
wcgw
Shell and coding agent on claude desktop app
Stars: 580
wcgw is a shell and coding agent designed for Claude and Chatgpt. It provides full shell access with no restrictions, desktop control on Claude for screen capture and control, interactive command handling, large file editing, and REPL support. Users can use wcgw to create, execute, and iterate on tasks, such as solving problems with Python, finding code instances, setting up projects, creating web apps, editing large files, and running server commands. Additionally, wcgw supports computer use on Docker containers for desktop control. The tool can be extended with a VS Code extension for pasting context on Claude app and integrates with Chatgpt for custom GPT interactions.
README:
Empowering chat applications to code, build and run on your local machine.
wcgw is an MCP server with tightly integrated shell and code editing tools.
![]()
![]()
![]()

-
[27 Apr 2025] Removed support for GPTs over relay server. Only MCP server is supported in version >= 5.
-
[24 Mar 2025] Improved writing and editing experience for sonnet 3.7, CLAUDE.md gets loaded automatically.
-
[16 Feb 2025] You can now attach to the working terminal that the AI uses. See the "attach-to-terminal" section below.
-
[15 Jan 2025] Modes introduced: architect, code-writer, and all powerful wcgw mode.
-
[8 Jan 2025] Context saving tool for saving relevant file paths along with a description in a single file. Can be used as a task checkpoint or for knowledge transfer.
-
[29 Dec 2024] Syntax checking on file writing and edits is now stable. Made
initializetool call useful; sending smart repo structure to claude if any repo is referenced. Large file handling is also now improved. -
[9 Dec 2024] Vscode extension to paste context on Claude app
- ⚡ Create, Execute, Iterate: Ask claude to keep running compiler checks till all errors are fixed, or ask it to keep checking for the status of a long running command till it's done.
- ⚡ Large file edit: Supports large file incremental edits to avoid token limit issues. Smartly selects when to do small edits or large rewrite based on % of change needed.
- ⚡ Syntax checking on edits: Reports feedback to the LLM if its edits have any syntax errors, so that it can redo it.
- ⚡ Interactive Command Handling: Supports interactive commands using arrow keys, interrupt, and ansi escape sequences.
- ⚡ File protections:
- The AI needs to read a file at least once before it's allowed to edit or rewrite it. This avoids accidental overwrites.
- Avoids context filling up while reading very large files. Files get chunked based on token length.
- On initialisation the provided workspace's directory structure is returned after selecting important files (based on .gitignore as well as a statistical approach)
- File edit based on search-replace tries to find correct search block if it has multiple matches based on previous search blocks. Fails otherwise (for correctness).
- File edit has spacing tolerant matching, with warning on issues like indentation mismatch. If there's no match, the closest match is returned to the AI to fix its mistakes.
- Using Aider-like search and replace, which has better performance than tool call based search and replace.
- ⚡ Shell optimizations:
- Only one command is allowed to be run at a time, simplifying management and avoiding rogue processes. There's only single shell instance at any point of time.
- Current working directory is always returned after any shell command to prevent AI from getting lost.
- Command polling exits after a quick timeout to avoid slow feedback. However, status checking has wait tolerance based on fresh output streaming from a command. Both of these approach combined provides a good shell interaction experience.
- ⚡ Saving repo context in a single file: Task checkpointing using "ContextSave" tool saves detailed context in a single file. Tasks can later be resumed in a new chat asking "Resume
task id". The saved file can be used to do other kinds of knowledge transfer, such as taking help from another AI. - ⚡ Easily switch between various modes:
- Ask it to run in 'architect' mode for planning. Inspired by adier's architect mode, work with Claude to come up with a plan first. Leads to better accuracy and prevents premature file editing.
- Ask it to run in 'code-writer' mode for code editing and project building. You can provide specific paths with wild card support to prevent other files getting edited.
- By default it runs in 'wcgw' mode that has no restrictions and full authorisation.
- More details in Modes section
- ⚡ Runs in multiplex terminal Run
screen -xto attach to the terminal that the AI runs commands on. See history or interrupt process or interact with the same terminal that AI uses. - ⚡ Automatically load CLAUDE.md/AGENTS.md Loads "CLAUDE.md" or "AGENTS.md" file in project root and sends as instructions during initialisation. Instructions in a global "
/.wcgw/CLAUDE.md" or "/.wcgw/AGENTS.md" file are loaded and added along with project specific CLAUDE.md. The file name is case sensitive. CLAUDE.md is attached if it's present otherwise AGENTS.md is attached.
