
tiny-llm
A course of learning LLM inference serving on Apple Silicon for systems engineers: build a tiny vLLM + Qwen.
Stars: 3222
tiny-llm is a course on LLM serving using MLX for system engineers. The codebase is focused on MLX array/matrix APIs to build model serving infrastructure from scratch and explore optimizations. The goal is to efficiently serve large language models like Qwen2 models. The course covers implementing components in Python, building an inference system similar to vLLM, and advanced topics on model interaction. The tool aims to provide hands-on experience in serving language models without high-level neural network APIs.
README:
![]()
A course on LLM serving using MLX for system engineers. The codebase is solely (almost!) based on MLX array/matrix APIs without any high-level neural network APIs, so that we can build the model serving infrastructure from scratch and dig into the optimizations.
The goal is to learn the techniques behind efficiently serving a large language model (e.g., Qwen2 models).
In week 1, you will implement the necessary components in Python (only Python!) to use the Qwen2 model to generate responses (e.g., attention, RoPE, etc). In week 2, you will implement the inference system which is similar to but a much simpler version of vLLM (e.g., KV cache, continuous batching, flash attention, etc). In week 3, we will cover more advanced topics and how the model interacts with the outside world.
Why MLX: nowadays it's easier to get a macOS-based local development environment than setting up an NVIDIA GPU.
Why Qwen2: this was the first LLM I've interacted with -- it's the go-to example in the vllm documentation. I spent some time looking at the vllm source code and built some knowledge around it.
The tiny-llm book is available at https://skyzh.github.io/tiny-llm/. You can follow the guide and start building.
You may join skyzh's Discord server and study with the tiny-llm community.
![]()
Week 1 is complete. Week 2 is in progress.
| Week + Chapter | Topic | Code | Test | Doc |
|---|---|---|---|---|
| 1.1 | Attention | ✅ | ✅ | ✅ |
| 1.2 | RoPE | ✅ | ✅ | ✅ |
| 1.3 | Grouped Query Attention | ✅ | ✅ | ✅ |
| 1.4 | RMSNorm and MLP | ✅ | ✅ | ✅ |
| 1.5 | Load the Model | ✅ | ✅ | ✅ |
| 1.6 | Generate Responses (aka Decoding) | ✅ | ✅ | ✅ |
| 1.7 | Sampling | ✅ | ✅ | ✅ |
| 2.1 | Key-Value Cache | ✅ | ✅ | ✅ |
| 2.2 | Quantized Matmul and Linear - CPU | ✅ | ✅ | 🚧 |
| 2.3 | Quantized Matmul and Linear - GPU | ✅ | ✅ | 🚧 |
| 2.4 | Flash Attention 2 - CPU | ✅ | ✅ | 🚧 |
| 2.5 | Flash Attention 2 - GPU | ✅ | ✅ | 🚧 |
| 2.6 | Continuous Batching | ✅ | ✅ | ✅ |
| 2.7 | Chunked Prefill | ✅ | ✅ | ✅ |
| 3.1 | Paged Attention - Part 1 | 🚧 | 🚧 | 🚧 |
| 3.2 | Paged Attention - Part 2 | 🚧 | 🚧 | 🚧 |
| 3.3 | MoE (Mixture of Experts) | 🚧 | 🚧 | 🚧 |
| 3.4 | Speculative Decoding | 🚧 | 🚧 | 🚧 |
| 3.5 | RAG Pipeline | 🚧 | 🚧 | 🚧 |
| 3.6 | AI Agent / Tool Calling | 🚧 | 🚧 | 🚧 |
| 3.7 | Long Context | 🚧 | 🚧 | 🚧 |
Other topics not covered: quantized/compressed kv cache, prefix/prompt cache; sampling, fine tuning; smaller kernels (softmax, silu, etc)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tiny-llm
Similar Open Source Tools
tiny-llm
tiny-llm is a course on LLM serving using MLX for system engineers. The codebase is focused on MLX array/matrix APIs to build model serving infrastructure from scratch and explore optimizations. The goal is to efficiently serve large language models like Qwen2 models. The course covers implementing components in Python, building an inference system similar to vLLM, and advanced topics on model interaction. The tool aims to provide hands-on experience in serving language models without high-level neural network APIs.
llama-stack
Llama Stack defines and standardizes core building blocks for AI application development, providing a unified API layer, plugin architecture, prepackaged distributions, developer interfaces, and standalone applications. It offers flexibility in infrastructure choice, consistent experience with unified APIs, and a robust ecosystem with integrated distribution partners. The tool simplifies building, testing, and deploying AI applications with various APIs and environments, supporting local development, on-premises, cloud, and mobile deployments.
