
tonic_validate
Metrics to evaluate the quality of responses of your Retrieval Augmented Generation (RAG) applications.
Stars: 233

Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
README:



A high performance LLM/RAG evaluation framework
Explore the docs »
Enhance your data for RAG »
Report Bug
·
Request Feature
·
Quick Start
Table of Contents
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
The foundation of a high-performing RAG systems is quality, secure data. High-quality data ensures that the information retrieved and generated is accurate, relevant, and reliable, which enhances the system's overall performance and user trust. Security, on the other hand, protects this valuable data from breaches, ensuring that sensitive information remains confidential and tamper-proof. Together, they form the bedrock of a robust RAG system, facilitating efficient, trustworthy retrieval and generation.
We are excited to introduce Tonic Textual, a powerful companion to Tonic Validate that can help improve your RAG system's performance. We created Tonic Textual to simplify and augment the data pre-processing for RAG systems. In just a few minutes, you can build automated unstructured data pipelines that extract text from unstructured data, detect and de-identify sensitive information, and transform the data into a format optimized for RAG systems. We also enrich your data with document metadata and contextual entity tags to build semantic entity graphs that ground your RAG system in truth, preventing hallucinations and improving the overall quality of the generated outputs.
You can learn more and try the tool completely free here. We'd love to hear what you think!
This is an example of how you may give instructions on setting up your project locally. To get a local copy up and running follow these simple example steps.
-
Install Tonic Validate
pip install tonic-validate -
Use the following code snippet to get started.
from tonic_validate import ValidateScorer, Benchmark import os os.environ["OPENAI_API_KEY"] = "your-openai-key" # Function to simulate getting a response and context from your LLM # Replace this with your actual function call def get_llm_response(question): return { "llm_answer": "Paris", "llm_context_list": ["Paris is the capital of France."] } benchmark = Benchmark(questions=["What is the capital of France?"], answers=["Paris"]) # Score the responses for each question and answer pair scorer = ValidateScorer() run = scorer.score(benchmark, get_llm_response)
This code snippet, creates a benchmark with one question and reference answer and then scores the answer. Providing a reference answer is not required for most metrics (see below Metrics table).
