
AutoRAG
AutoRAG: An Open-Source Framework for Retrieval-Augmented Generation (RAG) Evaluation & Optimization with AutoML-Style Automation
Stars: 3464
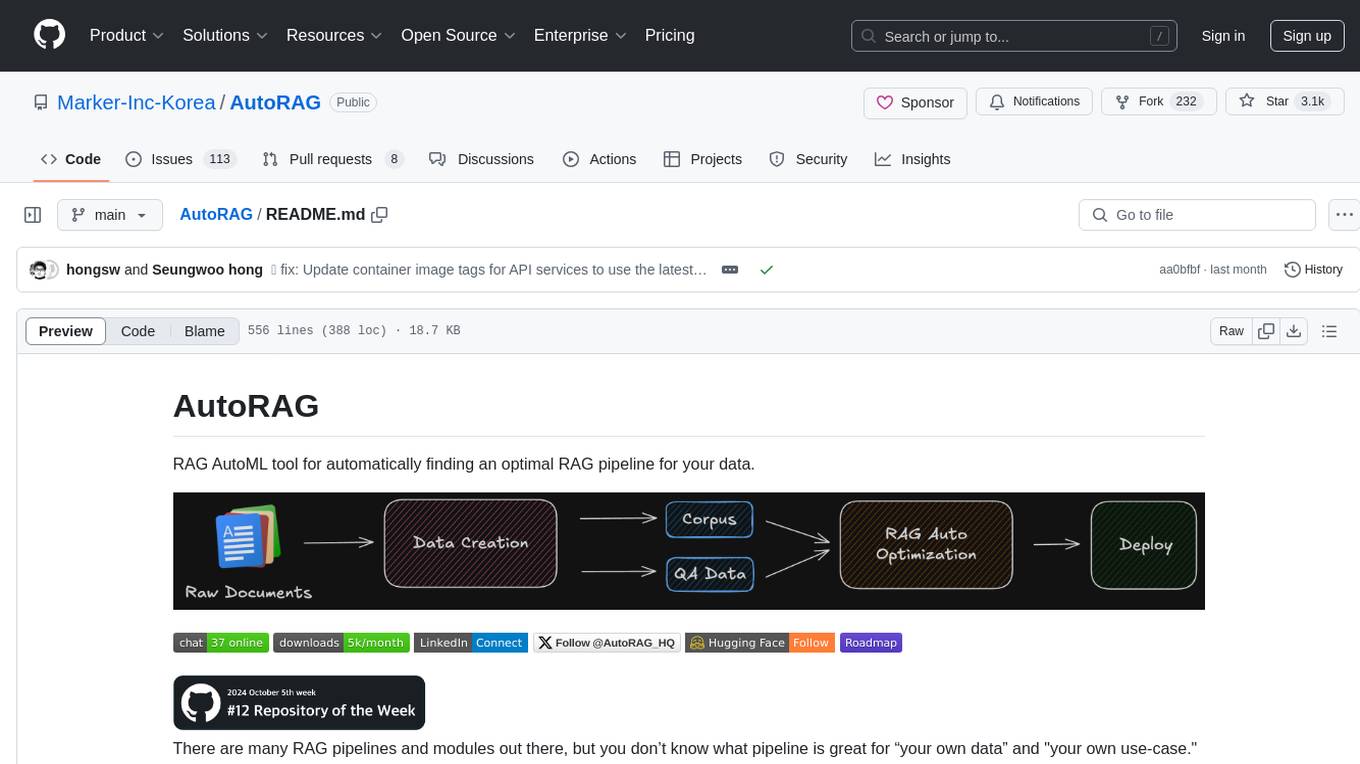
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.
README:
RAG AutoML tool for automatically finding an optimal RAG pipeline for your data.



There are many RAG pipelines and modules out there, but you don’t know what pipeline is great for “your own data” and "your own use-case." Making and evaluating all RAG modules is very time-consuming and hard to do. But without it, you will never know which RAG pipeline is the best for your own use-case.
