
QA-Pilot
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository.
Stars: 118
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository. It allows users to chat with GitHub public repositories using a git clone approach, store chat history, configure settings easily, manage multiple chat sessions, and quickly locate sessions with a search function. The tool integrates with `codegraph` to view Python files and supports various LLM models such as ollama, openai, mistralai, and localai. The project is continuously updated with new features and improvements, such as converting from `flask` to `fastapi`, adding `localai` API support, and upgrading dependencies like `langchain` and `Streamlit` to enhance performance.
README:
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository.
- Chat with github public repository with git clone way
- Store the chat history
- Easy to set the configuration
- Multiple chat sessions
- Locate the session quicly with search function
- Integrate with
codegraphto view the python file - Support the different LLM models
- ollama(llama3.1, phi3, llama3, gemma2)
- openai(gpt-4o, gpt-4-turbo, gpt-4, and gpt-3.5-turbo)
- mistralai(mistral-tiny, mistral-tiny, mistral-small-latest, mistral-medium-latest, mistral-large-latest, codestral-lates)
- localai(gpt-4, more)
- zhipuai(glm-4-0520, glm-4, glm-4-air, glm-4-airx, glm-4-flash)
- anthropic(claude-3-opus-20240229, claude-3-sonnet-20240229, claude-3-haiku-20240307, claude-3-5-sonnet-20240620)
- llamacpp
- nvidia(meta/llama3-70b-instruct, more)
- tongyi(qwen-turbo, qwen-plus, qwen-max, more)
- moonshot(moonshot-v1-8k, moonshot-v1-32k, moonshot-v1-128k)
-
2024-07-03 update langchain to
0.2.6version and addmoonshotAPI support -
2024-06-30 add
Go Codegraph -
2024-06-27 add
nvidia/tongyiAPI support -
2024-06-19 add
llamacppAPI support, improve thesettingslist in the sidebar and add upload model function forllamacpp, addprompt templatessetting -
2024-06-15 add
anthropicAPI support, refactor some functions, and fix chat show messages -
2024-06-12 add
zhipuaiAPI support -
2024-06-10 Convert
flasktofastapiand addlocalaiAPI support -
2024-06-07 Add
rr:option and useFlashRankfor the search -
2024-06-05 Upgrade
langchaintov0.2and addollama embeddings -
2024-05-26 Release v2.0.1: Refactoring to replace
Streamlitfontend withSvelteto improve the performance.
- This is a test project to validate the feasibility of a fully local solution for question answering using LLMs and Vector embeddings. It is not production ready, and it is not meant to be used in production.
Do not use models for analyzing your critical or production data!!Do not use models for analyzing customer data to ensure data privacy and security!!Do not use models for analyzing you private/sensitivity code respository!!
To deploy QA-Pilot, you can follow the below steps:
- Clone the QA-Pilot repository:
git clone https://github.com/reid41/QA-Pilot.git
cd QA-Pilot- Install conda for virtual environment management. Create and activate a new virtual environment.
conda create -n QA-Pilot python=3.10.14
conda activate QA-Pilot- Install the required dependencies:
pip install -r requirements.txt-
Install the pytorch with cuda pytorch
-
Setup providers
- For setup ollama website and ollama github to manage the local LLM. e.g.
ollama pull <model_name>
ollama list- For setup localAI and LocalAI github to manage the local LLM, set the localAI
base_urlin config/config.ini. e.g.
