
KG-LLM-MDQA
None
Stars: 290
This repository contains code and demo for Knowledge Graph Prompting for Multi-Document Question Answering. It includes modules for data collection, training DPR and MDR models, fine-tuning T5 and LLaMA, and reproducing KGP-LLM algorithm. The workflow involves document collection, knowledge graph construction, fine-tuning models, and reproducing main table results. The repository provides instructions for environment setup, folder architecture, and running different modules.
README:
This repository includes the code and demo of Knowledge Graph Prompting for Multi-Document Question Answering.
- Data-Collect: Codes for querying/collecting Documents based on QA datasets from existing literature. In addition, if you want to get access to the internally collected real-world document question-answering dataset, please refer paper PDFTriage: Question Answering over Long, Structured Documents for more details.
- DPR: Codes for training DPR, dense passage retrieval.
- MDR: Codes for training MDR, multi-hop dense passage retrieval.
- T5: Codes for instruction fine-tuning T5 based on reasoning data of HotpotQA and 2WikiMQA, the pre-trained T5 would be used as the agent for intelligent graph traversal.
- LLaMA: Codes for instruction fine-tuning LLaMA-7B based on reasoning data of HotpotQA and 2WikiMQA, the pre-trained LLaMA would be used as the agent for intelligent graph traversal.
- Pipeline: Codes for reproducing our KGP-LLM algorithm and other models in the main Table in the paper
All model checkpoints and real datasets are separately stored in the Dropbox! Due to limited number of times for the folder to be viewed by readers in a day, here I create another link sharing the folder, feel free to use this one as well
conda install -c anaconda python=3.8
pip install -r requirements.txt
pip install langchain
pip install nltk
pip install -U scikit-learn
pip install rank_bm25
pip install -U sentence-transformers
pip install -U pip setuptools wheel
pip install -U spacy
python -m spacy download en_core_web_lg
pip install torch-scatter
pip install Levenshtein
pip install openai==0.28
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install sentencepiece
pip install transformers
We query Wikipedia based on the QA data from existing literature.
- Input: train/val.json
- Output: train/val/test_docs.json
cd Data-Collect/{dataset}
python3 process.py
We generate KG for each set of documents (paired with a question) using TF-IDF/KNN/TAGME of various densities. For the main Table experiment, we only use the graph constructed by TAGME with prior_prob 0.8.
- Input: train/val/test_docs.json
- Output: .pkl
cd Data-Collect
bash run_{dataset}.sh
We fine-tune the DPR model based on training queries and supporting passages and further use it for obtaining DPR baseline performance.
- HotpotQA: we already have well-curated negative samples in train/val_with_neg_v0 obtained here provided in the Dropbox.
- MuSiQue/Wiki2MQA/IIRC: we randomly sample negative passages before each training epoch.
cd DPR
bash run.sh
After run.sh, you will get model.pt and retrieved contexts for supporting facts for questions in test_docs.json.
We fine-tune the MDR model based on training queries and supporting passages and further use it for obtaining DPR baseline performance. Please note that we only fine-tune MDR for HotpotQA and MuSiQue as we have access to their multi-hop inference training data while for Wiki2MQA and IIRC, we directly use model.pt from HotpotQA to retrieve contexts.
- HotpotQA: Multi-hop training data obtained here, we already provided in the Dropbox.
- MuSiQue: Multi-hop training data obtained ourselves, we already provided in the Dropbox.
- IIRC/Wiki2MQA: We use model.pt from HotpotQA for retrieval.
cd MDR
bash run.sh
After run.sh, you will get model.pt and retrieved contexts for supporting facts for questions in test_docs.json.
See README.md in T5 Folder
See README.md in LLaMA Folder
After completing all the above steps, we need to put the testing documents, retrieved contexts from the model, and generated knowledge graph in the corresponding place. Then, we have everything ready for the main Table in the paper. Specifically, see README.md in Pipeline to configure the files.
- DPR: require DPR_context.json (get from following 3. DPR instruction)
- MDR: require MDR_context.json (get from following 4. MDR instruction)
- LLaMA: require open LLaMA API (open following 6. LLaMA instruction, ensure the port number is consistent, we use localhost with port number 5000 by default)
- T5: open T5 API (open following 5. T5 instruction, ensure the port number is consistent, we use localhost with port number 5000 by default)
- KGP w/o LLM: require the type of KG our LLM is traversing on (get from following 1.-2. instructions)
- KGP-T5/LLaMA/MDR: require KG file (get from following 1-2 instructions) and LLM API is open (5-6 instructions)
- KGNN: require passage embeddings for each passage in the documents for each testing question (obtained by running knn_emb.py)
Then run the following commands:
cd Pipeline
bash run_{dataset}.sh
[!important]
We use multi-parallel processing to call LLM to process each question for each set of documents, which would incur a large amount of consumption when calling with OpenAI API call, therefore, please adaptively change the number of CPUs when parallel calling API according to your budget.
