
docker-aio
Docker installation and mirror
Stars: 56

The docker-aio repository provides an accelerated mirror service for Docker users, allowing them to speed up image pulls by replacing original domains with corresponding accelerated domains. Users in Asia are advised to comply with local laws and regulations when using this service. The repository offers installation scripts and instructions on how to modify Docker configurations to utilize the accelerated mirrors effectively.
README:
This accelerated mirror service is not available for users in Asia. Please check and comply with local laws and regulations. When using this service, ensure you comply with relevant laws and regulations. If your rights have been infringed upon, please contact Azimiao | imashen for resolution.
curl -fsSL https://docker.13140521.xyz/install | bash -s docker --mirror Aliyun
Options:
```text
--channel <stable|test>
--version <VERSION>
--mirror <Aliyun|AzureChinaCloud>Please note that before using any accelerated mirrors, ensure that the acceleration service meets your needs and that you comply with relevant terms of use and service agreements.
Accelerated domain: *.13140521.xyz
Below are some common Docker mirror sources and their corresponding accelerated domains:
| Source Domain | Accelerated Domain |
|---|---|
| quay.io | quay.13140521.xyz |
| gcr.io | gcr.13140521.xyz |
| ghcr.io | ghcr.13140521.xyz |
| k8s.gcr.io | k8s-gcr.13140521.xyz |
| registry.k8s.io | k8s.13140521.xyz |
| docker.cloudsmith.io | cloudsmith.13140521.xyz |
| mcr.microsoft.com | mcr.13140521.xyz |
| docker.elastic.co | elastic.13140521.xyz |
When using an accelerated mirror, replace the original domain in your Docker configuration with the corresponding accelerated domain from the table above. For example, if you want to use the accelerated mirror for quay.io, replace all references to quay.io with quay.13140521.xyz.
Note: In some versions, the configuration file is not named
daemon.jsonbut ratherdaemon.conf. Please adjust according to the actual version! If you do not make the necessary changes, you may face the following error:Job for docker.service failed because the control process exited with error code. See "systemctl status docker.service" and "journalctl -xeu docker.service" for details.
1.Edit the Docker configuration file:
Open the Docker configuration file (usually located at /etc/docker/daemon.json):
sudo nano /etc/docker/daemon.json2.Add or modify the mirror source:
Add or modify the registry-mirrors field in the configuration file:
{
"registry-mirrors": [
"https://docker.13140521.xyz"
]
}3.Restart the Docker service:
Save the configuration file and restart the Docker service:
sudo systemctl daemon-reload
sudo systemctl restart dockerSpecify the mirror source when pulling/viewing images:
For example, specify the accelerated source when pulling an image from quay.io:
docker pull quay.13140521.xyz/library/image_name:tagFor example, specify the accelerated source when inspecting an image from quay.io:
docker inspect quay.13140521.xyz/library/image_name:tagFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for docker-aio
Similar Open Source Tools
docker-aio
The docker-aio repository provides an accelerated mirror service for Docker users, allowing them to speed up image pulls by replacing original domains with corresponding accelerated domains. Users in Asia are advised to comply with local laws and regulations when using this service. The repository offers installation scripts and instructions on how to modify Docker configurations to utilize the accelerated mirrors effectively.

OneKE
OneKE is a flexible dockerized system for schema-guided knowledge extraction, capable of extracting information from the web and raw PDF books across multiple domains like science and news. It employs a collaborative multi-agent approach and includes a user-customizable knowledge base to enable tailored extraction. OneKE offers various IE tasks support, data sources support, LLMs support, extraction method support, and knowledge base configuration. Users can start with examples using YAML, Python, or Web UI, and perform tasks like Named Entity Recognition, Relation Extraction, Event Extraction, Triple Extraction, and Open Domain IE. The tool supports different source formats like Plain Text, HTML, PDF, Word, TXT, and JSON files. Users can choose from various extraction models like OpenAI, DeepSeek, LLaMA, Qwen, ChatGLM, MiniCPM, and OneKE for information extraction tasks. Extraction methods include Schema Agent, Extraction Agent, and Reflection Agent. The tool also provides support for schema repository and case repository management, along with solutions for network issues. Contributors to the project include Ningyu Zhang, Haofen Wang, Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, and Huajun Chen.

