
abliteration
Make abliterated models with transformers, easy and fast
Stars: 64
Abliteration is a tool that allows users to create abliterated models using transformers quickly and easily. It is not a tool for uncensorship, but rather for making models that will not explicitly refuse users. Users can clone the repository, install dependencies, and make abliterations using the provided commands. The tool supports adjusting parameters for stubborn models and offers various options for customization. Abliteration can be used for creating modified models for specific tasks or topics.
README:
Make abliterated models using transformers, easy and fast.
There exist some directions that make LLMs to refuse users' input. Abliteration is a technique that can calculate the most significant refusal directions with harmful and harmless prompts, and then remove them from the model. This is a crude, proof-of-concept implementation to remove refusals from an LLM model without using TransformerLens.
The code has been tested on Llama-3.2, Qwen2.5-Coder, Ministral-8b.
VRAM/RAM requirements: This repository has been making efforts to reduce VRAM usage. You can abliterate whatever model you want, as long as it fits in your VRAM. Loading model in 4-bit precision using bitsandbytes is recommended for large models if you have limited VRAM. However, I always assume that you have enough memory to load the bf16 model.
[!NOTE] Abliteration is not uncensorment. Though abliterated, it doesn't necessarily mean the model is completely uncensored, it simply will not explicitly refuse you, theoretically.
git clone https://github.com/Orion-zhen/abliteration.git && cd abliterationpip install -r requirements.txtpython abliterate.py -m <path_to_your_model> -o <output_dir>python chat.py -m <path_to_your_abliterated_model>python compare.py -a <model_a> -b <model_b>- Abliterate Llama-3.2:
python abliterate.py -m meta-llama/Llama-3.2-3B-Instruct -o llama3.2-3b-abliterated- Load model in 4-bit precision using bitsandbytes:
python abliterate.py -m meta-llama/Llama-3.2-3B-Instruct -o llama3.2-3b-abliterated --load-in-4bit- Compare your abliterated model with the original model:
python compare.py -a meta-llama/Llama-3.2-3B-Instruct -b llama3.2-3b-abliterated- Compare in 4-bit precision using bitsandbytes:
python compare.py -a meta-llama/Llama-3.2-3B-Instruct -b llama3.2-3b-abliterated --load-in-4bit[!NOTE] If you use
--load-in-4bitor--load-in-8bit, then I will assume you are lack of VRAM, and the final appliance step will be performed with CPU and memory. Please make sure you have enough memory to load the bf16 model.
Now your model will be abliterated and saved to <output_dir>. Once it finishes, you can immediately chat with your abliterated model in the terminal. For Chinese models, you can use --deccp to abliterate it from certain topics.
This repository now supports .json config file. This file should contain a dict of config key value pairs. For example:
{
"model": "/absolute/path/to/your/model",
"output": "/output/dir",
"data-harmful": "/absolute/path/to/harmful-prompts.txt",
"scale-factor": 114,
"load-in-4bit": true
}python abliterate.py -c config.jsonLoading config file will overwrite command line arguments.
You can use your own prompts to abliterate your model. Supported file formats are .txt, .parquet and .json. Detailed formats are listed below:
-
.txt: Each line of the file is a prompt -
.parquet: A parquet file with columntext -
.json: A json file with list of strings
Then load your own prompts using --data-harmful and --data-harmless arguments:
python abliterate.py -m <path_to_your_model> -o <output_dir> --data-harmful /path/to/my/harmful.txt --data-harmless /path/to/my/harmless.txtYou can use --scale-factor to control the abliteration strength. A scale factor larger then 1 will impose stronger removal of refusals, while a negative scale factor will encourage refusal. You can try to increase the scale factor to see if it helps.
python abliterate.py -m <path_to_your_model> -o <output_dir> --scale-factor 1.5You can output the refusals to a file using --output-refusals argument:
python abliterate.py -m <path_to_your_model> -o <output_dir> --output-refusals refusals.binAnd load the refusals back using --load-refusals argument:
python abliterate.py -m <path_to_your_model> --input-refusals refusals.bin -o <output_dir>If --input-refusal is provided, the script will not compute refusal directions again.
By default, abliteration will be applied to o_proj and down_proj. You can add more targets by modifying the code below, as long as it won't mess up the model:
# utils/apply.py, apply_abliteration()
lm_model.layers[layer_idx].self_attn.o_proj.weight = modify_tensor(
lm_model.layers[layer_idx].self_attn.o_proj.weight.data,
refusal_dir,
scale_factor,
)
lm_model.layers[layer_idx].mlp.down_proj.weight = modify_tensor(
lm_model.layers[layer_idx].mlp.down_proj.weight.data,
refusal_dir,
scale_factor,
)Available targets can be found in transformers model architectures and mergekit model architectures.
This repository provides a bunch of parameters to optimize. To get the best results, you can try the following steps:
- Carefully choose your prompts. Prompts in this repository is a general example, you can use your own prompts to get better results.
- Adjust parameters. The script provides various parameters to control the abliteration progress. You can try different values to see if it helps.
- Change the targets. You can modify the code to abliterate other targets, as long as it won't mess up the model.
- If you have limited VRAM, try
--load-in-4bitor--load-in-8bitto load the model in 4-bit or 8-bit precision.
Use --help to see all available arguments:
python abliterate.py --helpFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for abliteration
Similar Open Source Tools
abliteration
Abliteration is a tool that allows users to create abliterated models using transformers quickly and easily. It is not a tool for uncensorship, but rather for making models that will not explicitly refuse users. Users can clone the repository, install dependencies, and make abliterations using the provided commands. The tool supports adjusting parameters for stubborn models and offers various options for customization. Abliteration can be used for creating modified models for specific tasks or topics.

