
OpenAI-sublime-text
First class Sublime Text AI assistant with o1, o3-mini, gpt-4.5 and ollama support!
Stars: 267
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.
README:


[!WARNING] Package Control do not fetches any updates for a two weeks for now and there's nothing I can do with that, so if you want to use the latest version of this package you have to clone it and install it manually.
Cursor level of AI assistance for Sublime Text. I mean it.
Works with all OpenAI'ish API: llama.cpp server, ollama or whatever third party LLM hosting. Claude API support coming soon.
[!NOTE] 5.0.0 release is around the corner! Check out release notes for details.

- Chat mode powered by whatever model you'd like.
- o3-mini and o1 support.
- gpt-4.5-preview support
- llama.cpp's server, ollama and all the rest OpenAI'ish API compatible.
- Dedicated chats histories and assistant settings for a projects.
- Ability to send whole files or their parts as a context expanding.
- Phantoms Get non-disruptive inline right in view answers from the model.
- Markdown syntax with code languages syntax highlight (Chat mode only).
- Server Side Streaming (SSE) streaming support.
- Status bar various info: model name, mode, sent/received tokens.
- Proxy support.
- Sublime Text 4
- llama.cpp, ollama installed OR
- Remote llm service provider API key, e.g. OpenAI
- Atropic API key [coming soon].
- Install the Sublime Text Package Control plugin if you haven't done this before.
- Open the command palette and type
Package Control: Install Package. - Type
OpenAIand pressEnter.
[!NOTE] Highly recommended complimentary packages:
ChatGPT mode works the following way:
- Select some text or even the whole tabs to include them in request
- Run either
OpenAI: Chat Model SelectorOpenAI: Chat Model Select With Tabscommands. - Input a request in input window if any.
- The model will print a response in output panel by default, but you can switch that to a separate tab with
OpenAI: Open in Tab. - To get an existing chat in a new window run
OpenAI: Refresh Chat. - To reset history
OpenAI: Reset Chat Historycommand to rescue.
[!NOTE] You suggested to bind at least
OpenAI: New Message,OpenAI: Chat Model SelectandOpenAI: Show output panelin sake for convenience, you can do that in plugin settings.
You can separate a chat history and assistant settings for a given project by appending the following snippet to its settings:
{
"settings": {
"ai_assistant": {
"cache_prefix": "/absolute/path/to/project/"
}
}
}You can add a few things to your request:
- multi-line selection within a single file
- multiple files within a single View Group
To perform the former just select something within an active view and initiate the request this way without switching to another tab, selection would be added to a request as a preceding message (each selection chunk would be split by a new line).
To append the whole file(s) to request you should super+button1 on them to make whole tabs of them to become visible in a single view group and then run OpenAI: Add Sheets to Context command. Sheets can be deselected with the same command.
You can check the numbers of added sheets in the status bar and on "OpenAI: Chat Model Select" command call in the preview section.

Image handle can be called by OpenAI: Handle Image command.
It expects an absolute path to image to be selected in a buffer or stored in clipboard on the command call (smth like /Users/username/Documents/Project/image.png). In addition command can be passed by input panel to proceed the image with special treatment. png and jpg images are only supported.
[!NOTE] Currently plugin expects the link or the list of links separated by a new line to be selected in buffer or stored in clipboard only.
Phantom is the overlay UI placed inline in the editor view (see the picture below). It doesn't affects content of the view.
- [optional] Select some text to pass in context in to manipulate with.
- Pick
Phantomas an output mode in quick panelOpenAI: Chat Model Select. - You can apply actions to the llm prompt, they're quite self descriptive and follows behavior deprecated in buffer commands.
- You can hit
ctrl+cto stop prompting same as with inpanelmode.

