
witsy
Witsy: desktop AI assistant / universal MCP client
Stars: 1874
Witsy is a generative AI desktop application that supports various models like OpenAI, Ollama, Anthropic, MistralAI, Google, Groq, and Cerebras. It offers features such as chat completion, image generation, scratchpad for content creation, prompt anywhere functionality, AI commands for productivity, expert prompts for specialization, LLM plugins for additional functionalities, read aloud capabilities, chat with local files, transcription/dictation, Anthropic Computer Use support, local history of conversations, code formatting, image copy/download, and more. Users can interact with the application to generate content, boost productivity, and perform various AI-related tasks.
README:
Universal MCP Client


![]()


Download Witsy from the releases page.
On macOS you can also brew install --cask witsy.
Witsy is a BYOK (Bring Your Own Keys) AI application: it means you need to have API keys for the LLM providers you want to use. Alternatively, you can use Ollama to run models locally on your machine for free and use them in Witsy.
It is the first of very few (only?) universal MCP clients:
Witsy allows you to run MCP servers with virtually any LLM!
| Capability | Providers |
|---|---|
| Chat | OpenAI, Anthropic, Google (Gemini), xAI (Grok), Meta (Llama), Ollama, LM Studio, MistralAI, DeepSeek, OpenRouter, Groq, Cerebras, Azure OpenAI, any provider who supports the OpenAI API standard (together.ai for instance) |
| Image Creation | OpenAI, Google, xAI, Replicate, fal.ai, HuggingFace, Stable Diffusion WebUI |
| Video Creation | OpenAI, Google, Replicate, fal.ai |
| Text-to-Speech | OpenAI, ElevenLabs, Groq, fal.ai |
| Speech-to-Text | OpenAI (Whisper), fal.ai, Fireworks.ai, Gladia, Groq, nVidia, Speechmatics, Local Whisper, Soniox (realtime and async) any provider who supports the OpenAI API standard |
| Search Engines | Perplexity, Tavily, Brave, Exa, Local Google Search |
| MCP Repositories | Smithery.ai |
| Embeddings | OpenAI, Ollama |
Non-exhaustive feature list:
- Chat completion with vision models support (describe an image)
- Text-to-image and text-to video
- Image-to-image (image editing) and image-to-video
- LLM plugins to augment LLM: execute python code, search the Internet...
- Anthropic MCP server support
- Scratchpad to interactively create the best content with any model!
- Prompt anywhere allows to generate content directly in any application
- AI commands runnable on highlighted text in almost any application
- Experts prompts to specialize your bot on a specific topic
- Long-term memory plugin to increase relevance of LLM answers
- Read aloud of assistant messages
- Read aloud of any text in other applications
- Chat with your local files and documents (RAG)
- Transcription/Dictation (Speech-to-Text)
- Realtime Chat aka Voice Mode
- Anthropic Computer Use support
- Local history of conversations (with automatic titles)
- Formatting and copy to clipboard of generated code
- Conversation PDF export
- Image copy and download



You can download a binary from from the releases page or build yourself:
npm ci
npm start
To use OpenAI, Anthropic, Google or Mistral AI models, you need to enter your API key:
To use Ollama models, you need to install Ollama and download some models.
To use text-to-speech, you need an
- OpenAI API key.
- Fal.ai API Key
- Fireworks.ai API Key
- Groq API Key
- Speechmatics API Key
- Gladia API Key
To use Internet search you need a Tavily API key.

Generate content in any application:
- From any editable content in any application
- Hit the Prompt anywhere shortcut (Shift+Control+Space / ^⇧Space)
- Enter your prompt in the window that pops up
- Watch Witsy enter the text directly in your application!
On Mac, you can define an expert that will automatically be triggered depending on the foreground application. For instance, if you have an expert used to generate linux commands, you can have it selected if you trigger Prompt Anywhere from the Terminal application!
AI commands are quick helpers accessible from a shortcut that leverage LLM to boost your productivity:
- Select any text in any application
- Hit the AI command shorcut (Alt+Control+Space / ⌃⌥Space)
- Select one of the commands and let LLM do their magic!
You can also create custom commands with the prompt of your liking!



Commands inspired by https://the.fibery.io/@public/Public_Roadmap/Roadmap_Item/AI-Assistant-via-ChatGPT-API-170.
