
mcpd
Declaratively define and run required tools across environments, from local development to containerized cloud deployments.
Stars: 65
mcpd is a tool developed by Mozilla AI to declaratively manage Model Context Protocol (MCP) servers, enabling consistent interface for defining and running tools across different environments. It bridges the gap between local development and enterprise deployment by providing secure secrets management, declarative configuration, and seamless environment promotion. mcpd simplifies the developer experience by offering zero-config tool setup, language-agnostic tooling, version-controlled configuration files, enterprise-ready secrets management, and smooth transition from local to production environments.
README:
![]()
mcpd is a tool to declaratively manage Model Context Protocol (MCP) servers, providing a consistent interface to define and run tools across environments, from local development to containerized cloud deployments.
Built by Mozilla AI
Today, mcpd launches MCP servers as subprocesses using STDIO (Standard Input/Output) and acts as an HTTP proxy between agents and the tools they expose. This enables agent-compatible workflows with support for secrets, runtime arguments, and reproducible configurations, no matter where mcpd is running.
We're developing a Kubernetes operator, guided by our internal roadmap, to extend mcpd for deploying and managing MCP servers as long-lived services in production. It will use the same .mcpd.toml configuration and proxy model, making it easier to scale and manage lifecycles without changing the developer experience.
ML teams build agents that work perfectly locally. Operations teams get handed Python scripts and told "make this production-ready across dev/UAT/prod." The gap between local development and enterprise deployment kills AI initiatives.
mcpd solves this with declarative configuration, secure secrets management, and seamless environment promotion - all while keeping the developer experience simple.
Zero-Config Tool Setup
No cloning repos or installing language-specific dependencies. mcpd add and mcpd daemon handle everything.
Language-Agnostic Tooling
Use MCP servers written in Python, JavaScript, TypeScript via a unified HTTP API.
Declarative Configuration
Version-controlled .mcpd.toml files define your agent infrastructure. Reproducible, auditable, CI-friendly.
Enterprise-Ready Secrets
Separate project configuration from runtime variables, and export sanitized secrets templates. Never commit secrets to Git again.
Seamless Local-to-Prod
Same configuration works in development, CI, and cloud environments without modification.
| Development Workflow | Production Benefit |
|---|---|
mcpd daemon runs everything locally |
Same daemon runs in containers |
.mcpd.toml version-controlled configs |
Declarative infrastructure as code |
Local secrets in ~/.config/mcpd/
|
Secure secrets injection via control plane |
mcpd config export exports version-control safe snapshot of local configuration |
Sanitized secrets config and templates for CI/CD pipelines |
- Focus on Developer Experience via
mcpdCLI - Declarative configuration (
.mcpd.toml) to define required servers/tools - Run and manage language-agnostic MCP servers
- Secure execution context for secrets and runtime args
- Smooth dev-to-prod transition via the
mcpddaemon - Rich CLI and SDK tooling, see supported languages below:
Add the Mozilla.ai tap:
brew tap mozilla-ai/tapThen install mcpd:
brew install mcpdOr install directly from the cask:
brew install --cask mozilla-ai/tap/mcpdOfficial releases can be found on mcpd's GitHub releases page.
The following is an example of manually downloading and installing mcpd using curl and jq by running install_mcpd:
function install_mcpd() {
command -v curl >/dev/null || { echo "curl not found"; return 1; }
command -v jq >/dev/null || { echo "jq not found"; return 1; }
latest_version=$(curl -s https://api.github.com/repos/mozilla-ai/mcpd/releases/latest | jq -r .tag_name)
os=$(uname)
arch=$(uname -m)
zip_name="mcpd_${os}_${arch}.tar.gz"
url="https://github.com/mozilla-ai/mcpd/releases/download/${latest_version}/${zip_name}"
echo "Downloading: $url"
curl -sSL "$url" -o "$zip_name" || { echo "Download failed"; return 1; }
echo "Extracting: $zip_name"
tar -xzf "$zip_name" mcpd || { echo "Extraction failed"; return 1; }
echo "Installing to /usr/local/bin"
sudo mv mcpd /usr/local/bin/mcpd && sudo chmod +x /usr/local/bin/mcpd || { echo "Install failed"; return 1; }
rm -f "$zip_name"
echo "mcpd installed successfully"
}# Clone and build
git clone [email protected]:mozilla-ai/mcpd.git
cd mcpd
make build
sudo make install # Install mcpd 'globally' to /usr/local/bin# Initialize a new project
mcpd init
# Add an MCP server
mcpd add time
# Set the local timezone for the MCP server
mcpd config args set time -- --local-timezone=Europe/London
# Start the daemon in dev mode with debug logging
mcpd daemon --dev --log-level=DEBUG --log-path=$(pwd)/mcpd.log
# You can tail the log file
tail -f mcpd.logAPI docs will be available at http://localhost:8090/docs.
