
FinalRip
a distributed AI video processing tool
Stars: 55
FinalRip is a distributed video processing tool based on FFmpeg and VapourSynth. It cuts the original video into multiple clips, processes each clip in parallel, and merges them into the final video. Users can deploy the system in a distributed way, configure settings via environment variables or remote config files, and develop/test scripts in the vs-playground environment. It supports Nvidia GPU, AMD GPU with ROCm support, and provides a dashboard for selecting compatible scripts to process videos.
README:
a distributed video processing tool, based on FFmpeg and VapourSynth
![]()
![]()
![]()
![]()
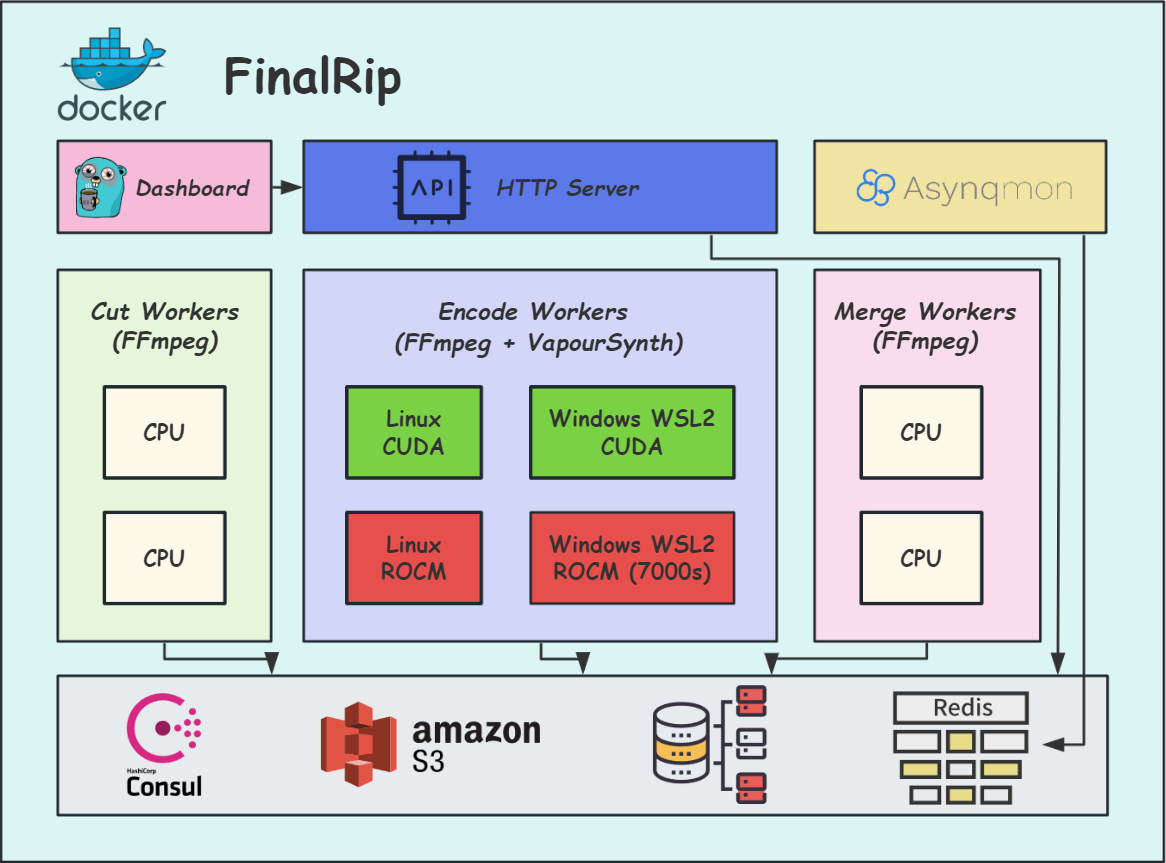
We cut the original video into multiple clips, and then process each clip in parallel in queue order. After all clips are processed, we merge them into the final video.