Many users find value in running evaluations during the code review/pull request process. You can create your own automation here using the snippet above and knowledge found in our documentation and this readme OR you can take advantage of our absolutely free Github Action in the Github Marketplace. The listing is here. It's easy to setup but if you have any questions, just create an issue in the corresponding repository.
Metrics are used to score your LLM's performance. Validate ships with many different metrics which are applicable to most RAG systems. You can create your own metrics as well by providing your own implementation of metric.py. To compute a metric, you must provide it data from your RAG application. The table below shows a few of the many metrics we offer with Tonic Validate. For more detail explanations of our metrics refer to our documentation.
| Metric Name | Inputs | Score Range | What does it measure? |
|---|---|---|---|
| Answer similarity score |
QuestionReference answerLLM answer
|
0 to 5 | How well the reference answer matches the LLM answer. |
| Retrieval precision |
QuestionRetrieved Context
|
0 to 1 | Whether the context retrieved is relevant to answer the given question. |
| Augmentation precision |
QuestionRetrieved ContextLLM answer
|
0 to 1 | Whether the relevant context is in the LLM answer. |
| Augmentation accuracy |
Retrieved ContextLLM answer
|
0 to 1 | Whether all the context is in the LLM answer. |
| Answer consistency |
Retrieved ContextLLM answer
|
0 to 1 | Whether there is information in the LLM answer that does not come from the context. |
| Latency | Run Time |
0 or 1 | Measures how long it takes for the LLM to complete a request. |
| Contains Text | LLM Answer |
0 or 1 | Checks whether or not response contains the given text. |
Metric inputs in Tonic Validate are used to provide the metrics with the information they need to calculate performance. Below, we explain each input type and how to pass them into Tonic Validate's SDK.
What is it: The question asked
How to use: You can provide the questions by passing them into the Benchmark via the questions argument.
from tonic_validate import Benchmark
benchmark = Benchmark(
questions=["What is the capital of France?", "What is the capital of Germany?"]
)What is it: A prewritten answer that serves as the ground truth for how the RAG application should answer the question.
How to use: You can provide the reference answers by passing it into the Benchmark via the answers argument. Each reference answer must correspond to a given question. So if the reference answer is for the third question in the questions list, then the reference answer must also be the third item in the answers list. The only metric that requires a reference answer is the Answer Similarity Score
from tonic_validate import Benchmark
benchmark = Benchmark(
questions=["What is the capital of France?", "What is the capital of Germany?"]
answers=["Paris", "Berlin"]
)What is it: The answer the RAG application / LLM gives to the question.