From https://github.com/f/awesome-chatgpt-prompts.
https://www.youtube.com/watch?v=czcSbG2H-wg
You can connect each chat with a document repository: Witsy will first search for relevant documents in your local files and provide this info to the LLM. To do so:
- Click on the database icon on the left of the prompt
- Click Manage and then create a document repository
- OpenAI Embedding require on API key, Ollama requires an embedding model
- Add documents by clicking the + button on the right hand side of the window
- Once your document repository is created, click on the database icon once more and select the document repository you want to use. The icon should turn blue
You can transcribe audio recorded on the microphone to text. Transcription can be done using a variety of state of the art speech to text models (which require API key) or using local Whisper model (requires download of large files).
Currently Witsy supports the following speech to text models:
- GPT4o-Transcribe
- Gladia
- Speechmatics (Standards + Enhanced)
- Groq Whisper V3
- Fireworks.ai Realtime Transcription
- fal.ai Wizper V3
- fal.ai ElevenLabs
- nVidia Microsoft Phi-4 Multimodal
Witsy supports quick shortcuts, so your transcript is always only one button press away.
Once the text is transcribed you can:
- Copy it to your clipboard
- Summarize it
- Translate it to any language
- Insert it in the application that was running before you activated the dictation
https://www.youtube.com/watch?v=vixl7I07hBk
Witsy provides a local HTTP API that allows external applications to trigger various commands and features. The API server runs on localhost by default on port 8090 (or the next available port if 8090 is in use).
Security Note: The HTTP server runs on localhost only by default. If you need external access, consider using a reverse proxy with proper authentication.
The current HTTP server port is displayed in the tray menu below the Settings option:
- macOS/Linux: Check the fountain pen icon in the menu bar
- Windows: Check the fountain pen icon in the system tray
All endpoints support both GET (with query parameters) and POST (with JSON or form-encoded body) requests.
| Endpoint | Description | Optional Parameters |
|---|---|---|
GET /api/health |
Server health check | - |
GET/POST /api/chat |
Open main window in chat view |
text - Pre-fill chat input |
GET/POST /api/scratchpad |
Open scratchpad | - |
GET/POST /api/settings |
Open settings window | - |
GET/POST /api/studio |
Open design studio | - |
GET/POST /api/forge |
Open agent forge | - |
GET/POST /api/realtime |
Open realtime chat (voice mode) | - |
GET/POST /api/prompt |
Trigger Prompt Anywhere |
text - Pre-fill prompt |
GET/POST /api/command |
Trigger AI command picker |
text - Pre-fill command text |
GET/POST /api/transcribe |
Start transcription/dictation | - |
GET/POST /api/readaloud |
Start read aloud | - |
GET /api/engines |
List available AI engines | Returns configured chat engines |
GET /api/models/:engine |
List models for an engine | Returns available models for specified engine |
POST /api/complete |
Run chat completion |
stream (default: true), engine, model, thread (Message[]) |
GET/POST /api/agent/run/:token |
Trigger agent execution via webhook | Query params passed as prompt inputs |
GET /api/agent/status/:token/:runId |
Check agent execution status | Returns status, output, and error |
# Health check
curl http://localhost:8090/api/health
# Open chat with pre-filled text (GET with query parameter)
curl "http://localhost:8090/api/chat?text=Hello%20World"
# Open chat with pre-filled text (POST with JSON)
curl -X POST http://localhost:8090/api/chat \
-H "Content-Type: application/json" \
-d '{"text":"Hello World"}'
# Trigger Prompt Anywhere with text
curl "http://localhost:8090/api/prompt?text=Write%20a%20poem"
# Trigger AI command on selected text
curl -X POST http://localhost:8090/api/command \
-H "Content-Type: application/json" \
-d '{"text":"selected text to process"}'
# Trigger agent via webhook with parameters
curl "http://localhost:8090/api/agent/run/abc12345?input1=value1&input2=value2"
# Trigger agent with POST JSON
curl -X POST http://localhost:8090/api/agent/run/abc12345 \
-H "Content-Type: application/json" \
-d '{"input1":"value1","input2":"value2"}'
# Check agent execution status
curl "http://localhost:8090/api/agent/status/abc12345/run-uuid-here"
# List available engines
curl http://localhost:8090/api/engines
# List models for a specific engine
curl http://localhost:8090/api/models/openai
# Run non-streaming chat completion
curl -X POST http://localhost:8090/api/complete \
-H "Content-Type: application/json" \
-d '{
"stream": "false",
"engine": "openai",
"model": "gpt-4",
"thread": [
{"role": "user", "content": "Hello, how are you?"}
]
}'
# Run streaming chat completion (SSE)
curl -X POST http://localhost:8090/api/complete \
-H "Content-Type: application/json" \
-d '{
"stream": "true",
"thread": [
{"role": "user", "content": "Write a short poem"}
]
}'Witsy includes a command-line interface that allows you to interact with the AI assistant directly from your terminal.