- docker and docker-compose
- Nvidia GPU / AMD GPU with ROCm support (7000 series on WSL2)
- GPU container runtime (optional)
- make (optional)
edit Line 19 to your LAN IP address
docker-compose -f deploy/docker-compose/lite/docker-compose.yml up -dIt will run all containers in a single host, then open http://localhost:8989 in your browser to access the dashboard, open http://localhost:8080 to access the Asynq monitor.
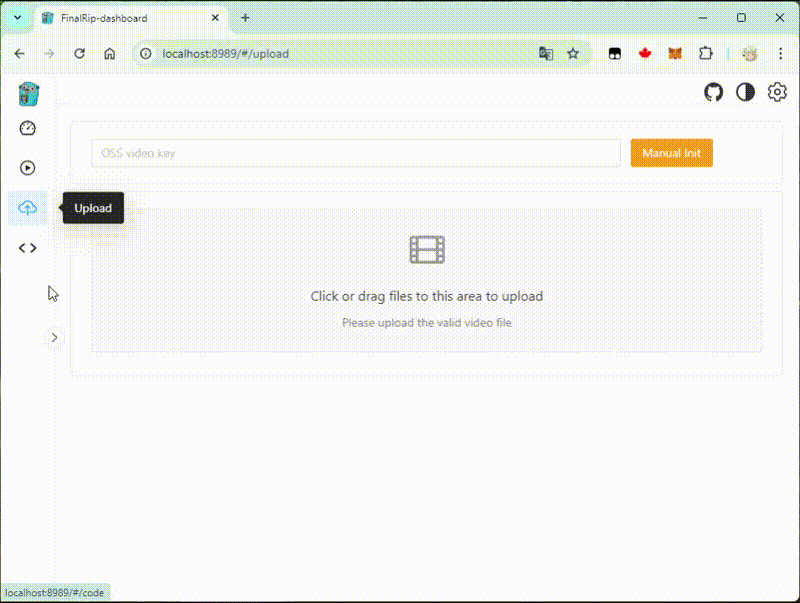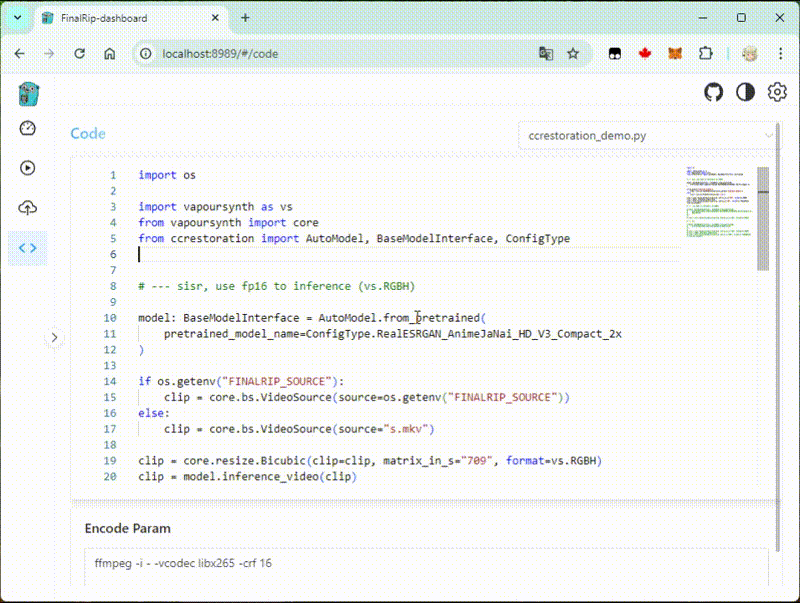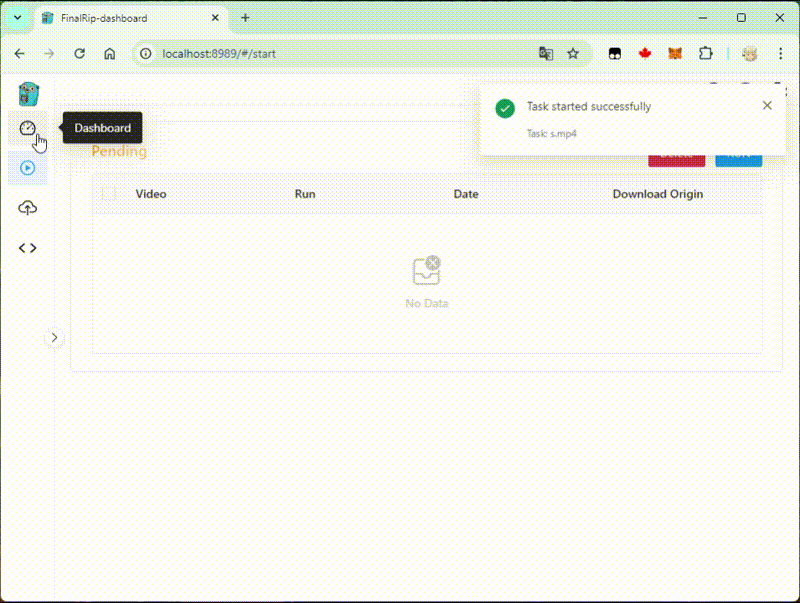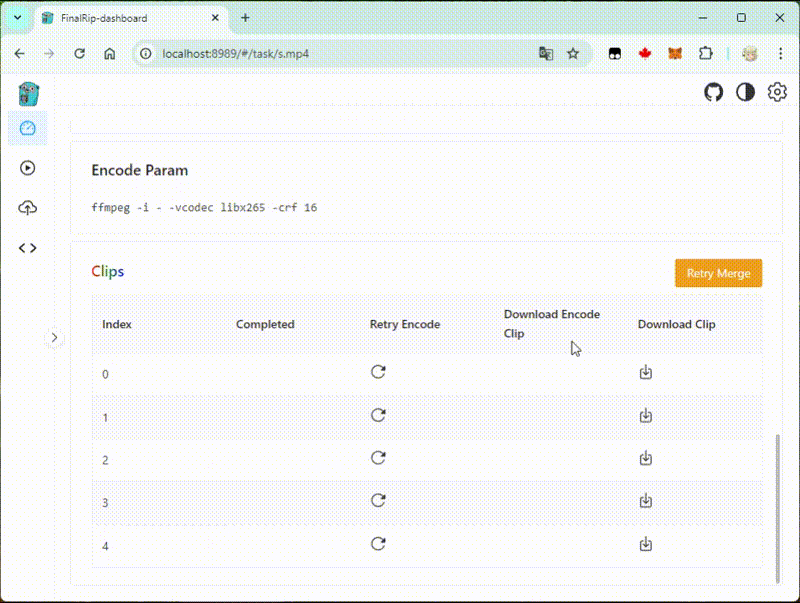
We use this container as the base image, which contains FFmpeg, VapourSynth, PyTorch...
So in the dashboard, we can select a compatible script to process the video!
Deploy the system in a distributed way, you can refer to the docker-compose directory for more details.
first, run docker-compose-base.yml to start the basic services, and open Consul dashboard, add a K/V pair with key finalrip.yml and value is the content of finalrip.yml -- or your own configuration file
then, run docker-compose-server.yml to start the dashboard, server, cut worker, and merge worker services
finally, run docker-compose-encode.yml to start the encode worker services, we can deploy multiple encode workers in different hosts to speed up the encoding process
Note: we suggest that deploy oss service, cut & merge worker in the same host
Override the default configuration by setting:
Special Env Variables:
-
FINALRIP_REMOTE_CONFIG_HOSTConsul host, default is None, that means load config from local file. When set, it will load the config from the Consul K/V store. When set toEASYTIER/easytier, will try load config fromFINALRIP_EASYTIER_HOST:8500(10.126.126.251:8500by default). -
FINALRIP_REMOTE_CONFIG_KEYConsul key, default isfinalrip.yml
In vs-playground, we provide the same environment as the encode worker, so you can develop and test your script in the playground.