weblinx
WebLINX is a Python library and dataset for real-world website navigation with multi-turn dialogue. The repository provides code for training models reported in the WebLINX paper, along with a comprehensive API to work with the dataset. It includes modules for data processing, model evaluation, and utility functions. The modeling directory contains code for processing, training, and evaluating models such as DMR, LLaMA, MindAct, Pix2Act, and Flan-T5. Users can install specific dependencies for HTML processing, video processing, model evaluation, and library development. The evaluation module provides metrics and functions for evaluating models, with ongoing work to improve documentation and functionality.
llama-recipes
The llama-recipes repository provides a scalable library for fine-tuning Llama 2, along with example scripts and notebooks to quickly get started with using the Llama 2 models in a variety of use-cases, including fine-tuning for domain adaptation and building LLM-based applications with Llama 2 and other tools in the LLM ecosystem. The examples here showcase how to run Llama 2 locally, in the cloud, and on-prem.
ai-dial-core
AI DIAL Core is an HTTP Proxy that provides a unified API to different chat completion and embedding models, assistants, and applications. It is written in Java 17 and built on Eclipse Vert.x. The core functionality includes handling static and dynamic settings, deployment on Kubernetes using Helm charts, and storing user data in Blob Storage and Redis. It supports various identity providers, storage providers like AWS S3, Google Cloud Storage, and Azure Blob Store, and features like AI DIAL Addons, Interceptors, Assistants, Applications, and Models with customizable parameters and configurations.
mcp
The Snowflake Cortex AI Model Context Protocol (MCP) Server provides tooling for Snowflake Cortex AI, object management, and SQL orchestration. It supports capabilities such as Cortex Search, Cortex Analyst, Cortex Agent, Object Management, SQL Execution, and Semantic View Querying. Users can connect to Snowflake using various authentication methods like username/password, key pair, OAuth, SSO, and MFA. The server is client-agnostic and works with MCP Clients like Claude Desktop, Cursor, fast-agent, Microsoft Visual Studio Code + GitHub Copilot, and Codex. It includes tools for Object Management (creating, dropping, describing, listing objects), SQL Execution (executing SQL statements), and Semantic View Querying (discovering, querying Semantic Views). Troubleshooting can be done using the MCP Inspector tool.
call-center-ai
Call Center AI is an AI-powered call center solution leveraging Azure and OpenAI GPT. It allows for AI agent-initiated phone calls or direct calls to the bot from a configured phone number. The bot is customizable for various industries like insurance, IT support, and customer service, with features such as accessing claim information, conversation history, language change, SMS sending, and more. The project is a proof of concept showcasing the integration of Azure Communication Services, Azure Cognitive Services, and Azure OpenAI for an automated call center solution.
