
kwaak
Burn through tech debt with AI agents!
Stars: 190

Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.
README:







Always wanted to run a team of AI agents locally from your own machine? Write code, improve test coverage, update documentation, or improve code quality, while you focus on building the cool stuff? Kwaak enables you to run a team of autonomous AI agents right from your terminal, in parallel. You interact with Kwaak in a chat-like terminal interface.
Kwaak is free and open-source. You can bring your own API keys, or your own models via Ollama.

Kwaak is aware of your codebase and can answer questions about your code, find examples, write and execute code, create pull requests, and more. Unlike other tools, Kwaak is focussed on autonomous agents, and can run multiple agents at the same time.
[!CAUTION] Kwaak can be considered alpha software. The project is under active development; expect breaking changes. Contributions, feedback, and bug reports are very welcome.
Kwaak is part of the bosun.ai project. An upcoming platform for autonomous code improvement.
Powered by Swiftide
- Run multiple agents in parallel
- Quacking terminal interface
- As fast as it gets; written in Rust, powered by Swiftide
- Agents operate on code, use tools, and can be interacted with
- View and pull code changes from an agent; or have it create a pull request
- Sandboxed execution in docker
- OpenAI, Ollama, Anthropic, Azure, and many other models via OpenRouter
- Python, TypeScript/Javascript, Go, Java, Ruby, Solidity, C, C++, and Rust
Kwaak focuses on out-of-your-way autonomous agents. There are great tools available to utilize AI in your own coding workflow, Kwaak does the opposite. Throw your backlog at Kwaak, so you can work on the cool stuff.
Before you can run Kwaak, make sure you have Docker installed on your machine.
Kwaak expects a Dockerfile in the root of your project. If you already have a Dockerfile, you can just name it differently and configure it in the configuration file. This Dockerfile should contain all the dependencies required to test and run your code.
[!NOTE] Docker is used to provide a safe execution environment for the agents. It does not affect the performance of the LLMs. The LLMs are running either locally or in the cloud, and the docker container is only used to run the code. This is done to ensure that the agents cannot access your local system. Kwaak itself runs locally.
Additionally, the Dockerfile expects git and should be ubuntu based.
A simple example for Rust:
FROM rust:latest
RUN apt-get update && apt install git -y --no-install-recommends
COPY . /app
WORKDIR /appIf you already have a Dockerfile for other purposes, you can either extend it or provide a new one and override the dockerfile path in the configuration.
For an example Dockerfile in Rust, see this project's Dockerfile
Additionally, you will need an API key for your LLM of choice.
If you'd like kwaak to be able to make pull requests, search github code, and automatically push to a remote, a github token.
Pre-built binaries are available from the releases page.
brew install bosun-ai/tap/kwaak curl --proto '=https' --tlsv1.2 -LsSf https://github.com/bosun-ai/kwaak/releases/latest/download/kwaak-installer.sh | shInstall the binary directly with binstall
cargo binstall kwaakOr compile from source with Cargo:
cargo install kwaakThe package is available in the extra repositories and can be installed with pacman:
pacman -S kwaakOnce installed, you can run kwaak init in the project you want to use Kwaak in. This will guide you through the setup process and it will help you create a configuration file. See Configuration for more customization options.
Api keys can be prefixed by env:, text: and file: to read secrets from the environment, a text string, or a file respectively.
We highly recommend taking a look at the configuration file and adjusting it to your needs. There are various options that can improve the performance and accuracy of the agents.
You can then run kwaak in the root of your project. On initial bootup, Kwaak will index your codebase. This can take a while, depending on the size. Once indexing has been completed, subsequent startups will be faster.
Keybindings:
- ctrl-s: Send the current message to the agent
- ctrl-x: Exit the agent
- ctrl-q: Exit kwaak
- ctrl-n: Create a new agent
- Page Up: Scroll chat up
- Page Down: Scroll chat down
- tab: Switch between agents
Additionally, kwaak provides a number of slash commands, /help will show all available commands.
