Best AI tools for< Test Llm Outputs >
20 - AI tool Sites

LLM Clash
LLM Clash is a web-based application that allows users to compare the outputs of different large language models (LLMs) on a given task. Users can input a prompt and select which LLMs they want to compare. The application will then display the outputs of the LLMs side-by-side, allowing users to compare their strengths and weaknesses.
PromptPoint Playground
PromptPoint Playground is an AI tool designed to help users design, test, and deploy prompts quickly and efficiently. It enables teams to create high-quality LLM outputs through automatic testing and evaluation. The platform allows users to make non-deterministic prompts predictable, organize prompt configurations, run automated tests, and monitor usage. With a focus on collaboration and accessibility, PromptPoint Playground empowers both technical and non-technical users to leverage the power of large language models for prompt engineering.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.
Prompt Hippo
Prompt Hippo is an AI tool designed as a side-by-side LLM prompt testing suite to ensure the robustness, reliability, and safety of prompts. It saves time by streamlining the process of testing LLM prompts and allows users to test custom agents and optimize them for production. With a focus on science and efficiency, Prompt Hippo helps users identify the best prompts for their needs.
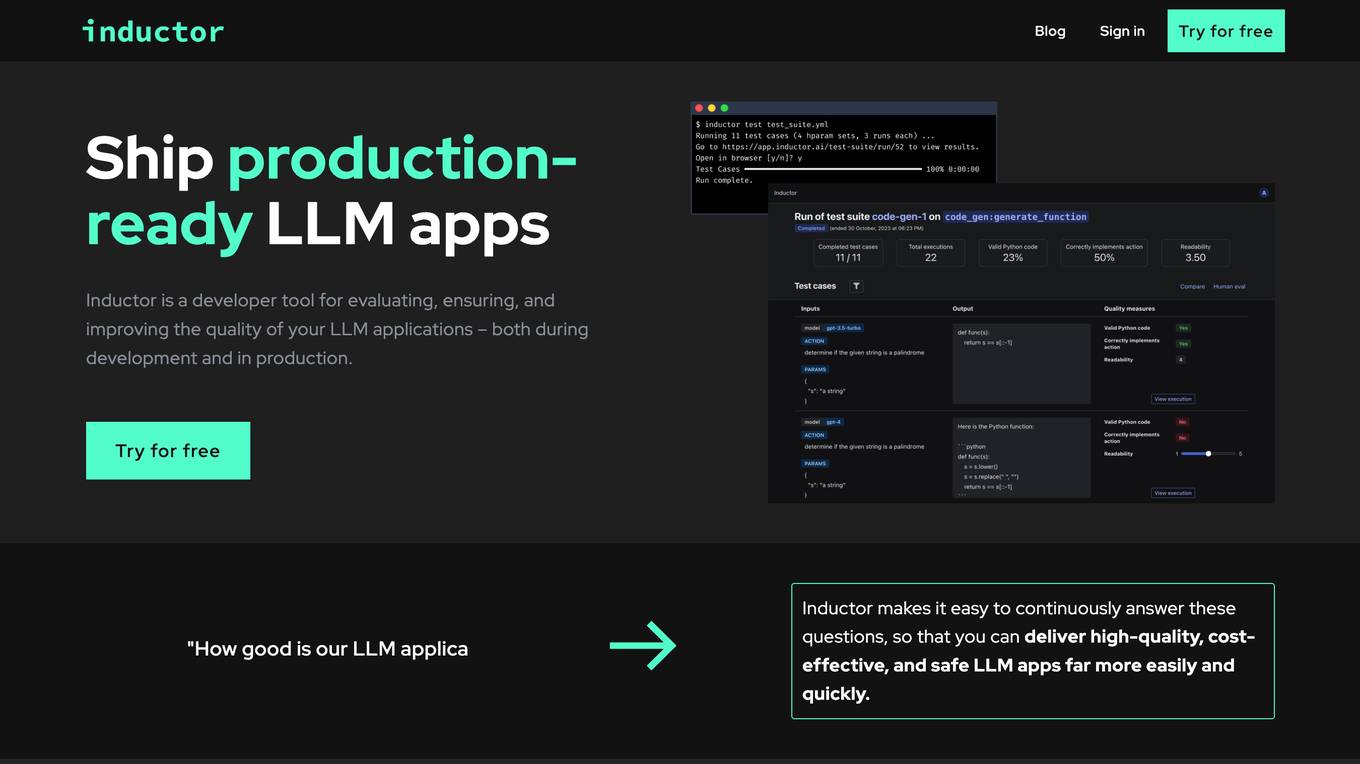
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
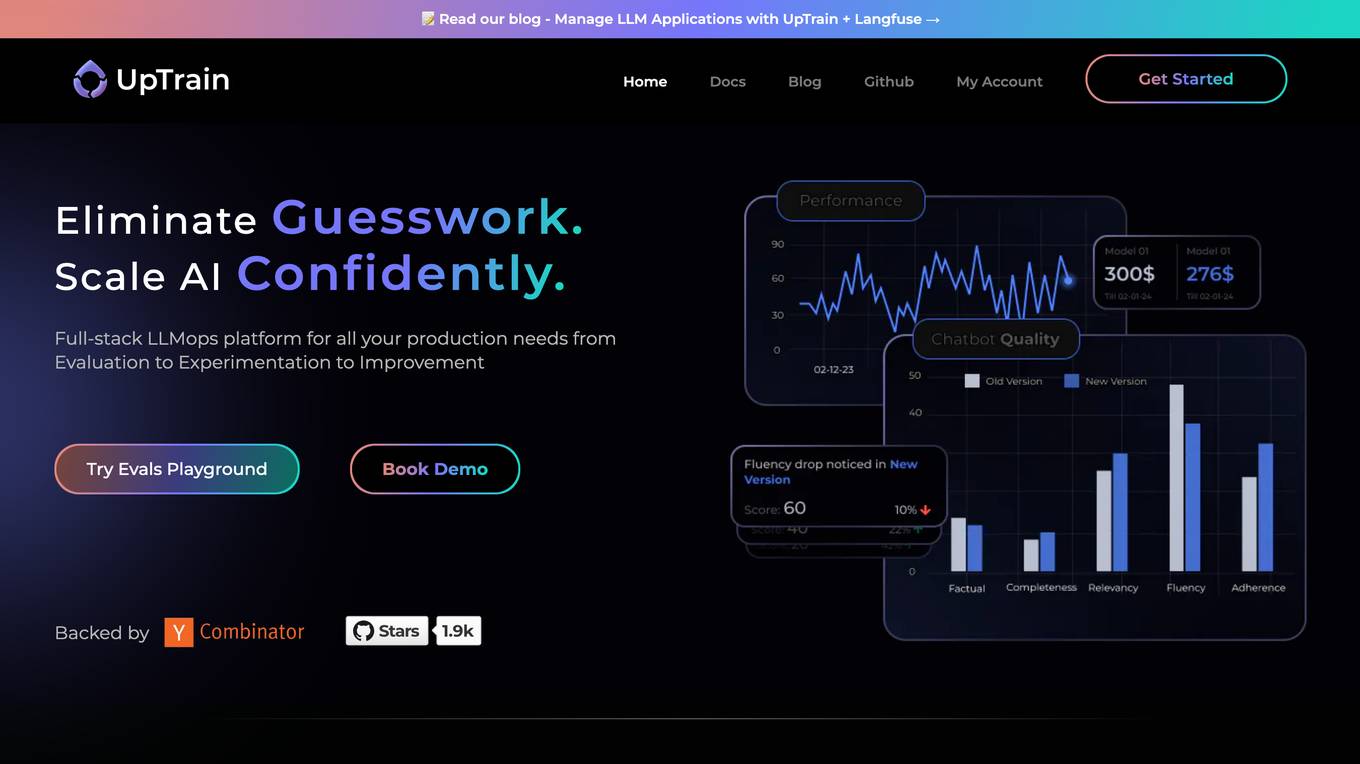
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
AARENA
AARENA is an AI-powered platform that allows users to build fully functional apps and websites through simple conversations. It provides a user-friendly interface where individuals can create various digital products without the need for coding knowledge. AARENA leverages AI technology to streamline the development process and empower users to bring their ideas to life efficiently.
Grit Brokerage
Grit Brokerage is a domain and website brokerage platform that facilitates the buying and selling of domains. The platform allows users to inquire about domain prices, submit offers, and connect with domain brokers. With a focus on domain transactions, Grit Brokerage provides a seamless experience for individuals and businesses looking to acquire or sell domain names.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
Langtail
Langtail is a platform that helps developers build, test, and deploy AI-powered applications. It provides a suite of tools to help developers debug prompts, run tests, and monitor the performance of their AI models. Langtail also offers a community forum where developers can share tips and tricks, and get help from other users.