Installation
The CLI is automatically installed when you launch Witsy for the first time:
-
macOS: Creates a symlink at
/usr/local/bin/witsy(requires admin password) - Windows: Adds the CLI to your user PATH (restart terminal for changes to take effect)
-
Linux: Creates a symlink at
/usr/local/bin/witsy(uses pkexec if needed)
Usage
Once installed, you can use the witsy command from any terminal:
witsyThe CLI will connect to your running Witsy application and provide an interactive chat interface. It uses the same configuration (engine, model, API keys) as your desktop application.
Available Commands
-
/help- Show available commands -
/model- Select engine and model -
/port- Change server port (default: 4321) -
/clear- Clear conversation history -
/history- Show conversation history -
/exit- Exit the CLI
Requirements
- Witsy desktop application must be running
- HTTP API server enabled (default port: 4321)
The /api/complete endpoint provides programmatic access to Witsy's chat completion functionality, enabling command-line tools and scripts to interact with any configured LLM.
Endpoint: POST /api/complete
Request body:
{
"stream": "true", // Optional: "true" (default) for SSE streaming, "false" for JSON response
"engine": "openai", // Optional: defaults to configured engine in settings
"model": "gpt-4", // Optional: defaults to configured model for the engine
"thread": [ // Required: array of messages
{"role": "user", "content": "Your prompt here"}
]
}Response (non-streaming, stream: "false"):
{
"success": true,
"response": {
"content": "The assistant's response text",
"usage": {
"promptTokens": 10,
"completionTokens": 20,
"totalTokens": 30
}
}
}Response (streaming, stream: "true"):
Server-Sent Events (SSE) format with chunks:
data: {"type":"content","text":"Hello","done":false}
data: {"type":"content","text":" world","done":false}
data: [DONE]
List Engines:
curl http://localhost:8090/api/enginesResponse:
{
"engines": [
{"id": "openai", "name": "OpenAI"},
{"id": "anthropic", "name": "Anthropic"},
{"id": "google", "name": "Google"}
]
}List Models for an Engine:
curl http://localhost:8090/api/models/openaiResponse:
{
"engine": "openai",
"models": [
{"id": "gpt-4", "name": "GPT-4"},
{"id": "gpt-3.5-turbo", "name": "GPT-3.5 Turbo"}
]
}Witsy includes a command-line interface for interacting with AI models directly from your terminal.
Requirements:
- Witsy application must be running (for the HTTP API server)
Launch the CLI:
npm run cliEnter /help to show the list of commands
Agent webhooks allow you to trigger agent execution via HTTP requests, enabling integration with external systems, automation tools, or custom workflows.
Setting up a webhook:
- Open the Agent Forge and select or create an agent
- Navigate to the "Invocation" tab (last step in the wizard)
- Check the "🌐 Webhook" checkbox
- A unique 8-character token is automatically generated for your agent
- Copy the webhook URL displayed (format:
http://localhost:{port}/api/agent/run/{token}) - You can regenerate the token at any time using the refresh button
Using the webhook:
- Send GET or POST requests to the webhook URL
- Include parameters as query strings (GET) or JSON body (POST)
- Parameters are automatically passed to the agent's prompt as input variables
- The agent must have prompt variables defined (e.g.,
{task},{name}) to receive the parameters - The webhook returns immediately with a
runIdandstatusUrlfor checking execution status
Example agent prompt:
Please process the following task: {task}
User: {user}
Priority: {priority}
Triggering the agent:
# Using GET with query parameters
curl "http://localhost:8090/api/agent/run/abc12345?task=backup&user=john&priority=high"
# Using POST with JSON
curl -X POST http://localhost:8090/api/agent/run/abc12345 \
-H "Content-Type: application/json" \
-d '{"task":"backup","user":"john","priority":"high"}'Run response:
{
"success": true,
"runId": "550e8400-e29b-41d4-a716-446655440000",
"statusUrl": "/api/agent/status/abc12345/550e8400-e29b-41d4-a716-446655440000"
}Checking execution status:
# Use the statusUrl from the webhook response (relative path)
curl "http://localhost:8090/api/agent/status/abc12345/550e8400-e29b-41d4-a716-446655440000"Status response (running):
{
"success": true,
"runId": "550e8400-e29b-41d4-a716-446655440000",
"agentId": "agent-uuid",
"status": "running",
"createdAt": 1234567890000,
"updatedAt": 1234567900000,
"trigger": "webhook"
}Status response (success):
{
"success": true,
"runId": "550e8400-e29b-41d4-a716-446655440000",
"agentId": "agent-uuid",
"status": "success",
"createdAt": 1234567890000,
"updatedAt": 1234567950000,
"trigger": "webhook",
"output": "Backup completed successfully for user john with high priority"
}Status response (error):
{
"success": true,
"runId": "550e8400-e29b-41d4-a716-446655440000",
"agentId": "agent-uuid",
"status": "error",
"createdAt": 1234567890000,
"updatedAt": 1234567999000,
"trigger": "webhook",
"error": "Failed to connect to backup server"
}- [ ] Workspaces / Projects (whatever the name is)
- [ ] Proper database (SQLite3) storage (??)
