
swt-bench
[NeurIPS 2024] Evaluation harness for SWT-Bench, a benchmark for evaluating LLM repository-level test-generation
Stars: 56
SWT-Bench is a benchmark tool for evaluating large language models on testing generation for real world software issues collected from GitHub. It tasks a language model with generating a reproducing test that fails in the original state of the code base and passes after a patch resolving the issue has been applied. The tool operates in unit test mode or reproduction script mode to assess model predictions and success rates. Users can run evaluations on SWT-Bench Lite using the evaluation harness with specific commands. The tool provides instructions for setting up and building SWT-Bench, as well as guidelines for contributing to the project. It also offers datasets and evaluation results for public access and provides a citation for referencing the work.
README:

SWT-Bench is a benchmark for evaluating large language models on testing generation for real world software issues collected from GitHub. Given a codebase and an issue, a language model is tasked with generating a reproducing test that fails in the original state of the code base and passes after a patch resolving the issue has been applied.
Check out our Paper for more details: SWT-Bench: Testing and Validating Real-World Bug-Fixes with Code Agents
SWT-Bench uses Docker for reproducible evaluations. Follow the instructions in the Docker setup guide to install Docker on your machine. If you're setting up on Linux, we recommend seeing the post-installation steps as well.
Finally, to build SWT-Bench, follow these steps:
git clone [email protected]:eth-sri/swt-bench.git
cd swt-bench
python -m venv .venv
source .venv/bin/activate
pip install -e .Test your installation by running:
python -m src.main \
--predictions_path gold \
--max_workers 1 \
--instance_ids sympy__sympy-20590 \
--run_id validate-gold[!WARNING] Running fast evaluations on SWT-Bench can be resource intensive We recommend running the evaluation harness on an
x86_64machine with at least 120GB of free storage, 16GB of RAM, and 8 CPU cores. You may need to experiment with the--max_workersargument to find the optimal number of workers for your machine, but we recommend using fewer thanmin(0.75 * os.cpu_count(), 24).If running with docker desktop, make sure to increase your virtual disk space to have ~120 free GB available, and set max_workers to be consistent with the above for the CPUs available to docker.
Support for
arm64machines is experimental.
Evaluate model predictions on SWT-Bench Lite using the evaluation harness with the following command:
python -m src.main \
--dataset_name princeton-nlp/SWE-bench_Lite \
--predictions_path <path_to_predictions> \
--filter_swt \
--max_workers <num_workers> \
--run_id <run_id>
# use --predictions_path 'gold' to verify the gold patches
# use --run_id to name the evaluation run
# use --exec_mode reproduction_script --reproduction_script_name <script_name> to run in reproduction script mode (see below)This command will generate docker build logs (image_build_logs) and evaluation logs (run_instance_swt_logs) in the current directory.
The final evaluation results will be stored in the evaluation_results directory.
By default, SWT-Bench operates in unit test mode, where model predictions are treated as unit tests to be integrated into the existing test suite. The evaluation harness runs the modified parts of the test suite and reports changes to compute the success rate. Successful patches add a pass-to-fail test without causing existing tests to fail.
In the simpler reproduction script mode, model predictions are considered standalone scripts that reproduce issues. The evaluation harness runs the script on the codebase and determines success based on the script's exit code: 0 for pass and 1 for fail. The test suite is not executed in this mode.
To assess the result of a single run, we provide a simple script to assess a single evaluation run. Pass it the path to your evaluation, including run_id and model to get a simple tabellaric overview. For example, to reproduce the results for SWE-Agent from Table 2 and 3 of the paper, run the following command:
python -m src.report run_instance_swt_logs/swea__gpt-4-1106-preview/gpt4__SWE-bench_Lite__default_test_demo3__t-0.00__p-0.95__c-3.00__install-1 --dataset lite
# |------------------------------------|--------------------------|
# | Method | swea__gpt-4-1106-preview |
# | Applicability (W) | 87.31884057971014 |
# | Success Rate (S) | 15.942028985507246 |
# | F->X | 48.18840579710145 |
# | F->P | 16.666666666666668 |
# | P->P | 9.782608695652174 |
# | Coverage Delta (Δᵃˡˡ) | 26.488815129800212 |
# | Coverage Delta Resolved (Δᔆ) | 64.69774543638181 |
# | Coverage Delta Unresolved (Δⁿᵒᵗ ᔆ) | 19.14736127176707 |In order to see a coverage delta reported, you need to have the gold evaluation included in the same evaluation path, i.e. download the golden results into run_instance_swt_logs from the downloads section below.
We list top performing methods for SWT-Bench Lite and Verified on our leaderboard. If you want to have your results included, please send us an email to [email protected] containing
- The name of your method
- The inference results from your method as the JSONL used to run the evaluation. The JSONL should contain a prediction for each instance in SWT-Bench Lite or Verified per line, each with the following fields
-
instance_idThe name of the instance in SWT-Bench Lite or Verified -