- Solve problem X using python, create and run test cases and fix any issues. Do it in a temporary directory
- Find instances of code with X behavior in my repository
- Git clone https://github.com/my/repo in my home directory, then understand the project, set up the environment and build
- Create a golang htmx tailwind webapp, then open browser to see if it works (use with puppeteer mcp)
- Edit or update a large file
- In a separate branch create feature Y, then use github cli to create a PR to original branch
- Command X is failing in Y directory, please run and fix issues
- Using X virtual environment run Y command
- Using cli tools, create build and test an android app. Finally run it using emulator for me to use
- Fix all mypy issues in my repo at X path.
- Using 'screen' run my server in background instead, then run another api server in bg, finally run the frontend build. Keep checking logs for any issues in all three
- Create repo wide unittest cases. Keep iterating through files and creating cases. Also keep running the tests after each update. Do not modify original code.
First install uv using homebrew brew install uv
(Important: use homebrew to install uv. Otherwise make sure uv is present in a global location like /usr/bin/)
Then create or update claude_desktop_config.json (~/Library/Application Support/Claude/claude_desktop_config.json) with following json.
{
"mcpServers": {
"wcgw": {
"command": "uv",
"args": ["tool", "run", "--python", "3.12", "wcgw"]
}
}
}Then restart claude app.
If there's an error in setting up
- If there's an error like "uv ENOENT", make sure
uvis installed. Then run 'which uv' in the terminal, and use its output in place of "uv" in the configuration. - If there's still an issue, check that
uv tool run --python 3.12 wcgwruns in your terminal. It should have no output and shouldn't exit. - Try removing ~/.cache/uv folder
- Try using
uvversion0.6.0for which this tool was tested. - Debug the mcp server using
npx @modelcontextprotocol/[email protected] uv tool run --python 3.12 wcgw
This mcp server works only on wsl on windows.
To set it up, install uv
Then add or update the claude config file %APPDATA%\Claude\claude_desktop_config.json with the following
{
"mcpServers": {
"wcgw": {
"command": "wsl.exe",
"args": ["uv", "tool", "run", "--python", "3.12", "wcgw"]
}
}
}When you encounter an error, execute the command wsl uv --python 3.12 wcgw in command prompt. If you get the error /bin/bash: line 1: uv: command not found, it means uv was not installed globally and you need to point to the correct path of uv.
- Find where uv is installed:
whereis uvExample output:
uv: /home/mywsl/.local/bin/uv
- Test the full path works:
wsl /home/mywsl/.local/bin/uv tool run --python 3.12 wcgw
- Update the config with the full path:
{
"mcpServers": {
"wcgw": {
"command": "wsl.exe",
"args": ["/home/mywsl/.local/bin/uv", "tool", "run", "--python", "3.12", "wcgw"]
}
}
}
Replace /home/mywsl/.local/bin/uv with your actual uv path from step 1.
Wait for a few seconds. You should be able to see this icon if everything goes right.
![]() over here
over here

Then ask claude to execute shell commands, read files, edit files, run your code, etc.
- You can do a task checkpoint or a knowledge transfer by attaching "KnowledgeTransfer" prompt using "Attach from MCP" button.
- On running "KnowledgeTransfer" prompt, the "ContextSave" tool will be called saving the task description and all file content together in a single file. An id for the task will be generated.
- You can in a new chat say "Resume ''", the AI should then call "Initialize" with the task id and load the context from there.
- Or you can directly open the file generated and share it with another AI for help.
There are three built-in modes. You may ask Claude to run in one of the modes, like "Use 'architect' mode"
| Mode | Description | Allows | Denies | Invoke prompt |
|---|---|---|---|---|
| Architect | Designed for you to work with Claude to investigate and understand your repo. | Read-only commands | FileEdit and Write tool | Run in mode='architect' |
| Code-writer | For code writing and development | Specified path globs for editing or writing, specified commands | FileEdit for paths not matching specified glob, Write for paths not matching specified glob | Run in code writer mode, only 'tests/**' allowed, only uv command allowed |
| **wcgw** | Default mode with everything allowed | Everything | Nothing | No prompt, or "Run in wcgw mode" |
Note: in code-writer mode either all commands are allowed or none are allowed for now. If you give a list of allowed commands, Claude is instructed to run only those commands, but no actual check happens. (WIP)
If you've screen command installed, wcgw runs on a screen instance automatically. If you've started wcgw mcp server, you can list the screen sessions:
screen -ls
And note down the wcgw screen name which will be something like 93358.wcgw.235521 where the last number is in the hour-minute-second format.