- [x]
- [x] OpenAI Sora support
- [x] Google Nano Banana support
- [x] Command line interface
- [x] HTTP Server for commanding Witsy, triggering Agents
- [x] Table rendering as artifact, download as CSV and XSLX
- [x] Web apps in menu bar
- [x] Perplexity Search API support
- [x] Design Studio drawing
- [x] MCP Authorization support
- [x] Implement Soniox for STT
- [x] OpenAI GPT-5 support
- [x] Agents (multi-step, scheduling...)
- [x] Document Repository file change monitoring
- [x] OpenAI API response (o3-pro)
- [x] ChatGPT history import
- [x] Onboarding experience
- [x] Add, Edit & Delete System Prompts
- [x] Backup/Restore of data and settings
- [x] Transcribe Local Audio Files
- [x] DeepResearch
- [x] Local filesystem access plugin
- [x] Close markdown when streaming
- [x] Multiple attachments
- [x] Custom OpenAI STT support
- [x] AI Commands copy/insert/replace shortcuts
- [x] Defaults at folder level
- [x] Tool selection for chat
- [x] Realtime STT with Speechmatics
- [x] Meta/Llama AI support
- [x] Realtime STT with Fireworks
- [x] OpenAI image generation
- [x] Azure AI support
- [x] Brave Search plugin
- [x] Allow user-input models for embeddings
- [x] User defined parameters for custom engines
- [x] Direct speech-to-text checbox
- [x] Quick access buttons on home
- [x] fal.ai support (speech-to-text, text-to-image and text-to-video)
- [x] Debug console
- [x] Design Studio
- [x] i18n
- [x] Mermaid diagram rendering
- [x] Smithery.ai MCP integration
- [x] Model Context Protocol
- [x] Local Web Search
- [x] Model defaults
- [x] Speech-to-text language
- [x] Model parameters (temperature...)
- [x] Favorite models
- [x] ElevenLabs Text-to-Speech
- [x] Custom engines (OpenAI compatible)
- [x] Long-term memory plugin
- [x] OpenRouter support
- [x] DeepSeek support
- [x] Folder mode
- [x] All instructions customization
- [x] Fork chat (with optional LLM switch)
- [x] Realtime chat
- [x] Replicate video generation
- [x] Together.ai compatibility
- [x] Gemini 2.0 Flash support
- [x] Groq LLama 3.3 support
- [x] xAI Grok Vision Model support
- [x] Ollama function-calling
- [x] Replicate image generation
- [x] AI Commands redesign
- [x] Token usage report
- [x] OpenAI o1 models support
- [x] Groq vision support
- [x] Image resize option
- [x] Llama 3.2 vision support
- [x] YouTube plugin
- [x] RAG in Scratchpad
- [x] Hugging face image generation
- [x] Show prompt used for image generation
- [x] Redesigned Prompt window
- [x] Anthropic Computer Use
- [x] Auto-update refactor (still not Windows)
- [x] Dark mode
- [x] Conversation mode
- [x] Google function calling
- [x] Anthropic function calling
- [x] Scratchpad
- [x] Dictation: OpenAI Whisper + Whisper WebGPU
- [x] Auto-select expert based on foremost app (Mac only)
- [x] Cerebras support
- [x] Local files RAG
- [x] Groq model update (8-Sep-2024)
- [x] PDF Export of chats
- [x] Prompts renamed to Experts. Now editable.
