
anterion
Open-source software engineer
Stars: 137
Anterion is an open-source AI software engineer that extends the capabilities of `SWE-agent` to plan and execute open-ended engineering tasks, with a frontend inspired by `OpenDevin`. It is designed to help users fix bugs and prototype ideas with ease. Anterion is equipped with easy deployment and a user-friendly interface, making it accessible to users of all skill levels.
README:
We've recently released a new web version of Anterion that requires no setup or LLM API key to use! You can access it here!:

Anterion is an open-source AI software engineer.
Anterion extends the capabilities of SWE-agent to plan and execute open-ended engineering tasks, with a frontend inspired by
OpenDevin.
We've equiped Anterion with easy deployment and UI to allow you to fix bugs and prototype ideas at ease.

🎉 Get on board with Anterion by doing the following! 🎉
- Linux, Mac OS, or WSL on Windows
- Docker
- Python >= 3.11
- NodeJS >= 18.17.1
- Miniconda
You will need to setup all three components of the system before being able to run it:
Before setting up OpenDevin, make a new conda environment and activate it by doing the following:
conda create --name anterion python=3.11
conda activate anterionTo setup OpenDevin, run the following command in the anterion directory:
make build-open-devinNext you will need to setup the SWE-agent.
To start, you will need to cd to the SWE-agent directory, and run the following
command:
cd SWE-agent
conda env create -f environment.yml
conda activate swe-agentYou will need to create a file called keys.cfg inside of the SWE-agent
directory:
OPENAI_API_KEY: '<OPENAI_API_KEY_GOES_HERE>'
ANTHROPIC_API_KEY: '<ANTHROPIC_API_KEY_GOES_HERE>'
GITHUB_TOKEN: '<GITHUB_PERSONAL_ACCESS_TOKEN_GOES_HERE>'And add the following
.env file inside of the SWE-agent directory:
NETLIFY_AUTH_TOKEN="<NETLIFY_AUTH_TOKEN_GOES_HERE>"
NETLIFY_SITE_ID="<NETLIFY_SITE_ID_GOES_HERE>"Netlify deployments are optional. If you do not want to use them or don't have netlify installed, you can leave both fields as empty strings.
From the SWE-agent directory head back to the anterion directory and run the following command to setup SWE-agent
cd ..
make build-swe-agentFinally, you need to setup the microservice, which ties together the
OpenDevin frontend and the SWE-agent agent.
First, within the microservice directory, create a new
directory called docker_volume which will be used to store files.
cd ./microservice
mkdir docker_volumeThen you need to create a .env file in the microservice directory
like the following:
OPENAI_API_KEY=<OPENAI_API_KEY_GOES_HERE>
ANTHROPIC_API_KEY=<ANTHROPIC_API_KEY_GOES_HERE>
SWE_AGENT_PATH=<SWE_AGENT_PATH_GOES_HERE>
PYTHON_PATH=<PATH_TO_SWE_AGENT_PYTHON_BINARY_GOES_HERE>
DOCKER_HOST_VOLUME_PATH=<PATH_TO_DOCKER_VOLUME_DIRECTORY_GOES_HERE>
DOCKER_CONTAINER_VOLUME_PATH=/usr/app
SWE_AGENT_PER_INSTANCE_COST_LIMIT=<MAX_USD_PER_AGENT_TASK>
SWE_AGENT_TIMEOUT=25
SWE_AGENT_MODEL_NAME=gpt4If you want to use an Ollama model, change SWE_AGENT_MODEL_NAME to look like the following:
SWE_AGENT_MODEL_NAME=ollama:<OLLAMA_MODEL_GOES_HERE>For example, if you want to try the new LLama 3 model, use the following line:
SWE_AGENT_MODEL_NAME=ollama:llama3Next, head from the microservice directory cd to the anterion directory and return to the anterion environment using:
cd ..
conda deactivateFinally, run the following command from the anterion directory to build the microservice:
make build-microserviceTo now run Anterion, you need to be in the anterion environment.
Then you need to run the frontend and the backend.
