
stable-diffusion-webui-Layer-Divider
Layer-Divider, an extension for stable-diffusion-webui using the segment-anything model (SAM)
Stars: 163
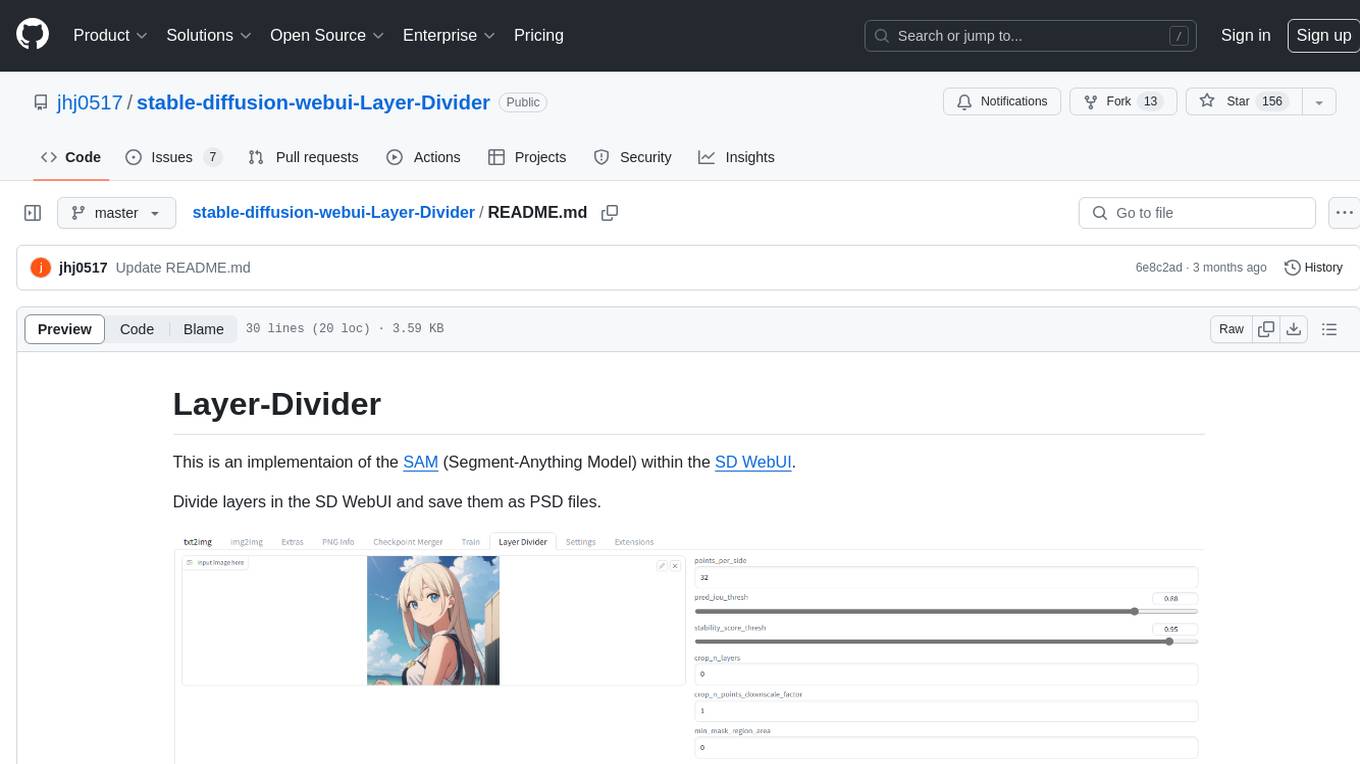
This repository contains an implementation of the Segment-Anything Model (SAM) within the SD WebUI. It allows users to divide layers in the SD WebUI and save them as PSD files. Users can adjust parameters, click 'Generate', and view the output below. A PSD file will be saved in the designated folder. The tool provides various parameters for customization, such as points_per_side, pred_iou_thresh, stability_score_thresh, crops_n_layers, crop_n_points_downscale_factor, and min_mask_region_area.