On initial boot up, Kwaak will index your codebase. This can take a while, depending on the size. Once indexing has been completed once, subsequent startups will be faster. Indexes are stored with duckdb. Kwaak uses the index to provide context to the agents.
Kwaak provides a chat interface similar to other LLM chat applications. You can type messages to the agent, and the agent will try to accomplish the task and respond.
When starting a chat, the code of the current branch is copied into an on-the-fly created docker container. This container is then used to run the code and execute the commands.
After each chat completion, kwaak can lint, commit, and push the code to the remote repository if any code changes have been made. Kwaak can also create a pull request. Pull requests include an issue link to #48. This helps us identify the success rate of the agents, and also enforces transparency for code reviewers. This behaviour is fully configurable.
Kwaak uses patch based editing by default. This means that only the changed lines are sent to the agent. This is more efficient. If you experience issues, try changing the edit mode to whole or line.
Kwaak supports configuring different Large Language Models (LLMs) for distinct tasks like indexing, querying, and embedding to optimize performance and accuracy. Be sure to tailor the configurations to fit the scope and blend of the tasks you're tackling.
All of these are inferred from the project directory and can be overridden in the kwaak.toml configuration file.
-
project_name: Defaults to the current directory name. Represents the name of your project. -
language: The programming language of the project, for instance, Rust, Go, Python, JavaScript, etc.
Kwaak uses tests, coverages, and lints as an additional opportunity to steer the agent. Configuring these will (significantly) improve the agents' performance.
-
test: Command to run tests, e.g.,cargo test. -
coverage: Command for running coverage checks, e.g.,cargo llvm-cov --summary-only. Expects coverage results as output. Currently handled unparsed via an LLM call. A friendly output is preferred -
lint_and_fix: Optional command to lint and fix project issues, e.g.,cargo clippy --fix --allow-dirty; cargo fmtin Rust.
- API keys and tokens can be configured through environment variables (
env:KEY), directly in the configuration (text:KEY), or through files (file:/path/to/key).
-
docker.dockerfile,docker.context: Paths to Dockerfile and context, default to project root andDockerfile. -
github.repository,github.main_branch,github.owner,github.token: GitHub repository details and token configuration.
Supported providers:
- OpenAI
- Ollama
- Anthropic
- Azure (
AzureOpenAI) - OpenRouter (no embeddings)
- FastEmbed (embeddings only)
OpenAI Configuration:
[llm.indexing]
api_key = "env:KWAAK_OPENAI_API_KEY"
provider = "OpenAI"
prompt_model = "gpt-4o-mini"
[llm.query]
api_key = "env:KWAAK_OPENAI_API_KEY"
provider = "OpenAI"
prompt_model = "gpt-4o"
[llm.embedding]
api_key = "env:KWAAK_OPENAI_API_KEY"
provider = "OpenAI"
embedding_model = "text-embedding-3-large"Ollama Configuration:
WARN: We do not recommend using the smaller models with kwaak, apart from indexing. The model should be able to make tool calls fairly reliable.
[llm.indexing]
provider = "Ollama"
prompt_model = "llama3.2"
[llm.query]
provider = "Ollama"
prompt_model = "llama3.3"
base_url = "http://localhost:11434/v1" # optional; this is the default
[llm.embedding]
provider = "Ollama"
embedding_model = { name = "bge-m3", vector_size = 1024 }Azure Configuration:
azure_openai_api_key = "env:KWAAK_AZURE_OPENAI_API_KEY"
[llm.indexing]
# or override it per provider
# api_key = "env:KWAAK_AZURE_OPENAI_API_KEY"
base_url = "https://your.base.url"
deployment_id = "your-deployment-id"
api_version = "version"
provider = "AzureOpenAI"
prompt_model = "gpt-4-mini"
[llm.query]
base_url = "https://your.base.url"
deployment_id = "your-deployment-id"
api_version = "version"
provider = "AzureOpenAI"
prompt_model = "gpt-4o"
[llm.embedding]
base_url = "https://your.base.url"
deployment_id = "your-deployment-id"
api_version = "version"
provider = "AzureOpenAI"
embedding_model = "text-embedding-3-large"For both you can provide a base_url to use a custom API endpoint. The api_key can be set per provider, or globally.
