
ml-road-map
The most streamlined road map to learn ML fundamentals for free.
Stars: 253
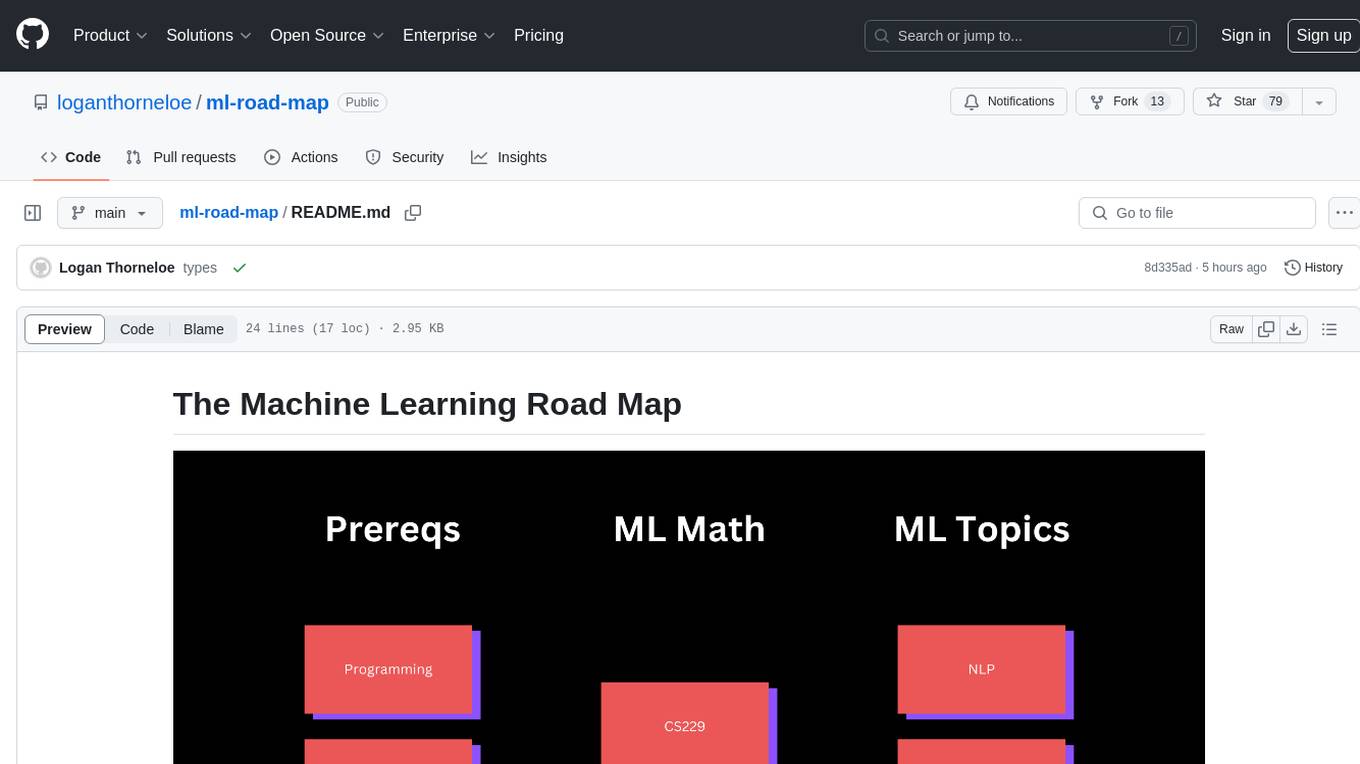
The Machine Learning Road Map is a comprehensive guide designed to take individuals from various levels of machine learning knowledge to a basic understanding of machine learning principles using high-quality, free resources. It aims to simplify the complex and rapidly growing field of machine learning by providing a structured roadmap for learning. The guide emphasizes the importance of understanding AI for everyone, the need for patience in learning machine learning due to its complexity, and the value of learning from experts in the field. It covers five different paths to learning about machine learning, catering to consumers, aspiring AI researchers, ML engineers, developers interested in building ML applications, and companies looking to implement AI solutions.