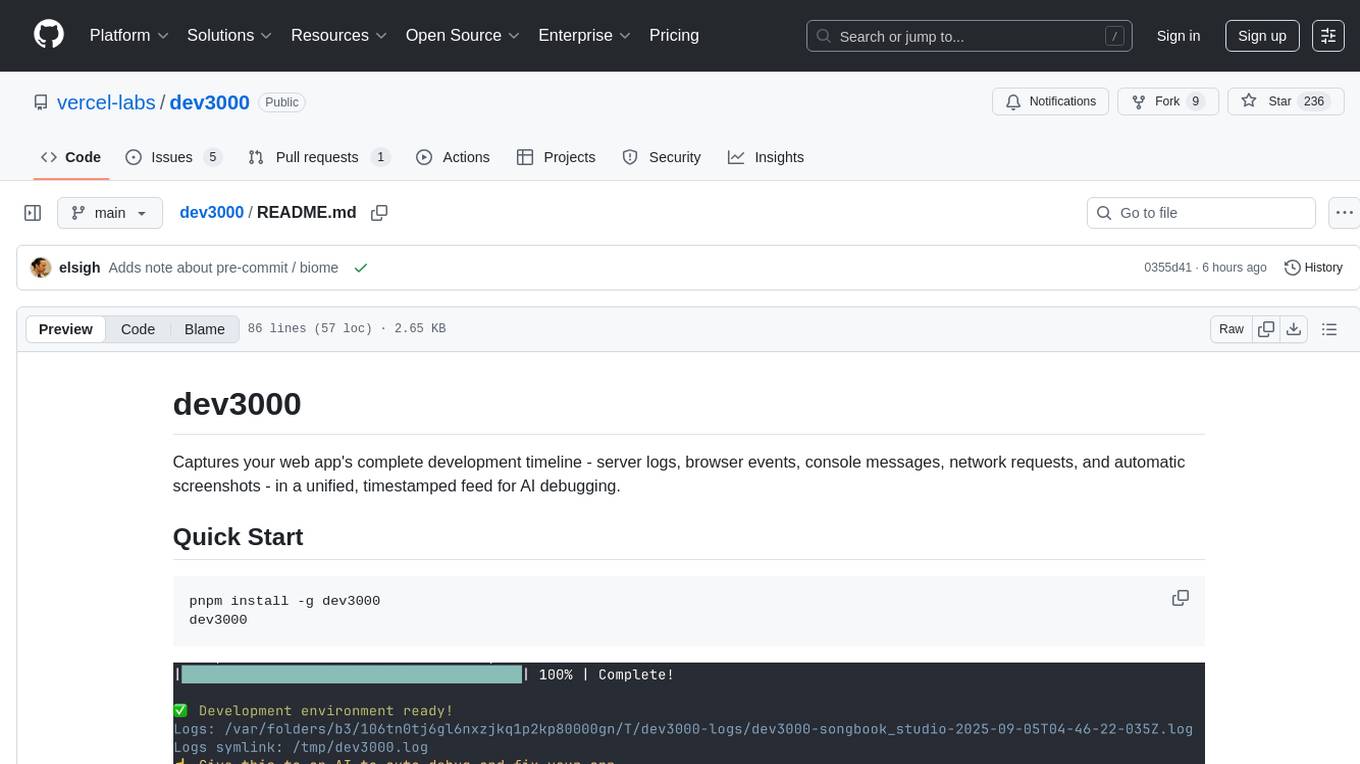
dev3000
dev3000 captures your web app's complete development timeline including server logs, browser events, console messages, network requests, and automatic screenshots in a unified, timestamped feed for AI debugging. It creates a comprehensive log of your development session that AI assistants can easily understand, monitoring your app in a real browser and capturing server logs, console output, browser console messages and errors, network requests and responses, and automatic screenshots on navigation, errors, and key events. Logs are saved with timestamps and rotated to keep the 10 most recent per project, with the current session symlinked for easy access. The tool integrates with AI assistants for instant debugging and provides advanced querying options through the MCP server.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.