README:
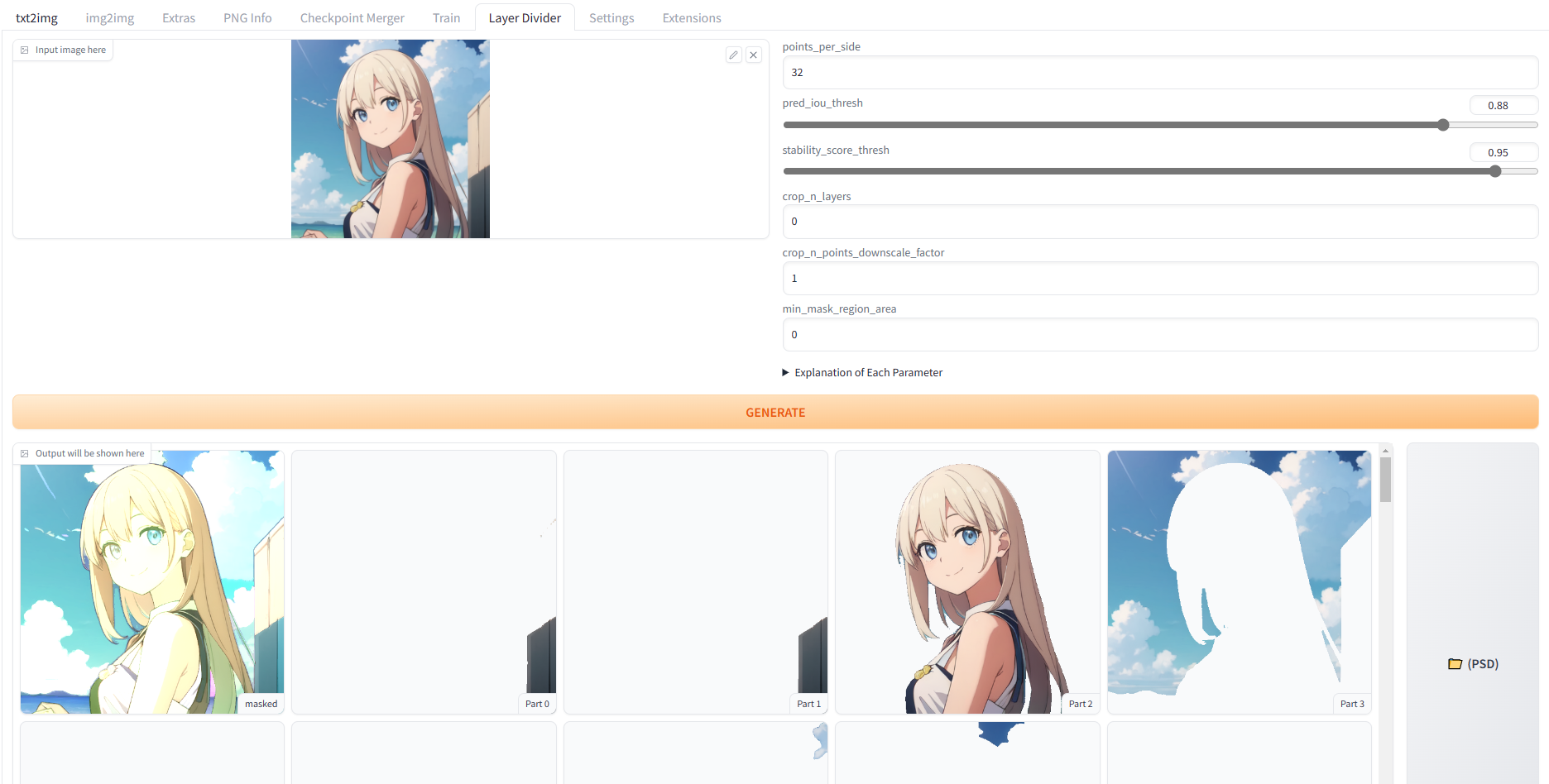
This is an implementaion of the SAM (Segment-Anything Model) within the SD WebUI.
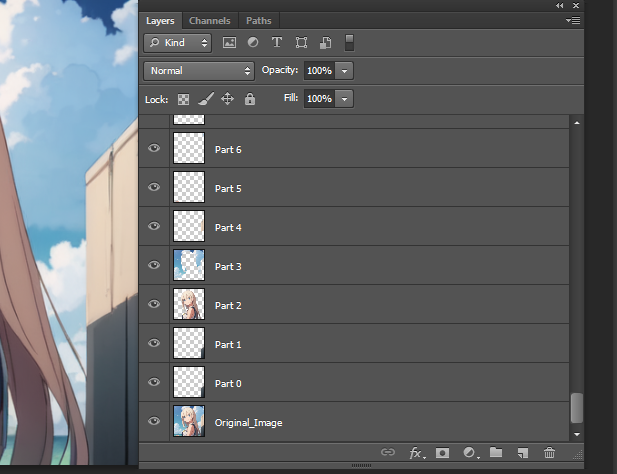
Divide layers in the SD WebUI and save them as PSD files.
