
MaterialSearch
AI语义搜索本地素材。以图搜图、查找本地素材、根据文字描述匹配画面、视频帧搜索、根据画面描述搜索视频。Semantic search. Search local photos and videos through natural language.
Stars: 1359
MaterialSearch is a tool for searching local images and videos using natural language. It provides functionalities such as text search for images, image search for images, text search for videos (providing matching video clips), image search for videos (searching for the segment in a video through a screenshot), image-text similarity calculation, and Pexels video search. The tool can be deployed through the source code or Docker image, and it supports GPU acceleration. Users can configure the tool through environment variables or a .env file. The tool is still under development, and configurations may change frequently. Users can report issues or suggest improvements through issues or pull requests.
README:
扫描本地的图片以及视频,并且可以用自然语言进行查找。
在线Demo:https://chn-lee-yumi.github.io/MaterialSearchWebDemo/
- 文字搜图
- 以图搜图
- 文字搜视频(会给出符合描述的视频片段)
- 以图搜视频(通过视频截图搜索所在片段)
- 图文相似度计算(只是给出一个分数,用处不大)
在这里下载整合包MaterialSearchWindows.7z或MaterialSearchWindowsLarge.7z,解压后请阅读里面的使用说明.txt。整合包会自动选择独显或核显进行加速。
MaterialSearchWindows.7z整合包自带OFA-Sys/chinese-clip-vit-base-patch16模型。MaterialSearchWindowsLarge.7z整合包则是OFA-Sys/chinese-clip-vit-large-patch14-336px模型。
一般而言OFA-Sys/chinese-clip-vit-base-patch16模型已经足够日常使用,如果效果不佳并且显卡显存足够大(8G以上),可以尝试MaterialSearchWindowsLarge.7z整合包。
首先安装Python环境,然后下载本仓库代码。
注意,首次运行会自动下载模型。下载速度可能比较慢,请耐心等待。如果网络不好,模型可能会下载失败,这个时候重新执行程序即可。
- 首次使用前需要安装依赖:
pip install -U -r requirements.txt。Windows系统使用requirements_windows.txt,或双击install.bat。 - 启动程序:
python main.py,Windows系统可以双击run.bat。
如遇到requirements.txt版本依赖问题(比如某个库版本过新会导致运行报错),请提issue反馈,我会添加版本范围限制。
如果想使用"下载视频片段"的功能,需要安装ffmpeg。如果是Windows系统,记得把ffmpeg.exe所在目录加入环境变量PATH,可以参考:Bing搜索。
支持amd64和arm64,打包了默认模型(OFA-Sys/chinese-clip-vit-base-patch16)并且支持GPU(仅amd64架构的镜像支持)。
镜像地址:
- yumilee/materialsearch (DockerHub)
- registry.cn-hongkong.aliyuncs.com/chn-lee-yumi/materialsearch (阿里云,推荐中国大陆用户使用)
启动镜像前,你需要准备:
- 数据库的保存路径
- 你的扫描路径以及打算挂载到容器内的哪个路径
- 你可以通过修改
docker-compose.yml里面的environment和volumes来进行配置。 - 如果打算使用GPU,则需要取消注释
docker-compose.yml里面的对应部分
具体请参考docker-compose.yml,已经写了详细注释。
最后执行docker-compose up -d启动容器即可。
注意:
- 不推荐对容器设置内存限制,否则可能会出现奇怪的问题。比如这个issue。
- 容器默认设置了环境变量
TRANSFORMERS_OFFLINE=1,也就是说运行时不会连接huggingface检查模型版本。如果你想更换容器内默认的模型,需要修改.env覆盖该环境变量为TRANSFORMERS_OFFLINE=0。
所有配置都在config.py文件中,里面已经写了详细的注释。
建议通过环境变量或在项目根目录创建.env文件修改配置。如果没有配置对应的变量,则会使用config.py中的默认值。例如os.getenv('HOST', '127.0.0.1'),如果没有配置HOST变量,则HOST默认为127.0.0.1。
.env文件配置示例:
ASSETS_PATH=C:/Users/Administrator/Pictures,C:/Users/Administrator/Videos