README:

Welcome to the Machine Learning Road Map. This is the fastest, high-quality road map to get up to speed on machine learning fundamentals. It teaches you the prerequisites and machine learning fundamentals necessary to understand how machine learning works and build with it. The goal is to quickly get to a point where you can comfortably explore machine learning topics on your own. Many other road maps are more comprehensive, this one is purposefully streamlined.
These resources are aggregated from the best ML educators. I've linked to the authors as much as possible. Please support them. Feedback/suggestions/corrections are always welcome and appreciated.
If you're less interested in the technical details of machine learning and want to know more about how machine learning will affect you as a consumer, I've written an article just for that. You can also check out the Google AI Essentials Course learn how to use generative AI to boost your productivity.
To support this project and stay updated:
- ⭐ Star this repository
- 🐦 Follow me on X (Twitter): @loganthorneloe
- 👨💻 Follow me on GitHub: loganthorneloe
This road map will be updated as new learning resources are created and new ML topics emerge. Let's get started!
- Machine Learning will impact everyone's life. It's a new paradigm of computing that will completely change the way consumers expect their devices to work.
- Machine learning is a rapidly developing field. There are many complex fields within machine learning. Take it slow and don't expect to become an expert in it all.
- The best way to understand machine learning is to learn from others who understand the topics you want to know more about. I've created a list of accounts to follow on X. I've also aggregated a list of newsletters, blogs, and channels I find helpful to stay updated.
These prerequisites contain a mixture of math and programming concepts. Feel free to skip things you already understand.
| Topic | Source | Author |
|---|---|---|
| Programming | ||
| General Programming | CS50 | Harvard |
| Python | Intro to Python (For Beginners) | Harvard |
| Google's Python Class (Refresher) | ||
| NumPy | NumPy Tutorial | NumPy Team |
| Pandas | Pandas Course | Kaggle |
| Math | ||
| Algebra | Algebra Curriculum | Khan Academy |
| Linear Algebra | Linear Algebra Curriculum | Khan Academy |
| Probability | Uncertainty Section of CS50 | Harvard |
| Calculus | Derivatives/Partial Derivatives | Khan Academy |
| Gradients | Khan Academy | |
| Backpropagation Visualization | ||
| Tools | ||
| Version Control | Learn How to Use Git | Open Source Git Community |
| Github Tutorial | GitHub | |
| Terminal | Learn Shell | learnshell.org |
This is the main material. Complete these to understand machine learning fundamentals:
| Topic | Source | Author |
|---|---|---|
| Intro | 20 Min Introduction to Machine Learning | |
| Fundamentals | Machine Learning Crash Course |
High-quality resources to explore more advanced topics that are helpful for machine learning:
Your support helps keep this resource up-to-date and valuable for the ML community!
This section contains the technologies and skills I find most often as I go through real machine learning-related job descriptions and the resources for learning each.
All of these are must-subscribes:
For a list of almost all the available ML YouTube Courses check out this repo by Dair AI.
I've aggregated a list of cloud providers that offer a free tier for training machine learning models. Anyone can get started with ML- you don't need a powerful local machine. If anything is incorrect, reach out to me on X so I can make the fix. If there is a cloud computing platform that I've missed, also let me know.
| Resource | Details |
|---|---|
| Top Choices | |
| Google Colab | Offers free access to GPUs (usually NVIDIA T4 or P100) and TPUs with limited usage time and resources. Excellent for small projects and experimentation. |
| Kaggle Notebooks | Provides 30 hours/week of GPU usage (NVIDIA Tesla P100 or T4) for free. It's a good option with access to Kaggle's datasets and community. |
| Other Options | |
| Lightning AI | Offers one free studio with 22 GPU hours and is pay-as-you-go after that. |
| Google Cloud Platform | Offers $300 in free credits to new users. |
| Amazon SageMaker | Provides a free tier with limited access to various machine learning resources. |
| Paperspace Gradient | Offers a free community tier with access to limited GPU resources for experimentation and learning. |
Don't forget to star this repo and follow me on X to support this guide. Please support the authors of these resources by following them at the links I included. You can also find them in my ML on X list.