If you want a dedicated WebUI specifically for this, rather than as an extension, please visit this repository
git clone https://github.com/jhj0517/stable-diffusion-webui-Layer-Divider.git to your stable-diffusion-webui extensions folder.
or alternatively, download and unzip the repository in your extensions folder!
Some packages are problematic to install programmatically when starting webui.
So you need to manually activate venv and install these packages before running webui.
- Open the terminal in the WebUI and activate the venv
C:\YourPath\To_SD_WebUI>venv\Scripts\activate
Then it will display (venv) in front of the terminal like this.
(venv) C:\YourPath\To_SD_WebUI>
- In this state, run
pip uninstall -y pytoshop
pip uninstall -y packbits
pip install git+https://github.com/jhj0517/forked-pytoshop.git
pip install packbits
Adjust the parameters and click "Generate". The output will be displayed below, and a PSD file will be saved in the extensions\stable-diffusion-webui-layer-divider\layer_divider_outputs\psd folder.
| Parameter | Description |
|---|---|
| points_per_side | The number of points to be sampled along one side of the image. The total number of points is points_per_side**2. If None, 'point_grids' must provide explicit point sampling. |
| pred_iou_thresh | A filtering threshold in [0,1], using the model's predicted mask quality. |
| stability_score_thresh | A filtering threshold in [0,1], using the stability of the mask under changes to the cutoff used to binarize the model's mask predictions. |
| crops_n_layers | If >0, mask prediction will be run again on crops of the image. Sets the number of layers to run, where each layer has 2**i_layer number of image crops. |
| crop_n_points_downscale_factor | The number of points-per-side sampled in layer n is scaled down by crop_n_points_downscale_factor**n. |
| min_mask_region_area | If >0, postprocessing will be applied to remove disconnected regions and holes in masks with area smaller than min_mask_region_area. Requires opencv. |
- [ ] Migrate to SAM-2
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for stable-diffusion-webui-Layer-Divider
Similar Open Source Tools
stable-diffusion-webui-Layer-Divider
This repository contains an implementation of the Segment-Anything Model (SAM) within the SD WebUI. It allows users to divide layers in the SD WebUI and save them as PSD files. Users can adjust parameters, click 'Generate', and view the output below. A PSD file will be saved in the designated folder. The tool provides various parameters for customization, such as points_per_side, pred_iou_thresh, stability_score_thresh, crops_n_layers, crop_n_points_downscale_factor, and min_mask_region_area.

PanelCleaner
Panel Cleaner is a tool that uses machine learning to find text in images and generate masks to cover it up with high accuracy. It is designed to clean text bubbles without leaving artifacts, avoiding painting over non-text parts, and inpainting bubbles that can't be masked out. The tool offers various customization options, detailed analytics on the cleaning process, supports batch processing, and can run OCR on pages. It supports CUDA acceleration, multiple themes, and can handle bubbles on any solid grayscale background color. Panel Cleaner is aimed at saving time for cleaners by automating monotonous work and providing precise cleaning of text bubbles.
stable-diffusion-webui
Stable Diffusion web UI is a web interface for Stable Diffusion, implemented using Gradio library. It provides a user-friendly interface to access the powerful image generation capabilities of Stable Diffusion. With Stable Diffusion web UI, users can easily generate images from text prompts, edit and refine images using inpainting and outpainting, and explore different artistic styles and techniques. The web UI also includes a range of advanced features such as textual inversion, hypernetworks, and embeddings, allowing users to customize and fine-tune the image generation process. Whether you're an artist, designer, or simply curious about the possibilities of AI-generated art, Stable Diffusion web UI is a valuable tool that empowers you to create stunning and unique images.

