Best AI tools for< Evaluate Answers >
20 - AI tool Sites
ThinkTask
ThinkTask is a project and team management tool that utilizes ChatGPT's capabilities to enhance productivity and streamline task management. It offers AI-generated reports and insights, AI usage tracking, Team Pulse for visualizing task types and status, Project Progress Table for monitoring project timelines and budgets, Task Insights for illustrating task interdependencies, and a comprehensive Overview for visualizing progress and managing dependencies. Additionally, ThinkTask features one-click auto-task creation with notes from ChatGPT, auto-tagging for task organization, and AI-suggested task assignments based on past experience and skills. It provides a unified workspace for notes, tasks, databases, collaboration, and customization.

Sereda.ai
Sereda.ai is an AI-powered platform designed to unleash a team's potential by offering solutions for employee knowledge management, surveys, performance reviews, learning, and more. It integrates artificial intelligence to streamline HR processes, improve employee engagement, and boost productivity. The platform provides a user-friendly interface, personalized settings, and automation features to enhance organizational efficiency and reduce costs.
The Clinical AI Report
The Clinical AI Report is an independent platform that provides reviews and rankings of clinical AI tools for physicians. It evaluates various platforms based on clinical accuracy, evidence quality, EHR integration, workflow fit, and value to help physicians access evidence at the point of care. The platform aims to identify the best tools that deliver transparent evidence citations and accurate clinical decision support. It offers detailed reviews and rankings to assist healthcare professionals in making informed decisions about the tools they use.

Brevoir
Brevoir is an AI-powered decision-grade due diligence tool designed for startup investing. It consolidates founder diligence, market and competitor research, risk assessment, and investment-ready writeups in one platform. Tailored for angel investors and startup evaluators, Brevoir streamlines the startup evaluation process by extracting key information from pitch decks or company URLs, verifying claims, mapping competitors, and providing structured reports with risks and opportunities. The tool aims to provide clear answers, identify market trends, evaluate team credibility, assess traction and risks, and offer pricing plans that scale with user needs.
