
OpenFactVerification
Loki: Open-source solution designed to automate the process of verifying factuality
Stars: 856

Loki is an open-source tool designed to automate the process of verifying the factuality of information. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information.
README:

Loki is our open-source solution designed to automate the process of verifying factuality. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information. To stay updated, please subscribe to our newsletter at our website or join us on Discord!
git clone https://github.com/Libr-AI/OpenFactVerification.git
cd OpenFactVerification- Install Poetry by following it installation guideline.
- Install all dependencies by running:
poetry install-
Create a Python environment at version 3.9 or newer and activate it.
-
Navigate to the project directory and install the required packages:
pip install -r requirements.txtYou can choose to export essential api key to the environment
- Example: Export essential api key to the environment
export SERPER_API_KEY=... # this is required in evidence retrieval if serper being used
export OPENAI_API_KEY=... # this is required in all tasksAlternatively, you configure API keys via a YAML file, see user guide for more details.
A sample test case:

The main interface of Loki fact-checker located in factcheck/__init__.py, which contains the check_response method. This method integrates the complete fact verification pipeline, where each functionality is encapsulated in its class as described in the Features section.
from factcheck import FactCheck
factcheck_instance = FactCheck()
# Example text
text = "Your text here"
# Run the fact-check pipeline
results = factcheck_instance.check_response(text)
print(results)python webapp.py --api_config demo_data/api_config.yaml# String
python -m factcheck --modal string --input "MBZUAI is the first AI university in the world"
# Text
python -m factcheck --modal text --input demo_data/text.txt
# Speech
python -m factcheck --modal speech --input demo_data/speech.mp3
# Image
python -m factcheck --modal image --input demo_data/image.webp
# Video
python -m factcheck --modal video --input demo_data/video.m4vFor advanced usage, please see our user guide.
💪 Join Our Journey to Innovation with the Supporter Edition
As we continue to evolve and enhance our fact-checking solution, we're excited to invite you to become an integral part of our journey. By registering for our Supporter Edition, you're not just unlocking a suite of advanced features and benefits; you're also fueling the future of trustworthy information.
Your support enables us to:
🚀 Innovate continuously: Develop new, cutting-edge features that keep you ahead in the fight against misinformation.
💡 Improve and refine: Enhance the user experience, making our app not just powerful, but also a joy to use.
🌱 Grow our community: Invest in the resources and tools our community needs to thrive and expand.
🎁 And as a token of our gratitude, registering now grants you complimentary token credits—a little thank you from us to you, for believing in our mission and supporting our growth!
| Feature | Open-Source Edition | Supporter Edition |
|---|---|---|
| Trustworthy Verification Results | ✅ | ✅ |
| Diverse Evidence from the Open Web | ✅ | ✅ |
| Automated Correction of Misinformation | ✅ | ✅ |
| Privacy and Data Security | ✅ | ✅ |
| Multimodal Input | ✅ | ✅ |
| One-Stop Custom Solution | ❌ | ✅ |
| Customizable Verification Data Sources | ❌ | ✅ |
| Enhanced User Experience | ❌ | ✅ |
| Faster Efficiency and Higher Accuracy | ❌ | ✅ |
Welcome and thank you for your interest in the Loki project! We welcome contributions and feedback from the community. To get started, please refer to our Contribution Guidelines.