venice
Venice is a derived data storage platform, providing the following characteristics: 1. High throughput asynchronous ingestion from batch and streaming sources (e.g. Hadoop and Samza). 2. Low latency online reads via remote queries or in-process caching. 3. Active-active replication between regions with CRDT-based conflict resolution. 4. Multi-cluster support within each region with operator-driven cluster assignment. 5. Multi-tenancy, horizontal scalability and elasticity within each cluster. The above makes Venice particularly suitable as the stateful component backing a Feature Store, such as Feathr. AI applications feed the output of their ML training jobs into Venice and then query the data for use during online inference workloads.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.
swt-bench
SWT-Bench is a benchmark tool for evaluating large language models on testing generation for real world software issues collected from GitHub. It tasks a language model with generating a reproducing test that fails in the original state of the code base and passes after a patch resolving the issue has been applied. The tool operates in unit test mode or reproduction script mode to assess model predictions and success rates. Users can run evaluations on SWT-Bench Lite using the evaluation harness with specific commands. The tool provides instructions for setting up and building SWT-Bench, as well as guidelines for contributing to the project. It also offers datasets and evaluation results for public access and provides a citation for referencing the work.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

supallm
Supallm is a Python library for super resolution of images using deep learning techniques. It provides pre-trained models for enhancing image quality by increasing resolution. The library is easy to use and allows users to upscale images with high fidelity and detail. Supallm is suitable for tasks such as enhancing image quality, improving visual appearance, and increasing the resolution of low-quality images. It is a valuable tool for researchers, photographers, graphic designers, and anyone looking to enhance image quality using AI technology.
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
ComfyBench
ComfyBench is a comprehensive benchmark tool designed to evaluate agents' ability to design collaborative AI systems in ComfyUI. It provides tasks for agents to learn from documents and create workflows, which are then converted into code for better understanding by LLMs. The tool measures performance based on pass rate and resolve rate, reflecting the correctness of workflow execution and task realization. ComfyAgent, a component of ComfyBench, autonomously designs new workflows by learning from existing ones, interpreting them as collaborative AI systems to complete given tasks.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.
For similar tasks
stable-diffusion-webui-Layer-Divider
This repository contains an implementation of the Segment-Anything Model (SAM) within the SD WebUI. It allows users to divide layers in the SD WebUI and save them as PSD files. Users can adjust parameters, click 'Generate', and view the output below. A PSD file will be saved in the designated folder. The tool provides various parameters for customization, such as points_per_side, pred_iou_thresh, stability_score_thresh, crops_n_layers, crop_n_points_downscale_factor, and min_mask_region_area.
abliteration
Abliteration is a tool that allows users to create abliterated models using transformers quickly and easily. It is not a tool for uncensorship, but rather for making models that will not explicitly refuse users. Users can clone the repository, install dependencies, and make abliterations using the provided commands. The tool supports adjusting parameters for stubborn models and offers various options for customization. Abliteration can be used for creating modified models for specific tasks or topics.
For similar jobs

ap-plugin
AP-PLUGIN is an AI drawing plugin for the Yunzai series robot framework, allowing you to have a convenient AI drawing experience in the input box. It uses the open source Stable Diffusion web UI as the backend, deploys it for free, and generates a variety of images with richer functions.
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.
Adobe-Photoshop-AI-Crack
Adobe Photoshop 2024 is the latest version of the program for processing raster graphics. It supports a variety of graphic formats and allows both the creation and editing of images. It is used for creating photorealistic images, working with color scanned images, retouching, color correction, collaging, graphic transformation, color separation, and more. Adobe Photoshop encompasses all methods of working with bitmap images, utilizes layers, and contours. The program is an undisputed leader among professional graphic editors due to its extensive capabilities, high efficiency, and speed. Adobe Photoshop provides all the necessary tools for correction, editing, preparing images for printing, and high-quality output.
IOPaint
IOPaint is a free and open-source inpainting & outpainting tool powered by SOTA AI model. It supports various AI models to perform erase, inpainting, or outpainting tasks. Users can remove unwanted objects, defects, watermarks, or people from images using erase models. Additionally, diffusion models can replace objects or perform outpainting. The tool also offers plugins for interactive object segmentation, background removal, anime segmentation, super resolution, face restoration, and file management. IOPaint provides a web UI for easy access to the latest AI models and supports batch processing of images through the command line. Developers can contribute to the project by installing front-end dependencies, setting up the backend, and starting the development environment for both front-end and back-end components.
adobe-photoshopCRCK
Adobe PhotoshopCRCK is a tool designed to provide users with the latest version of Adobe Photoshop for free on Windows. It allows users to access advanced photo editing features and functionalities without the need for a paid subscription. The tool is intended for individuals looking to explore professional photo editing capabilities without incurring additional costs. With Adobe PhotoshopCRCK, users can enhance their images, create stunning graphics, and unleash their creativity through a wide range of editing tools and options.