SKIP_PATH=C:/Users/Administrator/AppData
如果你发现某些格式的图片或视频没有被扫描到,可以尝试在IMAGE_EXTENSIONS和VIDEO_EXTENSIONS增加对应的后缀。如果你发现一些支持的后缀没有被添加到代码中,欢迎提issue或pr增加。
小图片没被扫描到的话,可以调低IMAGE_MIN_WIDTH和IMAGE_MIN_HEIGHT重试。
如果想使用代理,可以添加http_proxy和https_proxy,如:
http_proxy=http://127.0.0.1:7070
https_proxy=http://127.0.0.1:7070
注意:ASSETS_PATH不推荐设置为远程目录(如SMB/NFS),可能会导致扫描速度变慢。
如遇问题,请先仔细阅读本文档。如果找不到答案,请在issue中搜索是否有类似问题。如果没有,可以新开一个issue,详细说明你遇到的问题,加上你做过的尝试和思考,附上报错内容和截图,并说明你使用的系统(Windows/Linux/MacOS)和你的配置(配置在执行main.py的时候会打印出来)。
本人只负责本项目的功能、代码和文档等相关问题(例如功能不正常、代码报错、文档内容有误等)。运行环境问题请自行解决(例如:如何配置Python环境,无法使用GPU加速,如何安装ffmpeg等)。
本人做此项目纯属“为爱发电”(也就是说,其实本人并没有义务解答你的问题)。为了提高问题解决效率,请尽量在开issue时一次性提供尽可能多的信息。如问题已解决,请记得关闭issue。一个星期无人回复的issue会被关闭。如果在被回复前已自行解决问题,推荐留下解决步骤,赠人玫瑰,手有余香。
推荐使用amd64或arm64架构的CPU。内存最低2G,但推荐最少4G内存。如果照片数量很多,推荐增加更多内存。
测试环境:J3455,8G内存。全志H6,2G内存。
在 J3455 CPU 上,1秒钟可以进行大约31000次图片匹配或25000次视频帧匹配。
- 部分视频无法在网页上显示,原因是浏览器不支持这一类型的文件(例如svq3编码的视频)。
- 点击图片进行放大时,部分图片无法显示,原因是浏览器不支持这一类型的文件(例如tiff格式的图片)。小图可以正常显示,因为转换成缩略图的时候使用了浏览器支持的格式。大图使用的是原文件。
- 搜视频时,如果显示的视频太多且视频体积太大,电脑可能会卡,这是正常现象。建议搜索视频时不要超过12个。
欢迎提PR!不过为了避免无意义的劳动,建议先提issue讨论一下。
提PR前请确保代码已经格式化,并执行api_test.py确保所有测试都能通过。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MaterialSearch
Similar Open Source Tools
MaterialSearch
MaterialSearch is a tool for searching local images and videos using natural language. It provides functionalities such as text search for images, image search for images, text search for videos (providing matching video clips), image search for videos (searching for the segment in a video through a screenshot), image-text similarity calculation, and Pexels video search. The tool can be deployed through the source code or Docker image, and it supports GPU acceleration. Users can configure the tool through environment variables or a .env file. The tool is still under development, and configurations may change frequently. Users can report issues or suggest improvements through issues or pull requests.
wiseflow
Wiseflow is an agile information mining tool that utilizes the thinking and analysis capabilities of large models to accurately extract specific information from various given sources, without the need for manual intervention. The tool focuses on filtering noise from a vast amount of information to reveal valuable insights. It is recommended to use normal language models for information extraction tasks to optimize speed and cost, rather than complex reasoning models. The tool is designed for continuous information gathering based on specified focus points from various sources.