AIMLAPI.com
AIMLAPI.com is an AI tool that provides access to over 200 AI models through a single AI API. It offers a wide range of AI features for tasks such as chat, code, image generation, music generation, video, voice embedding, language, genomic models, and 3D generation. The platform ensures fast inference, top-tier serverless infrastructure, high data security, 99% uptime, and 24/7 support. Users can integrate AI features easily into their products and test API models in a sandbox environment before deployment.
Lakera
Lakera is the world's most advanced AI security platform that offers cutting-edge solutions to safeguard GenAI applications against various security threats. Lakera provides real-time security controls, stress-testing for AI systems, and protection against prompt attacks, data loss, and insecure content. The platform is powered by a proprietary AI threat database and aligns with global AI security frameworks to ensure top-notch security standards. Lakera is suitable for security teams, product teams, and LLM builders looking to secure their AI applications effectively and efficiently.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
Tonic.ai
Tonic.ai is a platform that allows users to build AI models on their unstructured data. It offers various products for software development and LLM development, including tools for de-identifying and subsetting structured data, scaling down data, handling semi-structured data, and managing ephemeral data environments. Tonic.ai focuses on standardizing, enriching, and protecting unstructured data, as well as validating RAG systems. The platform also provides integrations with relational databases, data lakes, NoSQL databases, flat files, and SaaS applications, ensuring secure data transformation for software and AI developers.
DeepEval
DeepEval by Confident AI is a comprehensive LLM Evaluation Framework used by leading AI companies. It enables users to build reliable evaluation pipelines to test any AI system. With 50+ research-backed metrics, native multi-modal support, and auto-optimization of prompts, DeepEval offers a sophisticated evaluation ecosystem for AI applications. The framework covers unit-testing for LLMs, single and multi-turn evaluations, generation & simulation of test data, and state-of-the-art evaluation techniques like G-Eval and DAG. DeepEval is integrated with Pytest and supports various system architectures, making it a versatile tool for AI testing.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.