You can mix and match models from different providers for different tasks.
Kwaak uses the exponential backoff strategy to handle retries. Currently, only
OpenAI, OpenRouter, and Anthropic calls will make use of the backoff parameters.
You can configure the backoff settings in the kwaak.toml file under a
[backoff] section. These settings are optional, and default to the following
values:
-
initial_interval_sec: Defaults to 15 seconds. This sets the initial waiting time between retries. -
multiplier: Defaults to 2.0. This factor multiplies the interval on each retry attempt. -
randomization_factor: Defaults to 0.05. Introduces randomness to avoid retry storms. -
max_elapsed_time_sec: Defaults to 120 seconds. This total time all attempts are allowed.
Example Configuration:
[backoff]
initial_interval_sec = 15
multiplier = 2.0
randomization_factor = 0.05
max_elapsed_time_sec = 120-
agent_custom_constraints: Additional constraints / instructions for the agent. These are passes to the agent in the system prompt. If you intend to use more complicated instructions, consider adding a file to read in the repository instead. -
cache_dir,log_dir: Directories for cache and logs. Defaults are within your system's cache directory. -
indexing_concurrency: Adjust concurrency for indexing, defaults based on CPU count. -
indexing_batch_size: Batch size setting for indexing. Defaults to a higher value for Ollama and a lower value for OpenAI. -
endless_mode: DANGER If enabled, agents run continuously until manually stopped or completion is reached. This is meant for debugging and evaluation purposes. -
otel_enabled: Enables OpenTelemetry tracing if set and respects all the standard OpenTelemetry environment variables. -
tool_executor: Defaults todocker. Can also belocal. We HIGHLY recommend usingdockerfor security reasons unless you are running in a secure environment. -
tavily_api_key: Enables the agent to use tavily for web search. Their entry-level plan is free. (we are not affiliated) -
agent_edit_mode: Defaults topatch. Other options arewholeandline. If you experience issues, try changing the edit mode.wholewill always write the full file. This consumes more tokens and can have side effects. -
git.auto_push_remote: Enabled by default if a github key is present. Automatically pushes to the remote repository after each chat completion. You can disable this by setting it tofalse. -
git.auto_commit_disabled: Opt-out of automatic commits after each chat completion. -
tools: A list of tool names to enable or disable. Example:
[tools]
shell_command = false
search_code = truePossible values: "shell_command", "read_file",
"read_file_with_line_numbers", "write_file", "search_file", "git",
"reset_file", "search_code", "explain_code",
"create_or_update_pull_request", "run_tests", "run_coverage",
"search_web", "github_search_code", "fetch_url", "add_lines",
"replace_lines"
-
ui.hide_header: Optionally hide the top header in the UI. Defaults tofalse. -
num_completions_for_summary: Number of completions before the agent summarizes the conversation. Defaults to 10; -
git.agent_user_name: Name which the kwaak agent will make commands with. Defaults to "kwaak"` -
git.agent_user_email: Email which the kwaak agent will make commits with. Defaults to "[email protected]"
- Support for more LLMs
- Tools for code documentation
- More sources for additional context
- ... and more! (we don't really have a roadmap, but we have a lot of ideas)
Q: I get a lot of failures, errors, or otherwise unexpected behaviour from the agent.
A: Make sure you are not on a Tier 1 account with either OpenAI or Anthropic, the token limits are not enough to run coding agents. Additionally, you can also experiment with different edit modes. See agent_edit_mode. If you only have Tier 1 accounts, you can also consider using OpenRouter, which does not have these limits. It is generally a bit slower and less reliable.
Q: Kwaak feels very slow
A: Try increasing the resources available for docker. For docker desktop this is in Settings -> Resources -> Advanced. On MacOS, adding your terminal and/or kwaak to developer tools can also help.