AutoRAG is a tool for finding the optimal RAG pipeline for “your data.” You can evaluate various RAG modules automatically with your own evaluation data and find the best RAG pipeline for your own use-case.
AutoRAG supports a simple way to evaluate many RAG module combinations. Try now and find the best RAG pipeline for your own use-case.
Explore our 📖 Document!!
Plus, join our 📞 Discord Community.
Do you have any difficulties in optimizing your RAG pipeline? Or is it hard to set up things to use AutoRAG? Try AutoRAG Cloud beta. We will help you to run AutoRAG and optimize. Plus, we can help you to build RAG evaluation dataset.
Starts with 9.99$ per optimization.
https://github.com/Marker-Inc-Korea/AutoRAG/assets/96727832/c0d23896-40c0-479f-a17b-aa2ec3183a26
Muted by default, enable sound for voice-over
You can see on YouTube
- Step 1: Basic of AutoRAG | Optimizing your RAG pipeline
- Step 2: Data Creation | Create your own Data for RAG Optimization
- Step 3: Use Custom LLM & Embedding Model | Use Custom Model
We recommend using Python version 3.10 or higher for AutoRAG.
pip install AutoRAGIf you want to use the local models, you need to install gpu version.
pip install "AutoRAG[gpu]"Or for parsing, you can use the parsing version.
pip install "AutoRAG[gpu,parse]"RAG Optimization requires two types of data: QA dataset and Corpus dataset.
- QA dataset file (qa.parquet)
- Corpus dataset file (corpus.parquet)
QA dataset is important for accurate and reliable evaluation and optimization.
Corpus dataset is critical to the performance of RAGs. This is because RAG uses the corpus to retrieve documents and generate answers using it.
modules:
- module_type: langchain_parse
parse_method: pdfminerYou can also use multiple Parse modules at once. However, in this case, you'll need to return a new process for each parsed result.
You can parse your raw documents with just a few lines of code.
from autorag.parser import Parser
parser = Parser(data_path_glob="your/data/path/*")
parser.start_parsing("your/path/to/parse_config.yaml")modules:
- module_type: llama_index_chunk
chunk_method: Token
chunk_size: 1024
chunk_overlap: 24
add_file_name: enYou can also use multiple Chunk modules at once. In this case, you need to use one corpus to create QA and then map the rest of the corpus to QA Data. If the chunk method is different, the retrieval_gt will be different, so we need to remap it to the QA dataset.
You can chunk your parsed results with just a few lines of code.
from autorag.chunker import Chunker
chunker = Chunker.from_parquet(parsed_data_path="your/parsed/data/path")
chunker.start_chunking("your/path/to/chunk_config.yaml")You can create QA dataset with just a few lines of code.
import pandas as pd
from llama_index.llms.openai import OpenAI
from autorag.data.qa.filter.dontknow import dontknow_filter_rule_based
from autorag.data.qa.generation_gt.llama_index_gen_gt import (
make_basic_gen_gt,
make_concise_gen_gt,
)
from autorag.data.qa.schema import Raw, Corpus
from autorag.data.qa.query.llama_gen_query import factoid_query_gen
from autorag.data.qa.sample import random_single_hop
llm = OpenAI()
raw_df = pd.read_parquet("your/path/to/parsed.parquet")
raw_instance = Raw(raw_df)
corpus_df = pd.read_parquet("your/path/to/corpus.parquet")
corpus_instance = Corpus(corpus_df, raw_instance)
initial_qa = (
corpus_instance.sample(random_single_hop, n=3)
.map(
lambda df: df.reset_index(drop=True),
)
.make_retrieval_gt_contents()
.batch_apply(
factoid_query_gen, # query generation
llm=llm,
)
.batch_apply(
make_basic_gen_gt, # answer generation (basic)
llm=llm,
)
.batch_apply(
make_concise_gen_gt, # answer generation (concise)
llm=llm,
)
.filter(
dontknow_filter_rule_based, # filter don't know
lang="en",
)
)
initial_qa.to_parquet('./qa.parquet', './corpus.parquet')Here is the AutoRAG RAG Structure that only show Nodes.