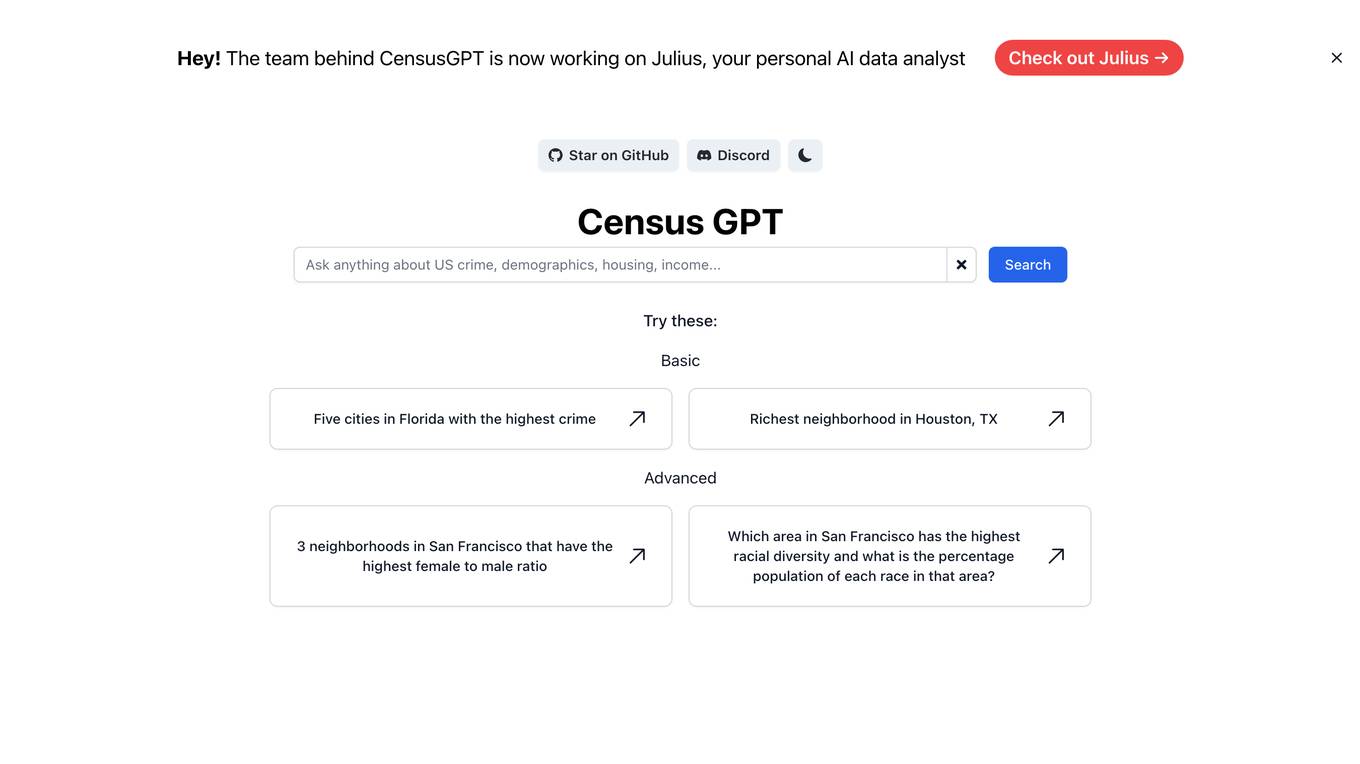
Census GPT
Census GPT is an AI-powered tool that provides data analysis and insights based on census data in the USA. It offers information on crime rates, demographics, income levels, education levels, and population statistics. Users can ask specific questions related to different areas and topics to get detailed answers and insights.
CloudExam AI
CloudExam AI is an online testing platform developed by Hanke Numerical Union Technology Co., Ltd. It provides stable and efficient AI online testing services, including intelligent grouping, intelligent monitoring, and intelligent evaluation. The platform ensures test fairness by implementing automatic monitoring level regulations and three random strategies. It prioritizes information security by combining software and hardware to secure data and identity. With global cloud deployment and flexible architecture, it supports hundreds of thousands of concurrent users. CloudExam AI offers features like queue interviews, interactive pen testing, data-driven cockpit, AI grouping, AI monitoring, AI evaluation, random question generation, dual-seat testing, facial recognition, real-time recording, abnormal behavior detection, test pledge book, student information verification, photo uploading for answers, inspection system, device detection, scoring template, ranking of results, SMS/email reminders, screen sharing, student fees, and collaboration with selected schools.
4'33"
4'33" is an AI agent designed to help students and researchers discover the people they need, such as students seeking professors in a specific field or city. The tool assists in asking better questions, connecting with individuals, and evaluating how well they align with the user's requirements and background. Powered by Perplexity, 4'33" offers a platform for connecting people and answering questions, alongside AI technology. The tool aims to facilitate easier and faster connections between users and relevant individuals, enabling knowledge sharing and collaboration.
Should I Hire AI
Should I Hire AI is an AI application that helps businesses determine if investing in AI tools is the right decision for them. By answering a few questions, the application provides a personalized recommendation on whether AI could be a cost-effective solution. The tool is designed to assist businesses in making informed decisions about integrating AI into their operations, ultimately aiming to enhance efficiency and productivity.