llm-foundry
LLM Foundry is a codebase for training, finetuning, evaluating, and deploying LLMs for inference with Composer and the MosaicML platform. It is designed to be easy-to-use, efficient _and_ flexible, enabling rapid experimentation with the latest techniques. You'll find in this repo: * `llmfoundry/` - source code for models, datasets, callbacks, utilities, etc. * `scripts/` - scripts to run LLM workloads * `data_prep/` - convert text data from original sources to StreamingDataset format * `train/` - train or finetune HuggingFace and MPT models from 125M - 70B parameters * `train/benchmarking` - profile training throughput and MFU * `inference/` - convert models to HuggingFace or ONNX format, and generate responses * `inference/benchmarking` - profile inference latency and throughput * `eval/` - evaluate LLMs on academic (or custom) in-context-learning tasks * `mcli/` - launch any of these workloads using MCLI and the MosaicML platform * `TUTORIAL.md` - a deeper dive into the repo, example workflows, and FAQs
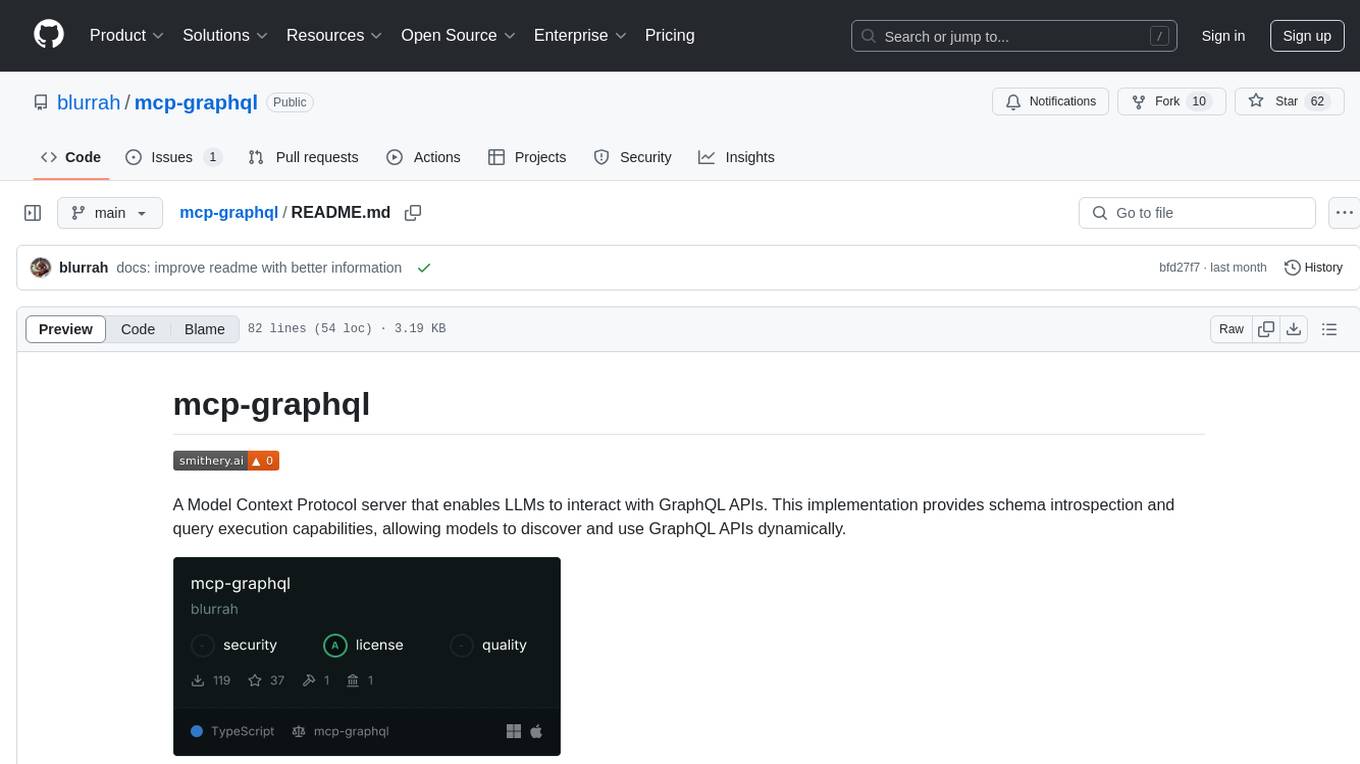
mcp-graphql
mcp-graphql is a Model Context Protocol server that enables Large Language Models (LLMs) to interact with GraphQL APIs. It provides schema introspection and query execution capabilities, allowing models to dynamically discover and use GraphQL APIs. The server offers tools for retrieving the GraphQL schema and executing queries against the endpoint. Mutations are disabled by default for security reasons. Users can install mcp-graphql via Smithery or manually to Claude Desktop. It is recommended to carefully consider enabling mutations in production environments to prevent unauthorized data modifications.