llm-engineer-toolkit
The LLM Engineer Toolkit is a curated repository containing over 120 LLM libraries categorized for various tasks such as training, application development, inference, serving, data extraction, data generation, agents, evaluation, monitoring, prompts, structured outputs, safety, security, embedding models, and other miscellaneous tools. It includes libraries for fine-tuning LLMs, building applications powered by LLMs, serving LLM models, extracting data, generating synthetic data, creating AI agents, evaluating LLM applications, monitoring LLM performance, optimizing prompts, handling structured outputs, ensuring safety and security, embedding models, and more. The toolkit covers a wide range of tools and frameworks to streamline the development, deployment, and optimization of large language models.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
auto-dev-vscode
AutoDev for VSCode is an AI-powered coding wizard with multilingual support, auto code generation, and a bug-slaying assistant. It offers customizable prompts and features like Auto Dev/Testing/Document/Agent. The tool aims to enhance coding productivity and efficiency by providing intelligent assistance and automation capabilities within the Visual Studio Code environment.
Model-References
The 'Model-References' repository contains examples for training and inference using Intel Gaudi AI Accelerator. It includes models for computer vision, natural language processing, audio, generative models, MLPerf™ training, and MLPerf™ inference. The repository provides performance data and model validation information for various frameworks like PyTorch. Users can find examples of popular models like ResNet, BERT, and Stable Diffusion optimized for Intel Gaudi AI accelerator.
crabml
Crabml is a llama.cpp compatible AI inference engine written in Rust, designed for efficient inference on various platforms with WebGPU support. It focuses on running inference tasks with SIMD acceleration and minimal memory requirements, supporting multiple models and quantization methods. The project is hackable, embeddable, and aims to provide high-performance AI inference capabilities.
watsonx-ai-samples
Sample notebooks for IBM Watsonx.ai for IBM Cloud and IBM Watsonx.ai software product. The notebooks demonstrate capabilities such as running experiments on model building using AutoAI or Deep Learning, deploying third-party models as web services or batch jobs, monitoring deployments with OpenScale, managing model lifecycles, inferencing Watsonx.ai foundation models, and integrating LangChain with Watsonx.ai. Notebooks with Python code and the Python SDK can be found in the `python_sdk` folder. The REST API examples are organized in the `rest_api` folder.

are-copilots-local-yet
Current trends and state of the art for using open & local LLM models as copilots to complete code, generate projects, act as shell assistants, automatically fix bugs, and more. This document is a curated list of local Copilots, shell assistants, and related projects, intended to be a resource for those interested in a survey of the existing tools and to help developers discover the state of the art for projects like these.
awesome-llm-planning-reasoning
The 'Awesome LLMs Planning Reasoning' repository is a curated collection focusing on exploring the capabilities of Large Language Models (LLMs) in planning and reasoning tasks. It includes research papers, code repositories, and benchmarks that delve into innovative techniques, reasoning limitations, and standardized evaluations related to LLMs' performance in complex cognitive tasks. The repository serves as a comprehensive resource for researchers, developers, and enthusiasts interested in understanding the advancements and challenges in leveraging LLMs for planning and reasoning in real-world scenarios.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).
linghe
A library of high-performance kernels for LLM training, linghe is designed for MoE training with FP8 quantization. It provides fused quantization kernels, memory-efficiency kernels, and implementation-optimized kernels. The repo benchmarks on H800 with specific configurations and offers examples in tests. Users can refer to the API for more details.
For similar tasks
tiny-llm
tiny-llm is a course on LLM serving using MLX for system engineers. The codebase is focused on MLX array/matrix APIs to build model serving infrastructure from scratch and explore optimizations. The goal is to efficiently serve large language models like Qwen2 models. The course covers implementing components in Python, building an inference system similar to vLLM, and advanced topics on model interaction. The tool aims to provide hands-on experience in serving language models without high-level neural network APIs.

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.
