
watsonx-ai-samples
IBM watsonx.ai sample models, notebooks and apps.
Stars: 128
Sample notebooks for IBM Watsonx.ai for IBM Cloud and IBM Watsonx.ai software product. The notebooks demonstrate capabilities such as running experiments on model building using AutoAI or Deep Learning, deploying third-party models as web services or batch jobs, monitoring deployments with OpenScale, managing model lifecycles, inferencing Watsonx.ai foundation models, and integrating LangChain with Watsonx.ai. Notebooks with Python code and the Python SDK can be found in the `python_sdk` folder. The REST API examples are organized in the `rest_api` folder.
README:
The sample notebooks in this repo demonstrate Watson Machine Learning and watsonx.ai capabilities such as:
- Running experiments on model building using AutoAI or Deep Learning
- Deploying third-party models as web services or batch jobs (i.e.: scikit-learn, xgboost, keras, PMMl, SPSS, etc.)
- Monitoring deployments with OpenScale (drift, bias detection)
- Managing model lifecycles (updating the model version, refreshing a deployment)
- Inferencing watsonx.ai foundation models
- Integrating LangChain with watsonx.ai
Notebooks with Python code and the Python SDK can be found in the python_sdk folder. The REST API examples are organized in the rest_api folder.
This section contains sample notebooks with examples of how to serve different types of models, either as online or batch jobs.
| Notebook | Description | cloud | CPD 4.0 | CPD 4.5 | CPD 4.6 | CPD 4.7 | CPD 4.8 | CPD 5.0 | CPD 5.1 |
|---|---|---|---|---|---|---|---|---|---|
| Use a custom software spec to create a statsmodels function | Demonstrates how to deploy a Python function with statsmode in Watson Machine Learning. For this, you need to create a custom software specification using a conda yaml file with all of the required libraries. | link | link | link | link | link | link | link | link |
| Use a function to recognize hand-written digits | Demonstrates how to create and deploy a function that receives HTML canvas image data from a web app and then sends that data to a model trained to recognize handwritten digits. | link | link | link | link | link | link | link | link |
| Use scikit-learn to recognize hand-written digits | Demonstrates how to persist and deploy a locally trained scikit-learn model in Watson Machine Learning. | link | link | link | link | link | link | link | link |
| Use scikit-learn and a custom library to predict temperature | Demonstrates how to train a scikit-learn model that uses a custom defined transformer and then how to use it with Watson Machine Learning. | link | link | link | link | link | link | link | link |
| Use watsonx, and LangChain to make a series of calls to a language model | Demonstrates how to chain google/flan-ul2 and google/flan-t5-xxl models to generate a sequence of creating a random question on a given topic and an answer to that question. This notebook familiarizes the user with the LangChain framework, using simple chain (LLMChain) and the extended chain (SimpleSequentialChain) with the WatsonxLLM. | link | - | - | - | - | link | link | link |
| Use watsonx to tune IBM 'granite-13b-instruct-v2' model with cars4u document | Demonstrates how to do prompt tuning in watsonx. | link | - | - | - | - | link | link | link |
| Use watsonx Granite Model Series, Chroma, and LangChain to answer questions (RAG) | Demonstrates how to use Retrieval Augumented Generation (RAG) in watsonx.ai. It introduces commands for data retrieval, knowledge base building and querying, and model testing. | link | - | - | - | - | link | link | link |
| Use watsonx to manage Prompt Template assets and create deployment | Demonstrates how to create a Prompt Template Asset and how to create a deployment pointing on it. | link | - | - | - | - | link | link | link |
| Use watsonx Text Extraction service to extract text from file | This notebook contains the steps and code demonstrating how to run a Text Extraction job using python SDK and then retrieve the results in the form of markdown file. | link | - | - | - | - | - | - | link |
| Use watsonx, and mistralai/mistral-large to make simple chat conversation and tool calls | This notebook provides a detailed demonstration of the steps and code required to showcase support for Chat models, including the integration of tools and watsonx.ai models. | link | - | - | - | - | - | - | link |
| Use watsonx, and mistralai/mistral-large with support for tools to perform simple calculations | This notebook provides a detailed demonstration of the steps and code required to showcase support for Chat models, including the integration of tools using LangGraph and watsonx.ai models. | link | - | - | - | - | - | - | link |
| Use watsonx, and meta-llama/llama-3-2-11b-vision-instruct model for image processing to generate a description of the IBM logo | This notebook provides a detailed demonstration of the steps and code required to showcase support for Chat models. | link | - | - | - | - | - | - | link |
| Use watsonx, and meta-llama/Meta-Llama-3-8B to Fine Tune with online banking queries annotated | This notebook contains the steps and code to demonstrate support of fine tuning in watsonx. | link | - | - | - | - | - | link | link |
| Use watsonx, and meta-llama/llama-3-2-11b-vision-instruct to run as an AI service | This notebook provides a detailed demonstration of the steps and code required to showcase support for watsonx.ai AI service. | link | - | - | - | - | - | - | - |
| Use watsonx, and meta-llama/llama-3-1-8b-instruct to run as an AI service | This notebook provides a detailed demonstration of the steps and code required to showcase support for watsonx.ai AI service. | - | - | - | - | - | - | - | link |
| Use Time Series Foundation Models and time series data to predict energy demand | This notebook demonstrates the use of a pre-trained time series foundation model for multivariate forecasting tasks and showcases the variety of features available in Time Series Foundation Models. | link | - | - | - | - | - | - | link |
This section contains sample notebooks with examples of how to use AutoAI and Deep Learning experiments. The notebooks show how to trigger such an experiment, work with trained models, and do model comparison, refinery, and finally deployment.