LEADS
LEADS is a lightweight embedded assisted driving system designed to simplify the development of instrumentation, control, and analysis systems for racing cars. It is written in Python and C/C++ with impressive performance. The system is customizable and provides abstract layers for component rearrangement. It supports hardware components like Raspberry Pi and Arduino, and can adapt to various hardware types. LEADS offers a modular structure with a focus on flexibility and lightweight design. It includes robust safety features, modern GUI design with dark mode support, high performance on different platforms, and powerful ESC systems for traction control and braking. The system also supports real-time data sharing, live video streaming, and AI-enhanced data analysis for driver training. LEADS VeC Remote Analyst enables transparency between the driver and pit crew, allowing real-time data sharing and analysis. The system is designed to be user-friendly, adaptable, and efficient for racing car development.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
we0
We0 is a web project generation tool that offers browser-based debugging, high-fidelity design restoration, importing historical projects, integration with WeChat Mini Program Developer Tools, and multi-platform support. It supports code generation, design-to-code conversion, open-source projects, WeChat Mini Program Tools preview, existing projects, and Deepseek. The tool uses pnpm as the package management tool and requires Node.js version 18.20. Users can install and configure the tool for web development and utilize quick start methods for building the web editor. Additionally, instructions are provided for installing and using the client version on Mac, along with troubleshooting tips. For any questions or support, users can contact [email protected] or join the WeChat group chat.
playword
PlayWord is a tool designed to supercharge web test automation experience with AI. It provides core features such as enabling browser operations and validations using natural language inputs, as well as monitoring interface to record and dry-run test steps. PlayWord supports multiple AI services including Anthropic, Google, and OpenAI, allowing users to select the appropriate provider based on their requirements. The tool also offers features like assertion handling, frame handling, custom variables, test recordings, and an Observer module to track user interactions on web pages. With PlayWord, users can interact with web pages using natural language commands, reducing the need to worry about element locators and providing AI-powered adaptation to UI changes.
For similar tasks
interpret
InterpretML is an open-source package that incorporates state-of-the-art machine learning interpretability techniques under one roof. With this package, you can train interpretable glassbox models and explain blackbox systems. InterpretML helps you understand your model's global behavior, or understand the reasons behind individual predictions. Interpretability is essential for: - Model debugging - Why did my model make this mistake? - Feature Engineering - How can I improve my model? - Detecting fairness issues - Does my model discriminate? - Human-AI cooperation - How can I understand and trust the model's decisions? - Regulatory compliance - Does my model satisfy legal requirements? - High-risk applications - Healthcare, finance, judicial, ...
llm_aigc
The llm_aigc repository is a comprehensive resource for everything related to llm (Large Language Models) and aigc (AI Governance and Control). It provides detailed information, resources, and tools for individuals interested in understanding and working with large language models and AI governance and control. The repository covers a wide range of topics including model training, evaluation, deployment, ethics, and regulations in the AI field.
docker-aio
The docker-aio repository provides an accelerated mirror service for Docker users, allowing them to speed up image pulls by replacing original domains with corresponding accelerated domains. Users in Asia are advised to comply with local laws and regulations when using this service. The repository offers installation scripts and instructions on how to modify Docker configurations to utilize the accelerated mirrors effectively.
For similar jobs

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
generative-ai-cdk-constructs
The AWS Generative AI Constructs Library is an open-source extension of the AWS Cloud Development Kit (AWS CDK) that provides multi-service, well-architected patterns for quickly defining solutions in code to create predictable and repeatable infrastructure, called constructs. The goal of AWS Generative AI CDK Constructs is to help developers build generative AI solutions using pattern-based definitions for their architecture. The patterns defined in AWS Generative AI CDK Constructs are high level, multi-service abstractions of AWS CDK constructs that have default configurations based on well-architected best practices. The library is organized into logical modules using object-oriented techniques to create each architectural pattern model.

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
dify-helm
Deploy langgenius/dify, an LLM based chat bot app on kubernetes with helm chart.