
LLMInterviewQuestions
This repository contains LLM (Large language model) interview question asked in top companies like Google, Nvidia , Meta , Microsoft & fortune 500 companies.
Stars: 78
LLMInterviewQuestions is a repository containing over 100+ interview questions for Large Language Models (LLM) used by top companies like Google, NVIDIA, Meta, Microsoft, and Fortune 500 companies. The questions cover various topics related to LLMs, including prompt engineering, retrieval augmented generation, chunking, embedding models, internal working of vector databases, advanced search algorithms, language models internal working, supervised fine-tuning of LLM, preference alignment, evaluation of LLM system, hallucination control techniques, deployment of LLM, agent-based system, prompt hacking, and miscellaneous topics. The questions are organized into 15 categories to facilitate learning and preparation.
README:
This repository contains over 100+ interview questions for Large Language Models (LLM) used by top companies like Google, NVIDIA, Meta, Microsoft, and Fortune 500 companies. Explore questions curated with insights from real-world scenarios, organized into 15 categories to facilitate learning and preparation.

- Prompt Engineering & Basics of LLM
- Retrieval Augmented Generation (RAG)
- Chunking
- Embedding Models
- Internal Working of Vector Databases
- Advanced Search Algorithms
- Language Models Internal Working
- Supervised Fine-Tuning of LLM
- Preference Alignment (RLHF/DPO)
- Evaluation of LLM System
- Hallucination Control Techniques
- Deployment of LLM
- Agent-Based System
- Prompt Hacking
- Miscellaneous
- Case Studies
- What is the difference between Predictive/Discriminative AI and Generative AI?
- What is LLM, and how are LLMs trained?
- What is a token in the language model?
- How to estimate the cost of running SaaS-based and Open Source LLM models?
- Explain the Temperature parameter and how to set it.
- What are different decoding strategies for picking output tokens?
- What are different ways you can define stopping criteria in large language model?
- How to use stop sequences in LLMs?
- Explain the basic structure prompt engineering.
- Explain in-context learning
- Explain type of prompt engineering
- What are some of the aspect to keep in mind while using few-shots prompting?
- What are certain strategies to write good prompt?
- What is hallucination, and how can it be controlled using prompt engineering?
- How to improve the reasoning ability of LLM through prompt engineering?
- How to improve LLM reasoning if your COT prompt fails?
- how to increase accuracy, and reliability & make answers verifiable in LLM
- How does RAG work?
- What are some benefits of using the RAG system?
- When should I use Fine-tuning instead of RAG?
- What are the architecture patterns for customizing LLM with proprietary data?
- What is chunking, and why do we chunk our data?
- What factors influence chunk size?
- What are the different types of chunking methods?
- How to find the ideal chunk size?
- What are vector embeddings, and what is an embedding model?
- How is an embedding model used in the context of LLM applications?
- What is the difference between embedding short and long content?
- How to benchmark embedding models on your data?
- Suppose you are working with an open AI embedding model, after benchmarking accuracy is coming low, how would you further improve the accuracy of embedding the search model?
- Walk me through steps of improving sentence transformer model used for embedding?
- What is a vector database?
- How does a vector database differ from traditional databases?
- How does a vector database work?
- Explain difference between vector index, vector DB & vector plugins?
- You are working on a project that involves a small dataset of customer reviews. Your task is to find similar reviews in the dataset. The priority is to achieve perfect accuracy in finding the most similar reviews, and the speed of the search is not a primary concern. Which search strategy would you choose and why?
- Explain vector search strategies like clustering and Locality-Sensitive Hashing.
- How does clustering reduce search space? When does it fail and how can we mitigate these failures?
- Explain Random projection index?
- Explain Locality-sensitive hashing (LHS) indexing method?
- Explain product quantization (PQ) indexing method?
- Compare different Vector index and given a scenario, which vector index you would use for a project?