Q:: There was an error during a chat, have I lost all progress?
A: Kwaak commits and pushes to the remote repository after each completion, so you should be able to recover the changes.
Q: I get a redb/duckdb error when starting, what is up?
A: Possibly your index got corrupted, or you have another kwaak instance running on the same project. Try clearing the index with kwaak clear-index and restart kwaak. Note that this will require a reindexing of your codebase.
Q: I get an error from Bollard: Socket not found /var/run/docker.sock
A: Enable the default Docker socket in docker desktop in General -> Advanced settings.
Q: I get an data did not match any variant of untagged enum LLMConfigurations
A: Make sure any env variables are set correctly, and that the configuration file is correct. This is unfortunately a very generic error.
Q: So why docker? How does it work? Does it affect local LLM performance?
A: Docker is only used to provide a save execution environment for the agents. It does not affect the performance of the LLMs. The LLMs are running either locally or in the cloud, and the docker container is only used to run the code. This is done to ensure that the agents cannot access your local system. Kwaak itself runs locally.
Q: What is the github token used for?
A: The github token is used to create pull requests, search code, and push code to a remote repository. It is not used for anything else.
Q: In my project, different contributors have different setups. How can I make sure kwaak works for everyone?
A: You can use a kwaak.local.toml and add it to your .gitignore. Alternatively, all configuration can be overridden by environment variables, prefixed with KWAAK and separated by double underscores. For instance, KWAAK__COMMAND_TEST=cargo nextest run. Overwriting via environment currently does not work for the llm configuration.
If you want to get more involved with kwaak, have questions or want to chat, you can find us on discord.
If you have a great idea, please fork the repo and create a pull request.
Don't forget to give the project a star! Thanks again!
See also ARCHITECTURE.md.
If you just want to contribute (bless you!), see our issues or join us on Discord.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'feat: Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
See CONTRIBUTING for more
Distributed under the MIT License. See LICENSE for more information.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kwaak
Similar Open Source Tools
kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.
PentestGPT
PentestGPT is a penetration testing tool empowered by ChatGPT, designed to automate the penetration testing process. It operates interactively to guide penetration testers in overall progress and specific operations. The tool supports solving easy to medium HackTheBox machines and other CTF challenges. Users can use PentestGPT to perform tasks like testing connections, using different reasoning models, discussing with the tool, searching on Google, and generating reports. It also supports local LLMs with custom parsers for advanced users.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.
OpenAI-sublime-text
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.
wcgw
wcgw is a shell and coding agent designed for Claude and Chatgpt. It provides full shell access with no restrictions, desktop control on Claude for screen capture and control, interactive command handling, large file editing, and REPL support. Users can use wcgw to create, execute, and iterate on tasks, such as solving problems with Python, finding code instances, setting up projects, creating web apps, editing large files, and running server commands. Additionally, wcgw supports computer use on Docker containers for desktop control. The tool can be extended with a VS Code extension for pasting context on Claude app and integrates with Chatgpt for custom GPT interactions.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.

agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.