How to use: You can provide the LLM answer via the callback you provide to the Validate scorer. The answer is the first item in the tuple response.
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)If you are manually logging the answers without using the callback, then you can provide the LLM answer via llm_answer when creating the LLMResponse.
from tonic_validate import LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
# llm_answer is the answer that LLM gives
llm_response = LLMResponse(
llm_answer="Paris",
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)What is it: The context that your RAG application retrieves when answering a given question. This context is what's put in the prompt by the RAG application to help the LLM answer the question.
How to use: You can provide the LLM's retrieved context list via the callback you provide to the Validate scorer. The answer is the second item in the tuple response. The retrieved context is always a list
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)If you are manually logging the answers, then you can provide the LLM context via llm_context_list when creating the LLMResponse.
from tonic_validate import LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
# llm_answer is the answer that LLM gives
# llm_context_list is a list of the context that the LLM used to answer the question
llm_response = LLMResponse(
llm_answer="Paris",
llm_context_list=["Paris is the capital of France."],
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)What is it: Used for the latency metric to measure how long it took the LLM to respond.
How to use: If you are using the Validate scorer callback, then this metric is automatically calculated for you. If you are manually creating the LLM responses, then you need to provide how long the LLM took yourself via the run_time argument.
from tonic_validate import LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
run_time = # Float representing how many seconds the LLM took to respond
# llm_answer is the answer that LLM gives
# llm_context_list is a list of the context that the LLM used to answer the question
llm_response = LLMResponse(
llm_answer="Paris",
llm_context_list=["Paris is the capital of France."],
benchmark_item=item
run_time=run_time
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)Most metrics are scored with the assistance of a LLM. Validate supports OpenAI and Azure OpenAI but other LLMs can easily be integrated (just file an github issue against this repository).
In order to use OpenAI you must provide an OpenAI API Key.
import os
os.environ["OPENAI_API_KEY"] = "put-your-openai-api-key-here"If you already have the OPENAI_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