- Special thanks to all contributors who have helped in shaping this project.
Don’t miss out on the latest updates, feature releases, and community insights! We invite you to subscribe to our newsletter and become a part of our growing community.
💌 Subscribe now at our website!
@misc{Loki,
author = {Wang, Hao and Wang, Yuxia and Wang, Minghan and Geng, Yilin and Zhao, Zhen and Zhai, Zenan and Nakov, Preslav and Baldwin, Timothy and Han, Xudong and Li, Haonan},
title = {Loki: An Open-source Tool for Fact Verification},
month = {04},
year = {2024},
publisher = {Zenodo},
version = {v0.0.2},
doi = {10.5281/zenodo.11004461},
url = {https://zenodo.org/records/11004461}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for OpenFactVerification
Similar Open Source Tools
OpenFactVerification
Loki is an open-source tool designed to automate the process of verifying the factuality of information. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information.
LaVague
LaVague is an open-source Large Action Model framework that uses advanced AI techniques to compile natural language instructions into browser automation code. It leverages Selenium or Playwright for browser actions. Users can interact with LaVague through an interactive Gradio interface to automate web interactions. The tool requires an OpenAI API key for default examples and offers a Playwright integration guide. Contributors can help by working on outlined tasks, submitting PRs, and engaging with the community on Discord. The project roadmap is available to track progress, but users should exercise caution when executing LLM-generated code using 'exec'.
Whatsapp-Ai-BOT
This WhatsApp AI chatbot is built using NodeJS technology and powered by OpenAI. It leverages the advanced deep learning models of ChatGPT, Playground, and DALL·E from OpenAI to provide a unique text-based and image-based conversational experience for users. The bot has two main features: ChatGPT (text) and DALL-E (Text To Image). To use these features, simply use the commands /ai, /img, and /sc respectively. The bot's code is encrypted to protect it from prying eyes, but the key to unlock the full potential of this amazing creation can be obtained by contacting the developer. The bot is free to use, but a PRIME version is available with additional features such as history mode, prime support, and customizable options.
embedchain
Embedchain is an Open Source Framework for personalizing LLM responses. It simplifies the creation and deployment of personalized AI applications by efficiently managing unstructured data, generating relevant embeddings, and storing them in a vector database. With diverse APIs, users can extract contextual information, find precise answers, and engage in interactive chat conversations tailored to their data. The framework follows the design principle of being 'Conventional but Configurable' to cater to both software engineers and machine learning engineers.
ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.
raycast-g4f
Raycast-G4F is a free extension that allows users to leverage powerful AI models such as GPT-4 and Llama-3 within the Raycast app without the need for an API key. The extension offers features like streaming support, diverse commands, chat interaction with AI, web search capabilities, file upload functionality, image generation, and custom AI commands. Users can easily install the extension from the source code and benefit from frequent updates and a user-friendly interface. Raycast-G4F supports various providers and models, each with different capabilities and performance ratings, ensuring a versatile AI experience for users.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.