For final evaluation the generated answer:
cd evaluation
jupyter notebook eval.ipynb
Run the corresponding kernels
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for KG-LLM-MDQA
Similar Open Source Tools
KG-LLM-MDQA
This repository contains code and demo for Knowledge Graph Prompting for Multi-Document Question Answering. It includes modules for data collection, training DPR and MDR models, fine-tuning T5 and LLaMA, and reproducing KGP-LLM algorithm. The workflow involves document collection, knowledge graph construction, fine-tuning models, and reproducing main table results. The repository provides instructions for environment setup, folder architecture, and running different modules.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

Simplifine
Simplifine is an open-source library designed for easy LLM finetuning, enabling users to perform tasks such as supervised fine tuning, question-answer finetuning, contrastive loss for embedding tasks, multi-label classification finetuning, and more. It provides features like WandB logging, in-built evaluation tools, automated finetuning parameters, and state-of-the-art optimization techniques. The library offers bug fixes, new features, and documentation updates in its latest version. Users can install Simplifine via pip or directly from GitHub. The project welcomes contributors and provides comprehensive documentation and support for users.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
FunGen-AI-Powered-Funscript-Generator
FunGen is a Python-based tool that uses AI to generate Funscript files from VR and 2D POV videos. It enables fully automated funscript creation for individual scenes or entire folders of videos. The tool includes features like automatic system scaling support, quick installation guides for Windows, Linux, and macOS, manual installation instructions, NVIDIA GPU setup, AMD GPU acceleration, YOLO model download, GUI settings, GitHub token setup, command-line usage, modular systems for funscript filtering and motion tracking, performance and parallel processing tips, and more. The project is still in early development stages and is not intended for commercial use.
ROSGPT_Vision
ROSGPT_Vision is a new robotic framework designed to command robots using only two prompts: a Visual Prompt for visual semantic features and an LLM Prompt to regulate robotic reactions. It is based on the Prompting Robotic Modalities (PRM) design pattern and is used to develop CarMate, a robotic application for monitoring driver distractions and providing real-time vocal notifications. The framework leverages state-of-the-art language models to facilitate advanced reasoning about image data and offers a unified platform for robots to perceive, interpret, and interact with visual data through natural language. LangChain is used for easy customization of prompts, and the implementation includes the CarMate application for driver monitoring and assistance.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.
Auditor
TheAuditor is an offline-first, AI-centric SAST & code intelligence platform designed to find security vulnerabilities, track data flow, analyze architecture, detect refactoring issues, run industry-standard tools, and produce AI-ready reports. It is specifically tailored for AI-assisted development workflows, providing verifiable ground truth for developers and AI assistants. The tool orchestrates verifiable data, focuses on AI consumption, and is extensible to support Python and Node.js ecosystems. The comprehensive analysis pipeline includes stages for foundation, concurrent analysis, and final aggregation, offering features like refactoring detection, dependency graph visualization, and optional insights analysis. The tool interacts with antivirus software to identify vulnerabilities, triggers performance impacts, and provides transparent information on common issues and troubleshooting. TheAuditor aims to address the lack of ground truth in AI development workflows and make AI development trustworthy by providing accurate security analysis and code verification.
Zentara-Code
Zentara Code is an AI coding assistant for VS Code that turns chat instructions into precise, auditable changes in the codebase. It is optimized for speed, safety, and correctness through parallel execution, LSP semantics, and integrated runtime debugging. It offers features like parallel subagents, integrated LSP tools, and runtime debugging for efficient code modification and analysis.
restai
RestAI is an AIaaS (AI as a Service) platform that allows users to create and consume AI agents (projects) using a simple REST API. It supports various types of agents, including RAG (Retrieval-Augmented Generation), RAGSQL (RAG for SQL), inference, vision, and router. RestAI features automatic VRAM management, support for any public LLM supported by LlamaIndex or any local LLM supported by Ollama, a user-friendly API with Swagger documentation, and a frontend for easy access. It also provides evaluation capabilities for RAG agents using deepeval.
sail
Sail is a tool designed to unify stream processing, batch processing, and compute-intensive workloads, serving as a drop-in replacement for Spark SQL and the Spark DataFrame API in single-process settings. It aims to streamline data processing tasks and facilitate AI workloads.