Run the following command from the anterion directory to run both together:
./run.shYou may have to change permissions for the file first:
chmod +x run.shIf that isn't working for some reason, run both of them separately:
make run-frontendmake run-backendWe'd like to say thanks to these amazing repos for inspiration!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for anterion
Similar Open Source Tools
anterion
Anterion is an open-source AI software engineer that extends the capabilities of `SWE-agent` to plan and execute open-ended engineering tasks, with a frontend inspired by `OpenDevin`. It is designed to help users fix bugs and prototype ideas with ease. Anterion is equipped with easy deployment and a user-friendly interface, making it accessible to users of all skill levels.
mods
AI for the command line, built for pipelines. LLM based AI is really good at interpreting the output of commands and returning the results in CLI friendly text formats like Markdown. Mods is a simple tool that makes it super easy to use AI on the command line and in your pipelines. Mods works with OpenAI, Groq, Azure OpenAI, and LocalAI To get started, install Mods and check out some of the examples below. Since Mods has built-in Markdown formatting, you may also want to grab Glow to give the output some _pizzazz_.
moxin
Moxin is an AI LLM client written in Rust to demonstrate the functionality of the Robius framework for multi-platform application development. It is currently in early stages of development and not fully functional. The tool supports building and running on macOS and Linux systems, with packaging options available for distribution. Users can install the required WasmEdge WASM runtime and dependencies to build and run Moxin. Packaging for distribution includes generating `.deb` Debian packages, AppImage, and pacman installation packages for Linux, as well as `.app` bundles and `.dmg` disk images for macOS. The macOS app is not signed, leading to a warning on installation, which can be resolved by removing the quarantine attribute from the installed app.

termax
Termax is an LLM agent in your terminal that converts natural language to commands. It is featured by: - Personalized Experience: Optimize the command generation with RAG. - Various LLMs Support: OpenAI GPT, Anthropic Claude, Google Gemini, Mistral AI, and more. - Shell Extensions: Plugin with popular shells like `zsh`, `bash` and `fish`. - Cross Platform: Able to run on Windows, macOS, and Linux.
