
rag-gpt
RAG-GPT, leveraging LLM and RAG technology, learns from user-customized knowledge bases to provide contextually relevant answers for a wide range of queries, ensuring rapid and accurate information retrieval.
Stars: 228
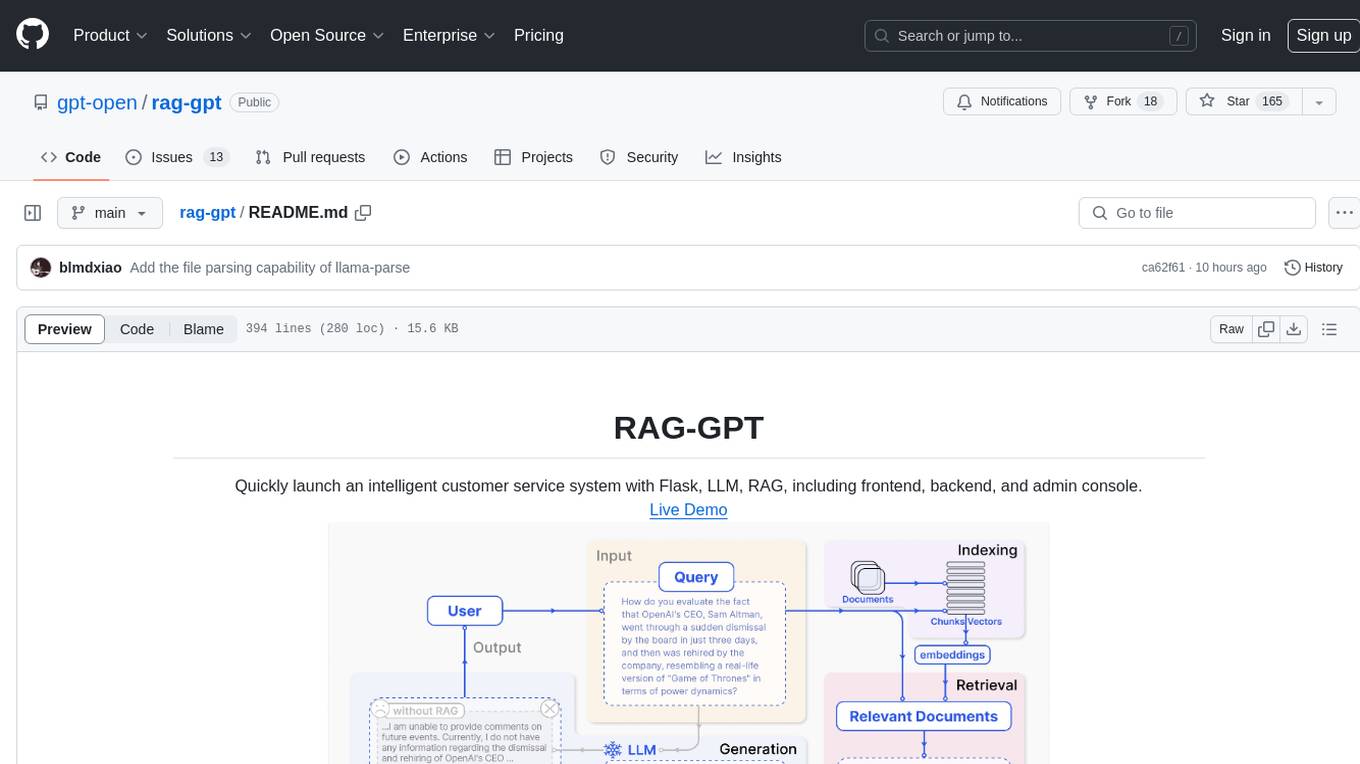
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, offers quick setup for conversational service robots, integrates diverse knowledge bases, provides flexible configuration options, and features an attractive user interface.
README:
Live Demo

- Features
- Online Retrieval Architecture
- Deploy the RAG-GPT Service
- Configure the admin console
- The frontend of admin console and chatbot
- Built-in LLM Support: Support cloud-based LLMs and local LLMs.
- Quick Setup: Enables deployment of production-level conversational service robots within just five minutes.
- Diverse Knowledge Base Integration: Supports multiple types of knowledge bases, including websites, isolated URLs, and local files.
- Flexible Configuration: Offers a user-friendly backend equipped with customizable settings for streamlined management.
- Attractive UI: Features a customizable and visually appealing user interface.