If you are using Azure, instead of setting the OPENAI_API_KEY environment variable, you instead need to set AZURE_OPENAI_API_KEY and AZURE_OPENAI_ENDPOINT. AZURE_OPENAI_ENDPOINT is the endpoint url for your Azure OpenAI deployment and AZURE_OPENAI_API_KEY is your API key.
import os
os.environ["AZURE_OPENAI_API_KEY"] = "put-your-azure-openai-api-key-here"
os.environ["AZURE_OPENAI_ENDPOINT"] = "put-your-azure-endpoint-here"If you already have the GEMINI_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
import os
os.environ["GEMINI_API_KEY"] = "put-your-gemini-api-key-here"Note that to use gemini, your Python version must be 3.9 or higher.
If you already have the ANTHROPIC_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
import os
os.environ["ANTHROPIC_API_KEY"] = "put-your-anthropic-api-key-here"If you already have the MISTRAL_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
import os
os.environ["MISTRAL_API_KEY"] = "put-your-mistral-api-key-here"If you already have the COHERE_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
import os
os.environ["COHERE_API_KEY"] = "put-your-cohere-api-key-here"If you already have the TOGETHERAI_API_KEY set in your system's environment variables then you can skip this step. Otherwise, please set the environment variable before proceeding.
import os
os.environ["TOGETHERAI_API_KEY"] = "put-your-togetherai-api-key-here"If you already have the "AWS_SECRET_ACCESS_KEY, AWS_ACCESS_KEY_ID, and AWS_REGION_NAME set in your system's environment variables then you can skip this step. Otherwise, please set the environment variables before proceeding.
import os
os.environ["AWS_ACCESS_KEY_ID"]="put-your-aws-access-key-id-here"
os.environ["AWS_SECRET_ACCESS_KEY"]="put-your-aws-secret-access-key-here"
os.environ["AWS_REGION_NAME"]="put-your-aws-region-name-here"To use metrics, instantiate an instance of ValidateScorer.
from tonic_validate import ValidateScorer
scorer = ValidateScorer()The default model used for scoring metrics is GPT 4 Turbo. To change the OpenAI model, pass the OpenAI model name into the model_evaluator argument for ValidateScorer. You can also pass in custom metrics via an array of metrics.
from tonic_validate import ValidateScorer
from tonic_validate.metrics import AnswerConsistencyMetric, AnswerSimilarityMetric
scorer = ValidateScorer([
AnswerConsistencyMetric(),
AugmentationAccuracyMetric()
], model_evaluator="gpt-3.5-turbo")You can also pass in other models like Google Gemini, Claude, Mistral, Cohere, Together AI, and AWS Bedrock by setting the model_evaluator argument to the model name like so
scorer = ValidateScorer(model_evaluator="gemini/gemini-1.5-pro-latest")scorer = ValidateScorer(model_evaluator="claude-3")scorer = ValidateScorer(model_evaluator="mistral/mistral-tiny")scorer = ValidateScorer(model_evaluator="command-r")scorer = ValidateScorer(model_evaluator="together_ai/togethercomputer/Llama-2-7B-32K-Instruct")scorer = ValidateScorer(model_evaluator="bedrock/your-bedrock-model")If an error occurs while scoring an item's metric, the score for that metric will be set to None. If you instead wish to have Tonic Validate throw an exception when there's an error scoring, then set fail_on_error to True in the constructor