fish-ai
fish-ai is a tool that adds AI functionality to Fish shell. It can be integrated with various AI providers like OpenAI, Azure OpenAI, Google, Hugging Face, Mistral, or a self-hosted LLM. Users can transform comments into commands, autocomplete commands, and suggest fixes. The tool allows customization through configuration files and supports switching between contexts. Data privacy is maintained by redacting sensitive information before submission to the AI models. Development features include debug logging, testing, and creating releases.
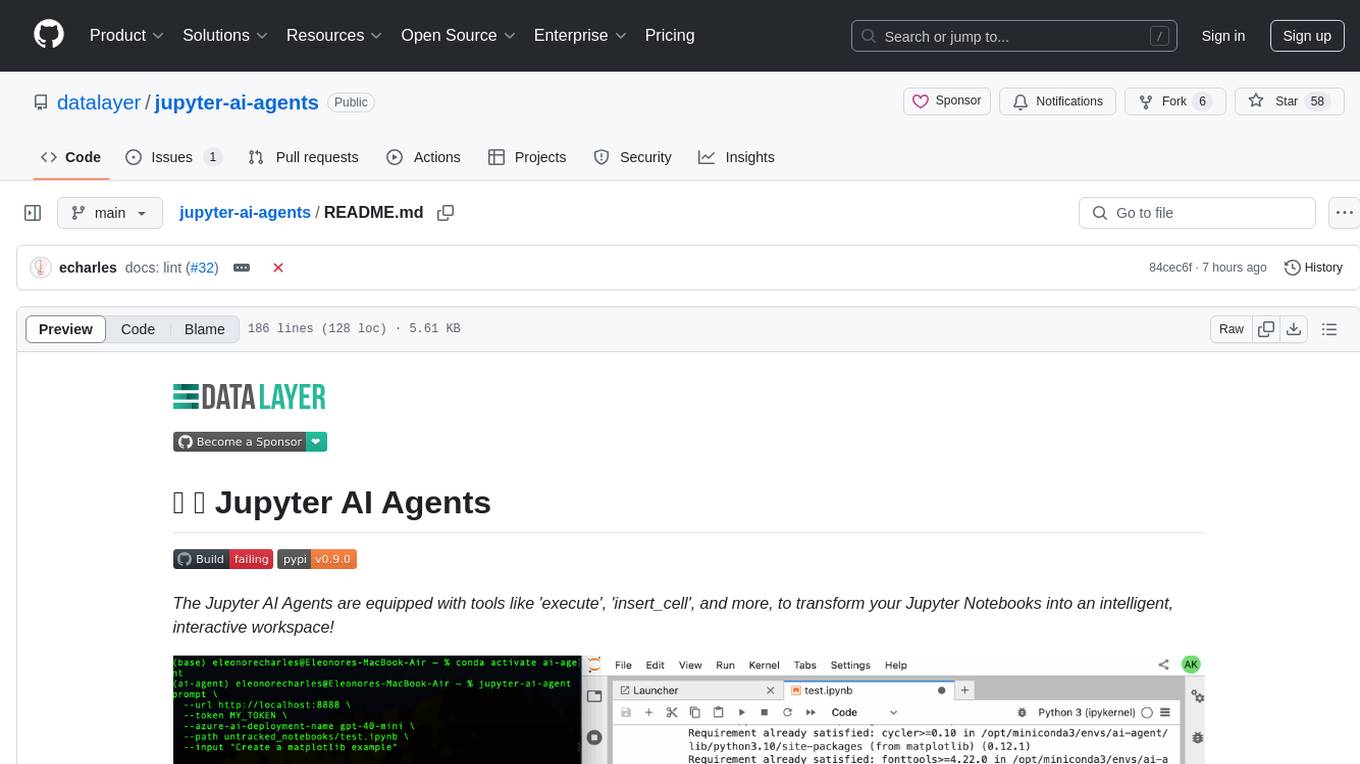
jupyter-ai-agents
The Jupyter AI Agents is a tool equipped with 'execute', 'insert_cell', and more, to transform Jupyter Notebooks into an intelligent, interactive workspace. It empowers AI models to interact with and modify Jupyter Notebooks comprehensively, operating on the entire notebook level. The agent communicates through RTC, enabling seamless modifications based on user instructions or notebook events. It uses the LangChain Agent Framework to manage interactions between AI models and tools, supporting real-time collaboration in JupyterLab. The tool can be installed via pip or from source, and supports multiple AI model providers like Azure OpenAI.
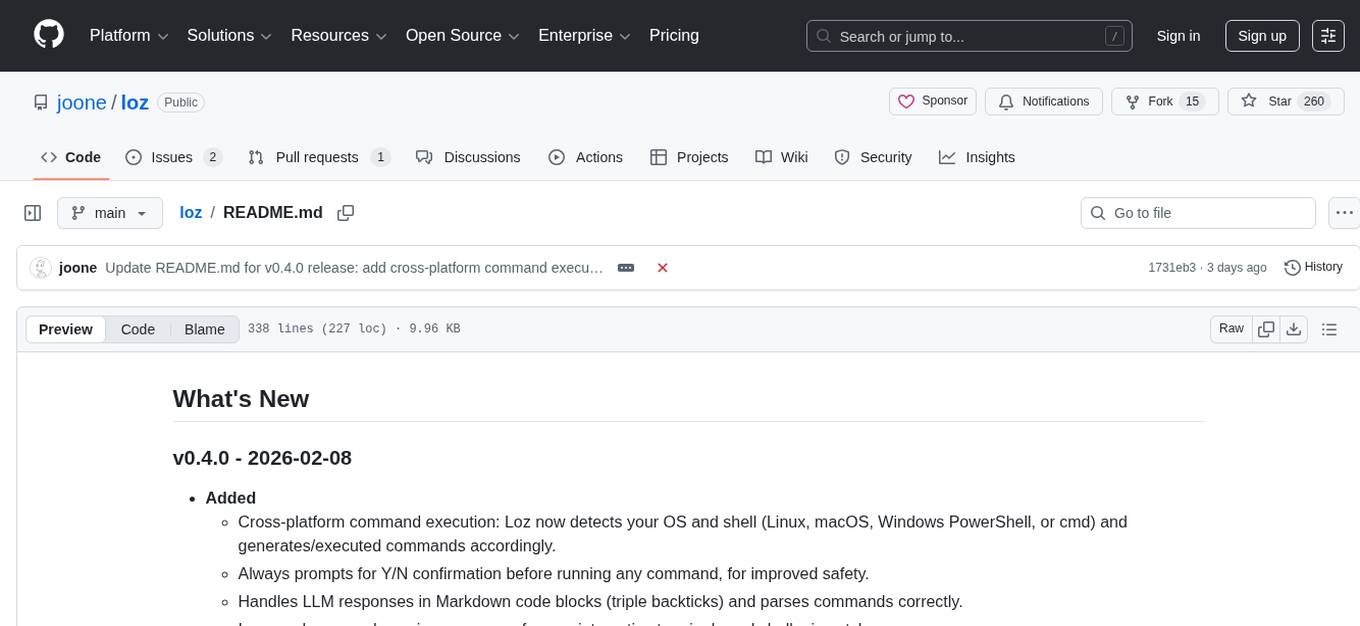
loz
Loz is a command-line tool that integrates AI capabilities with Unix tools, enabling users to execute system commands and utilize Unix pipes. It supports multiple LLM services like OpenAI API, Microsoft Copilot, and Ollama. Users can run Linux commands based on natural language prompts, enhance Git commit formatting, and interact with the tool in safe mode. Loz can process input from other command-line tools through Unix pipes and automatically generate Git commit messages. It provides features like chat history access, configurable LLM settings, and contribution opportunities.
chatlab
ChatLab is a Python package that simplifies experimenting with OpenAI's chat models. It provides an interactive interface for chatting with the models and registering custom functions. Users can easily create chat experiments, visualize color palettes, work with function registry, create knowledge graphs, and perform direct parallel function calling. The tool enables users to interact with chat models and customize functionalities for various tasks.