Here is the image showing all the nodes and modules.
The metrics used by each node in AutoRAG are shown below.
Here is the detailed information about the metrics that AutoRAG supports.
First, you need to set the config YAML file for your RAG optimization.
We highly recommend using pre-made config YAML files for starter.
Here is an example of the config YAML file to use retrieval, prompt_maker, and generator nodes.
node_lines:
- node_line_name: retrieve_node_line # Set Node Line (Arbitrary Name)
nodes:
- node_type: retrieval # Set Retrieval Node
strategy:
metrics: [retrieval_f1, retrieval_recall, retrieval_ndcg, retrieval_mrr] # Set Retrieval Metrics
top_k: 3
modules:
- module_type: vectordb
vectordb: default
- module_type: bm25
- module_type: hybrid_rrf
weight_range: (4,80)
- node_line_name: post_retrieve_node_line # Set Node Line (Arbitrary Name)
nodes:
- node_type: prompt_maker # Set Prompt Maker Node
strategy:
metrics: # Set Generation Metrics
- metric_name: meteor
- metric_name: rouge
- metric_name: sem_score
embedding_model: openai
modules:
- module_type: fstring
prompt: "Read the passages and answer the given question. \n Question: {query} \n Passage: {retrieved_contents} \n Answer : "
- node_type: generator # Set Generator Node
strategy:
metrics: # Set Generation Metrics
- metric_name: meteor
- metric_name: rouge
- metric_name: sem_score
embedding_model: openai
modules:
- module_type: openai_llm
llm: gpt-4o-mini
batch: 16You can evaluate your RAG pipeline with just a few lines of code.
from autorag.evaluator import Evaluator
evaluator = Evaluator(qa_data_path='your/path/to/qa.parquet', corpus_data_path='your/path/to/corpus.parquet')
evaluator.start_trial('your/path/to/config.yaml')or you can use the command line interface
autorag evaluate --config your/path/to/default_config.yaml --qa_data_path your/path/to/qa.parquet --corpus_data_path your/path/to/corpus.parquetOnce it is done, you can see several files and folders created in your current directory.
At the trial folder named to numbers (like 0),
you can check summary.csv file that summarizes the evaluation results and the best RAG pipeline for your data.
For more details, you can check out how the folder structure looks like at here.
You can run a dashboard to easily see the result.
autorag dashboard --trial_dir /your/path/to/trial_dirYou can use an optimal RAG pipeline right away from the trial folder. The trial folder is the directory used in the running dashboard. (like 0, 1, 2, ...)
from autorag.deploy import Runner
runner = Runner.from_trial_folder('/your/path/to/trial_dir')
runner.run('your question')You can run this pipeline as an API server.
Check out the API endpoint at here.
import nest_asyncio
from autorag.deploy import ApiRunner
nest_asyncio.apply()
runner = ApiRunner.from_trial_folder('/your/path/to/trial_dir')
runner.run_api_server()autorag run_api --trial_dir your/path/to/trial_dir --host 0.0.0.0 --port 8000The cli command uses extracted config YAML file. If you want to know it more, check out here.
you can run this pipeline as a web interface.
Check out the web interface at here.
autorag run_web --trial_path your/path/to/trial_pathYou can deploy the advanced web interface featured by Kotaemon to the fly.io. Go here to use it and deploy to the fly.io.
Example :
This guide provides a quick overview of building and running the AutoRAG Docker container for production, with instructions on setting up the environment for evaluation using your configuration and data paths.