You can then attach to the session using screen -x 93358.wcgw.235521
You may interrupt any running command safely.
You can interact with the terminal but beware that the AI might be running in parallel and it may conflict with what you're doing. It's recommended to keep your interactions to minimum.
You shouldn't exit the session using exit or Ctrl-d, instead you should use ctrl+a+d to safely detach without destroying the screen session.
Include the following in ~/.screenrc for better scrolling experience
defscrollback 10000
termcapinfo xterm* ti@:te@
https://marketplace.visualstudio.com/items?itemName=AmanRusia.wcgw
Commands:
- Select a text and press
cmd+'and then enter instructions. This will switch the app to Claude and paste a text containing your instructions, file path, workspace dir, and the selected text.

First build the docker image docker build -t wcgw https://github.com/rusiaaman/wcgw.git
Then you can update /Users/username/Library/Application Support/Claude/claude_desktop_config.json to have
{
"mcpServers": {
"wcgw": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"--mount",
"type=bind,src=/Users/username/Desktop,dst=/workspace/Desktop",
"wcgw"
]
}
}
}
Add OPENAI_API_KEY and OPENAI_ORG_ID env variables.
Then run
uvx wcgw wcgw_local --limit 0.1 # Cost limit $0.1
You can now directly write messages or press enter key to open vim for multiline message and text pasting.
Add ANTHROPIC_API_KEY env variable.
Then run
uvx wcgw wcgw_local --claude
You can now directly write messages or press enter key to open vim for multiline message and text pasting.
The server provides the following MCP tools:
Shell Operations:
-
Initialize: Reset shell and set up workspace environment- Parameters:
any_workspace_path(string),initial_files_to_read(string[]),mode_name("wcgw"|"architect"|"code_writer"),task_id_to_resume(string)
- Parameters:
-
BashCommand: Execute shell commands with timeout control- Parameters:
command(string),wait_for_seconds(int, optional) - Parameters:
send_text(string) orsend_specials(["Enter"|"Key-up"|...]) orsend_ascii(int[]),wait_for_seconds(int, optional)
- Parameters:
File Operations:
-
ReadFiles: Read content from one or more files- Parameters:
file_paths(string[])
- Parameters:
-
WriteIfEmpty: Create new files or write to empty files- Parameters:
file_path(string),file_content(string)
- Parameters:
-
FileEdit: Edit existing files using search/replace blocks- Parameters:
file_path(string),file_edit_using_search_replace_blocks(string)
- Parameters:
-
ReadImage: Read image files for display/processing- Parameters:
file_path(string)
- Parameters:
Project Management:
-
ContextSave: Save project context and files for Knowledge Transfer or saving task checkpoints to be resumed later- Parameters:
id(string),project_root_path(string),description(string),relevant_file_globs(string[])
- Parameters:
All tools support absolute paths and include built-in protections against common errors. See the MCP specification for detailed protocol information.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for wcgw
Similar Open Source Tools
wcgw
wcgw is a shell and coding agent designed for Claude and Chatgpt. It provides full shell access with no restrictions, desktop control on Claude for screen capture and control, interactive command handling, large file editing, and REPL support. Users can use wcgw to create, execute, and iterate on tasks, such as solving problems with Python, finding code instances, setting up projects, creating web apps, editing large files, and running server commands. Additionally, wcgw supports computer use on Docker containers for desktop control. The tool can be extended with a VS Code extension for pasting context on Claude app and integrates with Chatgpt for custom GPT interactions.
OpenAI-sublime-text
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.

kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.
slack-bot
The Slack Bot is a tool designed to enhance the workflow of development teams by integrating with Jenkins, GitHub, GitLab, and Jira. It allows for custom commands, macros, crons, and project-specific commands to be implemented easily. Users can interact with the bot through Slack messages, execute commands, and monitor job progress. The bot supports features like starting and monitoring Jenkins jobs, tracking pull requests, querying Jira information, creating buttons for interactions, generating images with DALL-E, playing quiz games, checking weather, defining custom commands, and more. Configuration is managed via YAML files, allowing users to set up credentials for external services, define custom commands, schedule cron jobs, and configure VCS systems like Bitbucket for automated branch lookup in Jenkins triggers.

patchwork
PatchWork is an open-source framework designed for automating development tasks using large language models. It enables users to automate workflows such as PR reviews, bug fixing, security patching, and more through a self-hosted CLI agent and preferred LLMs. The framework consists of reusable atomic actions called Steps, customizable LLM prompts known as Prompt Templates, and LLM-assisted automations called Patchflows. Users can run Patchflows locally in their CLI/IDE or as part of CI/CD pipelines. PatchWork offers predefined patchflows like AutoFix, PRReview, GenerateREADME, DependencyUpgrade, and ResolveIssue, with the flexibility to create custom patchflows. Prompt templates are used to pass queries to LLMs and can be customized. Contributions to new patchflows, steps, and the core framework are encouraged, with chat assistants available to aid in the process. The roadmap includes expanding the patchflow library, introducing a debugger and validation module, supporting large-scale code embeddings, parallelization, fine-tuned models, and an open-source GUI. PatchWork is licensed under AGPL-3.0 terms, while custom patchflows and steps can be shared using the Apache-2.0 licensed patchwork template repository.
Bard-API
The Bard API is a Python package that returns responses from Google Bard through the value of a cookie. It is an unofficial API that operates through reverse-engineering, utilizing cookie values to interact with Google Bard for users struggling with frequent authentication problems or unable to authenticate via Google Authentication. The Bard API is not a free service, but rather a tool provided to assist developers with testing certain functionalities due to the delayed development and release of Google Bard's API. It has been designed with a lightweight structure that can easily adapt to the emergence of an official API. Therefore, using it for any other purposes is strongly discouraged. If you have access to a reliable official PaLM-2 API or Google Generative AI API, replace the provided response with the corresponding official code. Check out https://github.com/dsdanielpark/Bard-API/issues/262.

bedrock-claude-chat
This repository is a sample chatbot using the Anthropic company's LLM Claude, one of the foundational models provided by Amazon Bedrock for generative AI. It allows users to have basic conversations with the chatbot, personalize it with their own instructions and external knowledge, and analyze usage for each user/bot on the administrator dashboard. The chatbot supports various languages, including English, Japanese, Korean, Chinese, French, German, and Spanish. Deployment is straightforward and can be done via the command line or by using AWS CDK. The architecture is built on AWS managed services, eliminating the need for infrastructure management and ensuring scalability, reliability, and security.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.
aiconfig
AIConfig is a framework that makes it easy to build generative AI applications for production. It manages generative AI prompts, models and model parameters as JSON-serializable configs that can be version controlled, evaluated, monitored and opened in a local editor for rapid prototyping. It allows you to store and iterate on generative AI behavior separately from your application code, offering a streamlined AI development workflow.
june
june-va is a local voice chatbot that combines Ollama for language model capabilities, Hugging Face Transformers for speech recognition, and the Coqui TTS Toolkit for text-to-speech synthesis. It provides a flexible, privacy-focused solution for voice-assisted interactions on your local machine, ensuring that no data is sent to external servers. The tool supports various interaction modes including text input/output, voice input/text output, text input/audio output, and voice input/audio output. Users can customize the tool's behavior with a JSON configuration file and utilize voice conversion features for voice cloning. The application can be further customized using a configuration file with attributes for language model, speech-to-text model, and text-to-speech model configurations.
chatgpt-vscode
ChatGPT-VSCode is a Visual Studio Code integration that allows users to prompt OpenAI's GPT-4, GPT-3.5, GPT-3, and Codex models within the editor. It offers features like using improved models via OpenAI API Key, Azure OpenAI Service deployments, generating commit messages, storing conversation history, explaining and suggesting fixes for compile-time errors, viewing code differences, and more. Users can customize prompts, quick fix problems, save conversations, and export conversation history. The extension is designed to enhance developer experience by providing AI-powered assistance directly within VS Code.