Follow
Follow is a content organization tool that creates a noise-free timeline for users, allowing them to share lists, explore collections, and browse distraction-free. It offers features like subscribing to feeds, AI-powered browsing, dynamic content support, an ownership economy with $POWER tipping, and a community-driven experience. Follow is under active development and welcomes feedback from users and developers. It can be accessed via web app or desktop client and offers installation methods for different operating systems. The tool aims to provide a customized information hub, AI-powered browsing experience, and support for various types of content, while fostering a community-driven and open-source environment.
SolidGPT
SolidGPT is an AI searching assistant for developers that helps with code and workspace semantic search. It provides features such as talking to your codebase, asking questions about your codebase, semantic search and summary in Notion, and getting questions answered from your codebase and Notion without context switching. The tool ensures data safety by not collecting users' data and uses the OpenAI series model API.

AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.
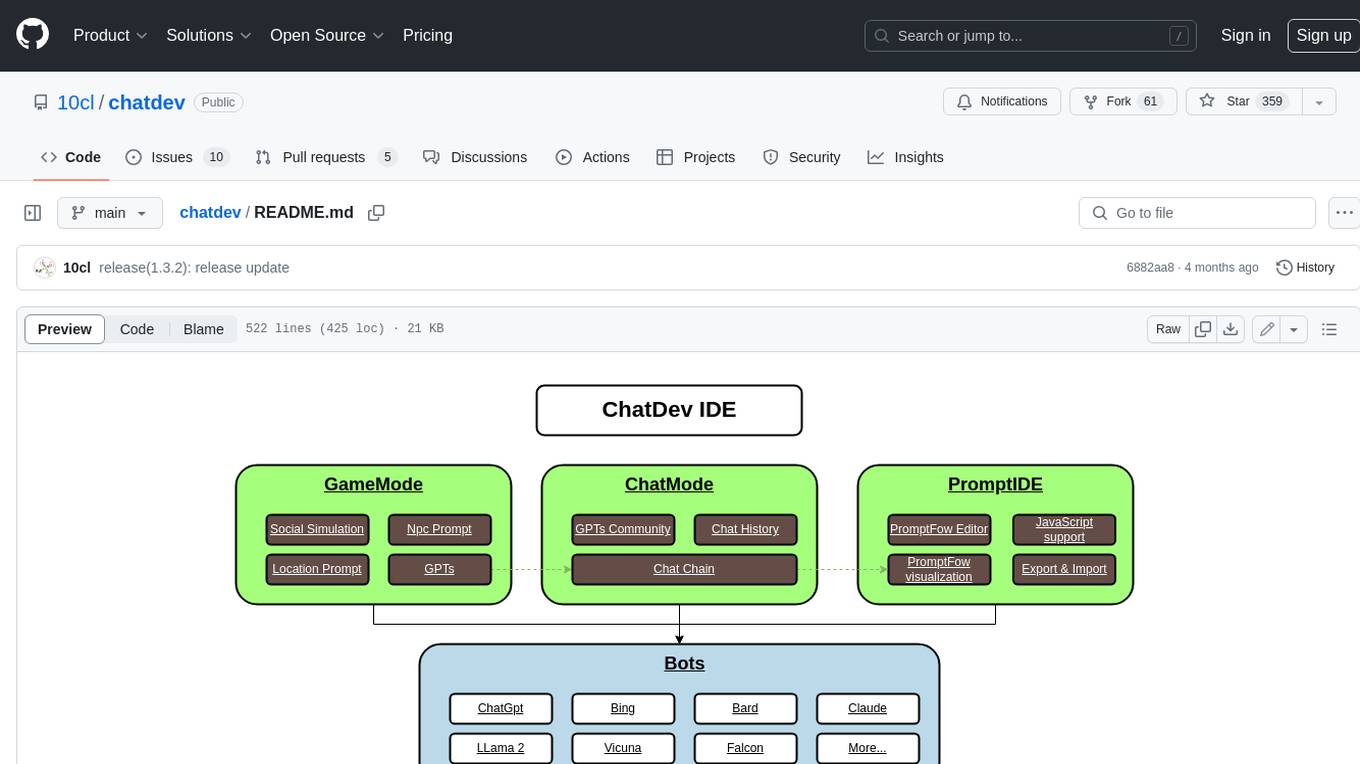
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.
OpenHands
OpenDevin is a platform for autonomous software engineers powered by AI and LLMs. It allows human developers to collaborate with agents to write code, fix bugs, and ship features. The tool operates in a secured docker sandbox and provides access to different LLM providers for advanced configuration options. Users can contribute to the project through code contributions, research and evaluation of LLMs in software engineering, and providing feedback and testing. OpenDevin is community-driven and welcomes contributions from developers, researchers, and enthusiasts looking to advance software engineering with AI.
Second-Me
Second Me is an open-source prototype that allows users to craft their own AI self, preserving their identity, context, and interests. It is locally trained and hosted, yet globally connected, scaling intelligence across an AI network. It serves as an AI identity interface, fostering collaboration among AI selves and enabling the development of native AI apps. The tool prioritizes individuality and privacy, ensuring that user information and intelligence remain local and completely private.
tribe
Tribe AI is a low code tool designed to rapidly build and coordinate multi-agent teams. It leverages the langgraph framework to customize and coordinate teams of agents, allowing tasks to be split among agents with different strengths for faster and better problem-solving. The tool supports persistent conversations, observability, tool calling, human-in-the-loop functionality, easy deployment with Docker, and multi-tenancy for managing multiple users and teams.
linkedin-api
The Linkedin API for Python allows users to programmatically search profiles, send messages, and find jobs using a regular Linkedin user account. It does not require 'official' API access, just a valid Linkedin account. However, it is important to note that this library is not officially supported by LinkedIn and using it may violate LinkedIn's Terms of Service. Users can authenticate using any Linkedin account credentials and access features like getting profiles, profile contact info, and connections. The library also provides commercial alternatives for extracting data, scraping public profiles, and accessing a full LinkedIn API. It is not endorsed or supported by LinkedIn and is intended for educational purposes and personal use only.
For similar tasks