mcpd is runtime-flexible and infrastructure-agnostic:
- ⚙️ Works in any container or host with
uvandnpx - ☁️ Multi-cloud ready (AWS, GCP, Azure, on-prem)
- ♻️ Low resource overhead via efficient server management
Full documentation: https://mozilla-ai.github.io/mcpd/
SDKs available:
| Language | Repository | Status |
|---|---|---|
| Python | mcpd-sdk-python | ✅ |
| JavaScript | Coming soon | 🟡 |
Build local code:
make buildRun tests:
make testValidate Mozilla AI registry (when modifying registry files):
make validate-registryRun the local documentation site (requires uv), dynamically generates command line documentation:
make docsPlease see our Contributing to mcpd guide for more information.
Licensed under the Apache License 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mcpd
Similar Open Source Tools
mcpd
mcpd is a tool developed by Mozilla AI to declaratively manage Model Context Protocol (MCP) servers, enabling consistent interface for defining and running tools across different environments. It bridges the gap between local development and enterprise deployment by providing secure secrets management, declarative configuration, and seamless environment promotion. mcpd simplifies the developer experience by offering zero-config tool setup, language-agnostic tooling, version-controlled configuration files, enterprise-ready secrets management, and smooth transition from local to production environments.
director
Director is a context infrastructure tool for AI agents that simplifies managing MCP servers, prompts, and configurations by packaging them into portable workspaces accessible through a single endpoint. It allows users to define context workspaces once and share them across different AI clients, enabling seamless collaboration, instant context switching, and secure isolation of untrusted servers without cloud dependencies or API keys. Director offers features like workspaces, universal portability, local-first architecture, sandboxing, smart filtering, unified OAuth, observability, multiple interfaces, and compatibility with all MCP clients and servers.

pentagi
PentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. It is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. The tool provides secure and isolated operations in a sandboxed Docker environment, fully autonomous AI-powered agent for penetration testing steps, a suite of 20+ professional security tools, smart memory system for storing research results, web intelligence for gathering information, integration with external search systems, team delegation system, comprehensive monitoring and reporting, modern interface, API integration, persistent storage, scalable architecture, self-hosted solution, flexible authentication, and quick deployment through Docker Compose.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.
AirCasting
AirCasting is a platform for gathering, visualizing, and sharing environmental data. It aims to provide a central hub for environmental data, making it easier for people to access and use this information to make informed decisions about their environment.
UCAgent
UCAgent is an AI-powered automated UT verification agent for chip design. It automates chip verification workflow, supports functional and code coverage analysis, ensures consistency among documentation, code, and reports, and collaborates with mainstream Code Agents via MCP protocol. It offers three intelligent interaction modes and requires Python 3.11+, Linux/macOS OS, 4GB+ memory, and access to an AI model API. Users can clone the repository, install dependencies, configure qwen, and start verification. UCAgent supports various verification quality improvement options and basic operations through TUI shortcuts and stage color indicators. It also provides documentation build and preview using MkDocs, PDF manual build using Pandoc + XeLaTeX, and resources for further help and contribution.

metis
Metis is an open-source, AI-driven tool for deep security code review, created by Arm's Product Security Team. It helps engineers detect subtle vulnerabilities, improve secure coding practices, and reduce review fatigue. Metis uses LLMs for semantic understanding and reasoning, RAG for context-aware reviews, and supports multiple languages and vector store backends. It provides a plugin-friendly and extensible architecture, named after the Greek goddess of wisdom, Metis. The tool is designed for large, complex, or legacy codebases where traditional tooling falls short.
fast-mcp
Fast MCP is a Ruby gem that simplifies the integration of AI models with your Ruby applications. It provides a clean implementation of the Model Context Protocol, eliminating complex communication protocols, integration challenges, and compatibility issues. With Fast MCP, you can easily connect AI models to your servers, share data resources, choose from multiple transports, integrate with frameworks like Rails and Sinatra, and secure your AI-powered endpoints. The gem also offers real-time updates and authentication support, making AI integration a seamless experience for developers.
steel-browser
Steel is an open-source browser API designed for AI agents and applications, simplifying the process of building live web agents and browser automation tools. It serves as a core building block for a production-ready, containerized browser sandbox with features like stealth capabilities, text-to-markdown session management, UI for session viewing/debugging, and full browser control through popular automation frameworks. Steel allows users to control, run, and manage a production-ready browser environment via a REST API, offering features such as full browser control, session management, proxy support, extension support, debugging tools, anti-detection mechanisms, resource management, and various browser tools. It aims to streamline complex browsing tasks programmatically, enabling users to focus on their AI applications while Steel handles the underlying complexity.