neo4j-graphrag-python
The Neo4j GraphRAG package for Python is an official repository that provides features for creating and managing vector indexes in Neo4j databases. It aims to offer developers a reliable package with long-term commitment, maintenance, and fast feature updates. The package supports various Python versions and includes functionalities for creating vector indexes, populating them, and performing similarity searches. It also provides guidelines for installation, examples, and development processes such as installing dependencies, making changes, and running tests.
voice-chat-ai
Voice Chat AI is a project that allows users to interact with different AI characters using speech. Users can choose from various characters with unique personalities and voices, and have conversations or role play with them. The project supports OpenAI, xAI, or Ollama language models for chat, and provides text-to-speech synthesis using XTTS, OpenAI TTS, or ElevenLabs. Users can seamlessly integrate visual context into conversations by having the AI analyze their screen. The project offers easy configuration through environment variables and can be run via WebUI or Terminal. It also includes a huge selection of built-in characters for engaging conversations.
code-assistant
Code Assistant is an AI coding tool built in Rust that offers command-line and graphical interfaces for autonomous code analysis and modification. It supports multi-modal tool execution, real-time streaming interface, session-based project management, multiple interface options, and intelligent project exploration. The tool provides auto-loaded repository guidance and allows for project configuration with format-on-save feature. Users can interact with the tool in GUI, terminal, or MCP server mode, and configure LLM providers for advanced options. The architecture highlights adaptive tool syntax, smart tool filtering, and multi-threaded streaming for efficient performance. Contributions are welcome, and the roadmap includes features like block replacing in changed files, compact tool use failures, UI improvements, memory tools, security enhancements, fuzzy matching search blocks, editing user messages, and selecting in messages.
sd-webui-agent-scheduler
AgentScheduler is an Automatic/Vladmandic Stable Diffusion Web UI extension designed to enhance image generation workflows. It allows users to enqueue prompts, settings, and controlnets, manage queued tasks, prioritize, pause, resume, and delete tasks, view generation results, and more. The extension offers hidden features like queuing checkpoints, editing queued tasks, and custom checkpoint selection. Users can access the functionality through HTTP APIs and API callbacks. Troubleshooting steps are provided for common errors. The extension is compatible with latest versions of A1111 and Vladmandic. It is licensed under Apache License 2.0.
Tiger
Tiger is a community-driven project developing a reusable and integrated tool ecosystem for LLM Agent Revolution. It utilizes Upsonic for isolated tool storage, profiling, and automatic document generation. With Tiger, you can create a customized environment for your agents or leverage the robust and publicly maintained Tiger curated by the community itself.
For similar tasks
wcgw
wcgw is a shell and coding agent designed for Claude and Chatgpt. It provides full shell access with no restrictions, desktop control on Claude for screen capture and control, interactive command handling, large file editing, and REPL support. Users can use wcgw to create, execute, and iterate on tasks, such as solving problems with Python, finding code instances, setting up projects, creating web apps, editing large files, and running server commands. Additionally, wcgw supports computer use on Docker containers for desktop control. The tool can be extended with a VS Code extension for pasting context on Claude app and integrates with Chatgpt for custom GPT interactions.

Protofy
Protofy is a full-stack, batteries-included low-code enabled web/app and IoT system with an API system and real-time messaging. It is based on Protofy (protoflow + visualui + protolib + protodevices) + Expo + Next.js + Tamagui + Solito + Express + Aedes + Redbird + Many other amazing packages. Protofy can be used to fast prototype Apps, webs, IoT systems, automations, or APIs. It is a ultra-extensible CMS with supercharged capabilities, mobile support, and IoT support (esp32 thanks to esphome).