DeepNude-AI-List
DeepNude AI List is a compilation of various NSFW AI tools that are designed for generating nude or suggestive content. The list includes tools like Dreampaint.net, Nudify.me, NoDress.io, Undress Her, and more. These tools utilize artificial intelligence algorithms to manipulate images and create provocative visuals. Users should exercise caution and responsibility when using such tools, as they may raise ethical and privacy concerns.
generative-ai-js
Generative AI JS is a JavaScript library that provides tools for creating generative art and music using artificial intelligence techniques. It allows users to generate unique and creative content by leveraging machine learning models. The library includes functions for generating images, music, and text based on user input and preferences. With Generative AI JS, users can explore the intersection of art and technology, experiment with different creative processes, and create dynamic and interactive content for various applications.
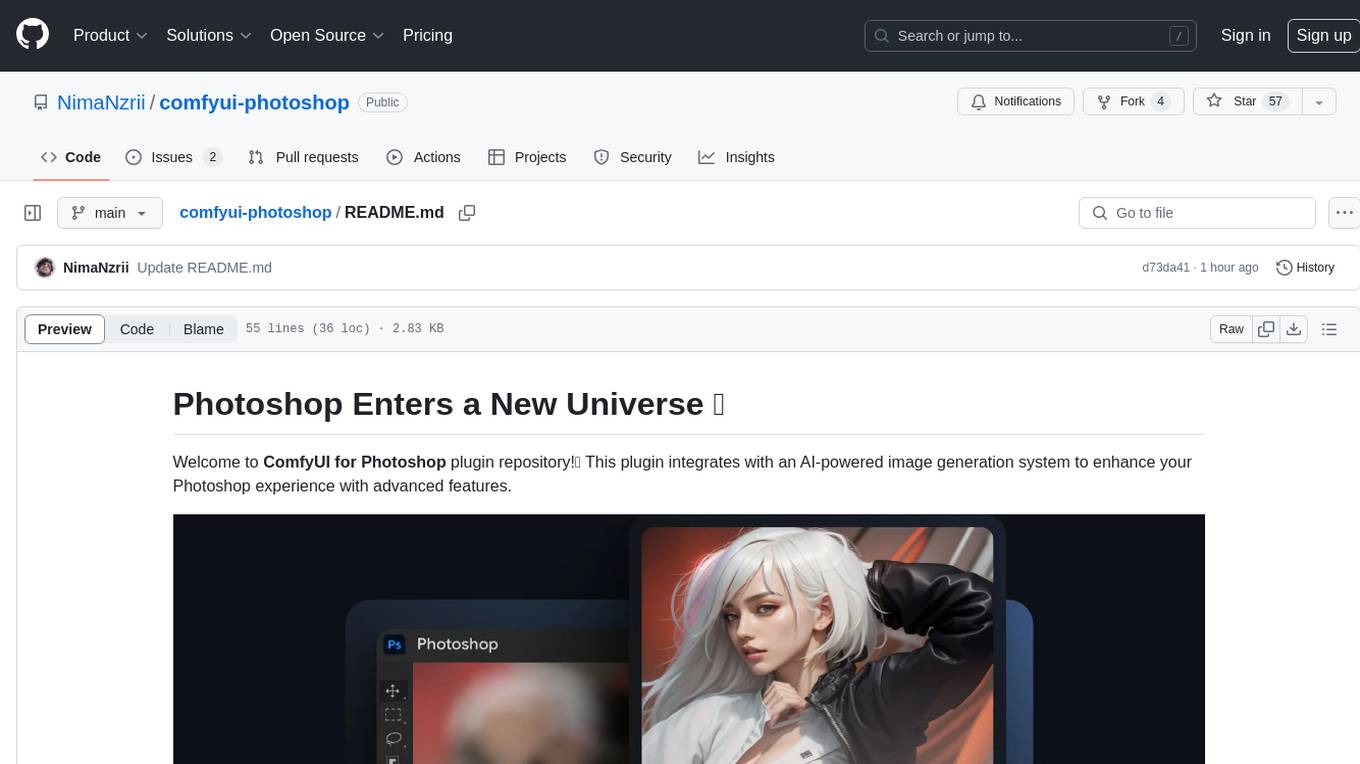
comfyui-photoshop
ComfyUI for Photoshop is a plugin that integrates with an AI-powered image generation system to enhance the Photoshop experience with features like unlimited generative fill, customizable back-end, AI-powered artistry, and one-click transformation. The plugin requires a minimum of 6GB graphics memory and 12GB RAM. Users can install the plugin and set up the ComfyUI workflow using provided links and files. Additionally, specific files like Check points, Loras, and Detailer Lora are required for different functionalities. Support and contributions are encouraged through GitHub.