garak
Garak is a free tool that checks if a Large Language Model (LLM) can be made to fail in a way that is undesirable. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Garak's a free tool. We love developing it and are always interested in adding functionality to support applications.

HuggingFaceGuidedTourForMac
HuggingFaceGuidedTourForMac is a guided tour on how to install optimized pytorch and optionally Apple's new MLX, JAX, and TensorFlow on Apple Silicon Macs. The repository provides steps to install homebrew, pytorch with MPS support, MLX, JAX, TensorFlow, and Jupyter lab. It also includes instructions on running large language models using HuggingFace transformers. The repository aims to help users set up their Macs for deep learning experiments with optimized performance.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.

ash_ai
Ash AI is a tool that provides a Model Context Protocol (MCP) server for exposing tool definitions to an MCP client. It allows for the installation of dev and production MCP servers, and supports features like OAuth2 flow with AshAuthentication, tool data access, tool execution callbacks, prompt-backed actions, and vectorization strategies. Users can also generate a chat feature for their Ash & Phoenix application using `ash_oban` and `ash_postgres`, and specify LLM API keys for OpenAI. The tool is designed to help developers experiment with tools and actions, monitor tool execution, and expose actions as tool calls.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.
mlx-lm
MLX LM is a Python package designed for generating text and fine-tuning large language models on Apple silicon using MLX. It offers integration with the Hugging Face Hub for easy access to thousands of LLMs, support for quantizing and uploading models to the Hub, low-rank and full model fine-tuning capabilities, and distributed inference and fine-tuning with `mx.distributed`. Users can interact with the package through command line options or the Python API, enabling tasks such as text generation, chatting with language models, model conversion, streaming generation, and sampling. MLX LM supports various Hugging Face models and provides tools for efficient scaling to long prompts and generations, including a rotating key-value cache and prompt caching. It requires macOS 15.0 or higher for optimal performance.