- API document: here
- Build your own
encodeimage: refer to the vs-playground, and set theTemplate Reponame in dashboard if you wanna select a script from the repo'stemplatesfolder.
make all
make ptmake pt-rocm for AMD GPU
This project is licensed under the GPL-3.0 license - see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FinalRip
Similar Open Source Tools
FinalRip
FinalRip is a distributed video processing tool based on FFmpeg and VapourSynth. It cuts the original video into multiple clips, processes each clip in parallel, and merges them into the final video. Users can deploy the system in a distributed way, configure settings via environment variables or remote config files, and develop/test scripts in the vs-playground environment. It supports Nvidia GPU, AMD GPU with ROCm support, and provides a dashboard for selecting compatible scripts to process videos.
browser
Lightpanda Browser is an open-source headless browser designed for fast web automation, AI agents, LLM training, scraping, and testing. It features ultra-low memory footprint, exceptionally fast execution, and compatibility with Playwright and Puppeteer through CDP. Built for performance, Lightpanda offers Javascript execution, support for Web APIs, and is optimized for minimal memory usage. It is a modern solution for web scraping and automation tasks, providing a lightweight alternative to traditional browsers like Chrome.
NeoGPT
NeoGPT is an AI assistant that transforms your local workspace into a powerhouse of productivity from your CLI. With features like code interpretation, multi-RAG support, vision models, and LLM integration, NeoGPT redefines how you work and create. It supports executing code seamlessly, multiple RAG techniques, vision models, and interacting with various language models. Users can run the CLI to start using NeoGPT and access features like Code Interpreter, building vector database, running Streamlit UI, and changing LLM models. The tool also offers magic commands for chat sessions, such as resetting chat history, saving conversations, exporting settings, and more. Join the NeoGPT community to experience a new era of efficiency and contribute to its evolution.
frontend
Nuclia frontend apps and libraries repository contains various frontend applications and libraries for the Nuclia platform. It includes components such as Dashboard, Widget, SDK, Sistema (design system), NucliaDB admin, CI/CD Deployment, and Maintenance page. The repository provides detailed instructions on installation, dependencies, and usage of these components for both Nuclia employees and external developers. It also covers deployment processes for different components and tools like ArgoCD for monitoring deployments and logs. The repository aims to facilitate the development, testing, and deployment of frontend applications within the Nuclia ecosystem.

opencode
Opencode is an AI coding agent designed for the terminal. It is a tool that allows users to interact with AI models for coding tasks in a terminal-based environment. Opencode is open source, provider-agnostic, and focuses on a terminal user interface (TUI) for coding. It offers features such as client/server architecture, support for various AI models, and a strong emphasis on community contributions and feedback.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.

obs-cleanstream
CleanStream is an OBS plugin that utilizes real-time local AI to clean live audio streams by removing unwanted words and utterances, such as 'uh' and 'um', and configurable words like profanity. It employs a neural network (OpenAI Whisper) to predict speech in real-time and eliminate undesired words. The plugin runs efficiently using the Whisper.cpp project from ggerganov. CleanStream offers users the ability to adjust settings and add the plugin to any audio-generating source in OBS, providing a seamless experience for content creators looking to enhance the quality of their live audio streams.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.
obs-cleanstream
CleanStream is an OBS plugin that utilizes AI to clean live audio streams by removing unwanted words and utterances, such as 'uh's and 'um's, and configurable words like profanity. It uses a neural network (OpenAI Whisper) in real-time to predict speech and eliminate unwanted words. The plugin is still experimental and not recommended for live production use, but it is functional for testing purposes. Users can adjust settings and configure the plugin to enhance audio quality during live streams.