- How would you decide ideal search similarity metrics for the use case?
- Explain different types and challenges associated with filtering in vector DB?
- How to decide the best vector database for your needs?
- What are architecture patterns for information retrieval & semantic search?
- Why it’s important to have very good search
- How can you achieve efficient and accurate search results in large-scale datasets?
- Consider a scenario where a client has already built a RAG-based system that is not giving accurate results, upon investigation you find out that the retrieval system is not accurate, what steps you will take to improve it?
- Explain the keyword-based retrieval method
- How to fine-tune re-ranking models?
- Explain most common metric used in information retrieval and when it fails?
- If you were to create an algorithm for a Quora-like question-answering system, with the objective of ensuring users find the most pertinent answers as quickly as possible, which evaluation metric would you choose to assess the effectiveness of your system?
- I have a recommendation system, which metric should I use to evaluate the system?
- Compare different information retrieval metrics and which one to use when?
- How does hybrid search works?
- If you have search results from multiple methods, how would you merge and homogenize the rankings into a single result set?
- How to handle multi-hop/multifaceted queries?
- What are different techniques to be used to improved retrieval?
- Can you provide a detailed explanation of the concept of self-attention?
- Explain the disadvantages of the self-attention mechanism and how can you overcome it.
- What is positional encoding?
- Explain Transformer architecture in detail.
- What are some of the advantages of using a transformer instead of LSTM?
- What is the difference between local attention and global attention?
- What makes transformers heavy on computation and memory, and how can we address this?
- How can you increase the context length of an LLM?
- If I have a vocabulary of 100K words/tokens, how can I optimize transformer architecture?
- A large vocabulary can cause computation issues and a small vocabulary can cause OOV issues, what approach you would use to find the best balance of vocabulary?
- Explain different types of LLM architecture and which type of architecture is best for which task?
- What is fine-tuning, and why is it needed?
- Which scenario do we need to fine-tune LLM?
- How to make the decision of fine-tuning?
- How do you improve the model to answer only if there is sufficient context for doing so?
- How to create fine-tuning datasets for Q&A?
- How to set hyperparameters for fine-tuning?
- How to estimate infrastructure requirements for fine-tuning LLM?
- How do you fine-tune LLM on consumer hardware?
- What are the different categories of the PEFT method?
- What is catastrophic forgetting in LLMs?
- What are different re-parameterized methods for fine-tuning?
- At which stage you will decide to go for the Preference alignment type of method rather than SFT?
- What is RLHF, and how is it used?
- What is the reward hacking issue in RLHF?
- Explain different preference alignment methods.
- How do you evaluate the best LLM model for your use case?
- How to evaluate RAG-based systems?
- What are different metrics for evaluating LLMs?
- Explain the Chain of Verification.
- What are different forms of hallucinations?
- How to control hallucinations at various levels?
- Why does quantization not decrease the accuracy of LLM?
- What are the techniques by which you can optimize the inference of LLM for higher throughput?
- How to accelerate response time of model without attention approximation like group query attention?
- Explain the basic concepts of an agent and the types of strategies available to implement agents
- Why do we need agents and what are some common strategies to implement agents?
- Explain ReAct prompting with a code example and its advantages
- Explain Plan and Execute prompting strategy
- Explain OpenAI functions strategy with code examples
- Explain the difference between OpenAI functions vs LangChain Agents
- What is prompt hacking and why should we bother about it?
- What are the different types of prompt hacking?
- What are the different defense tactics from prompt hacking?
- How to optimize cost of overall LLM System?
- What are mixture of expert models (MoE)?
- How to build production grade RAG system, explain each component in detail ?
- What is FP8 variable and what are its advantages of it
- How to train LLM with low precision training without compromising on accuracy ?
- How to calculate size of KV cache
- Explain dimension of each layer in multi headed transformation attention block
- How do you make sure that attention layer focuses on the right part of the input?