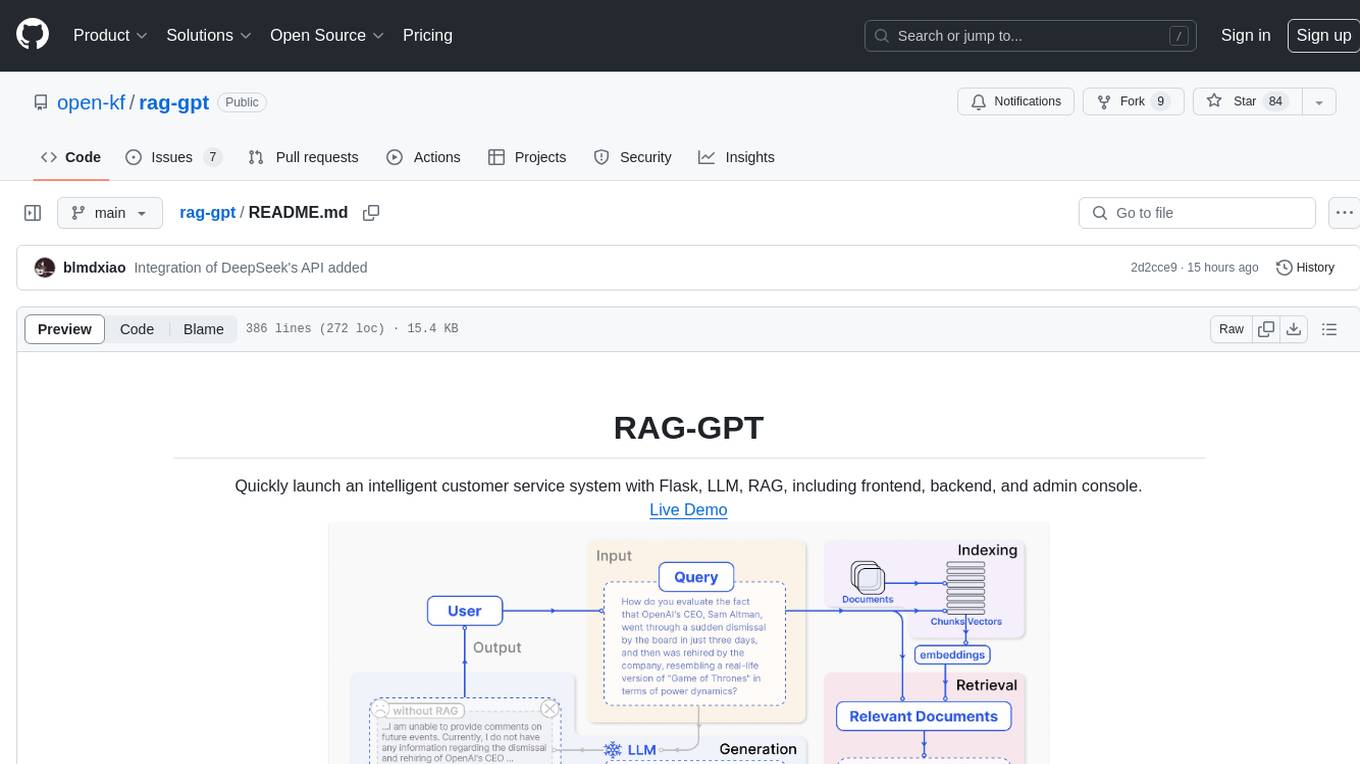
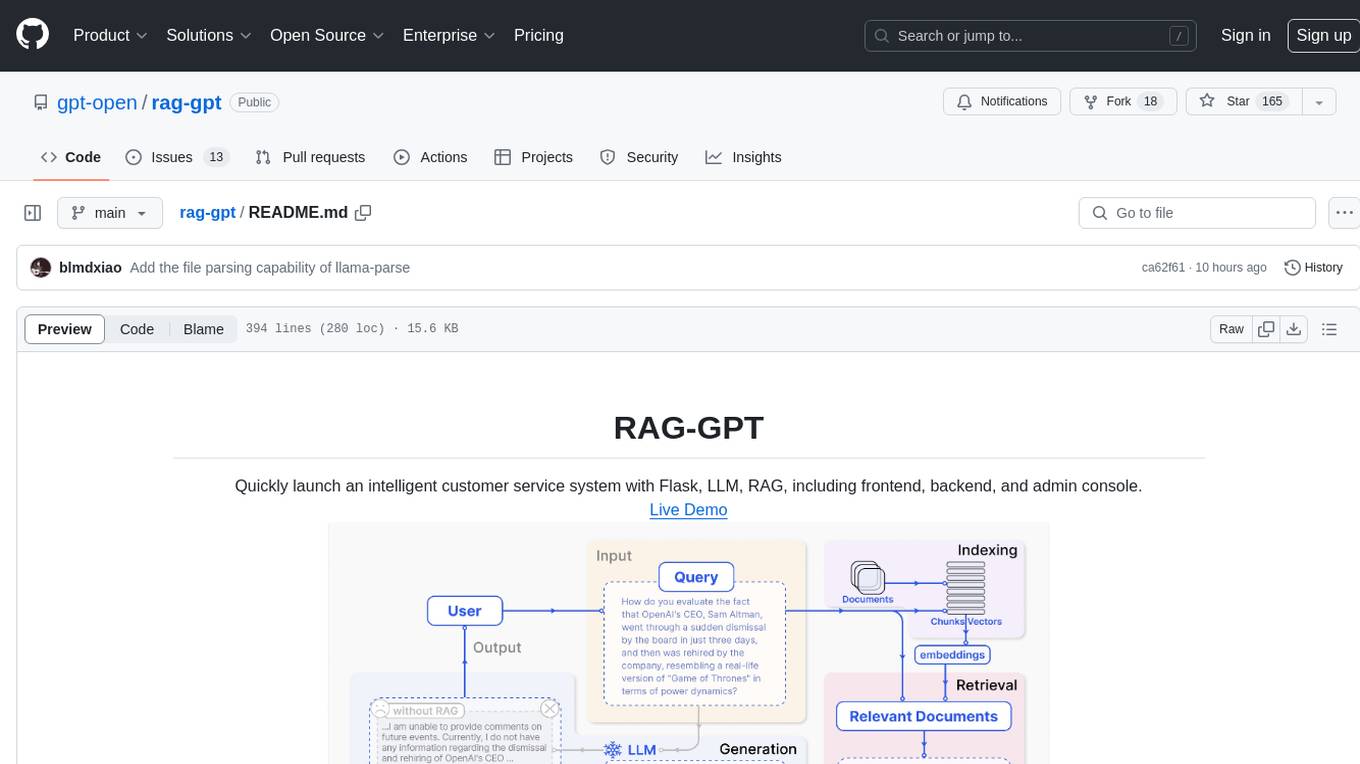
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, offers quick setup for conversational service robots, integrates diverse knowledge bases, provides flexible configuration options, and features an attractive user interface.

AutoAgent
AutoAgent is a fully-automated and zero-code framework that enables users to create and deploy LLM agents through natural language alone. It is a top performer on the GAIA Benchmark, equipped with a native self-managing vector database, and allows for easy creation of tools, agents, and workflows without any coding. AutoAgent seamlessly integrates with a wide range of LLMs and supports both function-calling and ReAct interaction modes. It is designed to be dynamic, extensible, customized, and lightweight, serving as a personal AI assistant.

fabric
Fabric is an open-source framework for augmenting humans using AI. It provides a structured approach to breaking down problems into individual components and applying AI to them one at a time. Fabric includes a collection of pre-defined Patterns (prompts) that can be used for a variety of tasks, such as extracting the most interesting parts of YouTube videos and podcasts, writing essays, summarizing academic papers, creating AI art prompts, and more. Users can also create their own custom Patterns. Fabric is designed to be easy to use, with a command-line interface and a variety of helper apps. It is also extensible, allowing users to integrate it with their own AI applications and infrastructure.

shellChatGPT
ShellChatGPT is a shell wrapper for OpenAI's ChatGPT, DALL-E, Whisper, and TTS, featuring integration with LocalAI, Ollama, Gemini, Mistral, Groq, and GitHub Models. It provides text and chat completions, vision, reasoning, and audio models, voice-in and voice-out chatting mode, text editor interface, markdown rendering support, session management, instruction prompt manager, integration with various service providers, command line completion, file picker dialogs, color scheme personalization, stdin and text file input support, and compatibility with Linux, FreeBSD, MacOS, and Termux for a responsive experience.