Tip: If you want to build an image for a gpu version, you can use autoraghq/autorag:gpu or autoraghq/autorag:gpu-parsing
1.Download dataset for Tutorial Step 1
python sample_dataset/eli5/load_eli5_dataset.py --save_path projects/tutorial_1Note: This step may take a long time to complete and involves OpenAI API calls, which may cost approximately $0.30.
docker run --rm -it \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v $(pwd)/projects:/usr/src/app/projects \
-e OPENAI_API_KEY=${OPENAI_API_KEY} \
autoraghq/autorag:api-latest evaluate \
--config /usr/src/app/projects/tutorial_1/config.yaml \
--qa_data_path /usr/src/app/projects/tutorial_1/qa_test.parquet \
--corpus_data_path /usr/src/app/projects/tutorial_1/corpus.parquet \
--project_dir /usr/src/app/projects/tutorial_1/docker run --rm -it \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v $(pwd)/projects:/usr/src/app/projects \
-e OPENAI_API_KEY=${OPENAI_API_KEY} \
autoraghq/autorag:api-latest validate \
--config /usr/src/app/projects/tutorial_1/config.yaml \
--qa_data_path /usr/src/app/projects/tutorial_1/qa_test.parquet \
--corpus_data_path /usr/src/app/projects/tutorial_1/corpus.parquetdocker run --rm -it \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v $(pwd)/projects:/usr/src/app/projects \
-e OPENAI_API_KEY=${OPENAI_API_KEY} \
-p 8502:8502 \
autoraghq/autorag:api-latest dashboard \
--trial_dir /usr/src/app/projects/tutorial_1/0docker run --rm -it \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v $(pwd)/projects:/usr/src/app/projects \
-e OPENAI_API_KEY=${OPENAI_API_KEY} \
-p 8501:8501 \
autoraghq/autorag:api-latest run_web --trial_path ./projects/tutorial_1/0-
-v ~/.cache/huggingface:/cache/huggingface: Mounts the host machine’s Hugging Face cache to/cache/huggingfacein the container, enabling access to pre-downloaded models. -
-e OPENAI_API_KEY: ${OPENAI_API_KEY}: Passes theOPENAI_API_KEYfrom your host environment.
For more detailed instructions, refer to the Docker Installation Guide.
🛣️ Roadmap
Talk with us! We are always open to talk with you.
Thanks go to these wonderful people:
We are developing AutoRAG as open-source.
So this project welcomes contributions and suggestions. Feel free to contribute to this project.
Plus, check out our detailed documentation at here.
@misc{kim2024autoragautomatedframeworkoptimization,
title={AutoRAG: Automated Framework for optimization of Retrieval Augmented Generation Pipeline},
author={Dongkyu Kim and Byoungwook Kim and Donggeon Han and Matouš Eibich},
year={2024},
eprint={2410.20878},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.20878},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AutoRAG
Similar Open Source Tools
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
WilliamButcherBot
WilliamButcherBot is a Telegram Group Manager Bot and Userbot written in Python using Pyrogram. It provides features for managing Telegram groups and users, with ready-to-use methods available. The bot requires Python 3.9, Telegram API Key, Telegram Bot Token, and MongoDB URI. Users can install it locally or on a VPS, run it directly, generate Pyrogram session for Heroku, or use Docker for deployment. Additionally, users can write new modules to extend the bot's functionality by adding them to the wbb/modules/ directory.
quickvid
QuickVid is an open-source video summarization tool that uses AI to generate summaries of YouTube videos. It is built with Whisper, GPT, LangChain, and Supabase. QuickVid can be used to save time and get the essence of any YouTube video with intelligent summarization.
genius-ai
Genius is a modern Next.js 14 SaaS AI platform that provides a comprehensive folder structure for app development. It offers features like authentication, dashboard management, landing pages, API integration, and more. The platform is built using React JS, Next JS, TypeScript, Tailwind CSS, and integrates with services like Netlify, Prisma, MySQL, and Stripe. Genius enables users to create AI-powered applications with functionalities such as conversation generation, image processing, code generation, and more. It also includes features like Clerk authentication, OpenAI integration, Replicate API usage, Aiven database connectivity, and Stripe API/webhook setup. The platform is fully configurable and provides a seamless development experience for building AI-driven applications.