- [x] Read aloud
- [x] Import/Export commands
- [x] Anthropic Sonnet 3.5
- [x] Ollama base URL as settings
- [x] OpenAI base URL as settings
- [x] DALL-E as tool
- [x] Google Gemini API
- [x] Prompt anywhere
- [x] Cancel commands
- [x] GPT-4o support
- [x] Different default engine/model for commands
- [x] Text attachments (TXT, PDF, DOCX, PPTX, XLSX)
- [x] MistralAI function calling
- [x] Auto-update
- [x] History date sections
- [x] Multiple selection delete
- [x] Search
- [x] Groq API
- [x] Custom prompts
- [x] Sandbox & contextIsolation
- [x] Application Menu
- [x] Prompt history navigation
- [x] Ollama model pull
- [x] macOS notarization
- [x] Fix when long text is highlighted
- [x] Shortcuts for AI commands
- [x] Shift to switch AI command behavior
- [x] User feedback when running a tool
- [x] Download internet content plugin
- [x] Tavily Internet search plugin
- [x] Python code execution plugin
- [x] LLM Tools supprt (OpenAI only)
- [x] Mistral AI API integration
- [x] Latex rendering
- [x] Anthropic API integration
- [x] Image generation as b64_json
- [x] Text-to-speech
- [x] Log file (electron-log)
- [x] Conversation language settings
- [x] Paste image in prompt
- [x] Run commands with default models
- [x] Models refresh
- [x] Edit commands
- [x] Customized commands
- [x] Conversation menu (info, save...)
- [x] Conversation depth setting
- [x] Save attachment on disk
- [x] Keep running in system tray
- [x] Nicer icon (still temporary)
- [x] Rename conversation
- [x] Copy/edit messages
- [x] New chat window for AI command
- [x] AI Commands with shortcut
- [x] Auto-switch to vision model
- [x] Run at login
- [x] Shortcut editor
- [x] Chat font size settings
- [x] Image attachment for vision
- [x] Stop response streaming
- [x] Save/Restore window position
- [x] Ollama support
- [x] View image full screen
- [x] Status/Tray bar icon + global shortcut to invoke
- [x] Chat themes
- [x] Default instructions in settings
- [x] Save DALL-E images locally (and delete properly)
- [x] OpenAI links in settings
- [x] Copy code button
- [x] Chat list ordering
- [x] OpenAI model choice
- [x] CSS variables
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for witsy
Similar Open Source Tools
witsy
Witsy is a generative AI desktop application that supports various models like OpenAI, Ollama, Anthropic, MistralAI, Google, Groq, and Cerebras. It offers features such as chat completion, image generation, scratchpad for content creation, prompt anywhere functionality, AI commands for productivity, expert prompts for specialization, LLM plugins for additional functionalities, read aloud capabilities, chat with local files, transcription/dictation, Anthropic Computer Use support, local history of conversations, code formatting, image copy/download, and more. Users can interact with the application to generate content, boost productivity, and perform various AI-related tasks.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.
zeroclaw
ZeroClaw is a fast, small, and fully autonomous AI assistant infrastructure built with Rust. It features a lean runtime, cost-efficient deployment, fast cold starts, and a portable architecture. It is secure by design, fully swappable, and supports OpenAI-compatible provider support. The tool is designed for low-cost boards and small cloud instances, with a memory footprint of less than 5MB. It is suitable for tasks like deploying AI assistants, swapping providers/channels/tools, and pluggable everything.

LocalAGI
LocalAGI is a powerful, self-hostable AI Agent platform that allows you to design AI automations without writing code. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities. With LocalAGI, you can create customizable AI assistants, automations, chat bots, and agents that run 100% locally, without the need for cloud services or API keys. The platform offers features like no-code agents, web-based interface, advanced agent teaming, connectors for various platforms, comprehensive REST API, short & long-term memory capabilities, planning & reasoning, periodic tasks scheduling, memory management, multimodal support, extensible custom actions, fully customizable models, observability, and more.

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.
browser4
Browser4 is a lightning-fast, coroutine-safe browser designed for AI integration with large language models. It offers ultra-fast automation, deep web understanding, and powerful data extraction APIs. Users can automate the browser, extract data at scale, and perform tasks like summarizing products, extracting product details, and finding specific links. The tool is developer-friendly, supports AI-powered automation, and provides advanced features like X-SQL for precise data extraction. It also offers RPA capabilities, browser control, and complex data extraction with X-SQL. Browser4 is suitable for web scraping, data extraction, automation, and AI integration tasks.
twick
Twick is a comprehensive video editing toolkit built with modern web technologies. It is a monorepo containing multiple packages for video and image manipulation. The repository includes core utilities for media handling, a React-based canvas library for video and image editing, a video visualization and animation toolkit, a React component for video playback and control, timeline management and editing capabilities, a React-based video editor, and example implementations and usage demonstrations. Twick provides detailed API documentation and module information for developers. It offers easy integration with existing projects and allows users to build videos using the Twick Studio. The project follows a comprehensive style guide for naming conventions and code style across all packages.