- Case Study 1: LLM Chat Assistant with dynamic context based on query
- Case Study 2: Prompting Techniques
For answers for those questions please, visit Mastering LLM.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLMInterviewQuestions
Similar Open Source Tools
LLMInterviewQuestions
LLMInterviewQuestions is a repository containing over 100+ interview questions for Large Language Models (LLM) used by top companies like Google, NVIDIA, Meta, Microsoft, and Fortune 500 companies. The questions cover various topics related to LLMs, including prompt engineering, retrieval augmented generation, chunking, embedding models, internal working of vector databases, advanced search algorithms, language models internal working, supervised fine-tuning of LLM, preference alignment, evaluation of LLM system, hallucination control techniques, deployment of LLM, agent-based system, prompt hacking, and miscellaneous topics. The questions are organized into 15 categories to facilitate learning and preparation.
AudioMuse-AI
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.
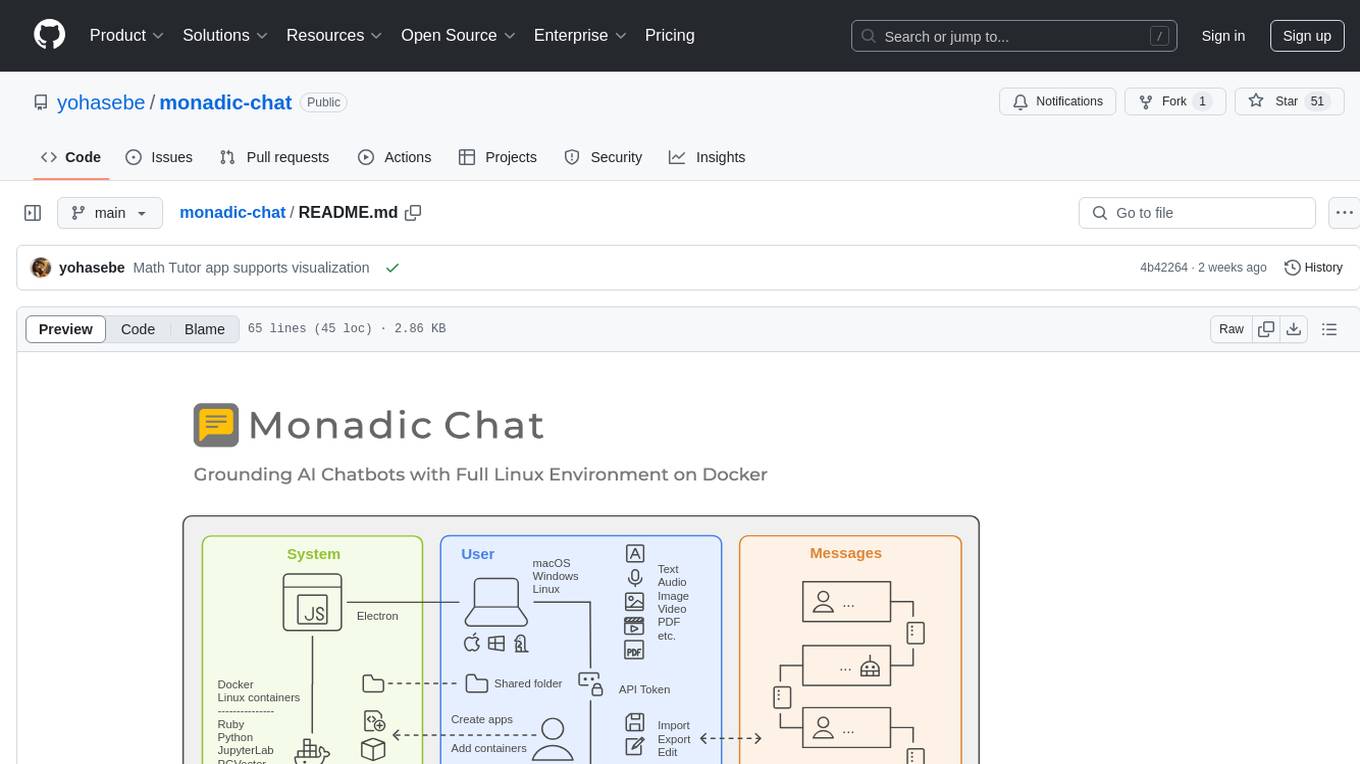
monadic-chat
Monadic Chat is a locally hosted web application designed to create and utilize intelligent chatbots. It provides a Linux environment on Docker to GPT and other LLMs, enabling the execution of advanced tasks that require external tools. The tool supports voice interaction, image and video recognition and generation, and AI-to-AI chat, making it useful for using AI and developing various applications. It is available for Mac, Windows, and Linux (Debian/Ubuntu) with easy-to-use installers.