model_name_or_pathThe name of your model/approach -
model_patchThe git patch to apply to the repository -
full_output(optional) The complete output of your model for the given task
-
- Your locally determined performance
- A link to your projects homepage and traces of your method (to verify that the predictions are legitimate)
- A description on how to reproduce your runs if you want to have your results independently verified through us
We will independently run your predictions in our dockerized environment to verify your score, contact you to confirm your results and to coordinate the publication. To ensure the accessibility of traces, we reserve the right to host your predictions on a server of ours.
The inclusion in the leaderboard will be performed on a best effort basis, but we can not guarantee inclusion or timely processing of your requests.
The SWT-Bench, SWT-Bench-Lite and SWT-Bench Verified datasets are published publicly accessible on huggingface and can be accessed using the following links. They already contain the 27k token capped context retrieved via BM25 in the prompt.
| Prompt Format | SWT-Bench | SWT-Bench Lite | SWT-Bench Verified |
|---|---|---|---|
| ZeroShotBase | Download | Download | Download |
| ZeroShotPlus | Download | Download | Download |
We provide the full traces of run code agents, the predicted patches by each method and setting and the logs of the evaluation harness.
| Artifact | Single Files | ZIP |
|---|---|---|
| Agent Traces | Download | Download |
| Predicted Patches | Download | Download (Lite) Download (Verified) |
| Evaluation Harness Logs | Download | Download (Lite) Download (Verified) |
The full list of resolved instances per approach can be found here.
For our evaluation of OpenHands, we automatically discard all top-level files to remove stale reproduction scripts generated by the agent.
Moreover, for the evaluation of the agent in the correct environment, we discard changes to setup.py, pyproject.toml and requirements.txt files, as they are changed by the test setup and conflict with the repeated evaluation.
To find the exact setup used for OpenHands, check out the branch feat/CI.
AEGIS was evaluated in reproduction script mode.
For reference, the results of our gold validation runs are below (Applicability, Success Rate, F->X and F->P rate are 100% each).
| Metric | Lite | Verified | Full |
|---|---|---|---|
| # Instances | 276 | 433 | 2294 |
| P->P (Gold) | 10.86 | 15.01 | 17.65 |
| Coverage Delta (Δᵃˡˡ) (Gold) | 71.84 | 69.12 | 65.13 |
To recreate the SWT-Bench dataset or create one with your own flavoring
and to run the zero-shot approaches from the paper on this dataset, follow these steps.
In order to avoid duplication, we re-use some of the SWE-Bench tooling.
First, create an SWE-Bench style dataset, i.e. by using the SWE-Bench dataset collection scripts.
If you want to add BM-25 retrieved documents, you can use the SWE-Bench BM-25 retrieval script bm25_retrieval.py - make sure to set include_tests to True to ensure that test files are included in the results.
Finally, run dataset/swt_bench.py to convert the SWE-Bench style dataset into an SWT-Bench dataset.
For example, with your SWE-Bench dataset in datasets/swe_bench, run the following commands.
python3 dataset/swt_bench.py --dataset_path datasets/swe_bench --output_path dataset/swt_bench_zsb --mode base
python3 dataset/swt_bench.py --dataset_path datasets/swe_bench --output_path dataset/swt_bench_zsp --mode plusThese commands will create the datasets for the approaches Zero-Shot Base and Zero-Shot Plus from the paper. You can then use the SWE-Bench inference tooling to generate the model inference files.
We would love to hear from the broader NLP, Machine Learning, and Software Engineering research communities, and we welcome any contributions, pull requests, or issues! To do so, please either file a new pull request or issue. We'll be sure to follow up shortly!
Contact person: Niels Mündler and Mark Niklas Müller (Email: {niels.muendler, mark.mueller}@inf.ethz.ch).
This repo is based on the SWE-Bench evaluation harness and we want to thank all their contributors.
If you find our work helpful, please use the following citations.
@inproceedings{
mundler2024swtbench,
title={{SWT}-Bench: Testing and Validating Real-World Bug-Fixes with Code Agents},
author={Niels M{\"u}ndler and Mark Niklas Mueller and Jingxuan He and Martin Vechev},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=9Y8zUO11EQ}
}Please also consider citing SWE-bench which inspired our work and forms the basis of this code-base.
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}MIT. Check LICENSE.md.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for swt-bench
Similar Open Source Tools
swt-bench
SWT-Bench is a benchmark tool for evaluating large language models on testing generation for real world software issues collected from GitHub. It tasks a language model with generating a reproducing test that fails in the original state of the code base and passes after a patch resolving the issue has been applied. The tool operates in unit test mode or reproduction script mode to assess model predictions and success rates. Users can run evaluations on SWT-Bench Lite using the evaluation harness with specific commands. The tool provides instructions for setting up and building SWT-Bench, as well as guidelines for contributing to the project. It also offers datasets and evaluation results for public access and provides a citation for referencing the work.

AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.
PostTrainBench
PostTrainBench is a benchmark designed to measure the ability of command-line interface (CLI) agents to post-train pre-trained large language models (LLMs). The agents are tasked with improving the performance of a base LLM on a given benchmark using an evaluation script and 10 hours on an H100 GPU. The benchmark scores are computed after post-training, and the setup evaluates an agent's capability to conduct AI research and development. The repository provides a platform for collaborative contributions to expand tasks and agent scaffolds, with the potential for co-authorship on research papers.

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.

weblinx
WebLINX is a Python library and dataset for real-world website navigation with multi-turn dialogue. The repository provides code for training models reported in the WebLINX paper, along with a comprehensive API to work with the dataset. It includes modules for data processing, model evaluation, and utility functions. The modeling directory contains code for processing, training, and evaluating models such as DMR, LLaMA, MindAct, Pix2Act, and Flan-T5. Users can install specific dependencies for HTML processing, video processing, model evaluation, and library development. The evaluation module provides metrics and functions for evaluating models, with ongoing work to improve documentation and functionality.

NineRec
NineRec is a benchmark dataset suite for evaluating transferable recommendation models. It provides datasets for pre-training and transfer learning in recommender systems, focusing on multimodal and foundation model tasks. The dataset includes user-item interactions, item texts in multiple languages, item URLs, and raw images. Researchers can use NineRec to develop more effective and efficient methods for pre-training recommendation models beyond end-to-end training. The dataset is accompanied by code for dataset preparation, training, and testing in PyTorch environment.
uptrain
UpTrain is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured evaluations (covering language, code, embedding use cases), perform root cause analysis on failure cases and give insights on how to resolve them.

maxtext
MaxText is a high-performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler. MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.