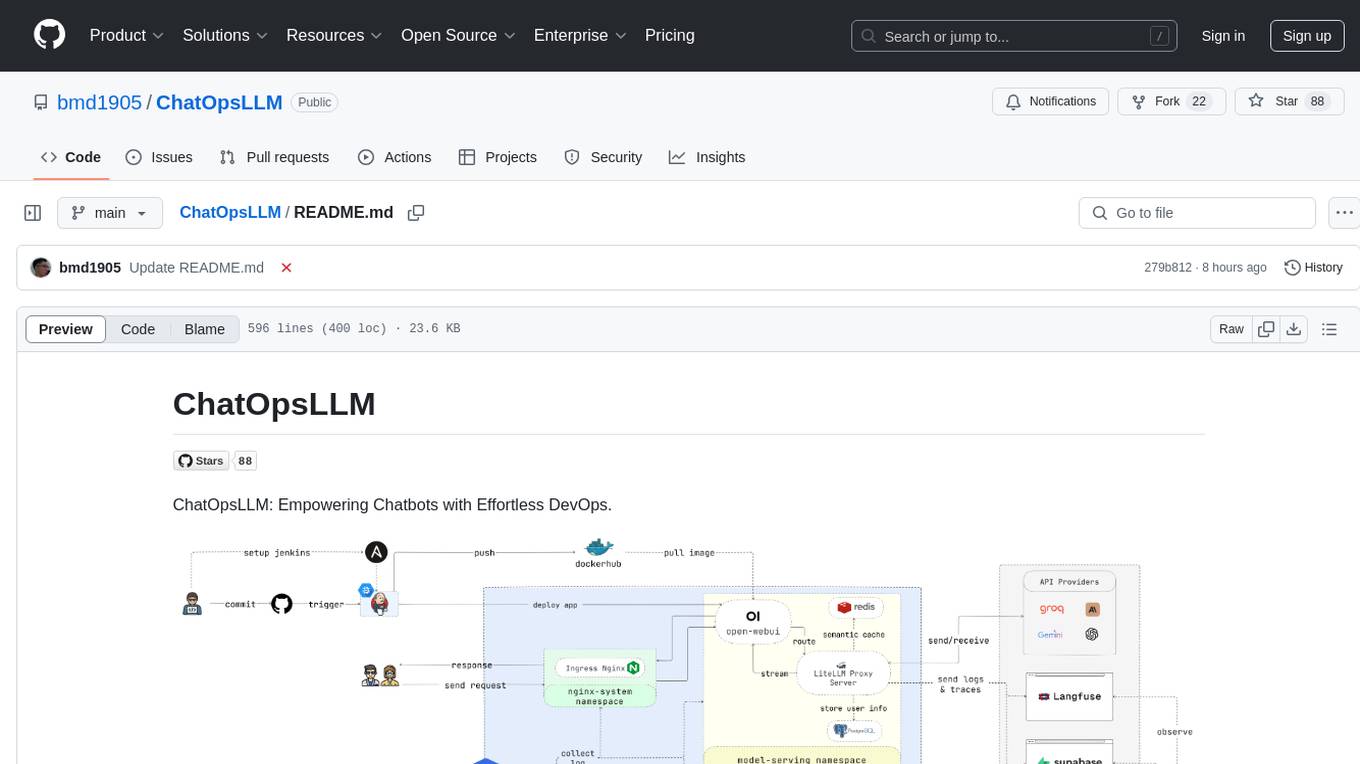
ChatOpsLLM
ChatOpsLLM is a project designed to empower chatbots with effortless DevOps capabilities. It provides an intuitive interface and streamlined workflows for managing and scaling language models. The project incorporates robust MLOps practices, including CI/CD pipelines with Jenkins and Ansible, monitoring with Prometheus and Grafana, and centralized logging with the ELK stack. Developers can find detailed documentation and instructions on the project's website.
forge
Forge is a powerful open-source tool for building modern web applications. It provides a simple and intuitive interface for developers to quickly scaffold and deploy projects. With Forge, you can easily create custom components, manage dependencies, and streamline your development workflow. Whether you are a beginner or an experienced developer, Forge offers a flexible and efficient solution for your web development needs.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.