100days_AI
The 100 Days in AI repository provides a comprehensive roadmap for individuals to learn Artificial Intelligence over a period of 100 days. It covers topics ranging from basic programming in Python to advanced concepts in AI, including machine learning, deep learning, and specialized AI topics. The repository includes daily tasks, resources, and exercises to ensure a structured learning experience. By following this roadmap, users can gain a solid understanding of AI and be prepared to work on real-world AI projects.
eureka-framework
The Eureka Framework is an open-source toolkit that leverages advanced Artificial Intelligence and Decentralized Science principles to revolutionize scientific discovery. It enables researchers, developers, and decentralized organizations to explore scientific papers, conduct AI-driven experiments, monetize research contributions, provide token-gated access to AI agents, and customize AI agents for specific research domains. The framework also offers features like a RESTful API, robust scheduler for task automation, and webhooks for real-time notifications, empowering users to automate research tasks, enhance productivity, and foster a committed research community.
pocketpal-ai
PocketPal AI is a versatile virtual assistant tool designed to streamline daily tasks and enhance productivity. It leverages artificial intelligence technology to provide personalized assistance in managing schedules, organizing information, setting reminders, and more. With its intuitive interface and smart features, PocketPal AI aims to simplify users' lives by automating routine activities and offering proactive suggestions for optimal time management and task prioritization.
aider-desk
AiderDesk is a desktop application that enhances coding workflow by leveraging AI capabilities. It offers an intuitive GUI, project management, IDE integration, MCP support, settings management, cost tracking, structured messages, visual file management, model switching, code diff viewer, one-click reverts, and easy sharing. Users can install it by downloading the latest release and running the executable. AiderDesk also supports Python version detection and auto update disabling. It includes features like multiple project management, context file management, model switching, chat mode selection, question answering, cost tracking, MCP server integration, and MCP support for external tools and context. Development setup involves cloning the repository, installing dependencies, running in development mode, and building executables for different platforms. Contributions from the community are welcome following specific guidelines.
lawglance
LawGlance is an AI-powered legal assistant that aims to bridge the gap between people and legal access. It is a free, open-source initiative designed to provide quick and accurate legal support tailored to individual needs. The project covers various laws, with plans for international expansion in the future. LawGlance utilizes AI-powered Retriever-Augmented Generation (RAG) to deliver legal guidance accessible to both laypersons and professionals. The tool is developed with support from mentors and experts at Data Science Academy and Curvelogics.