ML-Bench
ML-Bench is a tool designed to evaluate large language models and agents for machine learning tasks on repository-level code. It provides functionalities for data preparation, environment setup, usage, API calling, open source model fine-tuning, and inference. Users can clone the repository, load datasets, run ML-LLM-Bench, prepare data, fine-tune models, and perform inference tasks. The tool aims to facilitate the evaluation of language models and agents in the context of machine learning tasks on code repositories.

opencommit
OpenCommit is a tool that auto-generates meaningful commits using AI, allowing users to quickly create commit messages for their staged changes. It provides a CLI interface for easy usage and supports customization of commit descriptions, emojis, and AI models. Users can configure local and global settings, switch between different AI providers, and set up Git hooks for integration with IDE Source Control. Additionally, OpenCommit can be used as a GitHub Action to automatically improve commit messages on push events, ensuring all commits are meaningful and not generic. Payments for OpenAI API requests are handled by the user, with the tool storing API keys locally.

hordelib
horde-engine is a wrapper around ComfyUI designed to run inference pipelines visually designed in the ComfyUI GUI. It enables users to design inference pipelines in ComfyUI and then call them programmatically, maintaining compatibility with the existing horde implementation. The library provides features for processing Horde payloads, initializing the library, downloading and validating models, and generating images based on input data. It also includes custom nodes for preprocessing and tasks such as face restoration and QR code generation. The project depends on various open source projects and bundles some dependencies within the library itself. Users can design ComfyUI pipelines, convert them to the backend format, and run them using the run_image_pipeline() method in hordelib.comfy.Comfy(). The project is actively developed and tested using git, tox, and a specific model directory structure.