If any information is missing, you are the author of a resource and you'd like it removed, or any other general feedback send me a message to let me know.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ml-road-map
Similar Open Source Tools
ml-road-map
The Machine Learning Road Map is a comprehensive guide designed to take individuals from various levels of machine learning knowledge to a basic understanding of machine learning principles using high-quality, free resources. It aims to simplify the complex and rapidly growing field of machine learning by providing a structured roadmap for learning. The guide emphasizes the importance of understanding AI for everyone, the need for patience in learning machine learning due to its complexity, and the value of learning from experts in the field. It covers five different paths to learning about machine learning, catering to consumers, aspiring AI researchers, ML engineers, developers interested in building ML applications, and companies looking to implement AI solutions.
awesome-generative-ai-apis
Awesome Generative AI & LLM APIs is a curated list of useful APIs that allow developers to integrate generative models into their applications without building the models from scratch. These APIs provide an interface for generating text, images, or other content, and include pre-trained language models for various tasks. The goal of this project is to create a hub for developers to create innovative applications, enhance user experiences, and drive progress in the AI field.
HighPerfLLMs2024
High Performance LLMs 2024 is a comprehensive course focused on building a high-performance Large Language Model (LLM) from scratch using Jax. The course covers various aspects such as training, inference, roofline analysis, compilation, sharding, profiling, and optimization techniques. Participants will gain a deep understanding of Jax and learn how to design high-performance computing systems that operate close to their physical limits.
Journal-Club
The RISE Journal Club is a bi-weekly reading group that provides a friendly environment for discussing state-of-the-art papers in medical image analysis, AI, and computer vision. The club aims to enhance critical and design thinking skills essential for researchers. Moderators introduce papers for discussion on various topics such as registration, segmentation, federated learning, fairness, and reinforcement learning. The club covers papers from machine and deep learning communities, offering a broad overview of cutting-edge methods.
my-best-resources
my-best-resources is a curated list of resources for web developers and designers, aimed at making their lives easier. It includes sections on design inspiration, ready-made components, stock images, artificial intelligence tools for various use cases, and other useful sources. The repository provides links and descriptions for each resource, offering a valuable collection of tools and assets for web development and design projects.
aip-community-registry
AIP Community Registry is a collection of community-built applications and projects leveraging Palantir's AIP Platform. It showcases real-world implementations from developers using AIP in production. The registry features various solutions demonstrating practical implementations and integration patterns across different use cases.
GenAIExamples
This project provides a collective list of Generative AI (GenAI) and Retrieval-Augmented Generation (RAG) examples such as chatbot with question and answering (ChatQnA), code generation (CodeGen), document summary (DocSum), etc.
awesome-llm-planning-reasoning
The 'Awesome LLMs Planning Reasoning' repository is a curated collection focusing on exploring the capabilities of Large Language Models (LLMs) in planning and reasoning tasks. It includes research papers, code repositories, and benchmarks that delve into innovative techniques, reasoning limitations, and standardized evaluations related to LLMs' performance in complex cognitive tasks. The repository serves as a comprehensive resource for researchers, developers, and enthusiasts interested in understanding the advancements and challenges in leveraging LLMs for planning and reasoning in real-world scenarios.
FocusOnAI_24
The .NET Conf Focus on AI 2024 repository contains content from the event focusing on incorporating AI into .NET applications and services. It includes slides and demos showcasing various AI-powered web apps, AI models, generative AI apps, and more. The repository serves as a resource for developers looking to explore AI integration with .NET technologies.