fabric
Fabric is an open-source framework for augmenting humans using AI. It provides a structured approach to breaking down problems into individual components and applying AI to them one at a time. Fabric includes a collection of pre-defined Patterns (prompts) that can be used for a variety of tasks, such as extracting the most interesting parts of YouTube videos and podcasts, writing essays, summarizing academic papers, creating AI art prompts, and more. Users can also create their own custom Patterns. Fabric is designed to be easy to use, with a command-line interface and a variety of helper apps. It is also extensible, allowing users to integrate it with their own AI applications and infrastructure.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.
ComfyUI-mnemic-nodes
ComfyUI-mnemic-nodes is a repository hosting a collection of nodes developed for ComfyUI, providing useful components to enhance project functionality. The nodes include features like returning file paths, saving text files, downloading images from URLs, tokenizing text, cleaning strings, querying Groq language models, generating negative prompts, and more. Some nodes are experimental and marked with a 'Caution' label. Installation instructions and setup details are provided for each node, along with examples and presets for different tasks.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.

sage
Sage is a tool that allows users to chat with any codebase, providing a chat interface for code understanding and integration. It simplifies the process of learning how a codebase works by offering heavily documented answers sourced directly from the code. Users can set up Sage locally or on the cloud with minimal effort. The tool is designed to be easily customizable, allowing users to swap components of the pipeline and improve the algorithms powering code understanding and generation.
mods
AI for the command line, built for pipelines. LLM based AI is really good at interpreting the output of commands and returning the results in CLI friendly text formats like Markdown. Mods is a simple tool that makes it super easy to use AI on the command line and in your pipelines. Mods works with OpenAI, Groq, Azure OpenAI, and LocalAI To get started, install Mods and check out some of the examples below. Since Mods has built-in Markdown formatting, you may also want to grab Glow to give the output some _pizzazz_.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.
For similar tasks
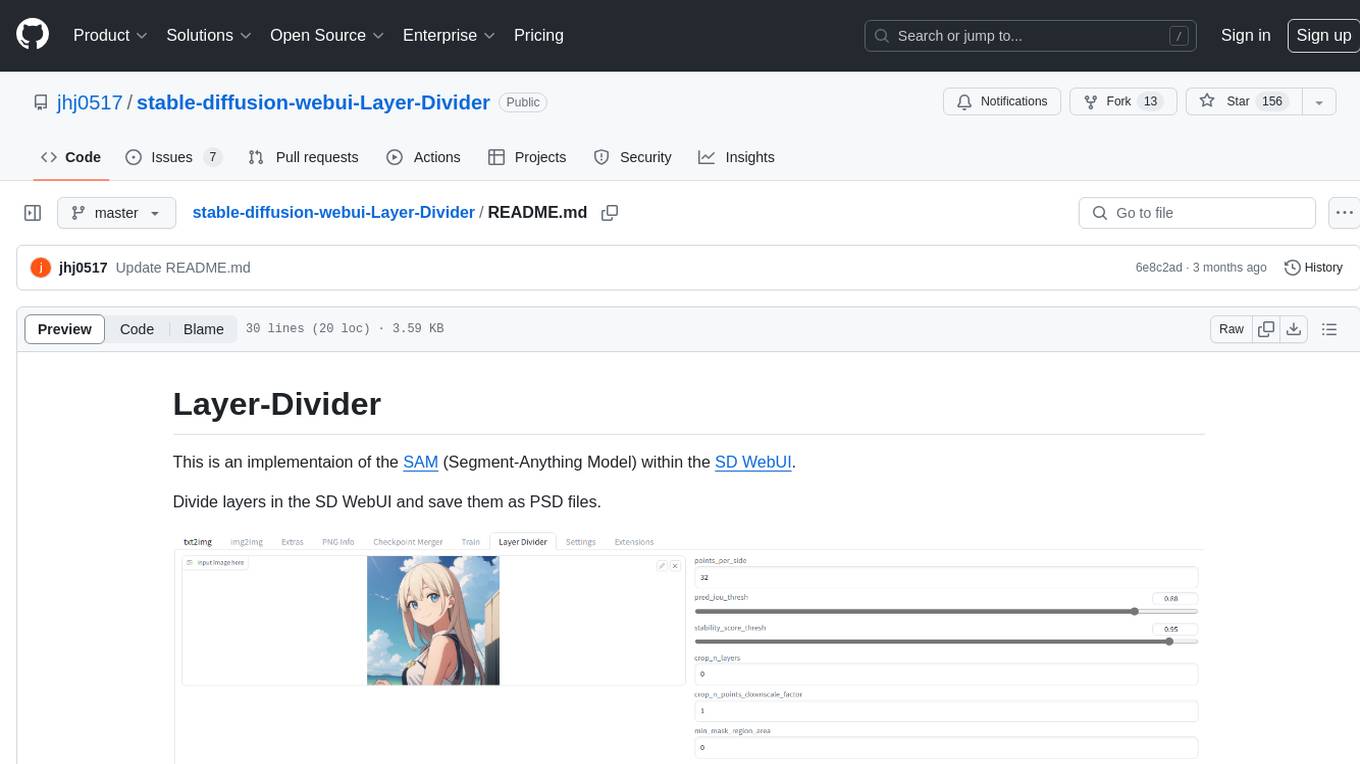
stable-diffusion-webui-Layer-Divider
This repository contains an implementation of the Segment-Anything Model (SAM) within the SD WebUI. It allows users to divide layers in the SD WebUI and save them as PSD files. Users can adjust parameters, click 'Generate', and view the output below. A PSD file will be saved in the designated folder. The tool provides various parameters for customization, such as points_per_side, pred_iou_thresh, stability_score_thresh, crops_n_layers, crop_n_points_downscale_factor, and min_mask_region_area.
abliteration
Abliteration is a tool that allows users to create abliterated models using transformers quickly and easily. It is not a tool for uncensorship, but rather for making models that will not explicitly refuse users. Users can clone the repository, install dependencies, and make abliterations using the provided commands. The tool supports adjusting parameters for stubborn models and offers various options for customization. Abliteration can be used for creating modified models for specific tasks or topics.