codebox-api
CodeBox is a cloud infrastructure tool designed for running Python code in an isolated environment. It also offers simple file input/output capabilities and will soon support vector database operations. Users can install CodeBox using pip and utilize it by setting up an API key. The tool allows users to execute Python code snippets and interact with the isolated environment. CodeBox is currently in early development stages and requires manual handling for certain operations like refunds and cancellations. The tool is open for contributions through issue reporting and pull requests. It is licensed under MIT and can be contacted via email at [email protected].
sre-agent
SRE Agent is an open-source AI agent designed to help Site Reliability Engineers (SREs) debug, maintain healthy Kubernetes systems, and simplify DevOps tasks. With a command-line interface (CLI), users can interact directly with the agent to diagnose issues, report diagnostics, and streamline operations. The agent supports root cause debugging, Kubernetes log querying, GitHub codebase search, and CLI-powered interactions. It is powered by the Model Context Protocol (MCP) for seamless connectivity. Users can configure AWS credentials, GitHub integration, and Anthropic API key to start monitoring deployments and diagnosing issues. The tool is structured with Python services and TypeScript MCP servers for development and maintenance.
IOPaint
IOPaint is a free and open-source inpainting & outpainting tool powered by SOTA AI model. It supports various AI models to perform erase, inpainting, or outpainting tasks. Users can remove unwanted objects, defects, watermarks, or people from images using erase models. Additionally, diffusion models can replace objects or perform outpainting. The tool also offers plugins for interactive object segmentation, background removal, anime segmentation, super resolution, face restoration, and file management. IOPaint provides a web UI for easy access to the latest AI models and supports batch processing of images through the command line. Developers can contribute to the project by installing front-end dependencies, setting up the backend, and starting the development environment for both front-end and back-end components.
openmeter
OpenMeter is a real-time and scalable usage metering tool for AI, usage-based billing, infrastructure, and IoT use cases. It provides a REST API for integrations and offers client SDKs in Node.js, Python, Go, and Web. OpenMeter is licensed under the Apache 2.0 License.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
For similar tasks
Forza-Mods-AIO
Forza Mods AIO is a free and open-source tool that enhances the gaming experience in Forza Horizon 4 and 5. It offers a range of time-saving and quality-of-life features, making gameplay more enjoyable and efficient. The tool is designed to streamline various aspects of the game, improving user satisfaction and overall enjoyment.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
MaterialSearch
MaterialSearch is a tool for searching local images and videos using natural language. It provides functionalities such as text search for images, image search for images, text search for videos (providing matching video clips), image search for videos (searching for the segment in a video through a screenshot), image-text similarity calculation, and Pexels video search. The tool can be deployed through the source code or Docker image, and it supports GPU acceleration. Users can configure the tool through environment variables or a .env file. The tool is still under development, and configurations may change frequently. Users can report issues or suggest improvements through issues or pull requests.
tenere
Tenere is a TUI interface for Language Model Libraries (LLMs) written in Rust. It provides syntax highlighting, chat history, saving chats to files, Vim keybindings, copying text from/to clipboard, and supports multiple backends. Users can configure Tenere using a TOML configuration file, set key bindings, and use different LLMs such as ChatGPT, llama.cpp, and ollama. Tenere offers default key bindings for global and prompt modes, with features like starting a new chat, saving chats, scrolling, showing chat history, and quitting the app. Users can interact with the prompt in different modes like Normal, Visual, and Insert, with various key bindings for navigation, editing, and text manipulation.
openkore
OpenKore is a custom client and intelligent automated assistant for Ragnarok Online. It is a free, open source, and cross-platform program (Linux, Windows, and MacOS are supported). To run OpenKore, you need to download and extract it or clone the repository using Git. Configure OpenKore according to the documentation and run openkore.pl to start. The tool provides a FAQ section for troubleshooting, guidelines for reporting issues, and information about botting status on official servers. OpenKore is developed by a global team, and contributions are welcome through pull requests. Various community resources are available for support and communication. Users are advised to comply with the GNU General Public License when using and distributing the software.
QA-Pilot
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository. It allows users to chat with GitHub public repositories using a git clone approach, store chat history, configure settings easily, manage multiple chat sessions, and quickly locate sessions with a search function. The tool integrates with `codegraph` to view Python files and supports various LLM models such as ollama, openai, mistralai, and localai. The project is continuously updated with new features and improvements, such as converting from `flask` to `fastapi`, adding `localai` API support, and upgrading dependencies like `langchain` and `Streamlit` to enhance performance.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.