Clone the repository:
git clone https://github.com/open-kf/rag-gpt.git && cd rag-gptBefore starting the RAG-GPT service, you need to modify the related configurations for the program to initialize correctly.
cp env_of_openai .envThe variables in .env
LLM_NAME="OpenAI"
OPENAI_API_KEY="xxxx"
GPT_MODEL_NAME="gpt-3.5-turbo"
MIN_RELEVANCE_SCORE=0.4
BOT_TOPIC="xxxx"
URL_PREFIX="http://127.0.0.1:7000/"
USE_PREPROCESS_QUERY=1
USE_RERANKING=1
USE_DEBUG=0
USE_LLAMA_PARSE=0
LLAMA_CLOUD_API_KEY="xxxx"
USE_GPT4O=0- Don't modify
LLM_NAME - Modify the
OPENAI_API_KEYwith your own key. Please log in to the OpenAI website to view your API Key. - Update the
GPT_MODEL_NAMEsetting, replacinggpt-3.5-turbowithgpt-4-turboorgpt-4oif you want to use GPT-4. - Change
BOT_TOPICto reflect your Bot's name. This is very important, as it will be used inPrompt Construction. Please try to use a concise and clear word, such asOpenIM,LangChain. - Adjust
URL_PREFIXto match your website's domain. This is mainly for generating accessible URL links for uploaded local files. Such ashttp://127.0.0.1:7000/web/download_dir/2024_05_20/d3a01d6a-90cd-4c2a-b926-9cda12466caf/openssl-cookbook.pdf. - Set
USE_LLAMA_PARSEto 1 if you want to useLlamaParse. - Modify the
LLAMA_CLOUD_API_KEYwith your own key. Please log in to the LLamaCloud website to view your API Key. - Set
USE_GPT4Oto 1 if you want to useGPT-4omode. - For more information about the meanings and usages of constants, you can check under the
server/constantdirectory.
If you cannot use OpenAI's API services, consider using ZhipuAI as an alternative.
cp env_of_zhipuai .envThe variables in .env
LLM_NAME="ZhipuAI"
ZHIPUAI_API_KEY="xxxx"
GLM_MODEL_NAME="glm-4-air"
MIN_RELEVANCE_SCORE=0.4
BOT_TOPIC="xxxx"
URL_PREFIX="http://127.0.0.1:7000/"
USE_PREPROCESS_QUERY=1
USE_RERANKING=1
USE_DEBUG=0
USE_LLAMA_PARSE=0
LLAMA_CLOUD_API_KEY="xxxx"- Don't modify
LLM_NAME - Modify the
ZHIPUAI_API_KEYwith your own key. Please log in to the ZhipuAI website to view your API Key. - Update the
GLM_MODEL_NAMEsetting, the model list is['glm-3-turbo', 'glm-4', 'glm-4-0520', 'glm-4-air', 'glm-4-airx', 'glm-4-flash']. - Change
BOT_TOPICto reflect your Bot's name. This is very important, as it will be used inPrompt Construction. Please try to use a concise and clear word, such asOpenIM,LangChain. - Adjust
URL_PREFIXto match your website's domain. This is mainly for generating accessible URL links for uploaded local files. Such ashttp://127.0.0.1:7000/web/download_dir/2024_05_20/d3a01d6a-90cd-4c2a-b926-9cda12466caf/openssl-cookbook.pdf. - Set
USE_LLAMA_PARSEto 1 if you want to useLlamaParse. - Modify the
LLAMA_CLOUD_API_KEYwith your own key. Please log in to the LLamaCloud website to view your API Key. - For more information about the meanings and usages of constants, you can check under the
server/constantdirectory.
If you cannot use OpenAI's API services, consider using DeepSeek as an alternative.
[!NOTE] DeepSeek does not provide an
Embedding API, so here we use ZhipuAI'sEmbedding API.
cp env_of_deepseek .envThe variables in .env
LLM_NAME="DeepSeek"
ZHIPUAI_API_KEY="xxxx"
DEEPSEEK_API_KEY="xxxx"
DEEPSEEK_MODEL_NAME="deepseek-chat"
MIN_RELEVANCE_SCORE=0.4
BOT_TOPIC="xxxx"
URL_PREFIX="http://127.0.0.1:7000/"
USE_PREPROCESS_QUERY=1
USE_RERANKING=1
USE_DEBUG=0
USE_LLAMA_PARSE=0
LLAMA_CLOUD_API_KEY="xxxx"- Don't modify
LLM_NAME - Modify the
ZHIPUAI_API_KEYwith your own key. Please log in to the ZhipuAI website to view your API Key. - Modify the
DEEPKSEEK_API_KEYwith your own key. Please log in to the DeepSeek website to view your API Key. - Update the
DEEPSEEK_MODEL_NAMEsetting if you want to use other models of DeepSeek. - Change
BOT_TOPICto reflect your Bot's name. This is very important, as it will be used inPrompt Construction. Please try to use a concise and clear word, such asOpenIM,LangChain. - Adjust
URL_PREFIXto match your website's domain. This is mainly for generating accessible URL links for uploaded local files. Such ashttp://127.0.0.1:7000/web/download_dir/2024_05_20/d3a01d6a-90cd-4c2a-b926-9cda12466caf/openssl-cookbook.pdf. - Set
USE_LLAMA_PARSEto 1 if you want to useLlamaParse. - Modify the
LLAMA_CLOUD_API_KEYwith your own key. Please log in to the LLamaCloud website to view your API Key. - For more information about the meanings and usages of constants, you can check under the
server/constantdirectory.
If you cannot use OpenAI's API services, consider using Moonshot as an alternative.
[!NOTE] Moonshot does not provide an
Embedding API, so here we use ZhipuAI'sEmbedding API.
cp env_of_moonshot .envThe variables in .env
LLM_NAME="Moonshot"