Verbiverse
Verbiverse is a tool that uses a large language model to assist in reading PDFs and watching videos, aimed at improving language proficiency. It provides a more convenient and efficient way to use large models through predefined prompts, designed for those looking to enhance their language skills. The tool analyzes unfamiliar words and sentences in foreign language PDFs or video subtitles, providing better contextual understanding compared to traditional dictionary translations or ambiguous meanings. It offers features such as automatic loading of subtitles, word analysis by clicking or double-clicking, and a word database for collecting words. Users can run the tool on Windows x86_64 or ubuntu_22.04 x86_64 platforms by downloading the precompiled packages or by cloning the source code and setting up a virtual environment with Python. It is recommended to use a local model or smaller PDF files for testing due to potential token consumption issues with large files.
ChatGPT-Next-Web
ChatGPT Next Web is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro models. It allows users to deploy their private ChatGPT applications with ease. The tool offers features like one-click deployment, compact client for Linux/Windows/MacOS, compatibility with self-deployed LLMs, privacy-first approach with local data storage, markdown support, responsive design, fast loading speed, prompt templates, awesome prompts, chat history compression, multilingual support, and more.
aidea
AIdea is an app that integrates mainstream large language models and drawing models, developed using Flutter. The code is completely open-source and supports various functions such as GPT-3.5, GPT-4 from OpenAI, Claude instant, Claude 2.1 from Anthropic, Gemini Pro and visual language models from Google, as well as various Chinese and open-source models. It also supports features like text-to-image, super-resolution, coloring black and white images, artistic fonts, artistic QR codes, and more.
yomitoku
YomiToku is a Japanese-focused AI document image analysis engine that provides full-text OCR and layout analysis capabilities for images. It recognizes, extracts, and converts text information and figures in images. It includes 4 AI models trained on Japanese datasets for tasks such as detecting text positions, recognizing text strings, analyzing layouts, and recognizing table structures. The models are specialized for Japanese document images, supporting recognition of over 7000 Japanese characters and analyzing layout structures specific to Japanese documents. It offers features like layout analysis, table structure analysis, and reading order estimation to extract information from document images without disrupting their semantic structure. YomiToku supports various output formats such as HTML, markdown, JSON, and CSV, and can also extract figures, tables, and images from documents. It operates efficiently in GPU environments, enabling fast and effective analysis of document transcriptions without requiring high-end GPUs.

Lumina-Note
Lumina Note is a local-first AI note-taking app designed to help users write, connect, and evolve knowledge with AI capabilities while ensuring data ownership. It offers a knowledge-centered workflow with features like Markdown editor, WikiLinks, and graph view. The app includes AI workspace modes such as Chat, Agent, Deep Research, and Codex, along with support for multiple model providers. Users can benefit from bidirectional links, LaTeX support, graph visualization, PDF reader with annotations, real-time voice input, and plugin ecosystem for extended functionalities. Lumina Note is built on Tauri v2 framework with a tech stack including React 18, TypeScript, Tailwind CSS, and SQLite for vector storage.
KB-Builder
KB Builder is an open-source knowledge base generation system based on the LLM large language model. It utilizes the RAG (Retrieval-Augmented Generation) data generation enhancement method to provide users with the ability to enhance knowledge generation and quickly build knowledge bases based on RAG. It aims to be the central hub for knowledge construction in enterprises, offering platform-based intelligent dialogue services and document knowledge base management functionality. Users can upload docx, pdf, txt, and md format documents and generate high-quality knowledge base question-answer pairs by invoking large models through the 'Parse Document' feature.
Awesome-Lists
Awesome-Lists is a curated list of awesome lists across various domains of computer science and beyond, including programming languages, web development, data science, and more. It provides a comprehensive index of articles, books, courses, open source projects, and other resources. The lists are organized by topic and subtopic, making it easy to find the information you need. Awesome-Lists is a valuable resource for anyone looking to learn more about a particular topic or to stay up-to-date on the latest developments in the field.