- Replace
"url"setting of a given model to point to whatever host you're server running on (e.g.http://localhost:8080/v1/chat/completions). - Provide a
"token"if your provider required one. - Tweak
"chat_model"to a model of your choice and you're set.
[!NOTE] You can set both
urlandtokeneither global or on per assistant instance basis, thus being capable to freely switching between closed source and open sourced models within a single session.
The OpenAI Completion plugin has a settings file where you can set your OpenAI API key. This is required for the most of providers to work. To set your API key, open the settings within Preferences -> Package Settings -> OpenAI -> Settings and paste your API key in the token property, as follows:
{
"token": "sk-your-token",
}To disable advertisement you have to add "advertisement": false line into an assistant setting where you wish it to be disabled.
You can bind keys for a given plugin command in Preferences -> Package Settings -> OpenAI -> Key Bindings. For example you can bind "New Message" including active tabs as context command like this:
{
"keys": [ "super+k", "super+'" ],
"command": "openai", // or "openai_panel"
"args": { "files_included": true }
},You can setup it up by overriding the proxy property in the OpenAI completion settings like follow:
"proxy": {
"address": "127.0.0.1", // required
"port": 9898, // required
"username": "account",
"password": "sOmEpAsSwOrD"
}[!WARNING] All selected code will be sent to the OpenAI servers (if not using custom API provider) for processing, so make sure you have all necessary permissions to do so.
[!NOTE] Dedicated to GPT3.5 that one the one who initially written at 80% of this back then. This was felt like a pure magic!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for OpenAI-sublime-text
Similar Open Source Tools
OpenAI-sublime-text
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.

kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.

smartcat
Smartcat is a CLI interface that brings language models into the Unix ecosystem, allowing power users to leverage the capabilities of LLMs in their daily workflows. It features a minimalist design, seamless integration with terminal and editor workflows, and customizable prompts for specific tasks. Smartcat currently supports OpenAI, Mistral AI, and Anthropic APIs, providing access to a range of language models. With its ability to manipulate file and text streams, integrate with editors, and offer configurable settings, Smartcat empowers users to automate tasks, enhance code quality, and explore creative possibilities.
slack-bot
The Slack Bot is a tool designed to enhance the workflow of development teams by integrating with Jenkins, GitHub, GitLab, and Jira. It allows for custom commands, macros, crons, and project-specific commands to be implemented easily. Users can interact with the bot through Slack messages, execute commands, and monitor job progress. The bot supports features like starting and monitoring Jenkins jobs, tracking pull requests, querying Jira information, creating buttons for interactions, generating images with DALL-E, playing quiz games, checking weather, defining custom commands, and more. Configuration is managed via YAML files, allowing users to set up credentials for external services, define custom commands, schedule cron jobs, and configure VCS systems like Bitbucket for automated branch lookup in Jenkins triggers.
wcgw
wcgw is a shell and coding agent designed for Claude and Chatgpt. It provides full shell access with no restrictions, desktop control on Claude for screen capture and control, interactive command handling, large file editing, and REPL support. Users can use wcgw to create, execute, and iterate on tasks, such as solving problems with Python, finding code instances, setting up projects, creating web apps, editing large files, and running server commands. Additionally, wcgw supports computer use on Docker containers for desktop control. The tool can be extended with a VS Code extension for pasting context on Claude app and integrates with Chatgpt for custom GPT interactions.

bedrock-claude-chat
This repository is a sample chatbot using the Anthropic company's LLM Claude, one of the foundational models provided by Amazon Bedrock for generative AI. It allows users to have basic conversations with the chatbot, personalize it with their own instructions and external knowledge, and analyze usage for each user/bot on the administrator dashboard. The chatbot supports various languages, including English, Japanese, Korean, Chinese, French, German, and Spanish. Deployment is straightforward and can be done via the command line or by using AWS CDK. The architecture is built on AWS managed services, eliminating the need for infrastructure management and ensuring scalability, reliability, and security.
ComfyUI-mnemic-nodes
ComfyUI-mnemic-nodes is a repository hosting a collection of nodes developed for ComfyUI, providing useful components to enhance project functionality. The nodes include features like returning file paths, saving text files, downloading images from URLs, tokenizing text, cleaning strings, querying Groq language models, generating negative prompts, and more. Some nodes are experimental and marked with a 'Caution' label. Installation instructions and setup details are provided for each node, along with examples and presets for different tasks.

magic-cli
Magic CLI is a command line utility that leverages Large Language Models (LLMs) to enhance command line efficiency. It is inspired by projects like Amazon Q and GitHub Copilot for CLI. The tool allows users to suggest commands, search across command history, and generate commands for specific tasks using local or remote LLM providers. Magic CLI also provides configuration options for LLM selection and response generation. The project is still in early development, so users should expect breaking changes and bugs.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.