| Notebook | Description | cloud | CPD 4.0 | CPD 4.5 | CPD 4.6 | CPD 4.7 | CPD 4.8 | CPD 5.0 | CPD 5.1 |
|---|---|---|---|---|---|---|---|---|---|
| Use AutoAI and Lale to predict credit risk | Demonstrates how to use AutoAI experiments by getting a German credit data set and training the model to predict banking credit. | link | link | link | link | link | link | link | link |
| Use AutoAI and timeseries data to predict COVID cases | Demonstrates how to use AutoAI experiments for timeseries data sets in Watson Machine Learning service. | link | - | link | link | link | link | link | link |
| Use AutoAI to train fair models | Demonstrates how to use AutoAI experiments with bias detection/mitigation in Watson Machine Learning. | link | - | link | link | link | link | link | link |
| Use Lale AIF360 scorers to calculate and mitigate bias for credit risk AutoAI model | Demonstrate how to use AutoAI experiments in Watson Machine Learning. | link | link | link | link | link | link | link | link |
| Use PyTorch to recognize hand-written digits | Demonstrates how to use Deep Learning model training and scoring in Watson Machine Learning. | - | link | link | link | link | link | link | link |
| Use AutoAI RAG and Chroma to create a pattern and get information from ibm-watsonx-ai SDK documentation | This notebook contains the steps and code to demonstrate the usage of IBM AutoAI RAG. The AutoAI RAG experiment conducted in this notebook uses data scraped from the ibm-watsonx-ai SDK documentation. | link | - | - | - | - | - | - | link |
| Use AutoAI RAG and Milvus database to work with ibm-watsonx-ai SDK documentation | This notebook contains the steps and code to demonstrate the usage of IBM AutoAI RAG. The AutoAI RAG experiment conducted in this notebook uses data scraped from the ibm-watsonx-ai SDK documentation. | link | - | - | - | - | - | - | link |
This section contains sample notebooks with examples that show how to work with the Watson Machine Learning instance.
| Notebook | Description | cloud | CPD 4.0 | CPD 4.5 | CPD 4.6 | CPD 4.7 | CPD 4.8 | CPD 5.0 | CPD 5.1 |
|---|---|---|---|---|---|---|---|---|---|
| Machine Learning artifacts export and import | Demonstrates an example of exporting and importing assets using Watson Machine Learning. | link | link | link | link | link | link | link | link |
| Machine Learning artifacts management | Demonstrates how to manage and clean up a Watson Machine Learning instance. | link | link | link | link | link | link | link | link |
| Space management | Demonstrates how to manage spaces in the context of Watson Machine Learning. | link | link | link | link | link | link | link | link |
This section contains sample notebooks with examples that show how to update an existing model version and refresh an existing deployment in-place.
| Notebook | Description | cloud | CPD 4.0 | CPD 4.5 | CPD 4.6 | CPD 4.7 | CPD 4.8 | CPD 5.0 | CPD 5.1 |
|---|---|---|---|---|---|---|---|---|---|
| Use python API to automate AutoAI deployment lifecycle | Demonstrates how to use the AI Lifecycle features from the AutoAI model in Watson Machine Learning. | link | - | - | - | link | link | link | link |
| Use scikit-learn and AI lifecycle capabilities to predict Boston house prices | Demonstrates how to use the AI Lifecycle features in Watson Machine Learning. | - | link | link | link | link | link | - | - |
| Use scikit-learn and AI lifecycle capabilities to predict California house prices | Demonstrates how to use the AI Lifecycle features in watsonx.ai. | link | - | - | - | - | - | link | link |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for watsonx-ai-samples
Similar Open Source Tools
watsonx-ai-samples
Sample notebooks for IBM Watsonx.ai for IBM Cloud and IBM Watsonx.ai software product. The notebooks demonstrate capabilities such as running experiments on model building using AutoAI or Deep Learning, deploying third-party models as web services or batch jobs, monitoring deployments with OpenScale, managing model lifecycles, inferencing Watsonx.ai foundation models, and integrating LangChain with Watsonx.ai. Notebooks with Python code and the Python SDK can be found in the `python_sdk` folder. The REST API examples are organized in the `rest_api` folder.