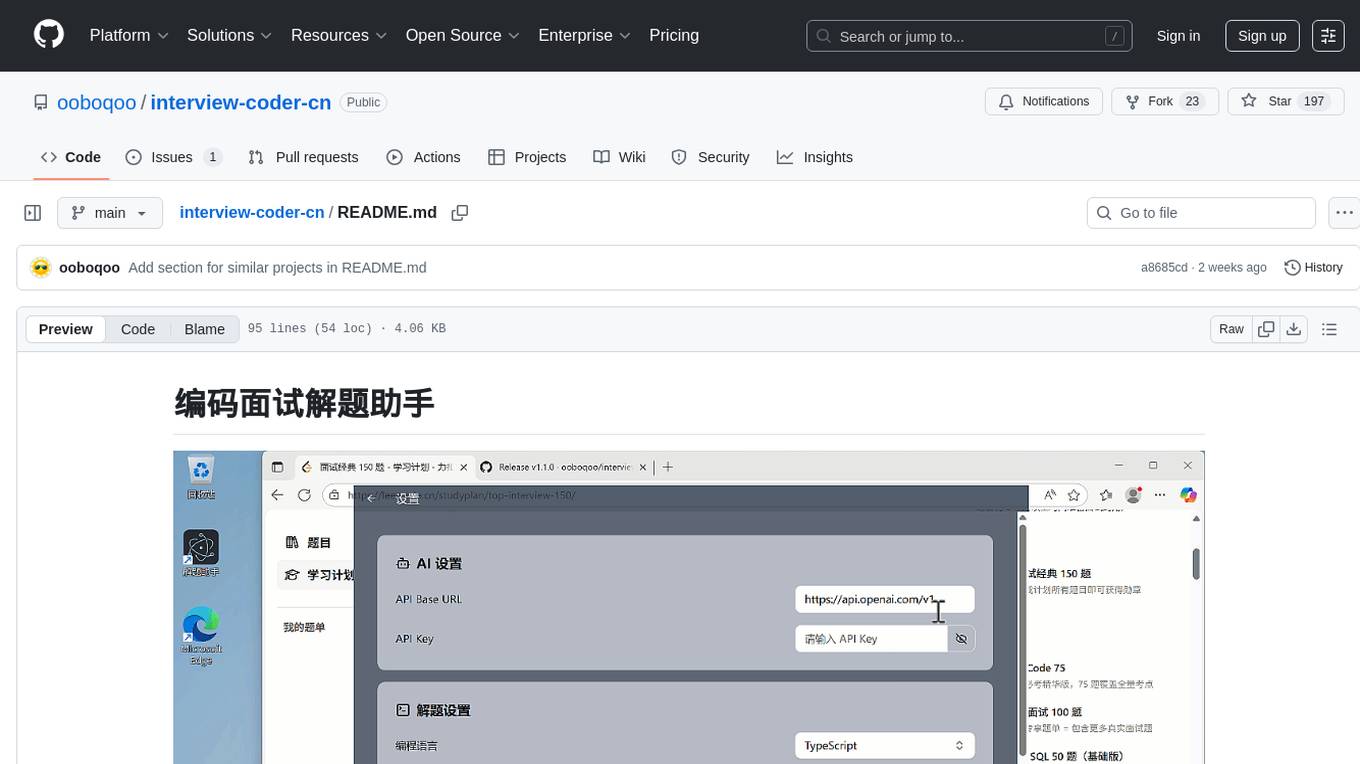
interview-coder-cn
This is a coding problem-solving assistant for Chinese users, tailored to the domestic AI ecosystem, simple and easy to use. It provides real-time problem-solving ideas and code analysis for coding interviews, avoiding detection during screen sharing. Users can also extend its functionality for other scenarios by customizing prompt words. The tool supports various programming languages and has stealth capabilities to hide its interface from interviewers even when screen sharing.