cria
Cria is a Python library designed for running Large Language Models with minimal configuration. It provides an easy and concise way to interact with LLMs, offering advanced features such as custom models, streams, message history management, and running multiple models in parallel. Cria simplifies the process of using LLMs by providing a straightforward API that requires only a few lines of code to get started. It also handles model installation automatically, making it efficient and user-friendly for various natural language processing tasks.
ChuanhuChatGPT
Chuanhu Chat is a user-friendly web graphical interface that provides various additional features for ChatGPT and other language models. It supports GPT-4, file-based question answering, local deployment of language models, online search, agent assistant, and fine-tuning. The tool offers a range of functionalities including auto-solving questions, online searching with network support, knowledge base for quick reading, local deployment of language models, GPT 3.5 fine-tuning, and custom model integration. It also features system prompts for effective role-playing, basic conversation capabilities with options to regenerate or delete dialogues, conversation history management with auto-saving and search functionalities, and a visually appealing user experience with themes, dark mode, LaTeX rendering, and PWA application support.

herc.ai
Herc.ai is a powerful library for interacting with the Herc.ai API. It offers free access to users and supports all languages. Users can benefit from Herc.ai's features unlimitedly with a one-time subscription and API key. The tool provides functionalities for question answering and text-to-image generation, with support for various models and customization options. Herc.ai can be easily integrated into CLI, CommonJS, TypeScript, and supports beta models for advanced usage. Developed by FiveSoBes and Luppux Development.
new-api
New API is an open-source project based on One API with additional features and improvements. It offers a new UI interface, supports Midjourney-Proxy(Plus) interface, online recharge functionality, model-based charging, channel weight randomization, data dashboard, token-controlled models, Telegram authorization login, Suno API support, Rerank model integration, and various third-party models. Users can customize models, retry channels, and configure caching settings. The deployment can be done using Docker with SQLite or MySQL databases. The project provides documentation for Midjourney and Suno interfaces, and it is suitable for AI enthusiasts and developers looking to enhance AI capabilities.

LightRAG
LightRAG is a PyTorch library designed for building and optimizing Retriever-Agent-Generator (RAG) pipelines. It follows principles of simplicity, quality, and optimization, offering developers maximum customizability with minimal abstraction. The library includes components for model interaction, output parsing, and structured data generation. LightRAG facilitates tasks like providing explanations and examples for concepts through a question-answering pipeline.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.