Haystack
Haystack is a production-ready open-source AI framework designed to facilitate building AI applications. It offers a flexible components and pipelines architecture, allowing users to customize and build applications according to their specific requirements. With partnerships with leading LLM providers and AI tools, Haystack provides freedom of choice for users. The framework is built for production, with fully serializable pipelines, logging, monitoring integrations, and deployment guides for full-scale deployments on various platforms. Users can build Haystack apps faster using deepset Studio, a platform for drag-and-drop construction of pipelines, testing, debugging, and sharing prototypes.
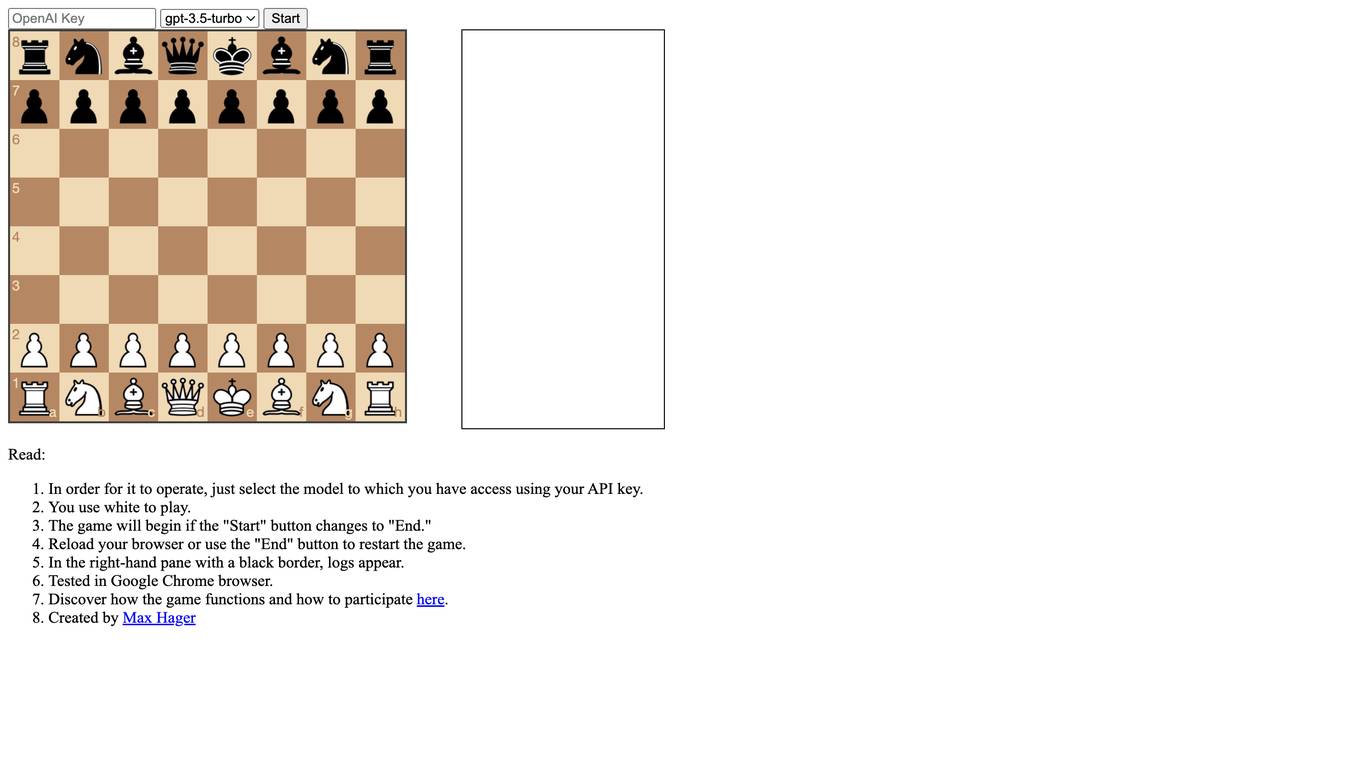
LLMChess
LLMChess is a web-based chess game that utilizes large language models (LLMs) to power the gameplay. Players can select the LLM model they wish to play against, and the game will commence once the "Start" button is clicked. The game logs are displayed in a black-bordered pane on the right-hand side of the screen. LLMChess is compatible with the Google Chrome browser. For more information on the game's functionality and participation guidelines, please refer to the provided link.