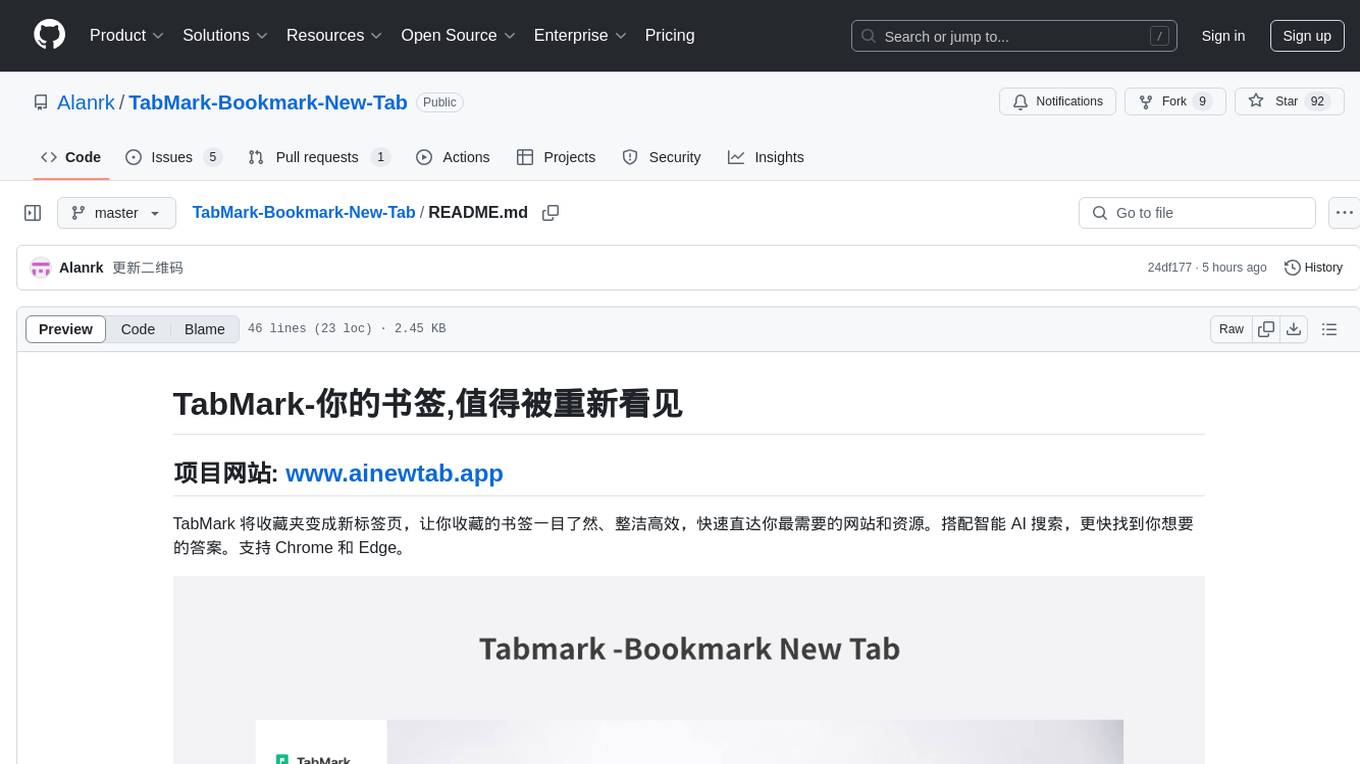
TabMark-Bookmark-New-Tab
TabMark is a browser extension that transforms bookmarks into a new tab page, allowing you to easily access and organize your saved bookmarks. It features intelligent AI search for quick answers and supports Chrome and Edge browsers. With TabMark, you can set bookmarks as new tab pages, access rich bookmark context menus, use sidebar bookmarks, utilize floating ball functionality, perform AI intelligent searches, compare search results, customize new tab pages, and access browser shortcuts. The extension enhances browsing efficiency and organization.
cf-proxy-ex
Cloudflare Proxy EX is a tool that provides Cloudflare super proxy, OpenAI/ChatGPT proxy, Github acceleration, and online proxy services. It allows users to create a worker in Cloudflare website by copying the content from worker.js file, and add their domain name before any URL to use the tool. The tool is an improvement based on gaboolic's cloudflare-reverse-proxy, offering features like removing '/proxy/', handling redirection events, modifying headers, converting relative paths to absolute paths, and more. It aims to enhance proxy functionality and address issues faced by some websites. However, users are advised not to log in to any website through the online proxy due to potential security risks.