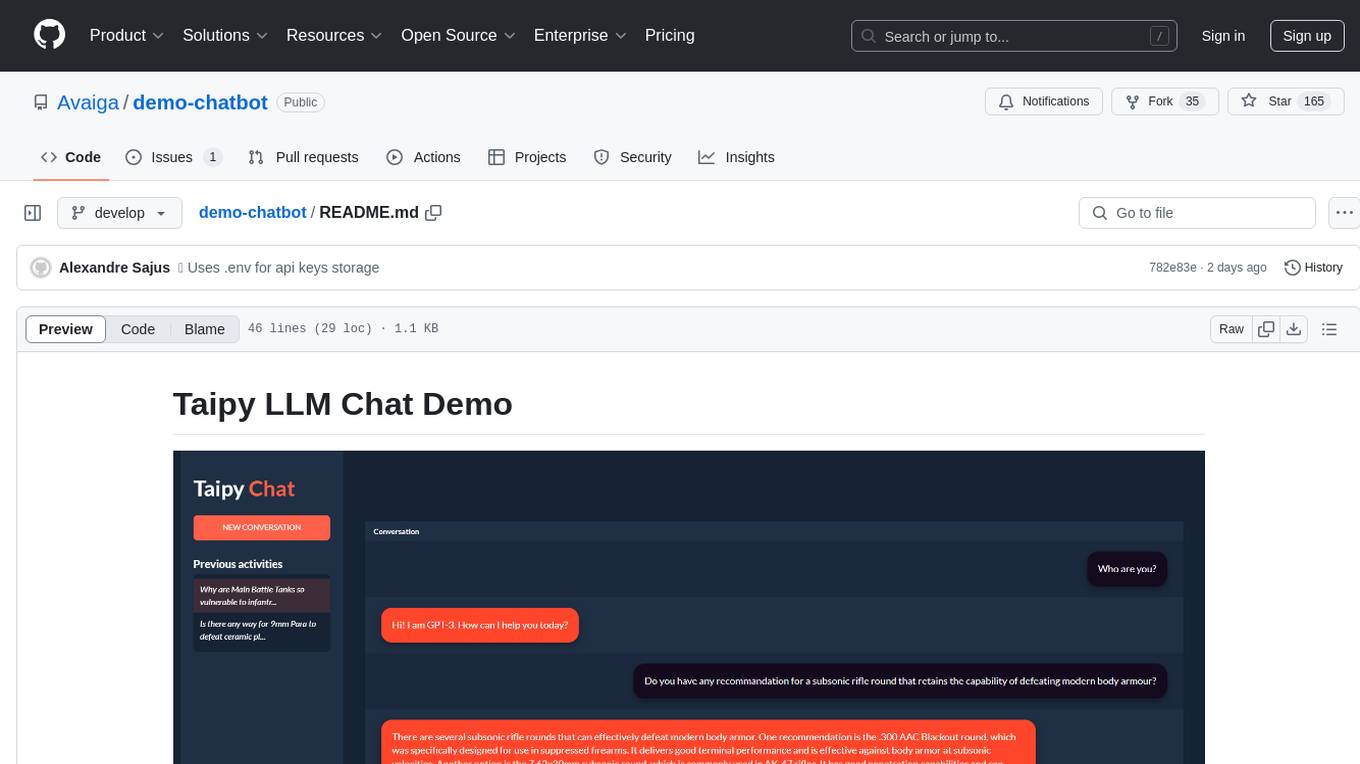
demo-chatbot
The demo-chatbot repository contains a simple app to chat with an LLM, allowing users to create any LLM Inference Web Apps using Python. The app utilizes OpenAI's GPT-4 API to generate responses to user messages, with the flexibility to switch to other APIs or models. The repository includes a tutorial in the Taipy documentation for creating the app. Users need an OpenAI account with an active API key to run the app by cloning the repository, installing dependencies, setting up the API key in a .env file, and running the main.py file.
melty
Melty is an open source AI code editor designed to help developers write production-ready code by collaborating with them from the terminal to GitHub. It can refactor code, create web apps from scratch, navigate large codebases, and write its own commits. Melty aims to help developers understand their code better, watch every change made, learn and adapt to the codebase, and integrate with various development tools.
mentat
Mentat is an AI tool designed to assist with coding tasks directly from the command line. It combines human creativity with computer-like processing to help users understand new codebases, add new features, and refactor existing code. Unlike other tools, Mentat coordinates edits across multiple locations and files, with the context of the project already in mind. The tool aims to enhance the coding experience by providing seamless assistance and improving edit quality.
mandark
Mandark is a lightweight AI tool that can perform various tasks, such as answering questions about codebases, editing files, verifying diffs, estimating token and cost before execution, and working with any codebase. It supports multiple AI models like Claude-3.5 Sonnet, Haiku, GPT-4o-mini, and GPT-4-turbo. Users can run Mandark without installation and easily interact with it through command line options. It offers flexibility in processing individual files or folders and allows for customization with optional AI model selection and output preferences.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.