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest-aio-cpu
# Do you have a Nvidia GPUs? Use this instead
# CUDA 11
# docker run -p 8080:8080 --gpus all --name local-ai -ti localai/localai:latest-aio-gpu-nvidia-cuda-11
# CUDA 12
# docker run -p 8080:8080 --gpus all --name local-ai -ti localai/localai:latest-aio-gpu-nvidia-cuda-12
# quick check the service with http://<localAI host>:8080/
# quick check the models with http://<localAI host>:8080/models/-
For setup llamacpp with llama-cpp-python
- upload the model to
llamacpp_modelsdir or upload from thellamacpp modelsunder theSettings - set the model in
llamacpp_llm_modelssection inconfig/config.ini
- upload the model to
-
For setup API key in
.env- OpenAI: OPENAI_API_KEY='<openai_api_key,>'
- MistralAI: MISTRAL_API_KEY='<mistralai_api_key>'
- ZhipuAI: ZHIPUAI_API_KEY='<zhipuai_api_key,>'
- Anthropic: ANTHROPIC_API_KEY='<anthropic_api_key>'
- Nvidia: NVIDIA_API_KEY='<nvidia_api_key>'
- TongYi: DASHSCOPE_API_KEY='<tongyi_api_key>'
- Moonshot: MOONSHOT_API_KEY='<moonshot_api_key>'
-
For
Go codegraph, make sure setup GO env, compile go file and test
go build -o parser parser.go
# test
./parser /path/test.go- Set the related parameters in
config/config.ini, e.g.model provider,model,variable,Ollama API urland setup the Postgresql env
# create the db, e.g.
CREATE DATABASE qa_pilot_chatsession_db;
CREATE USER qa_pilot_user WITH ENCRYPTED PASSWORD 'qa_pilot_p';
GRANT ALL PRIVILEGES ON DATABASE qa_pilot_chatsession_db TO qa_pilot_user;
# set the connection
cat config/config.ini
[database]
db_name = qa_pilot_chatsession_db
db_user = qa_pilot_user
db_password = qa_pilot_p
db_host = localhost
db_port = 5432
# set the arg in script and test connection
python check_postgresql_connection.py- Download and install node.js and Set up the fontend env in one terminal
# make sure the backend server host ip is correct, localhost is by default
cat svelte-app/src/config.js
export const API_BASE_URL = 'http://localhost:5000';
# install deps
cd svelte-app
npm install
npm run dev- Run the backend QA-Pilot in another terminal:
python qa_pilot_run.py- Do not use url and upload at the same time.
- The remove button cannot really remove the local chromadb, need to remove it manually when stop it.
- Switch to
New Source Buttonto add a new project - Use
rsd:to start the input and get the source document - Use
rr:to start the input and use theFlashrankRerankfor the search - Click
Open Code GraphinQA-Pilotto view the code(make sure the the already in the project session and loaded before click), curretly supportpythonandgo
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for QA-Pilot
Similar Open Source Tools
QA-Pilot
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository. It allows users to chat with GitHub public repositories using a git clone approach, store chat history, configure settings easily, manage multiple chat sessions, and quickly locate sessions with a search function. The tool integrates with `codegraph` to view Python files and supports various LLM models such as ollama, openai, mistralai, and localai. The project is continuously updated with new features and improvements, such as converting from `flask` to `fastapi`, adding `localai` API support, and upgrading dependencies like `langchain` and `Streamlit` to enhance performance.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.
shortest
Shortest is a project for local development that helps set up environment variables and services for a web application. It provides a guide for setting up Node.js and pnpm dependencies, configuring services like Clerk, Vercel Postgres, Anthropic, Stripe, and GitHub OAuth, and running the application and tests locally.

gcop
GCOP (Git Copilot) is an AI-powered Git assistant that automates commit message generation, enhances Git workflow, and offers 20+ smart commands. It provides intelligent commit crafting, customizable commit templates, smart learning capabilities, and a seamless developer experience. Users can generate AI commit messages, add all changes with AI-generated messages, undo commits while keeping changes staged, and push changes to the current branch. GCOP offers configuration options for AI models and provides detailed documentation, contribution guidelines, and a changelog. The tool is designed to make version control easier and more efficient for developers.
Flowise
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.

comp
Comp AI is an open-source compliance automation platform designed to assist companies in achieving compliance with standards like SOC 2, ISO 27001, and GDPR. It transforms compliance into an engineering problem solved through code, automating evidence collection, policy management, and control implementation while maintaining data and infrastructure control.