phospho
Phospho is a text analytics platform for LLM apps. It helps you detect issues and extract insights from text messages of your users or your app. You can gather user feedback, measure success, and iterate on your app to create the best conversational experience for your users.
OpenFactVerification
Loki is an open-source tool designed to automate the process of verifying the factuality of information. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

lima
LIMA is a multilingual linguistic analyzer developed by the CEA LIST, LASTI laboratory. It is Free Software available under the MIT license. LIMA has state-of-the-art performance for more than 60 languages using deep learning modules. It also includes a powerful rules-based mechanism called ModEx for extracting information in new domains without annotated data.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.
For similar jobs
OpenFactVerification
Loki is an open-source tool designed to automate the process of verifying the factuality of information. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information.
obs-cleanstream
CleanStream is an OBS plugin that utilizes AI to clean live audio streams by removing unwanted words and utterances, such as 'uh's and 'um's, and configurable words like profanity. It uses a neural network (OpenAI Whisper) in real-time to predict speech and eliminate unwanted words. The plugin is still experimental and not recommended for live production use, but it is functional for testing purposes. Users can adjust settings and configure the plugin to enhance audio quality during live streams.
uBlockOrigin-HUGE-AI-Blocklist
A huge blocklist of sites containing AI generated content (~950 sites) for cleaning image search engines with uBlock Origin or uBlacklist. Includes hosts file for pi-hole/adguard. Provides instructions for importing blocklists and additional lists for specific content. Allows users to create allowlists and customize filtering based on keywords. Offers tips and tricks for advanced filtering and comparison between uBlock Origin and uBlacklist implementations.
detoxify
Detoxify is a library that provides trained models and code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification. It includes models like 'original', 'unbiased', and 'multilingual' trained on different datasets to detect toxicity and minimize bias. The library aims to help in stopping harmful content online by interpreting visual content in context. Users can fine-tune the models on carefully constructed datasets for research purposes or to aid content moderators in flagging out harmful content quicker. The library is built to be user-friendly and straightforward to use.

obs-cleanstream
CleanStream is an OBS plugin that utilizes real-time local AI to clean live audio streams by removing unwanted words and utterances, such as 'uh' and 'um', and configurable words like profanity. It employs a neural network (OpenAI Whisper) to predict speech in real-time and eliminate undesired words. The plugin runs efficiently using the Whisper.cpp project from ggerganov. CleanStream offers users the ability to adjust settings and add the plugin to any audio-generating source in OBS, providing a seamless experience for content creators looking to enhance the quality of their live audio streams.
samurai
Samurai Telegram Bot is a simple yet effective moderator bot for Telegram. It provides features such as reporting functionality, profanity filtering in English and Russian, logging system via private channel, spam detection AI, and easy extensibility of bot code and functions. Please note that the code is not polished and is provided 'as is', with room for improvements.
iffy
Iffy is a tool for intelligent content moderation at scale, allowing users to keep unwanted content off their platform without the need to manage a team of moderators. It provides features such as a Moderation Dashboard to view and manage all moderation activity, User Lifecycle to automatically suspend users with flagged content, Appeals Management for efficient handling of user appeals, and Powerful Rules & Presets to create custom moderation rules. Users can choose between the managed Iffy Cloud or the free self-hosted Iffy Community version, each offering different features and setup requirements.
cringe-guard
Cringe-guard is a Chrome extension that filters out cringe content from your LinkedIn feed using AI analysis. It detects new posts, sends them for analysis based on predefined 'cringe' criteria, and blurs identified cringe posts. Users can customize post types to see or hide. The tool aims to empower users to have more control over the content they consume.