vectara-answer
Vectara Answer is a sample app for Vectara-powered Summarized Semantic Search (or question-answering) with advanced configuration options. For examples of what you can build with Vectara Answer, check out Ask News, LegalAid, or any of the other demo applications.
vscode-pddl
The vscode-pddl extension provides comprehensive support for Planning Domain Description Language (PDDL) in Visual Studio Code. It enables users to model planning domains, validate them, industrialize planning solutions, and run planners. The extension offers features like syntax highlighting, auto-completion, plan visualization, plan validation, plan happenings evaluation, search debugging, and integration with Planning.Domains. Users can create PDDL files, run planners, visualize plans, and debug search algorithms efficiently within VS Code.

promptwright
Promptwright is a Python library designed for generating large synthetic datasets using a local LLM and various LLM service providers. It offers flexible interfaces for generating prompt-led synthetic datasets. The library supports multiple providers, configurable instructions and prompts, YAML configuration for tasks, command line interface for running tasks, push to Hugging Face Hub for dataset upload, and system message control. Users can define generation tasks using YAML configuration or Python code. Promptwright integrates with LiteLLM to interface with LLM providers and supports automatic dataset upload to Hugging Face Hub.
node_characterai
Node.js client for the unofficial Character AI API, an awesome website which brings characters to life with AI! This repository is inspired by RichardDorian's unofficial node API. Though, I found it hard to use and it was not really stable and archived. So I remade it in javascript. This project is not affiliated with Character AI in any way! It is a community project. The purpose of this project is to bring and build projects powered by Character AI. If you like this project, please check their website.
promptwright
Promptwright is a Python library designed for generating large synthetic datasets using local LLM and various LLM service providers. It offers flexible interfaces for generating prompt-led synthetic datasets. The library supports multiple providers, configurable instructions and prompts, YAML configuration, command line interface, push to Hugging Face Hub, and system message control. Users can define generation tasks using YAML configuration files or programmatically using Python code. Promptwright integrates with LiteLLM for LLM providers and supports automatic dataset upload to Hugging Face Hub. The library is not responsible for the content generated by models and advises users to review the data before using it in production environments.
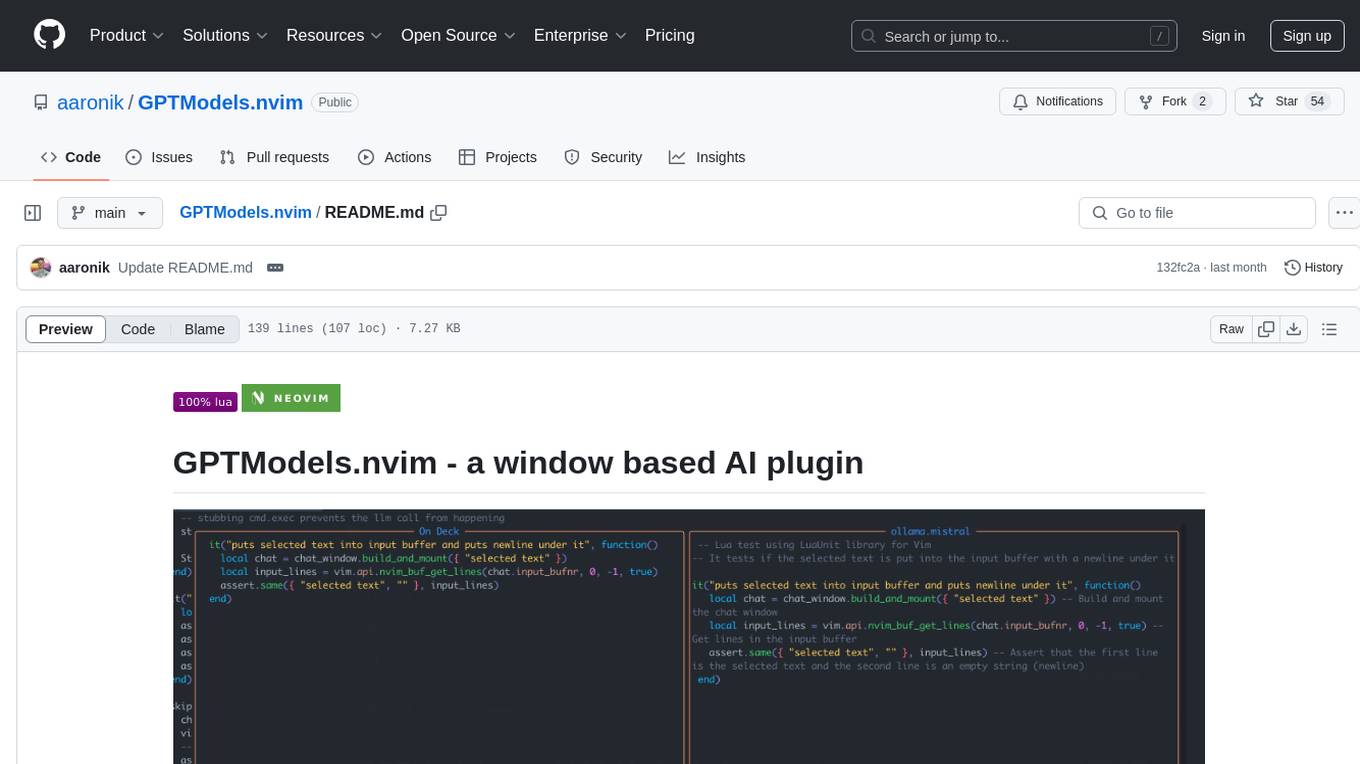
GPTModels.nvim
GPTModels.nvim is a window-based AI plugin for Neovim that enhances workflow with AI LLMs. It provides two popup windows for chat and code editing, focusing on stability and user experience. The plugin supports OpenAI and Ollama, includes LSP diagnostics, file inclusion, background processing, request cancellation, selection inclusion, and filetype inclusion. Developed with stability in mind, the plugin offers a seamless user experience with various features to streamline AI integration in Neovim.