UCAgent
UCAgent is an AI-powered automated UT verification agent for chip design. It automates chip verification workflow, supports functional and code coverage analysis, ensures consistency among documentation, code, and reports, and collaborates with mainstream Code Agents via MCP protocol. It offers three intelligent interaction modes and requires Python 3.11+, Linux/macOS OS, 4GB+ memory, and access to an AI model API. Users can clone the repository, install dependencies, configure qwen, and start verification. UCAgent supports various verification quality improvement options and basic operations through TUI shortcuts and stage color indicators. It also provides documentation build and preview using MkDocs, PDF manual build using Pandoc + XeLaTeX, and resources for further help and contribution.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.
cursor-tools
cursor-tools is a CLI tool designed to enhance AI agents with advanced skills, such as web search, repository context, documentation generation, GitHub integration, Xcode tools, and browser automation. It provides features like Perplexity for web search, Gemini 2.0 for codebase context, and Stagehand for browser operations. The tool requires API keys for Perplexity AI and Google Gemini, and supports global installation for system-wide access. It offers various commands for different tasks and integrates with Cursor Composer for AI agent usage.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.
mcpd
mcpd is a tool developed by Mozilla AI to declaratively manage Model Context Protocol (MCP) servers, enabling consistent interface for defining and running tools across different environments. It bridges the gap between local development and enterprise deployment by providing secure secrets management, declarative configuration, and seamless environment promotion. mcpd simplifies the developer experience by offering zero-config tool setup, language-agnostic tooling, version-controlled configuration files, enterprise-ready secrets management, and smooth transition from local to production environments.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, offers quick setup for conversational service robots, integrates diverse knowledge bases, provides flexible configuration options, and features an attractive user interface.
elyra
Elyra is a set of AI-centric extensions to JupyterLab Notebooks that includes features like Visual Pipeline Editor, running notebooks/scripts as batch jobs, reusable code snippets, hybrid runtime support, script editors with execution capabilities, debugger, version control using Git, and more. It provides a comprehensive environment for data scientists and AI practitioners to develop, test, and deploy machine learning models and workflows efficiently.
oxy
Oxy is an open-source framework for building comprehensive agentic analytics systems grounded in deterministic execution principles. Written in Rust and declarative by design, Oxy provides the foundational components needed to transform AI-driven data analysis into reliable, production-ready systems through structured primitives, semantic understanding, and predictable execution.
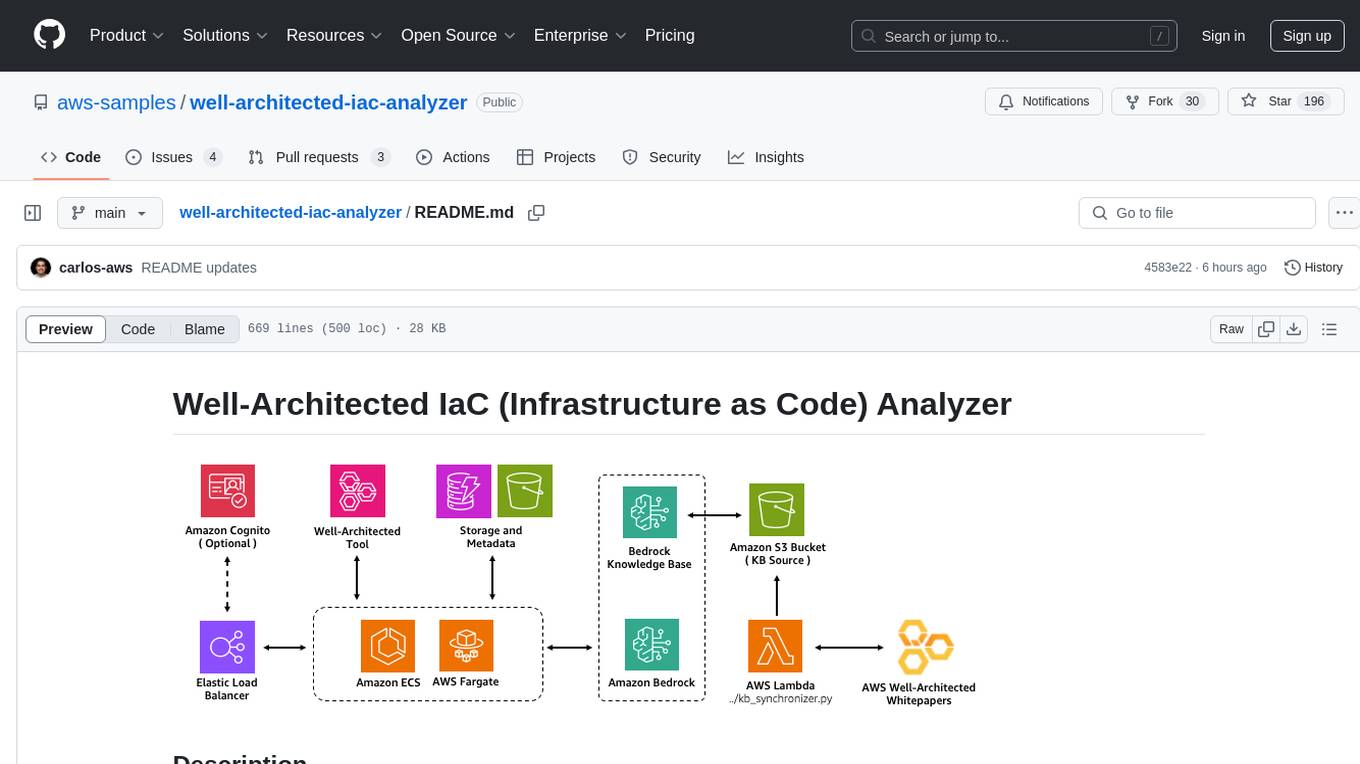
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.
For similar tasks
QA-Pilot