ZHIPUAI_API_KEY="xxxx"
MOONSHOT_API_KEY="xxxx"
MOONSHOT_MODEL_NAME="moonshot-v1-8k"
MIN_RELEVANCE_SCORE=0.4
BOT_TOPIC="xxxx"
URL_PREFIX="http://127.0.0.1:7000/"
USE_PREPROCESS_QUERY=1
USE_RERANKING=1
USE_DEBUG=0
USE_LLAMA_PARSE=0
LLAMA_CLOUD_API_KEY="xxxx"- Don't modify
LLM_NAME - Modify the
ZHIPUAI_API_KEYwith your own key. Please log in to the ZhipuAI website to view your API Key. - Modify the
MOONSHOT_API_KEYwith your own key. Please log in to the Moonshot website to view your API Key. - Update the
MOONSHOT_MODEL_NAMEsetting if you want to use other models of Moonshot. - Change
BOT_TOPICto reflect your Bot's name. This is very important, as it will be used inPrompt Construction. Please try to use a concise and clear word, such asOpenIM,LangChain. - Adjust
URL_PREFIXto match your website's domain. This is mainly for generating accessible URL links for uploaded local files. Such ashttp://127.0.0.1:7000/web/download_dir/2024_05_20/d3a01d6a-90cd-4c2a-b926-9cda12466caf/openssl-cookbook.pdf. - Set
USE_LLAMA_PARSEto 1 if you want to useLlamaParse. - Modify the
LLAMA_CLOUD_API_KEYwith your own key. Please log in to the LLamaCloud website to view your API Key. - For more information about the meanings and usages of constants, you can check under the
server/constantdirectory.
If your knowledge base involves sensitive information and you prefer not to use cloud-based LLMs, consider using Ollama to deploy large models locally.
[!NOTE] First, refer to ollama to Install Ollama, and download the embedding model
mxbai-embed-largeand the LLM model such asllama3.
cp env_of_ollama .envThe variables in .env
LLM_NAME="Ollama"
OLLAMA_MODEL_NAME="xxxx"
OLLAMA_BASE_URL="http://127.0.0.1:11434"
MIN_RELEVANCE_SCORE=0.4
BOT_TOPIC="xxxx"
URL_PREFIX="http://127.0.0.1:7000/"
USE_PREPROCESS_QUERY=1
USE_RERANKING=1
USE_DEBUG=0
USE_LLAMA_PARSE=0
LLAMA_CLOUD_API_KEY="xxxx"- Don't modify
LLM_NAME - Update the
OLLAMA_MODEL_NAMEsetting, select an appropriate model from ollama library. - If you have changed the default
IP:PORTwhen startingOllama, please updateOLLAMA_BASE_URL. Please pay special attention, only enter the IP (domain) and PORT here, without appending a URI. - Change
BOT_TOPICto reflect your Bot's name. This is very important, as it will be used inPrompt Construction. Please try to use a concise and clear word, such asOpenIM,LangChain. - Adjust
URL_PREFIXto match your website's domain. This is mainly for generating accessible URL links for uploaded local files. Such ashttp://127.0.0.1:7000/web/download_dir/2024_05_20/d3a01d6a-90cd-4c2a-b926-9cda12466caf/openssl-cookbook.pdf. - Set
USE_LLAMA_PARSEto 1 if you want to useLlamaParse. - Modify the
LLAMA_CLOUD_API_KEYwith your own key. Please log in to the LLamaCloud website to view your API Key. - For more information about the meanings and usages of constants, you can check under the
server/constantdirectory.
[!NOTE] When deploying with Docker, pay special attention to the host of URL_PREFIX in the
.envfile. If usingOllama, also pay special attention to the host of OLLAMA_BASE_URL in the.envfile. They need to use the actual IP address of the host machine.
docker-compose up --build[!NOTE] Please use Python version 3.10.x or above.
It is recommended to install Python-related dependencies in a Python virtual environment to avoid affecting dependencies of other projects.
If you have not yet created a virtual environment, you can create one with the following command:
python3 -m venv myenvAfter creation, activate the virtual environment:
source myenv/bin/activateOnce the virtual environment is activated, you can use pip to install the required dependencies.
pip install -r requirements.txtThe RAG-GPT service uses SQLite as its storage DB. Before starting the RAG-GPT service, you need to execute the following command to initialize the database and add the default configuration for admin console.
python3 create_sqlite_db.pyIf you have completed the steps above, you can try to start the RAG-GPT service by executing the following command.
- Start single process:
python3 rag_gpt_app.py- Start multiple processes:
sh start.sh[!NOTE]
- The service port for RAG-GPT is
7000. During the first test, please try not to change the port so that you can quickly experience the entire product process.- We recommend starting the RAG-GPT service using
start.shin multi-process mode for a smoother user experience.
Access the admin console through the link http://your-server-ip:7000/open-kf-admin/ to reach the login page. The default username and password are admin and open_kf_AIGC@2024 (can be checked in create_sqlite_db.py).