KsanaLLM
KsanaLLM is a high-performance engine for LLM inference and serving. It utilizes optimized CUDA kernels for high performance, efficient memory management, and detailed optimization for dynamic batching. The tool offers flexibility with seamless integration with popular Hugging Face models, support for multiple weight formats, and high-throughput serving with various decoding algorithms. It enables multi-GPU tensor parallelism, streaming outputs, and an OpenAI-compatible API server. KsanaLLM supports NVIDIA GPUs and Huawei Ascend NPU, and seamlessly integrates with verified Hugging Face models like LLaMA, Baichuan, and Qwen. Users can create a docker container, clone the source code, compile for Nvidia or Huawei Ascend NPU, run the tool, and distribute it as a wheel package. Optional features include a model weight map JSON file for models with different weight names.
auto-subs
Auto-subs is a tool designed to automatically transcribe editing timelines using OpenAI Whisper and Stable-TS for extreme accuracy. It generates subtitles in a custom style, is completely free, and runs locally within Davinci Resolve. It works on Mac, Linux, and Windows, supporting both Free and Studio versions of Resolve. Users can jump to positions on the timeline using the Subtitle Navigator and translate from any language to English. The tool provides a user-friendly interface for creating and customizing subtitles for video content.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.

easy-dataset
Easy Dataset is a specialized application designed to streamline the creation of fine-tuning datasets for Large Language Models (LLMs). It offers an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning. With Easy Dataset, users can transform domain knowledge into structured datasets compatible with all OpenAI-format compatible LLM APIs, making the fine-tuning process accessible and efficient.
yolo-flutter-app
Ultralytics YOLO for Flutter is a Flutter plugin that allows you to integrate Ultralytics YOLO computer vision models into your mobile apps. It supports both Android and iOS platforms, providing APIs for object detection and image classification. The plugin leverages Flutter Platform Channels for seamless communication between the client and host, handling all processing natively. Before using the plugin, you need to export the required models in `.tflite` and `.mlmodel` formats. The plugin provides support for tasks like detection and classification, with specific instructions for Android and iOS platforms. It also includes features like camera preview and methods for object detection and image classification on images. Ultralytics YOLO thrives on community collaboration and offers different licensing paths for open-source and commercial use cases.
flowgram.ai
FlowGram.AI is a node-based flow building engine that helps developers create workflows in fixed or free connection layout modes. It provides interaction best practices and is suitable for visual workflows with clear inputs and outputs. The tool focuses on empowering workflows with AI capabilities.
fastserve-ai
FastServe-AI is a machine learning serving tool focused on GenAI & LLMs with simplicity as the top priority. It allows users to easily serve custom models by implementing the 'handle' method for 'FastServe'. The tool provides a FastAPI server for custom models and can be deployed using Lightning AI Studio. Users can install FastServe-AI via pip and run it to serve their own GPT-like LLM models in minutes.
duolingo-clone
Lingo is an interactive platform for language learning that provides a modern UI/UX experience. It offers features like courses, quests, and a shop for users to engage with. The tech stack includes React JS, Next JS, Typescript, Tailwind CSS, Vercel, and Postgresql. Users can contribute to the project by submitting changes via pull requests. The platform utilizes resources from CodeWithAntonio, Kenney Assets, Freesound, Elevenlabs AI, and Flagpack. Key dependencies include @clerk/nextjs, @neondatabase/serverless, @radix-ui/react-avatar, and more. Users can follow the project creator on GitHub and Twitter, as well as subscribe to their YouTube channel for updates. To learn more about Next.js, users can refer to the Next.js documentation and interactive tutorial.
Flowise
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.
llama-assistant
Llama Assistant is an AI-powered assistant that helps with daily tasks, such as voice recognition, natural language processing, summarizing text, rephrasing sentences, answering questions, and more. It runs offline on your local machine, ensuring privacy by not sending data to external servers. The project is a work in progress with regular feature additions.
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.
For similar tasks
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.