Freeplay
Freeplay is a tool that helps product teams experiment, test, monitor, and optimize AI features for customers. It provides a single pane of glass for the entire team, lightweight developer SDKs for Python, Node, and Java, and deployment options to meet compliance needs. Freeplay also offers best practices for the entire AI development lifecycle.
1 - Open Source AI Tools

pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.
20 - OpenAI Gpts
HackMeIfYouCan
Hack Me if you can - I can only talk to you about computer security, software security and LLM security @JacquesGariepy
Test Shaman
Test Shaman: Guiding software testing with Grug wisdom and humor, balancing fun with practical advice.
Raven's Progressive Matrices Test
Provides Raven's Progressive Matrices test with explanations and calculates your IQ score.

IQ Test Assistant
An AI conducting 30-question IQ tests, assessing and providing detailed feedback.
Test Case GPT
I will provide guidance on testing, verification, and validation for QA roles.

GRE Test Vocabulary Learning
Helps user learn essential vocabulary for GRE test with multiple choice questions
Lab Test Insights
I'm your lab test consultant for blood tests and microbial cultures. How can I help you today?


Cyber Test & CareerPrep
Helping you study for cybersecurity certifications and get the job you want!
Complete Apex Test Class Assistant
Crafting full, accurate Apex test classes, with 100% user service.