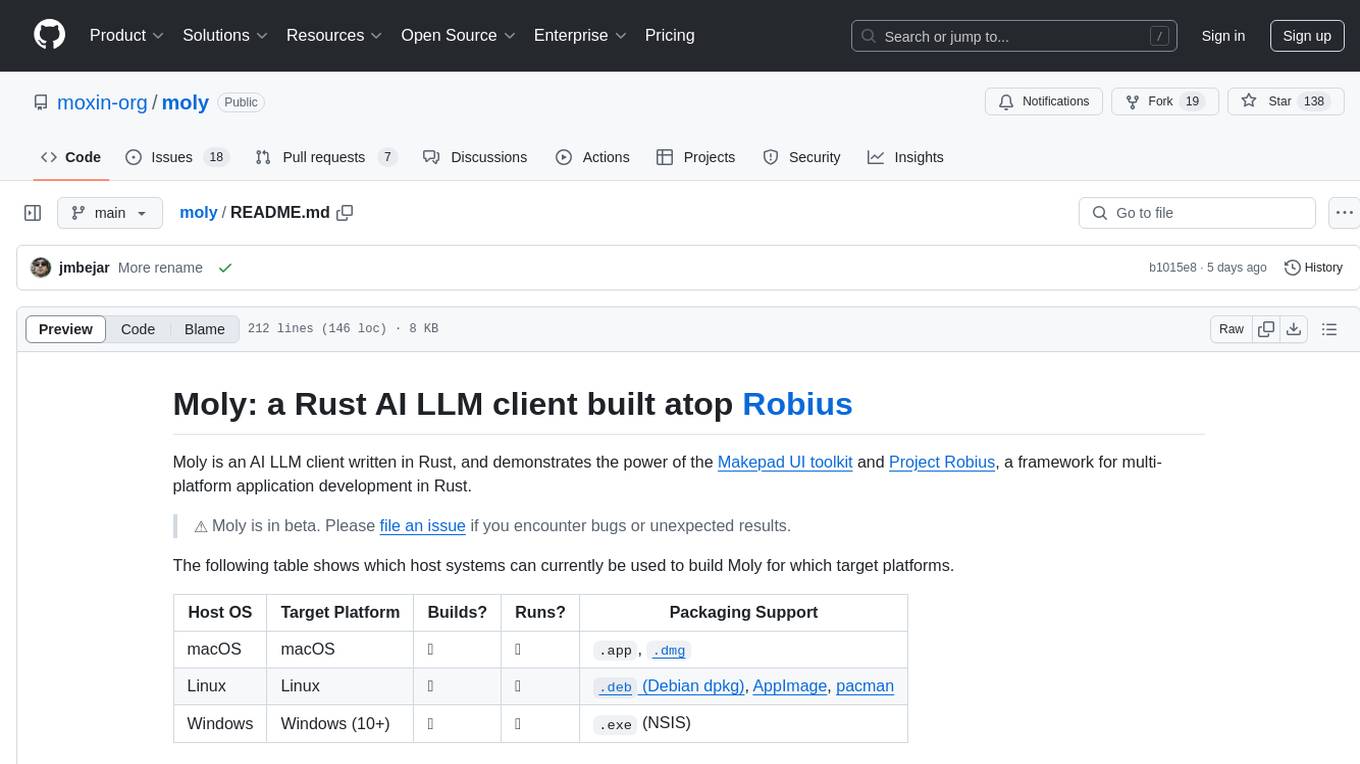
moly
Moly is an AI LLM client written in Rust, showcasing the capabilities of the Makepad UI toolkit and Project Robius, a framework for multi-platform application development in Rust. It is currently in beta, allowing users to build and run Moly on macOS, Linux, and Windows. The tool provides packaging support for different platforms, such as `.app`, `.dmg`, `.deb`, AppImage, pacman, and `.exe` (NSIS). Users can easily set up WasmEdge using `moly-runner` and leverage `cargo` commands to build and run Moly. Additionally, Moly offers pre-built releases for download and supports packaging for distribution on Linux, Windows, and macOS.
shell-pilot
Shell-pilot is a simple, lightweight shell script designed to interact with various AI models such as OpenAI, Ollama, Mistral AI, LocalAI, ZhipuAI, Anthropic, Moonshot, and Novita AI from the terminal. It enhances intelligent system management without any dependencies, offering features like setting up a local LLM repository, using official models and APIs, viewing history and session persistence, passing input prompts with pipe/redirector, listing available models, setting request parameters, generating and running commands in the terminal, easy configuration setup, system package version checking, and managing system aliases.

