
pytest-evals
A pytest plugin for running and analyzing LLM evaluation tests.
Stars: 83

pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.
README:
Test your LLM outputs against examples - no more manual checking! A (minimalistic) pytest plugin that helps you to evaluate that your LLM is giving good answers.




Building LLM applications is exciting, but how do you know they're actually working well? pytest-evals helps you:
- 🎯 Test & Evaluate: Run your LLM prompt against many cases
- 📈 Track & Measure: Collect metrics and analyze the overall performance
- 🔄 Integrate Easily: Works with pytest, Jupyter notebooks, and CI/CD pipelines
- ✨ Scale Up: Run tests in parallel with
pytest-xdistand asynchronously withpytest-asyncio.
To get started, install pytest-evals and write your tests:
pip install pytest-evalsFor example, say you're building a support ticket classifier. You want to test cases like:
| Input Text | Expected Classification |
|---|---|
| My login isn't working and I need to access my account | account_access |
| Can I get a refund for my last order? | billing |
| How do I change my notification settings? | settings |
pytest-evals helps you automatically test how your LLM perform against these cases, track accuracy, and ensure it
keeps working as expected over time.
# Predict the LLM performance for each case
@pytest.mark.eval(name="my_classifier")
@pytest.mark.parametrize("case", TEST_DATA)
def test_classifier(case: dict, eval_bag, classifier):
# Run predictions and store results
eval_bag.prediction = classifier(case["Input Text"])
eval_bag.expected = case["Expected Classification"]
eval_bag.accuracy = eval_bag.prediction == eval_bag.expected
# Now let's see how our app performing across all cases...
@pytest.mark.eval_analysis(name="my_classifier")
def test_analysis(eval_results):
accuracy = sum([result.accuracy for result in eval_results]) / len(eval_results)
print(f"Accuracy: {accuracy:.2%}")
assert accuracy >= 0.7 # Ensure our performance is not degrading 🫢Then, run your evaluation tests:
# Run test cases
pytest --run-eval
# Analyze results
pytest --run-eval-analysisEvaluations are just tests. No need for complex frameworks or DSLs. pytest-evals is minimalistic by design:
- Use
pytest- the tool you already know - Keep tests and evaluations together
- Focus on logic, not infrastructure
It just collects your results and lets you analyze them as a whole. Nothing more, nothing less.
Check out our detailed guides and examples:
Built on top of pytest-harvest, pytest-evals splits evaluation into
two phases:
-
Evaluation Phase: Run all test cases, collecting results and metrics in
eval_bag. The results are saved in a temporary file to allow the analysis phase to access them. -
Analysis Phase: Process all results at once through
eval_resultsto calculate final metrics
This split allows you to:
- Run evaluations in parallel (since the analysis test MUST run after all cases are done, we must run them separately)
- Make pass/fail decisions on the overall evaluation results instead of individual test failures (by passing the
--supress-failed-exit-code --run-evalflags) - Collect comprehensive metrics
Note: When running evaluation tests, the rest of your test suite will not run. This is by design to keep the results clean and focused.
By default, pytest-evals saves the results of each case in a json file to allow the analysis phase to access them.
However, this might not be a friendly format for deeper analysis. To save the results in a more friendly format, as a
CSV file, use the --save-evals-csv flag:
pytest --run-eval --save-evals-csvIt's also possible to run evaluations from a notebook. To do that, simply install ipytest, and load the extension:
%load_ext pytest_evalsThen, use the magic commands %%ipytest_eval in your cell to run evaluations. This will run the evaluation phase and
then the analysis phase. By default, using this magic will run both --run-eval and --run-eval-analysis, but you can
specify your own flags by passing arguments right after the magic command (e.g., %%ipytest_eval --run-eval).
%%ipytest_eval
import pytest
@pytest.mark.eval(name="my_eval")
def test_agent(eval_bag):
eval_bag.prediction = agent.run(case["input"])
@pytest.mark.eval_analysis(name="my_eval")
def test_analysis(eval_results):
print(f"F1 Score: {calculate_f1(eval_results):.2%}")You can see an example of this in the example/example_notebook.ipynb notebook. Or
look at the advanced example for a more complex example that tracks multiple
experiments.
It's recommended to use a CSV file to store test data. This makes it easier to manage large datasets and allows you to communicate with non-technical stakeholders.
To do this, you can use pandas to read the CSV file and pass the test cases as parameters to your tests using
@pytest.mark.parametrize 🙃 :
import pandas as pd
import pytest
test_data = pd.read_csv("tests/testdata.csv")
@pytest.mark.eval(name="my_eval")
@pytest.mark.parametrize("case", test_data.to_dict(orient="records"))
def test_agent(case, eval_bag, agent):
eval_bag.prediction = agent.run(case["input"])In case you need to select a subset of the test data (e.g., a golden set), you can simply define an environment variable
to indicate that, and filter the data with pandas.
Run tests and analysis as separate steps:
evaluate:
steps:
- run: pytest --run-eval -n auto --supress-failed-exit-code # Run cases in parallel
- run: pytest --run-eval-analysis # Analyze resultsUse --supress-failed-exit-code with --run-eval - let the analysis phase determine success/failure. If all your
cases pass, your evaluation set is probably too small!
As your evaluation set grows, you may want to run your test cases in parallel. To do this, install
pytest-xdist. pytest-evals will support that out of the box 🚀.
run: pytest --run-eval -n autoContributions make the open-source community a fantastic place to learn, inspire, and create. Any contributions you make are greatly appreciated (not only code! but also documenting, blogging, or giving us feedback) 😍.
Please fork the repo and create a pull request if you have a suggestion. You can also simply open an issue to give us some feedback.
Don't forget to give the project a star! ⭐️
For more information about contributing code to the project, read the CONTRIBUTING.md guide.
This project is licensed under the MIT License - see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pytest-evals
Similar Open Source Tools
pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.