llm-foundry
LLM Foundry is a codebase for training, finetuning, evaluating, and deploying LLMs for inference with Composer and the MosaicML platform. It is designed to be easy-to-use, efficient _and_ flexible, enabling rapid experimentation with the latest techniques. You'll find in this repo: * `llmfoundry/` - source code for models, datasets, callbacks, utilities, etc. * `scripts/` - scripts to run LLM workloads * `data_prep/` - convert text data from original sources to StreamingDataset format * `train/` - train or finetune HuggingFace and MPT models from 125M - 70B parameters * `train/benchmarking` - profile training throughput and MFU * `inference/` - convert models to HuggingFace or ONNX format, and generate responses * `inference/benchmarking` - profile inference latency and throughput * `eval/` - evaluate LLMs on academic (or custom) in-context-learning tasks * `mcli/` - launch any of these workloads using MCLI and the MosaicML platform * `TUTORIAL.md` - a deeper dive into the repo, example workflows, and FAQs
pint-benchmark
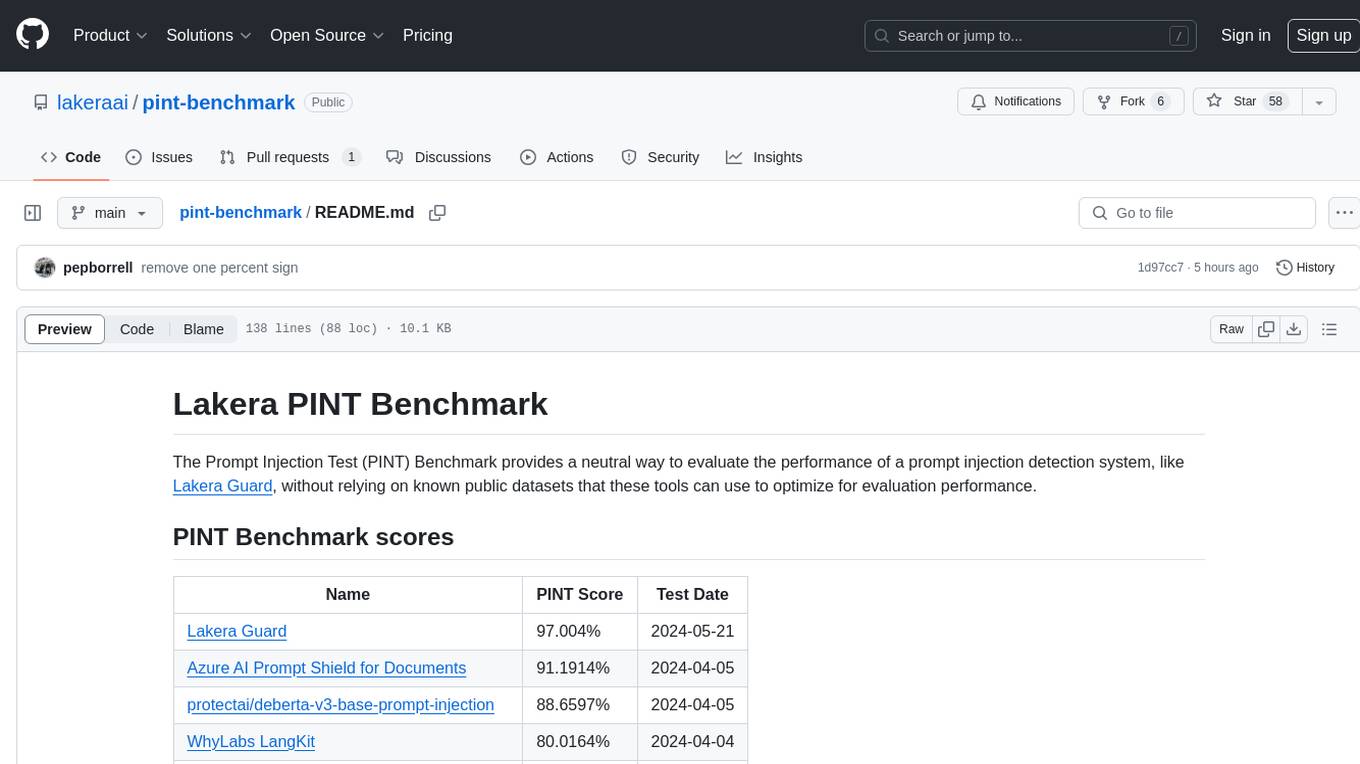
The Lakera PINT Benchmark provides a neutral evaluation method for prompt injection detection systems, offering a dataset of English inputs with prompt injections, jailbreaks, benign inputs, user-agent chats, and public document excerpts. The dataset is designed to be challenging and representative, with plans for future enhancements. The benchmark aims to be unbiased and accurate, welcoming contributions to improve prompt injection detection. Users can evaluate prompt injection detection systems using the provided Jupyter Notebook. The dataset structure is specified in YAML format, allowing users to prepare their datasets for benchmarking. Evaluation examples and resources are provided to assist users in evaluating prompt injection detection models and tools.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