scorer = ValidateScorer(fail_on_error=True)If you are using Azure, you MUST set the model_evaluator argument to your deployment name like so
scorer = ValidateScorer(model_evaluator="your-deployment-name")If you are using AWS Bedrock, you MUST set the model_evaluator argument to your endpoint name and the model_id argument to your model name like so
scorer = ValidateScorer(model_evaluator="your-endpoint-name", model_id="your-model-name")After you instantiate the ValidateScorer with your desired metrics, you can then score the metrics using the callback you defined earlier.
from tonic_validate import ValidateScorer, ValidateApi
# Function to simulate getting a response and context from your LLM
# Replace this with your actual function call
def get_rag_response(question):
return {
"llm_answer": "Paris",
"llm_context_list": ["Paris is the capital of France."]
}
# Score the responses
scorer = ValidateScorer()
run = scorer.score(benchmark, ask_rag)If you don't want to use the callback, you can instead log your answers manually by iterating over the benchmark and then score the answers.
from tonic_validate import ValidateScorer, LLMResponse
# Save the responses into an array for scoring
responses = []
for item in benchmark:
llm_response = LLMResponse(
llm_answer="Paris",
llm_context_list=["Paris is the capital of France"],
benchmark_item=item
)
responses.append(llm_response)
# Score the responses
scorer = ValidateScorer()
run = scorer.score_responses(responses)There are two ways to view the results of a run.
You can manually print out the results via python like so
print("Overall Scores")
print(run.overall_scores)
print("------")
for item in run.run_data:
print("Question: ", item.reference_question)
print("Answer: ", item.reference_answer)
print("LLM Answer: ", item.llm_answer)
print("LLM Context: ", item.llm_context)
print("Scores: ", item.scores)
print("------")which outputs the following
Overall Scores
{'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
Question: What is the capital of France?
Answer: Paris
LLM Answer: Paris
LLM Context: ['Paris is the capital of France.']
Scores: {'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
Question: What is the capital of Spain?
Answer: Madrid
LLM Answer: Paris
LLM Context: ['Paris is the capital of France.']
Scores: {'answer_consistency': 1.0, 'augmentation_accuracy': 1.0}
------
You can easily view your run results by uploading them to our free to use UI. The main advantage of this method is the Tonic Validate UI provides graphing for your results along with additional visualization features. To sign up for the UI, go to here.