eval-dev-quality
DevQualityEval is an evaluation benchmark and framework designed to compare and improve the quality of code generation of Language Model Models (LLMs). It provides developers with a standardized benchmark to enhance real-world usage in software development and offers users metrics and comparisons to assess the usefulness of LLMs for their tasks. The tool evaluates LLMs' performance in solving software development tasks and measures the quality of their results through a point-based system. Users can run specific tasks, such as test generation, across different programming languages to evaluate LLMs' language understanding and code generation capabilities.

tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.

garak
Garak is a vulnerability scanner designed for LLMs (Large Language Models) that checks for various weaknesses such as hallucination, data leakage, prompt injection, misinformation, toxicity generation, and jailbreaks. It combines static, dynamic, and adaptive probes to explore vulnerabilities in LLMs. Garak is a free tool developed for red-teaming and assessment purposes, focusing on making LLMs or dialog systems fail. It supports various LLM models and can be used to assess their security and robustness.

garak
Garak is a free tool that checks if a Large Language Model (LLM) can be made to fail in a way that is undesirable. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Garak's a free tool. We love developing it and are always interested in adding functionality to support applications.

AI-Scientist
The AI Scientist is a comprehensive system for fully automatic scientific discovery, enabling Foundation Models to perform research independently. It aims to tackle the grand challenge of developing agents capable of conducting scientific research and discovering new knowledge. The tool generates papers on various topics using Large Language Models (LLMs) and provides a platform for exploring new research ideas. Users can create their own templates for specific areas of study and run experiments to generate papers. However, caution is advised as the codebase executes LLM-written code, which may pose risks such as the use of potentially dangerous packages and web access.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

OlympicArena
OlympicArena is a comprehensive benchmark designed to evaluate advanced AI capabilities across various disciplines. It aims to push AI towards superintelligence by tackling complex challenges in science and beyond. The repository provides detailed data for different disciplines, allows users to run inference and evaluation locally, and offers a submission platform for testing models on the test set. Additionally, it includes an annotation interface and encourages users to cite their paper if they find the code or dataset helpful.