are-copilots-local-yet
Current trends and state of the art for using open & local LLM models as copilots to complete code, generate projects, act as shell assistants, automatically fix bugs, and more. This document is a curated list of local Copilots, shell assistants, and related projects, intended to be a resource for those interested in a survey of the existing tools and to help developers discover the state of the art for projects like these.
Model-References
The 'Model-References' repository contains examples for training and inference using Intel Gaudi AI Accelerator. It includes models for computer vision, natural language processing, audio, generative models, MLPerf™ training, and MLPerf™ inference. The repository provides performance data and model validation information for various frameworks like PyTorch. Users can find examples of popular models like ResNet, BERT, and Stable Diffusion optimized for Intel Gaudi AI accelerator.

LLM-KG4QA
LLM-KG4QA is a repository focused on the integration of Large Language Models (LLMs) and Knowledge Graphs (KGs) for Question Answering (QA). It covers various aspects such as using KGs as background knowledge, reasoning guideline, and refiner/filter. The repository provides detailed information on pre-training, fine-tuning, and Retrieval Augmented Generation (RAG) techniques for enhancing QA performance. It also explores complex QA tasks like Explainable QA, Multi-Modal QA, Multi-Document QA, Multi-Hop QA, Multi-run and Conversational QA, Temporal QA, Multi-domain and Multilingual QA, along with advanced topics like Optimization and Data Management. Additionally, it includes benchmark datasets, industrial and scientific applications, demos, and related surveys in the field.
ai-samples
AI Samples for .NET is a repository containing various samples demonstrating how to use AI in .NET applications. It provides quickstarts using Semantic Kernel and Azure OpenAI SDK, covers LLM Core Concepts, End to End Examples, Local Models, Local Embedding Models, Tokenizers, Vector Databases, and Reference Examples. The repository showcases different AI-related projects and tools for developers to explore and learn from.
awesome-llm-planning-reasoning
The 'Awesome LLMs Planning Reasoning' repository is a curated collection focusing on exploring the capabilities of Large Language Models (LLMs) in planning and reasoning tasks. It includes research papers, code repositories, and benchmarks that delve into innovative techniques, reasoning limitations, and standardized evaluations related to LLMs' performance in complex cognitive tasks. The repository serves as a comprehensive resource for researchers, developers, and enthusiasts interested in understanding the advancements and challenges in leveraging LLMs for planning and reasoning in real-world scenarios.
awesome-openclaw
Awesome OpenClaw is a curated collection of resources, tools, skills, tutorials, and articles for the open-source AI agent OpenClaw. It provides official resources, installation guides, skills & plugins, integrations with messaging platforms and external services, MCP support, tutorials & guides, articles & news, community information, community projects, alternatives & comparisons, security best practices and tools, and guidelines for contributing. OpenClaw is an autonomous AI agent that connects to 50+ integrations and allows chatting with AI through various messaging platforms.
Multiverse_of_100-_data_science_project_series
This repository contains a series of 100+ data science projects covering a wide range of topics and techniques. Each project is designed to help learners practice and improve their data science skills by working on real-world datasets and problems. The projects include data cleaning, exploratory data analysis, machine learning modeling, and data visualization. Whether you are a beginner looking to build a portfolio or an experienced data scientist wanting to sharpen your skills, this repository offers a diverse set of projects to work on.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.