vectorflow
VectorFlow is an open source, high throughput, fault tolerant vector embedding pipeline. It provides a simple API endpoint for ingesting large volumes of raw data, processing, and storing or returning the vectors quickly and reliably. The tool supports text-based files like TXT, PDF, HTML, and DOCX, and can be run locally with Kubernetes in production. VectorFlow offers functionalities like embedding documents, running chunking schemas, custom chunking, and integrating with vector databases like Pinecone, Qdrant, and Weaviate. It enforces a standardized schema for uploading data to a vector store and supports features like raw embeddings webhook, chunk validation webhook, S3 endpoint, and telemetry. The tool can be used with the Python client and provides detailed instructions for running and testing the functionalities.

HuggingFaceGuidedTourForMac
HuggingFaceGuidedTourForMac is a guided tour on how to install optimized pytorch and optionally Apple's new MLX, JAX, and TensorFlow on Apple Silicon Macs. The repository provides steps to install homebrew, pytorch with MPS support, MLX, JAX, TensorFlow, and Jupyter lab. It also includes instructions on running large language models using HuggingFace transformers. The repository aims to help users set up their Macs for deep learning experiments with optimized performance.

chat-ai
A Seamless Slurm-Native Solution for HPC-Based Services. This repository contains the stand-alone web interface of Chat AI, which can be set up independently to act as a wrapper for an OpenAI-compatible API endpoint. It consists of two Docker containers, 'front' and 'back', providing a ReactJS app served by ViteJS and a wrapper for message requests to prevent CORS errors. Configuration files allow setting port numbers, backend paths, models, user data, default conversation settings, and more. The 'back' service interacts with an OpenAI-compatible API endpoint using configurable attributes in 'back.json'. Customization options include creating a path for available models and setting the 'modelsPath' in 'front.json'. Acknowledgements to contributors and the Chat AI community are included.
For similar tasks

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
continue
Continue is an open-source autopilot for VS Code and JetBrains that allows you to code with any LLM. With Continue, you can ask coding questions, edit code in natural language, generate files from scratch, and more. Continue is easy to use and can help you save time and improve your coding skills.
anterion
Anterion is an open-source AI software engineer that extends the capabilities of `SWE-agent` to plan and execute open-ended engineering tasks, with a frontend inspired by `OpenDevin`. It is designed to help users fix bugs and prototype ideas with ease. Anterion is equipped with easy deployment and a user-friendly interface, making it accessible to users of all skill levels.
sglang
SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with LLMs faster and more controllable by co-designing the frontend language and the runtime system. The core features of SGLang include: - **A Flexible Front-End Language**: This allows for easy programming of LLM applications with multiple chained generation calls, advanced prompting techniques, control flow, multiple modalities, parallelism, and external interaction. - **A High-Performance Runtime with RadixAttention**: This feature significantly accelerates the execution of complex LLM programs by automatic KV cache reuse across multiple calls. It also supports other common techniques like continuous batching and tensor parallelism.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.
aider
Aider is a command-line tool that lets you pair program with GPT-3.5/GPT-4 to edit code stored in your local git repository. Aider will directly edit the code in your local source files and git commit the changes with sensible commit messages. You can start a new project or work with an existing git repo. Aider is unique in that it lets you ask for changes to pre-existing, larger codebases.
chatgpt-web
ChatGPT Web is a web application that provides access to the ChatGPT API. It offers two non-official methods to interact with ChatGPT: through the ChatGPTAPI (using the `gpt-3.5-turbo-0301` model) or through the ChatGPTUnofficialProxyAPI (using a web access token). The ChatGPTAPI method is more reliable but requires an OpenAI API key, while the ChatGPTUnofficialProxyAPI method is free but less reliable. The application includes features such as user registration and login, synchronization of conversation history, customization of API keys and sensitive words, and management of users and keys. It also provides a user interface for interacting with ChatGPT and supports multiple languages and themes.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.