slack-bot
The Slack Bot is a tool designed to enhance the workflow of development teams by integrating with Jenkins, GitHub, GitLab, and Jira. It allows for custom commands, macros, crons, and project-specific commands to be implemented easily. Users can interact with the bot through Slack messages, execute commands, and monitor job progress. The bot supports features like starting and monitoring Jenkins jobs, tracking pull requests, querying Jira information, creating buttons for interactions, generating images with DALL-E, playing quiz games, checking weather, defining custom commands, and more. Configuration is managed via YAML files, allowing users to set up credentials for external services, define custom commands, schedule cron jobs, and configure VCS systems like Bitbucket for automated branch lookup in Jenkins triggers.
restai
RestAI is an AIaaS (AI as a Service) platform that allows users to create and consume AI agents (projects) using a simple REST API. It supports various types of agents, including RAG (Retrieval-Augmented Generation), RAGSQL (RAG for SQL), inference, vision, and router. RestAI features automatic VRAM management, support for any public LLM supported by LlamaIndex or any local LLM supported by Ollama, a user-friendly API with Swagger documentation, and a frontend for easy access. It also provides evaluation capabilities for RAG agents using deepeval.
For similar tasks
kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.
gpt-translate
Markdown Translation BOT is a GitHub action that translates markdown files into multiple languages using various AI models. It supports markdown, markdown-jsx, and json files only. The action can be executed by individuals with write permissions to the repository, preventing API abuse by non-trusted parties. Users can set up the action by providing their API key and configuring the workflow settings. The tool allows users to create comments with specific commands to trigger translations and automatically generate pull requests or add translated files to existing pull requests. It supports multiple file translations and can interpret any language supported by GPT-4 or GPT-3.5.
generative-ai-design-patterns
A catalog of design patterns for building generative AI applications, capturing current best practices in the field. The repository serves as a living catalog on GitHub to help practitioners navigate through the noise and identify areas for improvement. It is too early for a book due to the evolving nature of generative AI in production and the lack of concrete evidence to support certain claims.
opencode-manager
OpenCode Manager is a mobile-first web interface for managing and coding with OpenCode AI agents. It allows users to control and code from any device, including phones, tablets, and desktops. The tool provides features for repository and Git management, file management, chat and sessions, AI configuration, as well as mobile and PWA support. Users can clone and manage multiple git repos, work on multiple branches simultaneously, view changes, commits, and branches in a unified interface, create pull requests, navigate files with tree view and search, preview code with syntax highlighting, and perform various file operations. Additionally, the tool supports real-time streaming, slash commands, file mentions, plan/build modes, Mermaid diagrams, text-to-speech, speech-to-text, model selection, provider management, OAuth support, custom agents creation, and more. It is optimized for mobile devices, installable as a PWA, and offers push notifications for agent events.
code-review-gpt
Code Review GPT uses Large Language Models to review code in your CI/CD pipeline. It helps streamline the code review process by providing feedback on code that may have issues or areas for improvement. It should pick up on common issues such as exposed secrets, slow or inefficient code, and unreadable code. It can also be run locally in your command line to review staged files. Code Review GPT is in alpha and should be used for fun only. It may provide useful feedback but please check any suggestions thoroughly.
digma
Digma is a Continuous Feedback platform that provides code-level insights related to performance, errors, and usage during development. It empowers developers to own their code all the way to production, improving code quality and preventing critical issues. Digma integrates with OpenTelemetry traces and metrics to generate insights in the IDE, helping developers analyze code scalability, bottlenecks, errors, and usage patterns.
ai-codereviewer
AI Code Reviewer is a GitHub Action that utilizes OpenAI's GPT-4 API to provide intelligent feedback and suggestions on pull requests. It helps enhance code quality and streamline the code review process by offering insightful comments and filtering out specified files. The tool is easy to set up and integrate into GitHub workflows.
sourcery
Sourcery is an automated code reviewer tool that provides instant feedback on pull requests, helping to speed up the code review process, improve code quality, and accelerate development velocity. It offers high-level feedback, line-by-line suggestions, and aims to mimic the type of code review one would expect from a colleague. Sourcery can also be used as an IDE coding assistant to understand existing code, add unit tests, optimize code, and improve code quality with instant suggestions. It is free for public repos/open source projects and offers a 14-day trial for private repos.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.