After logging in successfully, you will be able to see the configuration page of the admin console.

On the page http://your-server-ip:7000/open-kf-admin/#/, you can set the following configurations:
- Choose the LLM base, currently only the
gpt-3.5-turbooption is available, which will be gradually expanded. - Initial Messages
- Suggested Messages
- Message Placeholder
- Profile Picture (upload a picture)
- Display name
- Chat icon (upload a picture)
After submitting the website URL, once the server retrieves the list of all web page URLs via crawling, you can select the web page URLs you need as the knowledge base (all selected by default). The initial Status is Recorded.

You can actively refresh the page http://your-server-ip:7000/open-kf-admin/#/source in your browser to get the progress of web page URL processing. After the content of the web page URL has been crawled, and the Embedding calculation and storage are completed, you can see the corresponding Size in the admin console, and the Status will also be updated to Trained.

Clicking on a webpage's URL reveals how many sub-pages the webpage is divided into, and the text size of each sub-page.

Clicking on a sub-page allows you to view its full text content. This will be very helpful for verifying the effects during the experience testing process.

Collect the URLs of the required web pages. You can submit up to 10 web page URLs at a time, and these pages can be from different domains.

Upload the required local files. You can upload up to 10 files at a time, and each file cannot exceed 30MB. The following file types are currently supported: [".txt", ".md", ".pdf", ".epub", ".mobi", ".html", ".docx", ".pptx", ".xlsx", ".csv"].

After importing website data in the admin console, you can experience the chatbot service through the link http://your-server-ip:7000/open-kf-chatbot/.

Through the admin console link http://your-server-ip:7000/open-kf-admin/#/embed, you can see the detailed tutorial for configuring the iframe in your website.