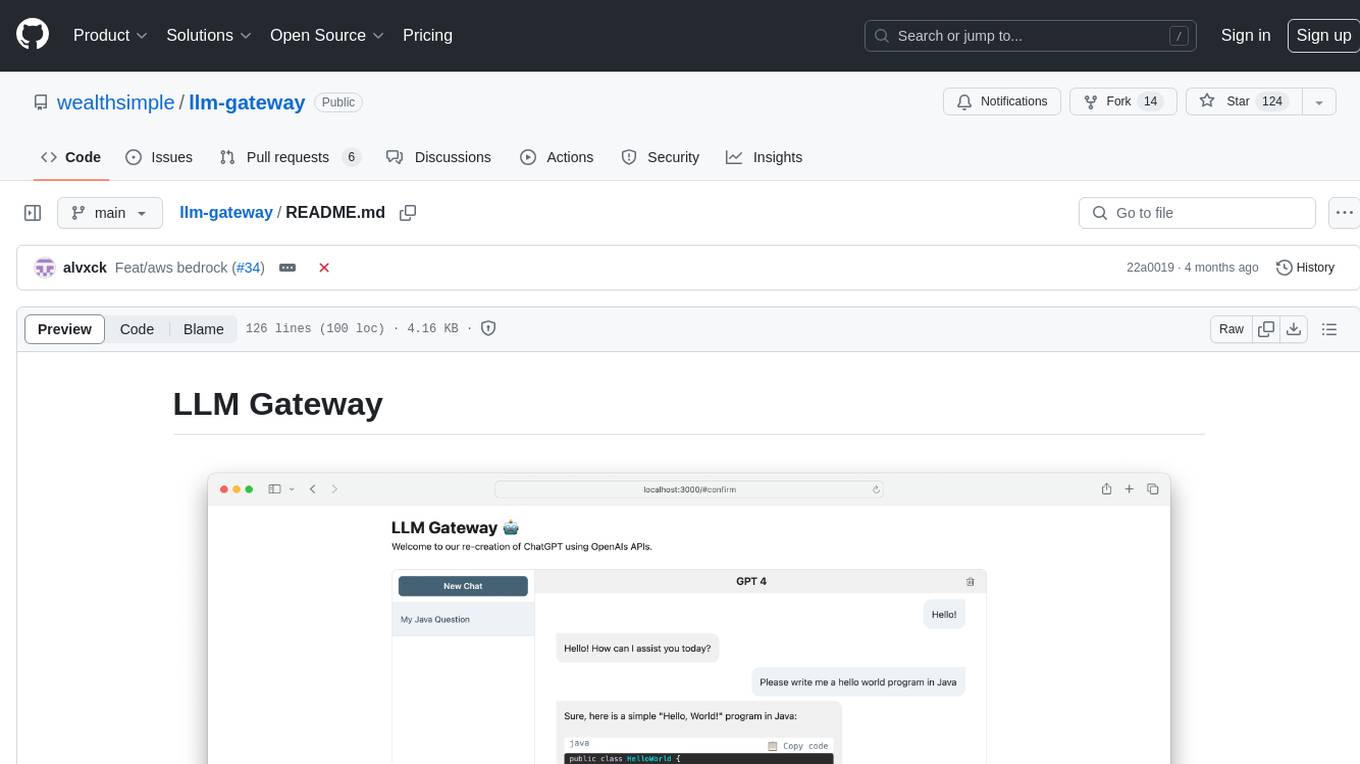
llm-gateway
llm-gateway is a gateway tool designed for interacting with third-party LLM providers such as OpenAI, Cohere, etc. It tracks data exchanged with these providers in a postgres database, applies PII scrubbing heuristics, and ensures safe communication with OpenAI's services. The tool supports various models from different providers and offers API and Python usage examples. Developers can set up the tool using Poetry, Pyenv, npm, and yarn for dependency management. The project also includes Docker setup for backend and frontend development.
Ollamac
Ollamac is a macOS app designed for interacting with Ollama models. It is optimized for macOS, allowing users to easily use any model from the Ollama library. The app features a user-friendly interface, chat archive for saving interactions, and real-time communication using HTTP streaming technology. Ollamac is open-source, enabling users to contribute to its development and enhance its capabilities. It requires macOS 14 or later and the Ollama system to be installed on the user's Mac with at least one Ollama model downloaded.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.
mistral-ai-kmp
Mistral AI SDK for Kotlin Multiplatform (KMP) allows communication with Mistral API to get AI models, start a chat with the assistant, and create embeddings. The library is based on Mistral API documentation and built with Kotlin Multiplatform and Ktor client library. Sample projects like ZeChat showcase the capabilities of Mistral AI SDK. Users can interact with different Mistral AI models through ZeChat apps on Android, Desktop, and Web platforms. The library is not yet published on Maven, but users can fork the project and use it as a module dependency in their apps.

LightRAG
LightRAG is a PyTorch library designed for building and optimizing Retriever-Agent-Generator (RAG) pipelines. It follows principles of simplicity, quality, and optimization, offering developers maximum customizability with minimal abstraction. The library includes components for model interaction, output parsing, and structured data generation. LightRAG facilitates tasks like providing explanations and examples for concepts through a question-answering pipeline.
ell
ell is a command-line interface for Language Model Models (LLMs) written in Bash. It allows users to interact with LLMs from the terminal, supports piping, context bringing, and chatting with LLMs. Users can also call functions and use templates. The tool requires bash, jq for JSON parsing, curl for HTTPS requests, and perl for PCRE. Configuration involves setting variables for different LLM models and APIs. Usage examples include asking questions, specifying models, recording input/output, running in interactive mode, and using templates. The tool is lightweight, easy to install, and pipe-friendly, making it suitable for interacting with LLMs in a terminal environment.
For similar jobs

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.