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL
OpenGPT-4o
OpenGPT 4o is a free alternative to OpenAI GPT 4o. It offers various features such as free pricing, image and video generation, image QnA, voice and video chat, multilingual support, high customization, and continuous learning capability. The tool aims to provide an alternative to OpenAI GPT 4o with enhanced capabilities and features for users.
recommenders
Recommenders is a project under the Linux Foundation of AI and Data that assists researchers, developers, and enthusiasts in prototyping, experimenting with, and bringing to production a range of classic and state-of-the-art recommendation systems. The repository contains examples and best practices for building recommendation systems, provided as Jupyter notebooks. It covers tasks such as preparing data, building models using various recommendation algorithms, evaluating algorithms, tuning hyperparameters, and operationalizing models in a production environment on Azure. The project provides utilities to support common tasks like loading datasets, evaluating model outputs, and splitting training/test data. It includes implementations of state-of-the-art algorithms for self-study and customization in applications.
mastering-github-copilot-for-dotnet-csharp-developers
Enhance coding efficiency with expert-led GitHub Copilot course for C#/.NET developers. Learn to integrate AI-powered coding assistance, automate testing, and boost collaboration using Visual Studio Code and Copilot Chat. From autocompletion to unit testing, cover essential techniques for cleaner, faster, smarter code.
crewAI-quickstart
CrewAI quickstart is a small project providing starter templates for an easy start with CrewAI. It includes notebooks, Python scripts, GUI with Streamlit, and Local LLMs for various tasks like web search, CSV lookup, web scraping, PDF search, and more. Contributions are welcome to enhance the project.
MMLU-Pro
MMLU-Pro is an enhanced benchmark designed to evaluate language understanding models across broader and more challenging tasks. It integrates more challenging, reasoning-focused questions and increases answer choices per question, significantly raising difficulty. The dataset comprises over 12,000 questions from academic exams and textbooks across 14 diverse domains. Experimental results show a significant drop in accuracy compared to the original MMLU, with greater stability under varying prompts. Models utilizing Chain of Thought reasoning achieved better performance on MMLU-Pro.
For similar tasks
ml-road-map
The Machine Learning Road Map is a comprehensive guide designed to take individuals from various levels of machine learning knowledge to a basic understanding of machine learning principles using high-quality, free resources. It aims to simplify the complex and rapidly growing field of machine learning by providing a structured roadmap for learning. The guide emphasizes the importance of understanding AI for everyone, the need for patience in learning machine learning due to its complexity, and the value of learning from experts in the field. It covers five different paths to learning about machine learning, catering to consumers, aspiring AI researchers, ML engineers, developers interested in building ML applications, and companies looking to implement AI solutions.

God-Level-AI
A drill of scientific methods, processes, algorithms, and systems to build stories & models. An in-depth learning resource for humans. This repository is designed for individuals aiming to excel in the field of Data and AI, providing video sessions and text content for learning. It caters to those in leadership positions, professionals, and students, emphasizing the need for dedicated effort to achieve excellence in the tech field. The content covers various topics with a focus on practical application.
ai_igu
AI-IGU is a GitHub repository focused on Artificial Intelligence (AI) concepts, technology, software development, and algorithm improvement for all ages and professions. It emphasizes the importance of future software for future scientists and the increasing need for software developers in the industry. The repository covers various topics related to AI, including machine learning, deep learning, data mining, data science, big data, and more. It provides educational materials, practical examples, and hands-on projects to enhance software development skills and create awareness in the field of AI.
AI-PhD-S24
AI-PhD-S24 is a mono-repo for the PhD course 'AI for Business Research' at CUHK Business School in Spring 2024. The course aims to provide a basic understanding of machine learning and artificial intelligence concepts/methods used in business research, showcase how ML/AI is utilized in business research, and introduce state-of-the-art AI/ML technologies. The course includes scribed lecture notes, class recordings, and covers topics like AI/ML fundamentals, DL, NLP, CV, unsupervised learning, and diffusion models.