Through the admin console link http://your-server-ip:7000/open-kf-admin/#/dashboard, you can view the historical request records of all users within a specified time range.

The RAG-GPT service integrates 2 frontend modules, and their source code information is as follows:
An intuitive web-based admin interface for Smart QA Service, offering comprehensive control over content, configuration, and user interactions. Enables effortless management of the knowledge base, real-time monitoring of queries and feedback, and continuous improvement based on user insights.
An HTML5 interface for Smart QA Service designed for easy integration into websites via iframe, providing users direct access to a tailored knowledge base without leaving the site, enhancing functionality and immediate query resolution.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rag-gpt
Similar Open Source Tools
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, offers quick setup for conversational service robots, integrates diverse knowledge bases, provides flexible configuration options, and features an attractive user interface.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.

AutoAgent
AutoAgent is a fully-automated and zero-code framework that enables users to create and deploy LLM agents through natural language alone. It is a top performer on the GAIA Benchmark, equipped with a native self-managing vector database, and allows for easy creation of tools, agents, and workflows without any coding. AutoAgent seamlessly integrates with a wide range of LLMs and supports both function-calling and ReAct interaction modes. It is designed to be dynamic, extensible, customized, and lightweight, serving as a personal AI assistant.
Groqqle
Groqqle 2.1 is a revolutionary, free AI web search and API that instantly returns ORIGINAL content derived from source articles, websites, videos, and even foreign language sources, for ANY target market of ANY reading comprehension level! It combines the power of large language models with advanced web and news search capabilities, offering a user-friendly web interface, a robust API, and now a powerful Groqqle_web_tool for seamless integration into your projects. Developers can instantly incorporate Groqqle into their applications, providing a powerful tool for content generation, research, and analysis across various domains and languages.
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.
infinite-image-browsing
Infinite Image Browsing (IIB) is a versatile tool that offers excellent performance in displaying images, supports image search and favorite functionalities, allows viewing images/videos with various features like full-screen preview and sending to other tabs, provides multiple usage methods including extension installation, standalone Python usage, and desktop application, supports TikTok-style view, walk mode for automatic loading of folders, preview based on file tree structure, image comparison, topic/tag analysis, smart file organization, multilingual support, privacy and security features, packaging/batch download, keyboard shortcuts, and AI integration. The tool also offers natural language categorization and search capabilities, with API endpoints for embedding, clustering, and prompt retrieval. It supports caching and incremental updates for efficient processing and offers various configuration options through environment variables.
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
NeoPass
NeoPass is a free Chrome extension designed for students taking tests on exam portals like Iamneo and Wildlife Ecology NPTEL. It provides features such as NPTEL integration, NeoExamShield bypass, AI chatbot with stealth mode, AI search answers/code, MCQ solving, tab switching bypass, pasting when restricted, and remote logout. Users can install the extension by following simple steps and use shortcuts for quick access to features. The tool is intended for educational purposes only and promotes academic integrity.