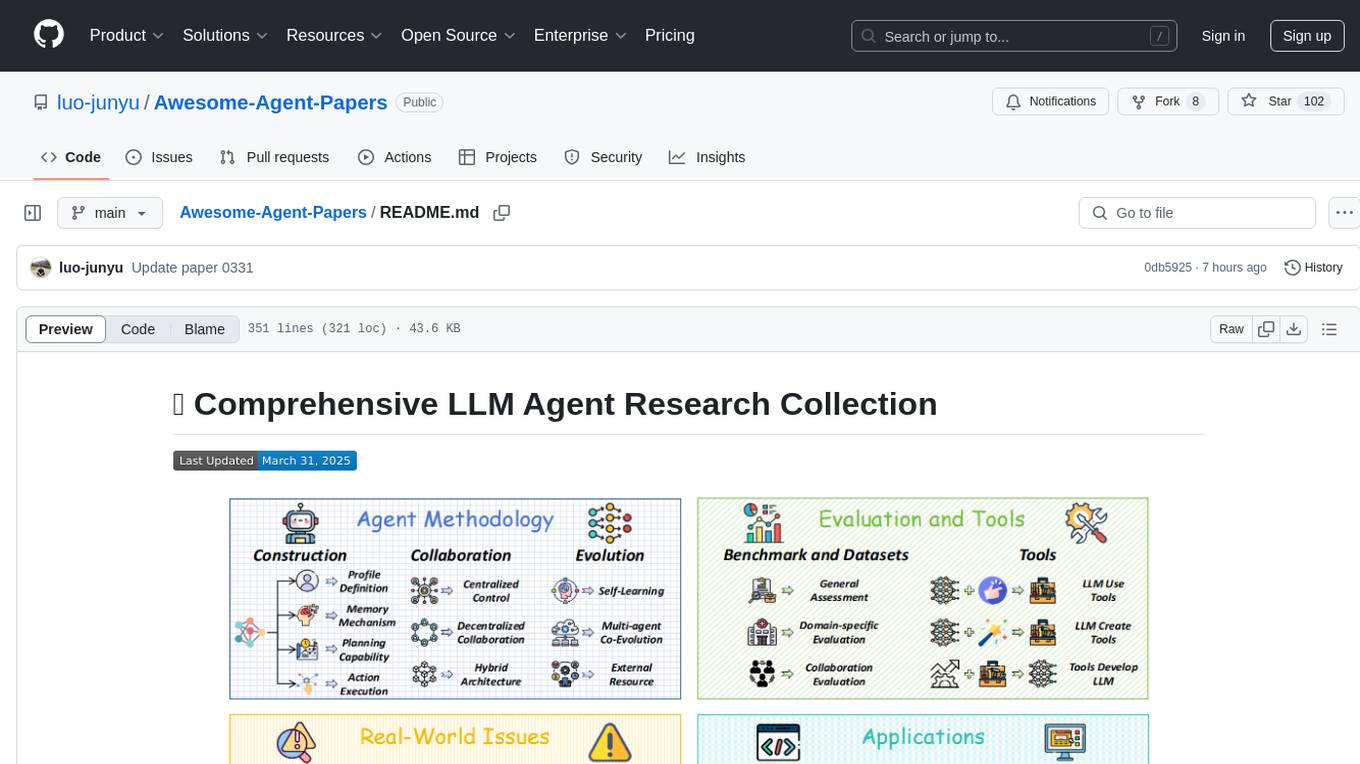
Awesome-Agent-Papers
This repository is a comprehensive collection of research papers on Large Language Model (LLM) agents, organized across key categories including agent construction, collaboration mechanisms, evolution, tools, security, benchmarks, and applications. The taxonomy provides a structured framework for understanding the field of LLM agents, bridging fragmented research threads by highlighting connections between agent design principles and emergent behaviors.
models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. It aims to replicate the best-known performance of target model/dataset combinations in optimally-configured hardware environments. The repository will be deprecated upon the publication of v3.2.0 and will no longer be maintained or published.
data-prep-kit
Data Prep Kit is a community project aimed at democratizing and speeding up unstructured data preparation for LLM app developers. It provides high-level APIs and modules for transforming data (code, language, speech, visual) to optimize LLM performance across different use cases. The toolkit supports Python, Ray, Spark, and Kubeflow Pipelines runtimes, offering scalability from laptop to datacenter-scale processing. Developers can contribute new custom modules and leverage the data processing library for building data pipelines. Automation features include workflow automation with Kubeflow Pipelines for transform execution.
awesome-open-data-annotation
At ZenML, we believe in the importance of annotation and labeling workflows in the machine learning lifecycle. This repository showcases a curated list of open-source data annotation and labeling tools that are actively maintained and fit for purpose. The tools cover various domains such as multi-modal, text, images, audio, video, time series, and other data types. Users can contribute to the list and discover tools for tasks like named entity recognition, data annotation for machine learning, image and video annotation, text classification, sequence labeling, object detection, and more. The repository aims to help users enhance their data-centric workflows by leveraging these tools.
rubra
Rubra is a collection of open-weight large language models enhanced with tool-calling capability. It allows users to call user-defined external tools in a deterministic manner while reasoning and chatting, making it ideal for agentic use cases. The models are further post-trained to teach instruct-tuned models new skills and mitigate catastrophic forgetting. Rubra extends popular inferencing projects for easy use, enabling users to run the models easily.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
Azure-AIGEN-demos
Microsoft Foundry is a unified Azure platform-as-a-service offering for enterprise AI operations, model builders, and application development. This foundation combines production-grade infrastructure with friendly interfaces, enabling developers to focus on building applications rather than managing infrastructure. Microsoft Foundry unifies agents, models, and tools under a single management grouping with built-in enterprise-readiness capabilities including tracing, monitoring, evaluations, and customizable enterprise setup configurations. The platform provides streamlined management through unified Role-based access control (RBAC), networking, and policies under one Azure resource provider namespace.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.