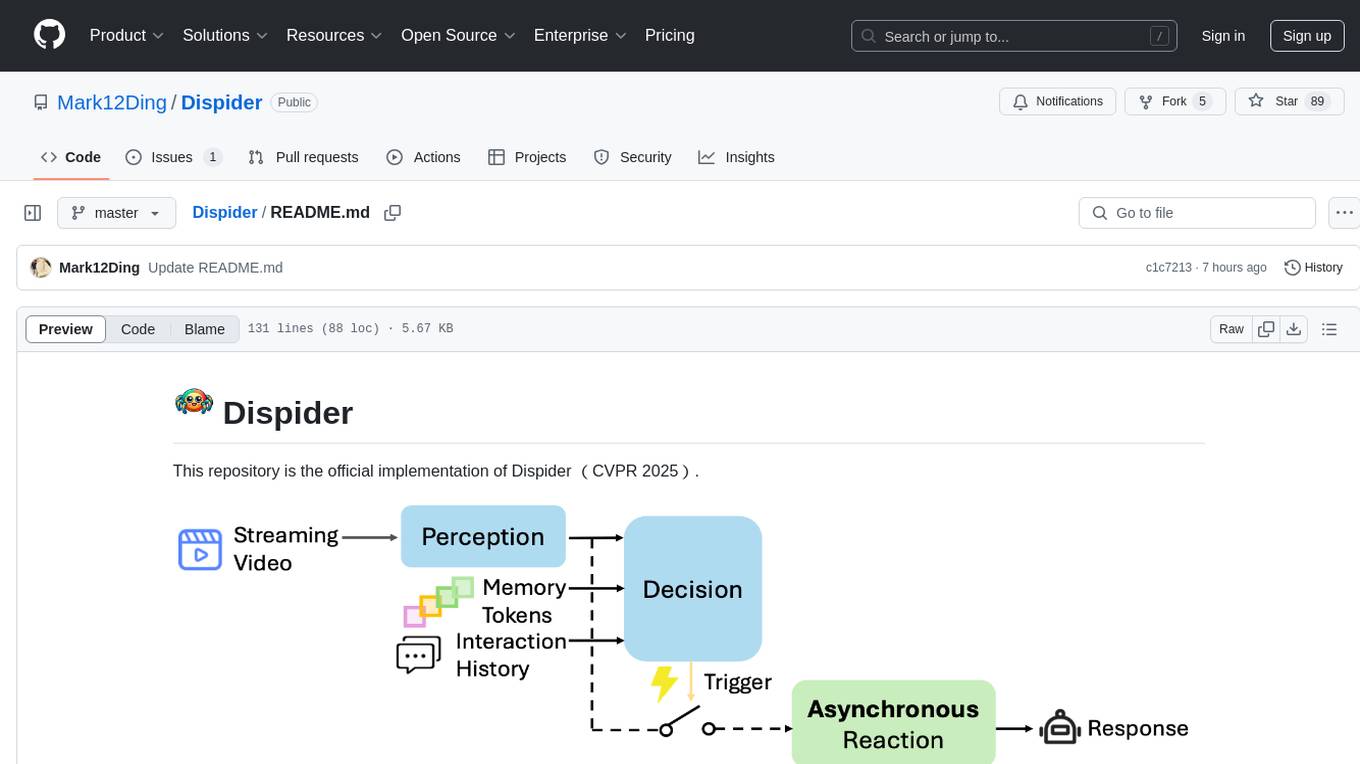
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
AI-PhD-S25
AI-PhD-S25 is a mono-repo for the DOTE 6635 course on AI for Business Research at CUHK Business School. The course aims to provide a fundamental understanding of ML/AI concepts and methods relevant to business research, explore applications of ML/AI in business research, and discover cutting-edge AI/ML technologies. The course resources include Google CoLab for code distribution, Jupyter Notebooks, Google Sheets for group tasks, Overleaf template for lecture notes, replication projects, and access to HPC Server compute resource. The course covers topics like AI/ML in business research, deep learning basics, attention mechanisms, transformer models, LLM pretraining, posttraining, causal inference fundamentals, and more.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.