helper
I assist with English pronunciation using the Turkish alphabet.