hi-ml
The Microsoft Health Intelligence Machine Learning Toolbox is a repository that provides low-level and high-level building blocks for Machine Learning / AI researchers and practitioners. It simplifies and streamlines work on deep learning models for healthcare and life sciences by offering tested components such as data loaders, pre-processing tools, deep learning models, and cloud integration utilities. The repository includes two Python packages, 'hi-ml-azure' for helper functions in AzureML, 'hi-ml' for ML components, and 'hi-ml-cpath' for models and workflows related to histopathology images.
magika
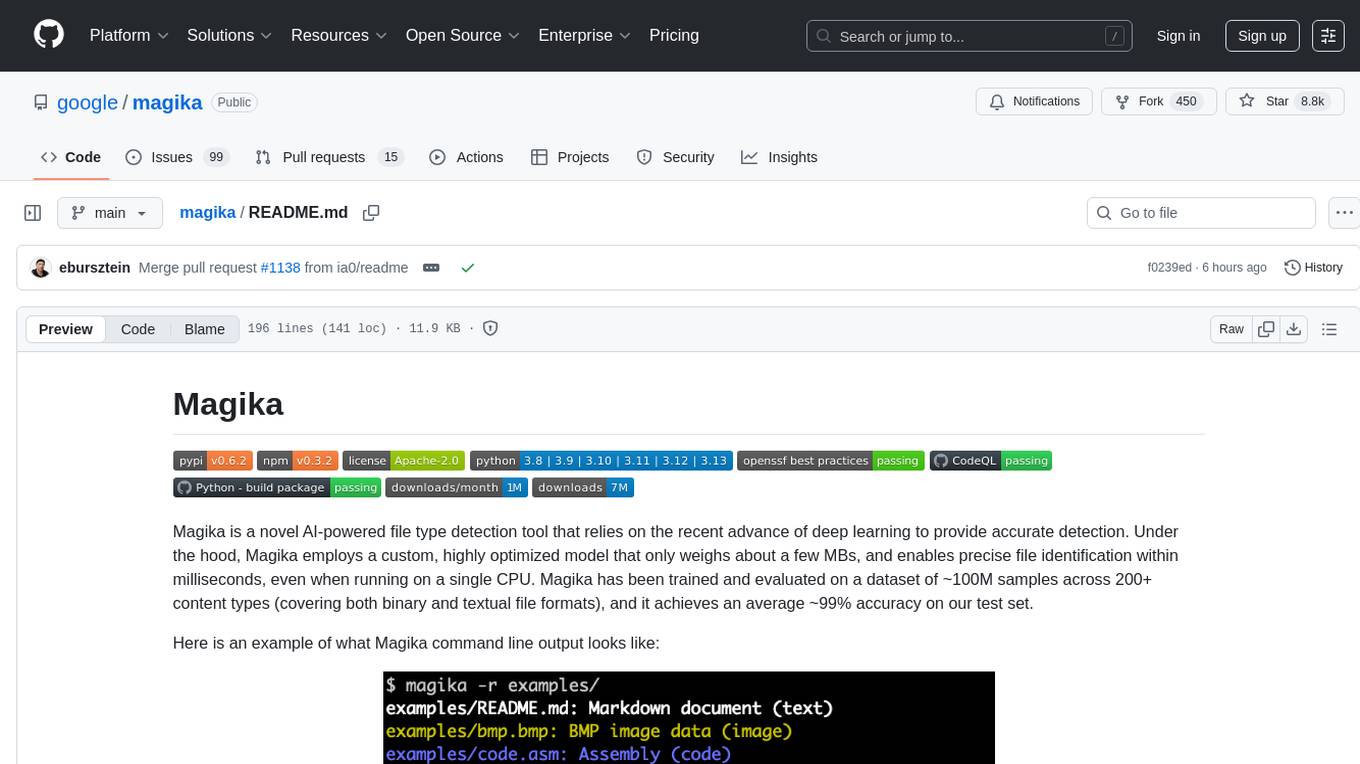
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.