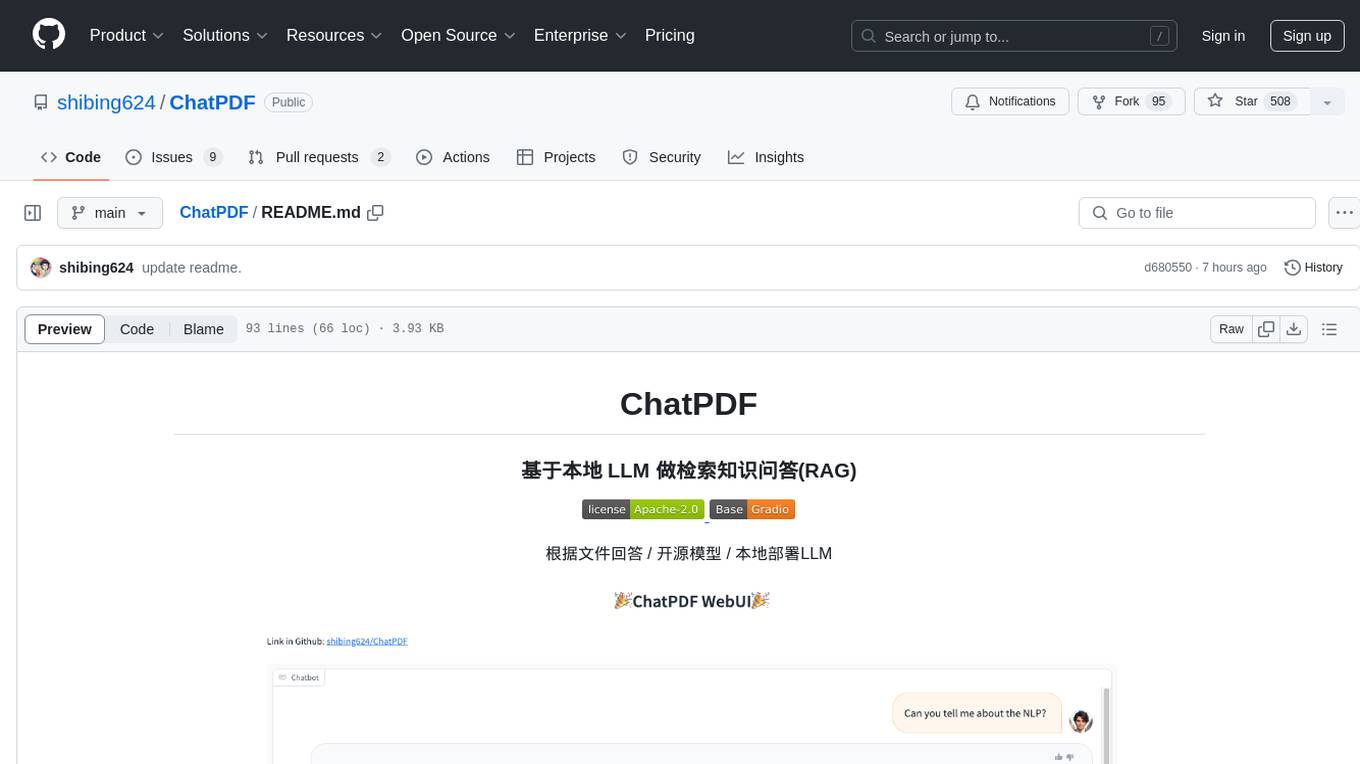
ChatPDF
ChatPDF is a knowledge question and answer retrieval tool based on local LLM. It supports various open-source LLM models like ChatGLM3-6b, Chinese-LLaMA-Alpaca-2, Baichuan, YI, and multiple file formats including PDF, docx, markdown, txt. The tool optimizes RAG accuracy, Chinese chunk segmentation, embedding using text2vec's sentence embedding, retrieval matching with rank_BM25, and introduces reranker module for reranking candidate sets. It also enhances candidate chunk extension context, supports custom RAG models, and provides a Gradio-based RAG conversation page for seamless dialogue.