MM-RLHF
MM-RLHF is a comprehensive project for aligning Multimodal Large Language Models (MLLMs) with human preferences. It includes a high-quality MLLM alignment dataset, a Critique-Based MLLM reward model, a novel alignment algorithm MM-DPO, and benchmarks for reward models and multimodal safety. The dataset covers image understanding, video understanding, and safety-related tasks with model-generated responses and human-annotated scores. The reward model generates critiques of candidate texts before assigning scores for enhanced interpretability. MM-DPO is an alignment algorithm that achieves performance gains with simple adjustments to the DPO framework. The project enables consistent performance improvements across 10 dimensions and 27 benchmarks for open-source MLLMs.
octocode-mcp
Octocode is a methodology and platform that empowers AI assistants with the skills of a Senior Staff Engineer. It transforms how AI interacts with code by moving from 'guessing' based on training data to 'knowing' based on deep, evidence-based research. The ecosystem includes the Manifest for Research Driven Development, the MCP Server for code interaction, Agent Skills for extending AI capabilities, a CLI for managing agent capabilities, and comprehensive documentation covering installation, core concepts, tutorials, and reference materials.
exllamav3
ExLlamaV3 is an inference library for running local LLMs on modern consumer GPUs. It features a new EXL3 quantization format based on QTIP, flexible tensor-parallel and expert-parallel inference, OpenAI-compatible server via TabbyAPI, continuous dynamic batching, HF Transformers plugin, speculative decoding, multimodal support, and more. The library supports various architectures and aims to simplify and optimize the quantization process for large models, offering efficient conversion with reduced GPU-hours and cost. It provides a streamlined variant of QTIP, enabling fast and memory-bound latency for inference on GPUs.
agentfactory
The AI Agent Factory is a spec-driven blueprint for building and monetizing digital FTEs. It empowers developers, entrepreneurs, and organizations to learn, build, and monetize intelligent AI agents, creating reliable digital FTEs that can be trusted, deployed, and scaled. The tool focuses on co-learning between humans and machines, emphasizing collaboration, clear specifications, and evolving together. It covers AI-assisted, AI-driven, and AI-native development approaches, guiding users through the AI development spectrum and organizational AI maturity levels. The core philosophy revolves around treating AI as a collaborative partner, using specification-first methodology, bilingual development, learning by doing, and ensuring transparency and reproducibility. The tool is suitable for beginners, professional developers, entrepreneurs, product leaders, educators, and tech leaders.
AI-Blueprints
This repository hosts a collection of AI blueprint projects for HP AI Studio, providing end-to-end solutions across key AI domains like data science, machine learning, deep learning, and generative AI. The projects are designed to be plug-and-play, utilizing open-source and hosted models to offer ready-to-use solutions. The repository structure includes projects related to classical machine learning, deep learning applications, generative AI, NGC integration, and troubleshooting guidelines for common issues. Each project is accompanied by detailed descriptions and use cases, showcasing the versatility and applicability of AI technologies in various domains.
learn-low-code-agentic-ai
This repository is dedicated to learning about Low-Code Full-Stack Agentic AI Development. It provides material for building modern AI-powered applications using a low-code full-stack approach. The main tools covered are UXPilot for UI/UX mockups, Lovable.dev for frontend applications, n8n for AI agents and workflows, Supabase for backend data storage, authentication, and vector search, and Model Context Protocol (MCP) for integration. The focus is on prompt and context engineering as the foundation for working with AI systems, enabling users to design, develop, and deploy AI-driven full-stack applications faster, smarter, and more reliably.
comfyui-portrait-master
ComfyUI Portrait Master 3.1 is a tool designed to assist AI image creators in generating prompts for human portraits. The tool offers various modules for customizing character details such as base character, skin details, style & pose, and makeup. Users can control parameters like shot type, gender, age, ethnicity mix, body type, facial features, hair details, skin imperfections, and more to create unique portrait prompts. The tool aims to enhance photorealism and provide a user-friendly interface for generating portrait prompts efficiently.
animal-crossing-llm-mod
The Animal Crossing LLM Mod transforms the game into an AI-powered conversation experience by generating dynamic, contextual dialogue for villagers in real-time. It reads dialogue memory, generates AI responses, writes new dialogue back to the game, and creates natural and contextual conversations. The mod is experimental software with known bugs and is currently only tested on macOS. Users can interact with villagers in Animal Crossing using AI-generated responses, enhancing the gameplay experience.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.