OneKE
OneKE is a flexible dockerized system for schema-guided knowledge extraction, capable of extracting information from the web and raw PDF books across multiple domains like science and news. It employs a collaborative multi-agent approach and includes a user-customizable knowledge base to enable tailored extraction. OneKE offers various IE tasks support, data sources support, LLMs support, extraction method support, and knowledge base configuration. Users can start with examples using YAML, Python, or Web UI, and perform tasks like Named Entity Recognition, Relation Extraction, Event Extraction, Triple Extraction, and Open Domain IE. The tool supports different source formats like Plain Text, HTML, PDF, Word, TXT, and JSON files. Users can choose from various extraction models like OpenAI, DeepSeek, LLaMA, Qwen, ChatGLM, MiniCPM, and OneKE for information extraction tasks. Extraction methods include Schema Agent, Extraction Agent, and Reflection Agent. The tool also provides support for schema repository and case repository management, along with solutions for network issues. Contributors to the project include Ningyu Zhang, Haofen Wang, Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, and Huajun Chen.

pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.
For similar tasks

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

rclip
rclip is a command-line photo search tool powered by the OpenAI's CLIP neural network. It allows users to search for images using text queries, similar image search, and combining multiple queries. The tool extracts features from photos to enable searching and indexing, with options for previewing results in supported terminals or custom viewers. Users can install rclip on Linux, macOS, and Windows using different installation methods. The repository follows the Conventional Commits standard and welcomes contributions from the community.

honcho
Honcho is a platform for creating personalized AI agents and LLM powered applications for end users. The repository is a monorepo containing the server/API for managing database interactions and storing application state, along with a Python SDK. It utilizes FastAPI for user context management and Poetry for dependency management. The API can be run using Docker or manually by setting environment variables. The client SDK can be installed using pip or Poetry. The project is open source and welcomes contributions, following a fork and PR workflow. Honcho is licensed under the AGPL-3.0 License.
core
OpenSumi is a framework designed to help users quickly build AI Native IDE products. It provides a set of tools and templates for creating Cloud IDEs, Desktop IDEs based on Electron, CodeBlitz web IDE Framework, Lite Web IDE on the Browser, and Mini-App liked IDE. The framework also offers documentation for users to refer to and a detailed guide on contributing to the project. OpenSumi encourages contributions from the community and provides a platform for users to report bugs, contribute code, or improve documentation. The project is licensed under the MIT license and contains third-party code under other open source licenses.
yolo-ios-app
The Ultralytics YOLO iOS App GitHub repository offers an advanced object detection tool leveraging YOLOv8 models for iOS devices. Users can transform their devices into intelligent detection tools to explore the world in a new and exciting way. The app provides real-time detection capabilities with multiple AI models to choose from, ranging from 'nano' to 'x-large'. Contributors are welcome to participate in this open-source project, and licensing options include AGPL-3.0 for open-source use and an Enterprise License for commercial integration. Users can easily set up the app by following the provided steps, including cloning the repository, adding YOLOv8 models, and running the app on their iOS devices.
PyAirbyte
PyAirbyte brings the power of Airbyte to every Python developer by providing a set of utilities to use Airbyte connectors in Python. It enables users to easily manage secrets, work with various connectors like GitHub, Shopify, and Postgres, and contribute to the project. PyAirbyte is not a replacement for Airbyte but complements it, supporting data orchestration frameworks like Airflow and Snowpark. Users can develop ETL pipelines and import connectors from local directories. The tool simplifies data integration tasks for Python developers.
md-agent
MD-Agent is a LLM-agent based toolset for Molecular Dynamics. It uses Langchain and a collection of tools to set up and execute molecular dynamics simulations, particularly in OpenMM. The tool assists in environment setup, installation, and usage by providing detailed steps. It also requires API keys for certain functionalities, such as OpenAI and paper-qa for literature searches. Contributions to the project are welcome, with a detailed Contributor's Guide available for interested individuals.
flowgen
FlowGen is a tool built for AutoGen, a great agent framework from Microsoft and a lot of contributors. It provides intuitive visual tools that streamline the construction and oversight of complex agent-based workflows, simplifying the process for creators and developers. Users can create Autoflows, chat with agents, and share flow templates. The tool is fully dockerized and supports deployment on Railway.app. Contributions to the project are welcome, and the platform uses semantic-release for versioning and releases.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.