Awesome-Lists-and-CheatSheets
Awesome-Lists is a curated index of selected resources spanning various fields including programming languages and theories, web and frontend development, server-side development and infrastructure, cloud computing and big data, data science and artificial intelligence, product design, etc. It includes articles, books, courses, examples, open-source projects, and more. The repository categorizes resources according to the knowledge system of different domains, aiming to provide valuable and concise material indexes for readers. Users can explore and learn from a wide range of high-quality resources in a systematic way.
chatgpt-adapter
ChatGPT-Adapter is an interface service that integrates various free services together. It provides a unified interface specification and integrates services like Bing, Claude-2, Gemini. Users can start the service by running the linux-server script and set proxies if needed. The tool offers model lists for different adapters, completion dialogues, authorization methods for different services like Claude, Bing, Gemini, Coze, and Lmsys. Additionally, it provides a free drawing interface with options like coze.dall-e-3, sd.dall-e-3, xl.dall-e-3, pg.dall-e-3 based on user-provided Authorization keys. The tool also supports special flags for enhanced functionality.
AI-Translation-Assistant-Pro
AI Translation Assistant Pro is a powerful AI-driven platform for multilingual translation and content processing. It offers features such as text translation, image recognition, PDF processing, speech recognition, and video processing. The platform includes a subscription system with different membership levels, user management functionalities, quota management, and real-time usage statistics. It utilizes technologies like Next.js, React, TypeScript for the frontend, Node.js, PostgreSQL for the backend, NextAuth.js for authentication, Stripe for payments, and integrates with cloud services like Aliyun OSS and Tencent Cloud for AI services.
For similar tasks
MaterialSearch
MaterialSearch is a tool for searching local images and videos using natural language. It provides functionalities such as text search for images, image search for images, text search for videos (providing matching video clips), image search for videos (searching for the segment in a video through a screenshot), image-text similarity calculation, and Pexels video search. The tool can be deployed through the source code or Docker image, and it supports GPU acceleration. Users can configure the tool through environment variables or a .env file. The tool is still under development, and configurations may change frequently. Users can report issues or suggest improvements through issues or pull requests.
Forza-Mods-AIO
Forza Mods AIO is a free and open-source tool that enhances the gaming experience in Forza Horizon 4 and 5. It offers a range of time-saving and quality-of-life features, making gameplay more enjoyable and efficient. The tool is designed to streamline various aspects of the game, improving user satisfaction and overall enjoyment.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
tenere
Tenere is a TUI interface for Language Model Libraries (LLMs) written in Rust. It provides syntax highlighting, chat history, saving chats to files, Vim keybindings, copying text from/to clipboard, and supports multiple backends. Users can configure Tenere using a TOML configuration file, set key bindings, and use different LLMs such as ChatGPT, llama.cpp, and ollama. Tenere offers default key bindings for global and prompt modes, with features like starting a new chat, saving chats, scrolling, showing chat history, and quitting the app. Users can interact with the prompt in different modes like Normal, Visual, and Insert, with various key bindings for navigation, editing, and text manipulation.
openkore
OpenKore is a custom client and intelligent automated assistant for Ragnarok Online. It is a free, open source, and cross-platform program (Linux, Windows, and MacOS are supported). To run OpenKore, you need to download and extract it or clone the repository using Git. Configure OpenKore according to the documentation and run openkore.pl to start. The tool provides a FAQ section for troubleshooting, guidelines for reporting issues, and information about botting status on official servers. OpenKore is developed by a global team, and contributions are welcome through pull requests. Various community resources are available for support and communication. Users are advised to comply with the GNU General Public License when using and distributing the software.
QA-Pilot
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository. It allows users to chat with GitHub public repositories using a git clone approach, store chat history, configure settings easily, manage multiple chat sessions, and quickly locate sessions with a search function. The tool integrates with `codegraph` to view Python files and supports various LLM models such as ollama, openai, mistralai, and localai. The project is continuously updated with new features and improvements, such as converting from `flask` to `fastapi`, adding `localai` API support, and upgrading dependencies like `langchain` and `Streamlit` to enhance performance.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.