LlamaIndex
LlamaIndex is a framework for building context-augmented Large Language Model (LLM) applications. It provides tools to ingest and process data, implement complex query workflows, and build applications like question-answering chatbots, document understanding systems, and autonomous agents. LlamaIndex enables context augmentation by combining LLMs with private or domain-specific data, offering tools for data connectors, data indexes, engines for natural language access, chat engines, agents, and observability/evaluation integrations. It caters to users of all levels, from beginners to advanced developers, and is available in Python and Typescript.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
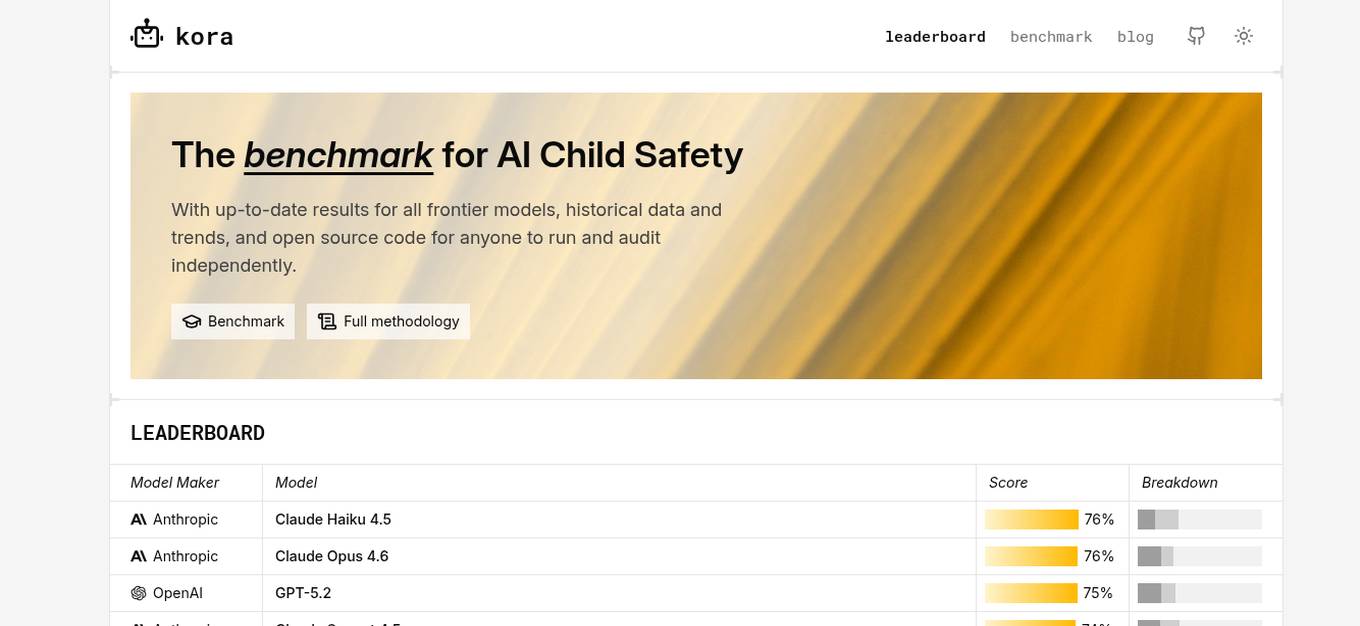
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
3 - Open Source AI Tools
Aidan-Bench
Aidan Bench is a tool that rewards creativity, reliability, contextual attention, and instruction following. It is weakly correlated with Lmsys, has no score ceiling, and aligns with real-world open-ended use. The tool involves giving LLMs open-ended questions and evaluating their answers based on novelty scores. Users can set up the tool by installing required libraries and setting up API keys. The project allows users to run benchmarks for different models and provides flexibility in threading options.
KG-LLM-MDQA
This repository contains code and demo for Knowledge Graph Prompting for Multi-Document Question Answering. It includes modules for data collection, training DPR and MDR models, fine-tuning T5 and LLaMA, and reproducing KGP-LLM algorithm. The workflow involves document collection, knowledge graph construction, fine-tuning models, and reproducing main table results. The repository provides instructions for environment setup, folder architecture, and running different modules.
PersonalExam
PersonalExam is a personalized question generation system based on LLM and knowledge graph collaboration. It utilizes the BKT algorithm, RAG engine, and OpenPangu model to achieve personalized intelligent question generation and recommendation. The system features adaptive question recommendation, fine-grained knowledge tracking, AI answer evaluation, student profiling, visual reports, interactive knowledge graph, user management, and system monitoring.
20 - OpenAI Gpts

Chronic Disease Indicators Expert
This chatbot answers questions about the CDC’s Chronic Disease Indicators dataset

VC Associate
A gpt assistant that helps with analyzing a startup/market. The answers you get back is already structured to give you the core elements you would want to see in an investment memo/ market analysis
Step 1 Med Mentor
USMLE Step 1 study tutor using Duke Pathoma Anki deck, evaluates and guides answers. Powered by SlaySchool.com
Leica Guru
A Photography Expert specializing in personalized Leica gear advice and evaluations.
Legal Tax Minimizer
Interactive questionnaire-based guide for assessing tax residency, liability, and legal minimization strategies.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