fabric
Fabric is an open-source framework for augmenting humans using AI. It provides a structured approach to breaking down problems into individual components and applying AI to them one at a time. Fabric includes a collection of pre-defined Patterns (prompts) that can be used for a variety of tasks, such as extracting the most interesting parts of YouTube videos and podcasts, writing essays, summarizing academic papers, creating AI art prompts, and more. Users can also create their own custom Patterns. Fabric is designed to be easy to use, with a command-line interface and a variety of helper apps. It is also extensible, allowing users to integrate it with their own AI applications and infrastructure.
For similar tasks

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
continue
Continue is an open-source autopilot for VS Code and JetBrains that allows you to code with any LLM. With Continue, you can ask coding questions, edit code in natural language, generate files from scratch, and more. Continue is easy to use and can help you save time and improve your coding skills.
anterion
Anterion is an open-source AI software engineer that extends the capabilities of `SWE-agent` to plan and execute open-ended engineering tasks, with a frontend inspired by `OpenDevin`. It is designed to help users fix bugs and prototype ideas with ease. Anterion is equipped with easy deployment and a user-friendly interface, making it accessible to users of all skill levels.
sglang
SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with LLMs faster and more controllable by co-designing the frontend language and the runtime system. The core features of SGLang include: - **A Flexible Front-End Language**: This allows for easy programming of LLM applications with multiple chained generation calls, advanced prompting techniques, control flow, multiple modalities, parallelism, and external interaction. - **A High-Performance Runtime with RadixAttention**: This feature significantly accelerates the execution of complex LLM programs by automatic KV cache reuse across multiple calls. It also supports other common techniques like continuous batching and tensor parallelism.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.
aider
Aider is a command-line tool that lets you pair program with GPT-3.5/GPT-4 to edit code stored in your local git repository. Aider will directly edit the code in your local source files and git commit the changes with sensible commit messages. You can start a new project or work with an existing git repo. Aider is unique in that it lets you ask for changes to pre-existing, larger codebases.
chatgpt-web
ChatGPT Web is a web application that provides access to the ChatGPT API. It offers two non-official methods to interact with ChatGPT: through the ChatGPTAPI (using the `gpt-3.5-turbo-0301` model) or through the ChatGPTUnofficialProxyAPI (using a web access token). The ChatGPTAPI method is more reliable but requires an OpenAI API key, while the ChatGPTUnofficialProxyAPI method is free but less reliable. The application includes features such as user registration and login, synchronization of conversation history, customization of API keys and sensitive words, and management of users and keys. It also provides a user interface for interacting with ChatGPT and supports multiple languages and themes.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.