Once you sign up for the UI, you will go through an onboarding to create an API Key and Project.
Copy both the API Key and Project ID from the onboarding and insert it into the following code
from tonic_validate import ValidateApi
validate_api = ValidateApi("your-api-key")
validate_api.upload_run("your-project-id", run)
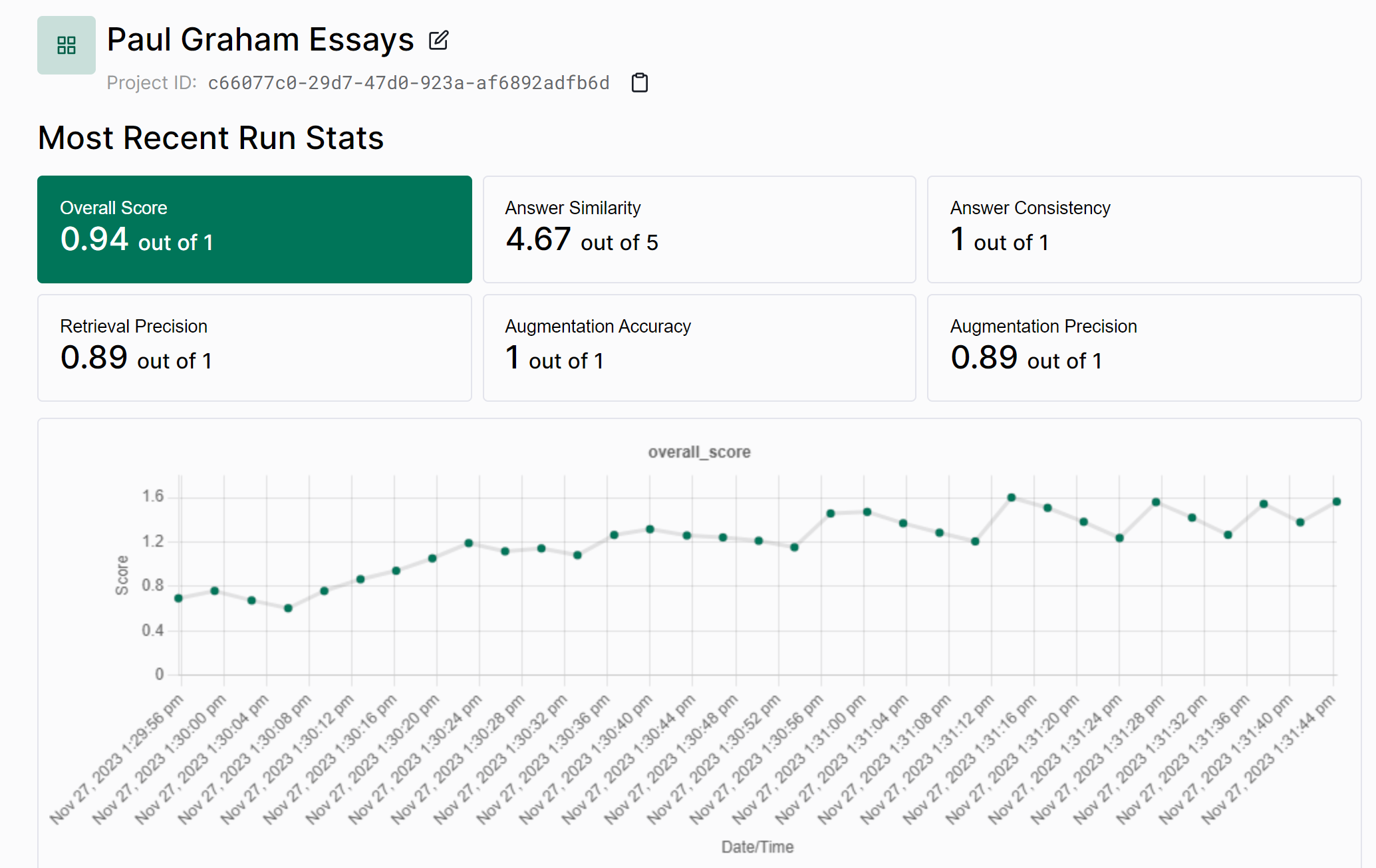
This will upload your run to the Tonic Validate UI where you can view the results. On the home page (as seen below) you can view the change in scores across runs over time.
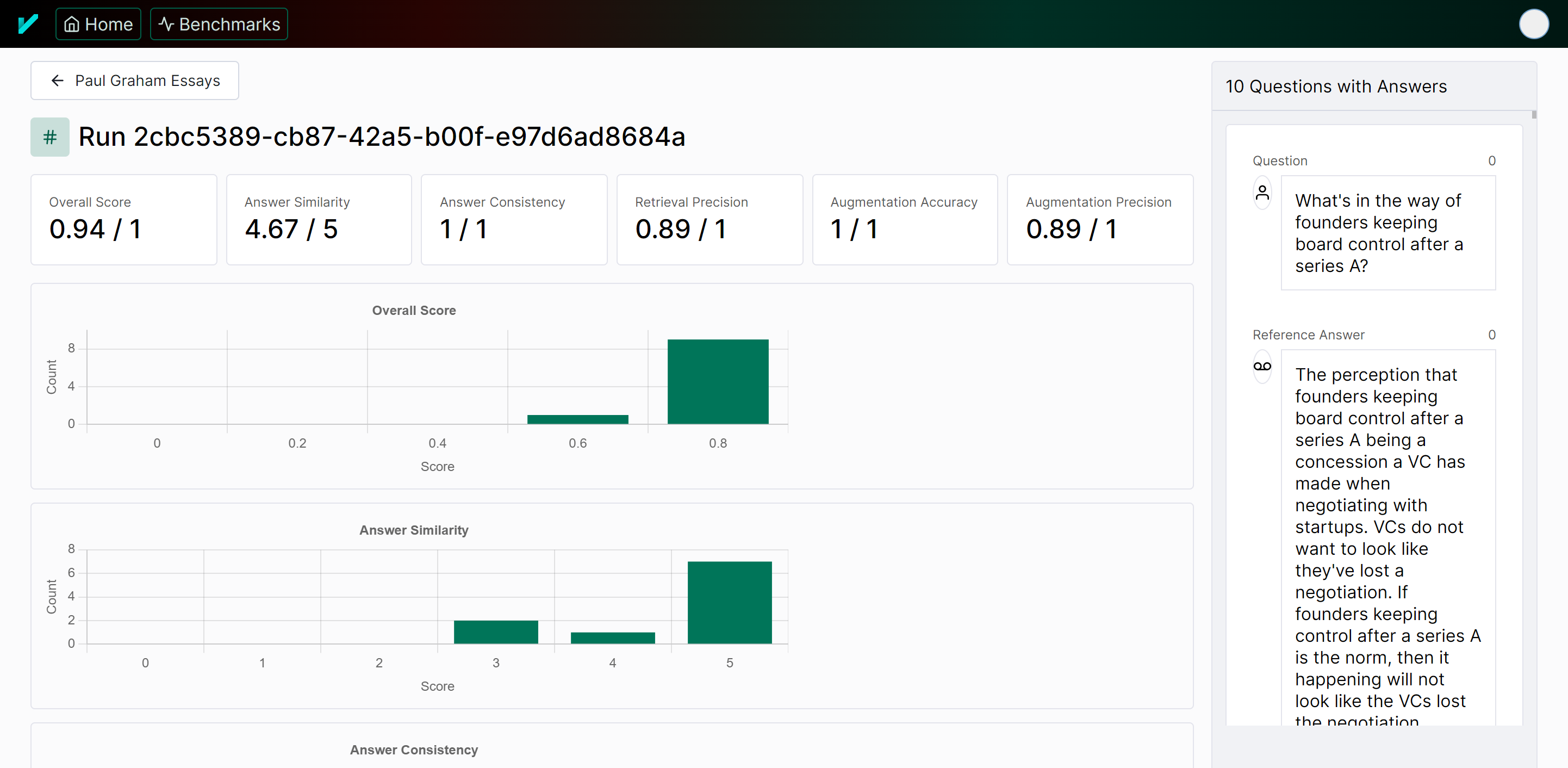
You can also view the results of an individual run in the UI as well.
Tonic Validate collects minimal telemetry to help us figure out what users want and how they're using the product. We do not use any existing telemetry framework and instead created our own privacy focused setup. Only the following information is tracked
- What metrics were used for a run
- Number of questions in a run
- Time taken for a run to be evaluated
- Number of questions in a benchmark
- SDK Version being used
We do NOT track things such as the contents of the questions / answers, your scores, or any other sensitive information. For detecting CI/CD, we only check for common environment variables in different CI/CD environments. We do not log the values of these environment variables.
We also generate a random UUID to help us figure out how many users are using the product. This UUID is linked to your Validate account only to help track who is using the SDK and UI at once and to get user counts. If you want to see how we implemented telemetry, you can do so in the tonic_validate/utils/telemetry.py file
If you wish to opt out of telemetry, you only need to set the TONIC_VALIDATE_DO_NOT_TRACK environment variable to True.
We currently allow the family of chat completion models from Open AI, Google, Anthropic, and more. We are always looking to add more models to our evaluator. If you have a model you would like to see added, please file an issue against this repository.
We'd like to add more models as choices for the LLM evaluator without adding to the complexity of the package too much.
The default model used for scoring metrics is GPT 4 Turbo. To change the model, pass the model name into the model argument for ValidateScorer
scorer = ValidateScorer([
AnswerConsistencyMetric(),
AugmentationAccuracyMetric()
], model_evaluator="gpt-3.5-turbo")Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are greatly appreciated.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement". Don't forget to give the project a star! Thanks again!
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Distributed under the MIT License. See LICENSE.txt for more information.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tonic_validate
Similar Open Source Tools
tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.