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository. It allows users to chat with GitHub public repositories using a git clone approach, store chat history, configure settings easily, manage multiple chat sessions, and quickly locate sessions with a search function. The tool integrates with `codegraph` to view Python files and supports various LLM models such as ollama, openai, mistralai, and localai. The project is continuously updated with new features and improvements, such as converting from `flask` to `fastapi`, adding `localai` API support, and upgrading dependencies like `langchain` and `Streamlit` to enhance performance.
Forza-Mods-AIO
Forza Mods AIO is a free and open-source tool that enhances the gaming experience in Forza Horizon 4 and 5. It offers a range of time-saving and quality-of-life features, making gameplay more enjoyable and efficient. The tool is designed to streamline various aspects of the game, improving user satisfaction and overall enjoyment.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
MaterialSearch
MaterialSearch is a tool for searching local images and videos using natural language. It provides functionalities such as text search for images, image search for images, text search for videos (providing matching video clips), image search for videos (searching for the segment in a video through a screenshot), image-text similarity calculation, and Pexels video search. The tool can be deployed through the source code or Docker image, and it supports GPU acceleration. Users can configure the tool through environment variables or a .env file. The tool is still under development, and configurations may change frequently. Users can report issues or suggest improvements through issues or pull requests.
tenere
Tenere is a TUI interface for Language Model Libraries (LLMs) written in Rust. It provides syntax highlighting, chat history, saving chats to files, Vim keybindings, copying text from/to clipboard, and supports multiple backends. Users can configure Tenere using a TOML configuration file, set key bindings, and use different LLMs such as ChatGPT, llama.cpp, and ollama. Tenere offers default key bindings for global and prompt modes, with features like starting a new chat, saving chats, scrolling, showing chat history, and quitting the app. Users can interact with the prompt in different modes like Normal, Visual, and Insert, with various key bindings for navigation, editing, and text manipulation.
openkore
OpenKore is a custom client and intelligent automated assistant for Ragnarok Online. It is a free, open source, and cross-platform program (Linux, Windows, and MacOS are supported). To run OpenKore, you need to download and extract it or clone the repository using Git. Configure OpenKore according to the documentation and run openkore.pl to start. The tool provides a FAQ section for troubleshooting, guidelines for reporting issues, and information about botting status on official servers. OpenKore is developed by a global team, and contributions are welcome through pull requests. Various community resources are available for support and communication. Users are advised to comply with the GNU General Public License when using and distributing the software.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.