AmigaGPT
AmigaGPT is a versatile ChatGPT client for AmigaOS 3.x, 4.1, and MorphOS. It brings the capabilities of OpenAI’s GPT to Amiga systems, enabling text generation, question answering, and creative exploration. AmigaGPT can generate images using DALL-E, supports speech output, and seamlessly integrates with AmigaOS. Users can customize the UI, choose fonts and colors, and enjoy a native user experience. The tool requires specific system requirements and offers features like state-of-the-art language models, AI image generation, speech capability, and UI customization.
Backlog.md
Backlog.md is a Markdown-native Task Manager & Kanban visualizer for any Git repository. It turns any folder with a Git repo into a self-contained project board powered by plain Markdown files and a zero-config CLI. Features include managing tasks as plain .md files, private & offline usage, instant terminal Kanban visualization, board export, modern web interface, AI-ready CLI, rich query commands, cross-platform support, and MIT-licensed open-source. Users can create tasks, view board, assign tasks to AI, manage documentation, make decisions, and configure settings easily.
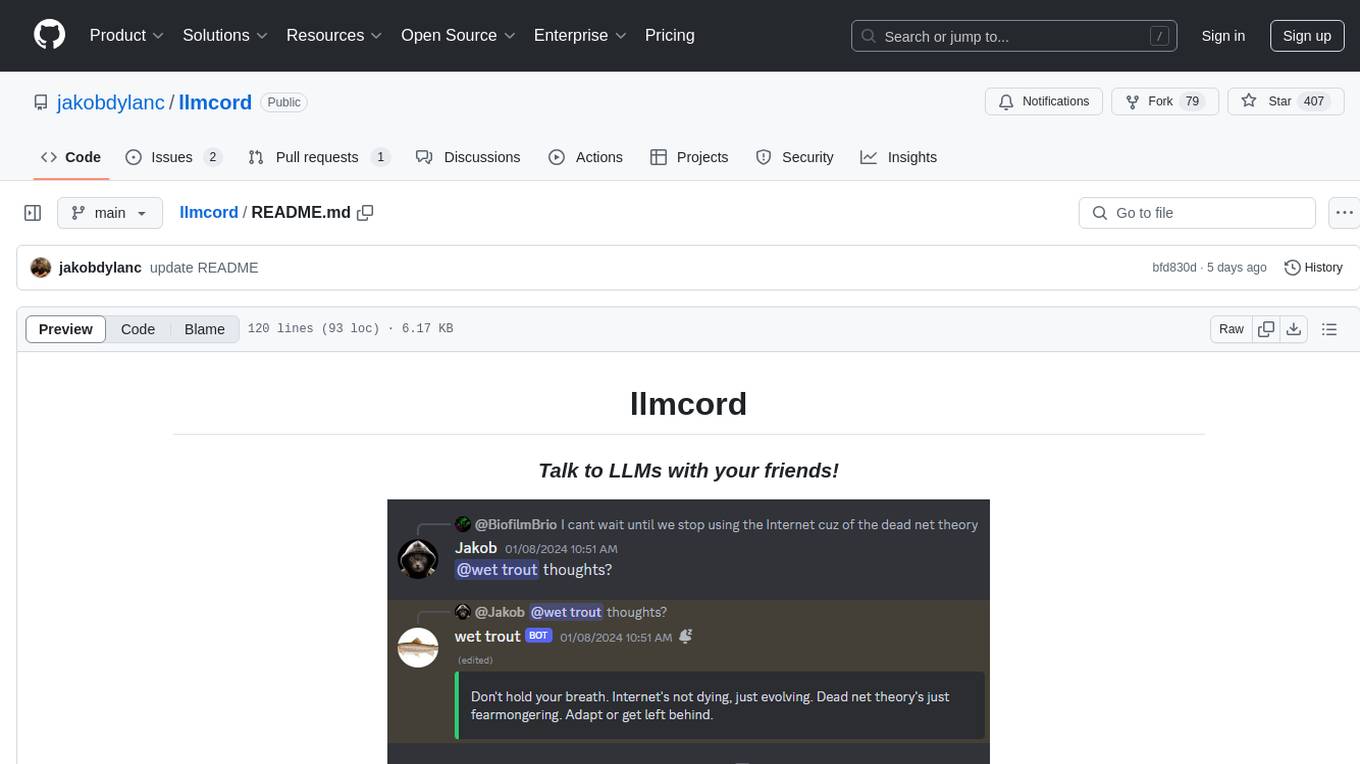
llmcord
llmcord is a Discord bot that transforms Discord into a collaborative LLM frontend, allowing users to interact with various LLM models. It features a reply-based chat system that enables branching conversations, supports remote and local LLM models, allows image and text