For similar tasks
KG-LLM-MDQA
This repository contains code and demo for Knowledge Graph Prompting for Multi-Document Question Answering. It includes modules for data collection, training DPR and MDR models, fine-tuning T5 and LLaMA, and reproducing KGP-LLM algorithm. The workflow involves document collection, knowledge graph construction, fine-tuning models, and reproducing main table results. The repository provides instructions for environment setup, folder architecture, and running different modules.
openspg
OpenSPG is a knowledge graph engine developed by Ant Group in collaboration with OpenKG, based on the SPG (Semantic-enhanced Programmable Graph) framework. It provides explicit semantic representations, logical rule definitions, operator frameworks (construction, inference), and other capabilities for domain knowledge graphs. OpenSPG supports pluggable adaptation of basic engines and algorithmic services by various vendors to build customized solutions.
Advanced-QA-and-RAG-Series
This repository contains advanced LLM-based chatbots for Retrieval Augmented Generation (RAG) and Q&A with different databases. It provides guides on using AzureOpenAI and OpenAI API for each project. The projects include Q&A and RAG with SQL and Tabular Data, and KnowledgeGraph Q&A and RAG with Tabular Data. Key notes emphasize the importance of good column names, read-only database access, and familiarity with query languages. The chatbots allow users to interact with SQL databases, CSV, XLSX files, and graph databases using natural language.
Aidan-Bench
Aidan Bench is a tool that rewards creativity, reliability, contextual attention, and instruction following. It is weakly correlated with Lmsys, has no score ceiling, and aligns with real-world open-ended use. The tool involves giving LLMs open-ended questions and evaluating their answers based on novelty scores. Users can set up the tool by installing required libraries and setting up API keys. The project allows users to run benchmarks for different models and provides flexibility in threading options.
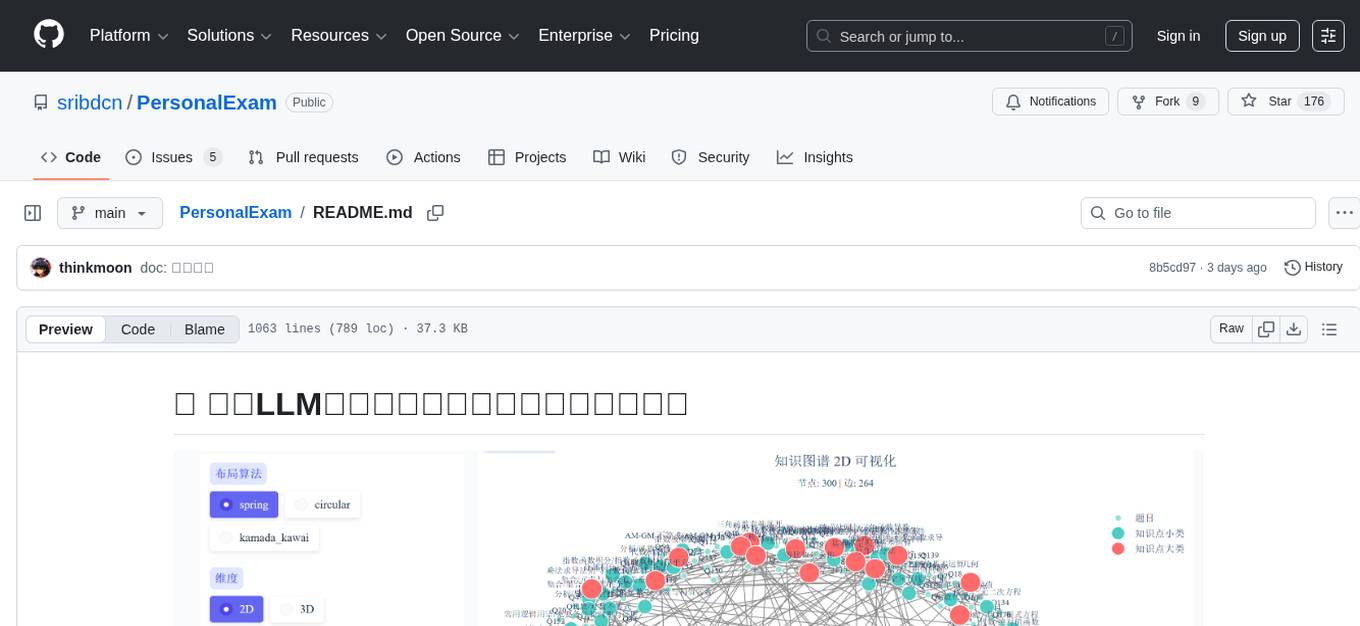
PersonalExam
PersonalExam is a personalized question generation system based on LLM and knowledge graph collaboration. It utilizes the BKT algorithm, RAG engine, and OpenPangu model to achieve personalized intelligent question generation and recommendation. The system features adaptive question recommendation, fine-grained knowledge tracking, AI answer evaluation, student profiling, visual reports, interactive knowledge graph, user management, and system monitoring.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.