vectara-answer
Vectara Answer is a sample app for Vectara-powered Summarized Semantic Search (or question-answering) with advanced configuration options. For examples of what you can build with Vectara Answer, check out Ask News, LegalAid, or any of the other demo applications.

smartcat
Smartcat is a CLI interface that brings language models into the Unix ecosystem, allowing power users to leverage the capabilities of LLMs in their daily workflows. It features a minimalist design, seamless integration with terminal and editor workflows, and customizable prompts for specific tasks. Smartcat currently supports OpenAI, Mistral AI, and Anthropic APIs, providing access to a range of language models. With its ability to manipulate file and text streams, integrate with editors, and offer configurable settings, Smartcat empowers users to automate tasks, enhance code quality, and explore creative possibilities.

garak
Garak is a free tool that checks if a Large Language Model (LLM) can be made to fail in a way that is undesirable. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Garak's a free tool. We love developing it and are always interested in adding functionality to support applications.

pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.

py-vectara-agentic
The `vectara-agentic` Python library is designed for developing powerful AI assistants using Vectara and Agentic-RAG. It supports various agent types, includes pre-built tools for domains like finance and legal, and enables easy creation of custom AI assistants and agents. The library provides tools for summarizing text, rephrasing text, legal tasks like summarizing legal text and critiquing as a judge, financial tasks like analyzing balance sheets and income statements, and database tools for inspecting and querying databases. It also supports observability via LlamaIndex and Arize Phoenix integration.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and follows a process of embedding docs and queries, searching for top passages, creating summaries, scoring and selecting relevant summaries, putting summaries into prompt, and generating answers. Users can customize prompts and use various models for embeddings and LLMs. The tool can be used asynchronously and supports adding documents from paths, files, or URLs.

garak
Garak is a vulnerability scanner designed for LLMs (Large Language Models) that checks for various weaknesses such as hallucination, data leakage, prompt injection, misinformation, toxicity generation, and jailbreaks. It combines static, dynamic, and adaptive probes to explore vulnerabilities in LLMs. Garak is a free tool developed for red-teaming and assessment purposes, focusing on making LLMs or dialog systems fail. It supports various LLM models and can be used to assess their security and robustness.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.

fabric
Fabric is an open-source framework for augmenting humans using AI. It provides a structured approach to breaking down problems into individual components and applying AI to them one at a time. Fabric includes a collection of pre-defined Patterns (prompts) that can be used for a variety of tasks, such as extracting the most interesting parts of YouTube videos and podcasts, writing essays, summarizing academic papers, creating AI art prompts, and more. Users can also create their own custom Patterns. Fabric is designed to be easy to use, with a command-line interface and a variety of helper apps. It is also extensible, allowing users to integrate it with their own AI applications and infrastructure.

bia-bob
BIA `bob` is a Jupyter-based assistant for interacting with data using large language models to generate Python code. It can utilize OpenAI's chatGPT, Google's Gemini, Helmholtz' blablador, and Ollama. Users need respective accounts to access these services. Bob can assist in code generation, bug fixing, code documentation, GPU-acceleration, and offers a no-code custom Jupyter Kernel. It provides example notebooks for various tasks like bio-image analysis, model selection, and bug fixing. Installation is recommended via conda/mamba environment. Custom endpoints like blablador and ollama can be used. Google Cloud AI API integration is also supported. The tool is extensible for Python libraries to enhance Bob's functionality.

reader
Reader is a tool that converts any URL to an LLM-friendly input with a simple prefix `https://r.jina.ai/`. It improves the output for your agent and RAG systems at no cost. Reader supports image reading, captioning all images at the specified URL and adding `Image [idx]: [caption]` as an alt tag. This enables downstream LLMs to interact with the images in reasoning, summarizing, etc. Reader offers a streaming mode, useful when the standard mode provides an incomplete result. In streaming mode, Reader waits a bit longer until the page is fully rendered, providing more complete information. Reader also supports a JSON mode, which contains three fields: `url`, `title`, and `content`. Reader is backed by Jina AI and licensed under Apache-2.0.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**

kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.
For similar tasks

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.
tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
llm
LLM is a Rust library that allows users to utilize multiple LLM backends (OpenAI, Anthropic, Ollama, DeepSeek, xAI, Phind, Groq, Google) in a single project. It provides a unified API and builder style for creating chat or text completion requests without the need for multiple structures and crates. Key features include multi-backend management, multi-step chains, templates for complex prompts, builder pattern for easy configuration, extensibility, validation, evaluation, parallel evaluation, function calling, REST API support, vision integration, and reasoning capabilities.
quick-start-guide-to-llms
This GitHub repository serves as the companion to the 'Quick Start Guide to Large Language Models - Second Edition' book. It contains code snippets and notebooks demonstrating various applications and advanced techniques in working with Transformer models and large language models (LLMs). The repository is structured into directories for notebooks, data, and images, with each notebook corresponding to a chapter in the book. Users can explore topics such as semantic search, prompt engineering, model fine-tuning, custom embeddings, advanced LLM usage, moving LLMs into production, and evaluating LLMs. The repository aims to provide practical examples and insights for working with LLMs in different contexts.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.