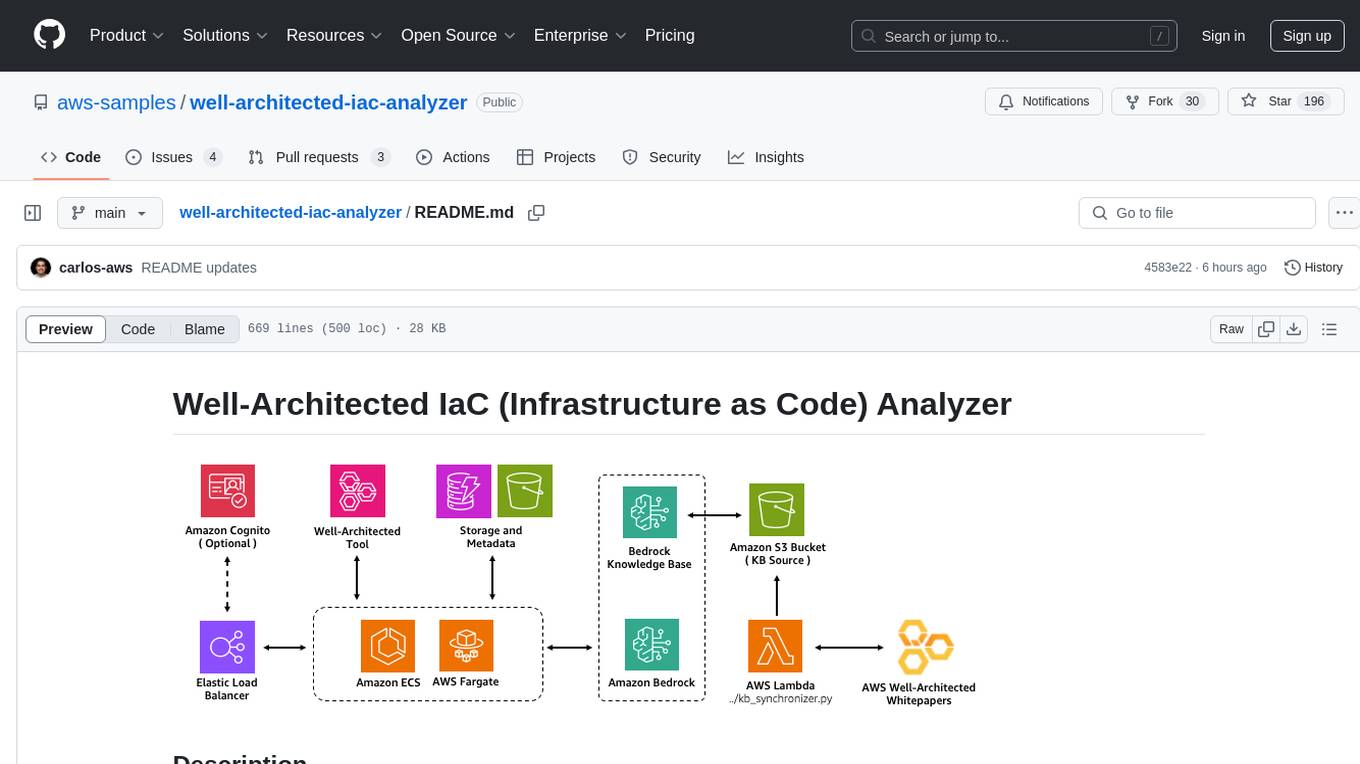
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.
supabase-mcp
Supabase MCP Server standardizes how Large Language Models (LLMs) interact with Supabase, enabling AI assistants to manage tables, fetch config, and query data. It provides tools for project management, database operations, project configuration, branching (experimental), and development tools. The server is pre-1.0, so expect some breaking changes between versions.
AutoDocs
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.
BuildCLI
BuildCLI is a command-line interface (CLI) tool designed for managing and automating common tasks in Java project development. It simplifies the development process by allowing users to create, compile, manage dependencies, run projects, generate documentation, manage configuration profiles, dockerize projects, integrate CI/CD tools, and generate structured changelogs. The tool aims to enhance productivity and streamline Java project management by providing a range of functionalities accessible directly from the terminal.
For similar tasks
mcpd
mcpd is a tool developed by Mozilla AI to declaratively manage Model Context Protocol (MCP) servers, enabling consistent interface for defining and running tools across different environments. It bridges the gap between local development and enterprise deployment by providing secure secrets management, declarative configuration, and seamless environment promotion. mcpd simplifies the developer experience by offering zero-config tool setup, language-agnostic tooling, version-controlled configuration files, enterprise-ready secrets management, and smooth transition from local to production environments.
For similar jobs

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.