file attachments, offers customizable personality settings, and provides streamed responses. The bot is fully asynchronous, efficient in managing message data, and offers hot reloading config. With just one Python file and around 200 lines of code, llmcord provides a seamless experience for engaging with LLMs on Discord.
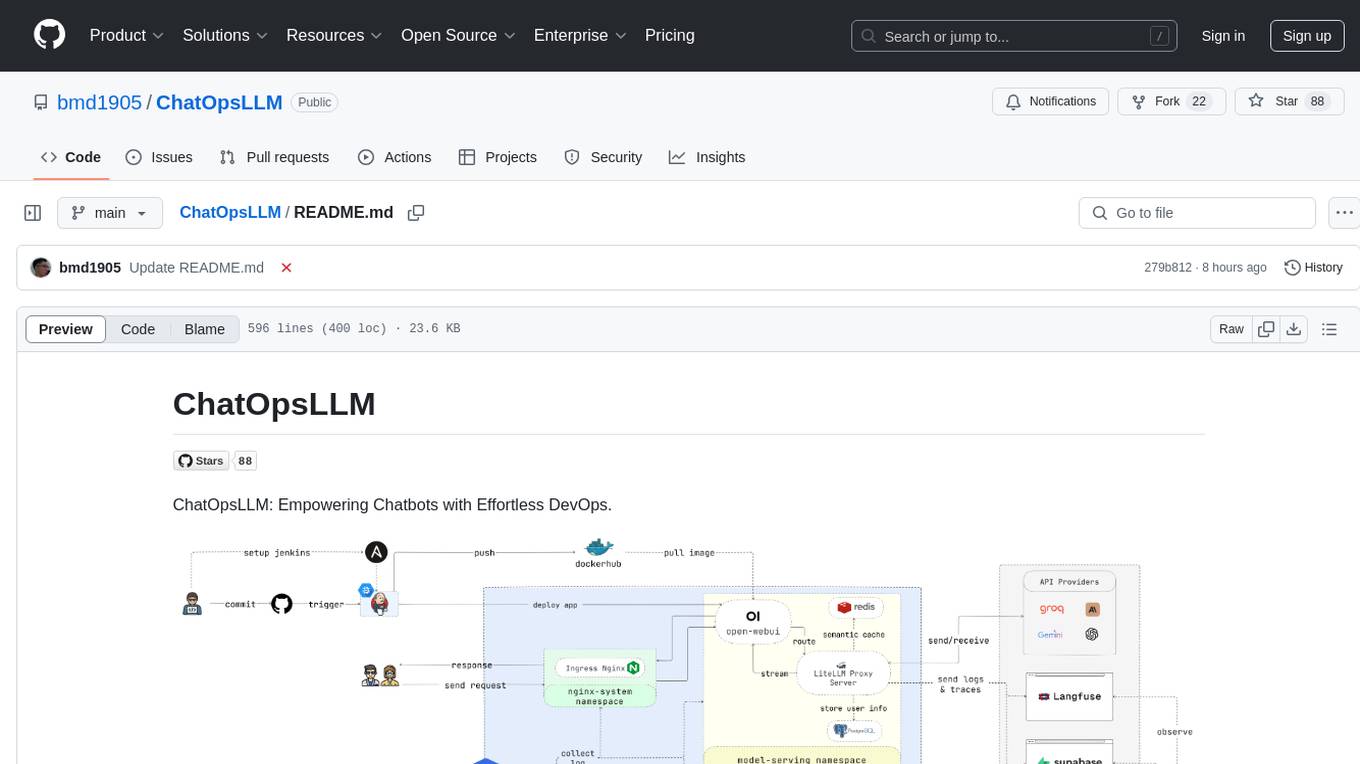
ChatOpsLLM
ChatOpsLLM is a project designed to empower chatbots with effortless DevOps capabilities. It provides an intuitive interface and streamlined workflows for managing and scaling language models. The project incorporates robust MLOps practices, including CI/CD pipelines with Jenkins and Ansible, monitoring with Prometheus and Grafana, and centralized logging with the ELK stack. Developers can find detailed documentation and instructions on the project's website.
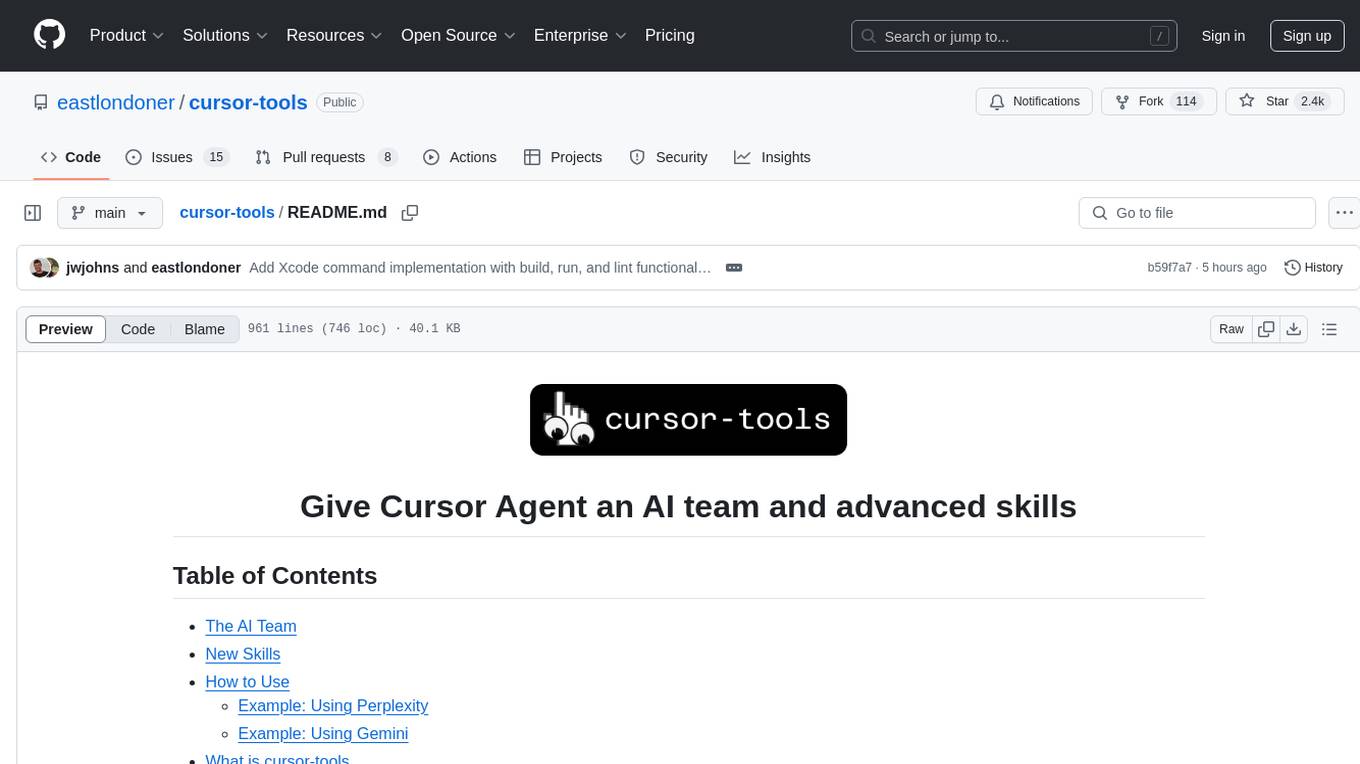
cursor-tools
cursor-tools is a CLI tool designed to enhance AI agents with advanced skills, such as web search, repository context, documentation generation, GitHub integration, Xcode tools, and browser automation. It provides features like Perplexity for web search, Gemini 2.0 for codebase context, and Stagehand for browser operations. The tool requires API keys for Perplexity AI and Google Gemini, and supports global installation for system-wide access. It offers various commands for different tasks and integrates with Cursor Composer for AI agent usage.

patchwork
PatchWork is an open-source framework designed for automating development tasks using large language models. It enables users to automate workflows such as PR reviews, bug fixing, security patching, and more through a self-hosted CLI agent and preferred LLMs. The framework consists of reusable atomic actions called Steps, customizable LLM prompts known as Prompt Templates, and LLM-assisted automations called Patchflows. Users can run Patchflows locally in their CLI/IDE or as part of CI/CD pipelines. PatchWork offers predefined patchflows like AutoFix, PRReview, GenerateREADME, DependencyUpgrade, and ResolveIssue, with the flexibility to create custom patchflows. Prompt templates are used to pass queries to LLMs and can be customized. Contributions to new patchflows, steps, and the core framework are encouraged, with chat assistants available to aid in the process. The roadmap includes expanding the patchflow library, introducing a debugger and validation module, supporting large-scale code embeddings, parallelization, fine-tuned models, and an open-source GUI. PatchWork is licensed under AGPL-3.0 terms, while custom patchflows and steps can be shared using the Apache-2.0 licensed patchwork template repository.
For similar tasks
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, offers quick setup for conversational service robots, integrates diverse knowledge bases, provides flexible configuration options, and features an attractive user interface.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.