LiveBench
LiveBench is a benchmark tool designed for Language Model Models (LLMs) with a focus on limiting contamination through monthly new questions based on recent datasets, arXiv papers, news articles, and IMDb movie synopses. It provides verifiable, objective ground-truth answers for accurate scoring without an LLM judge. The tool offers 18 diverse tasks across 6 categories and promises to release more challenging tasks over time. LiveBench is built on FastChat's llm_judge module and incorporates code from LiveCodeBench and IFEval.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic
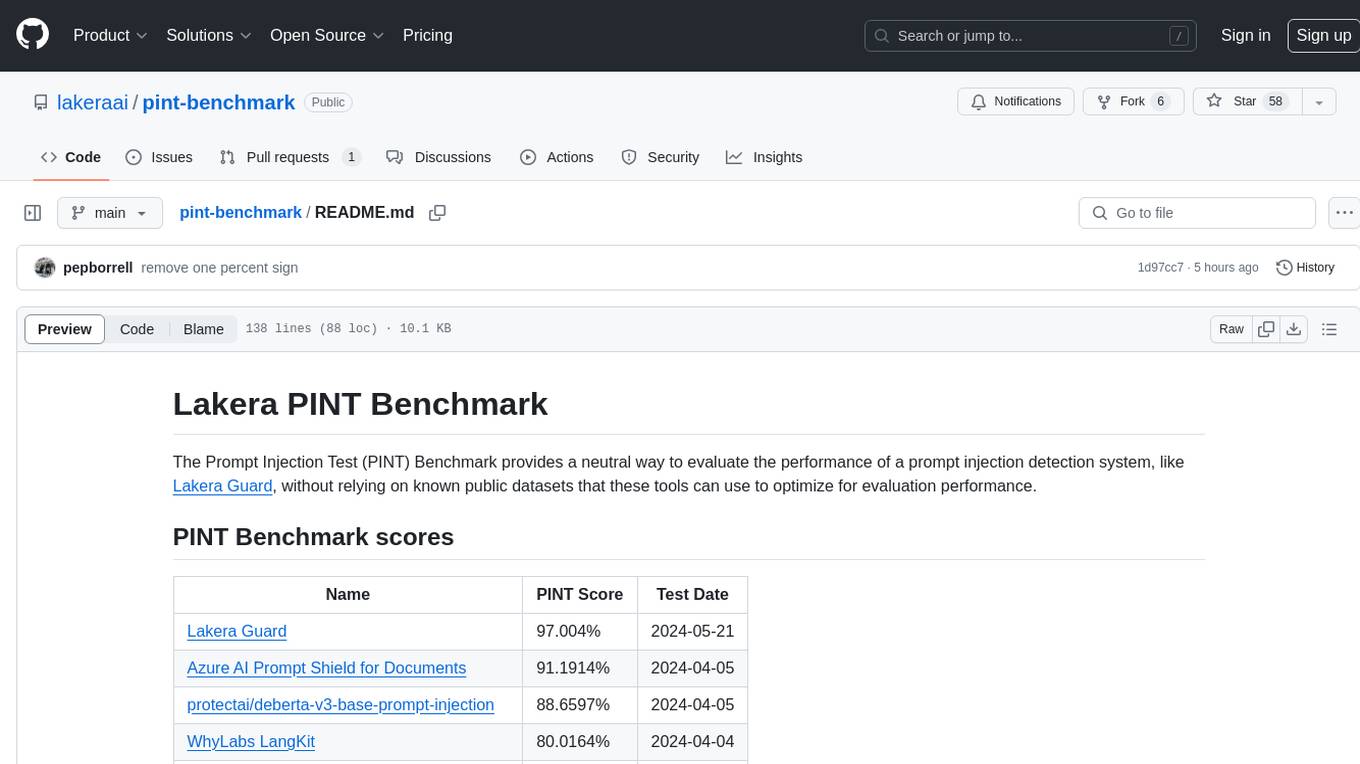
pint-benchmark
The Lakera PINT Benchmark provides a neutral evaluation method for prompt injection detection systems, offering a dataset of English inputs with prompt injections, jailbreaks, benign inputs, user-agent chats, and public document excerpts. The dataset is designed to be challenging and representative, with plans for future enhancements. The benchmark aims to be unbiased and accurate, welcoming contributions to improve prompt injection detection. Users can evaluate prompt injection detection systems using the provided Jupyter Notebook. The dataset structure is specified in YAML format, allowing users to prepare their datasets for benchmarking. Evaluation examples and resources are provided to assist users in evaluating prompt injection detection models and tools.
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.

physical-AI-interpretability
Physical AI Interpretability is a toolkit for transformer-based Physical AI and robotics models, providing tools for attention mapping, feature extraction, and out-of-distribution detection. It includes methods for post-hoc attention analysis, applying Dictionary Learning into robotics, and training sparse autoencoders. The toolkit aims to enhance interpretability and understanding of AI models in physical environments.
For similar tasks
pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.