ai00_server
AI00 RWKV Server is an inference API server for the RWKV language model based upon the web-rwkv inference engine. It supports VULKAN parallel and concurrent batched inference and can run on all GPUs that support VULKAN. No need for Nvidia cards!!! AMD cards and even integrated graphics can be accelerated!!! No need for bulky pytorch, CUDA and other runtime environments, it's compact and ready to use out of the box! Compatible with OpenAI's ChatGPT API interface. 100% open source and commercially usable, under the MIT license. If you are looking for a fast, efficient, and easy-to-use LLM API server, then AI00 RWKV Server is your best choice. It can be used for various tasks, including chatbots, text generation, translation, and Q&A.
node-sdk
The ChatBotKit Node SDK is a JavaScript-based platform for building conversational AI bots and agents. It offers easy setup, serverless compatibility, modern framework support, customizability, and multi-platform deployment. With capabilities like multi-modal and multi-language support, conversation management, chat history review, custom datasets, and various integrations, this SDK enables users to create advanced chatbots for websites, mobile apps, and messaging platforms.
logicstamp-context
LogicStamp Context is a static analyzer that extracts deterministic component contracts from TypeScript codebases, providing structured architectural context for AI coding assistants. It helps AI assistants understand architecture by extracting props, hooks, and dependencies without implementation noise. The tool works with React, Next.js, Vue, Express, and NestJS, and is compatible with various AI assistants like Claude, Cursor, and MCP agents. It offers features like watch mode for real-time updates, breaking change detection, and dependency graph creation. LogicStamp Context is a security-first tool that protects sensitive data, runs locally, and is non-opinionated about architectural decisions.
x
Ant Design X is a tool for crafting AI-driven interfaces effortlessly. It is built on the best practices of enterprise-level AI products, offering flexible and diverse atomic components for various AI dialogue scenarios. The tool provides out-of-the-box model integration with inference services compatible with OpenAI standards. It also enables efficient management of conversation data flows, supports rich template options, complete TypeScript support, and advanced theme customization. Ant Design X is designed to enhance development efficiency and deliver exceptional AI interaction experiences.

Bindu
Bindu is an operating layer for AI agents that provides identity, communication, and payment capabilities. It delivers a production-ready service with a convenient API to connect, authenticate, and orchestrate agents across distributed systems using open protocols: A2A, AP2, and X402. Built with a distributed architecture, Bindu makes it fast to develop and easy to integrate with any AI framework. Transform any agent framework into a fully interoperable service for communication, collaboration, and commerce in the Internet of Agents.

Scrapegraph-ai
ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.
client-python
The Mistral Python Client is a tool inspired by cohere-python that allows users to interact with the Mistral AI API. It provides functionalities to access and utilize the AI capabilities offered by Mistral. Users can easily install the client using pip and manage dependencies using poetry. The client includes examples demonstrating how to use the API for various tasks, such as chat interactions. To get started, users need to obtain a Mistral API Key and set it as an environment variable. Overall, the Mistral Python Client simplifies the integration of Mistral AI services into Python applications.
For similar tasks
chatflow
Chatflow is a tool that provides a chat interface for users to interact with systems using natural language. The engine understands user intent and executes commands for tasks, allowing easy navigation of complex websites/products. This approach enhances user experience, reduces training costs, and boosts productivity.
AiR
AiR is an AI tool built entirely in Rust that delivers blazing speed and efficiency. It features accurate translation and seamless text rewriting to supercharge productivity. AiR is designed to assist non-native speakers by automatically fixing errors and polishing language to sound like a native speaker. The tool is under heavy development with more features on the horizon.
awesome-ai-newsletters
Awesome AI Newsletters is a curated list of AI-related newsletters that provide the latest news, trends, tools, and insights in the field of Artificial Intelligence. It includes a variety of newsletters covering general AI news, prompts for marketing and productivity, AI job opportunities, and newsletters tailored for professionals in the AI industry. Whether you are a beginner looking to stay updated on AI advancements or a professional seeking to enhance your knowledge and skills, this repository offers a collection of valuable resources to help you navigate the world of AI.
ollama-autocoder
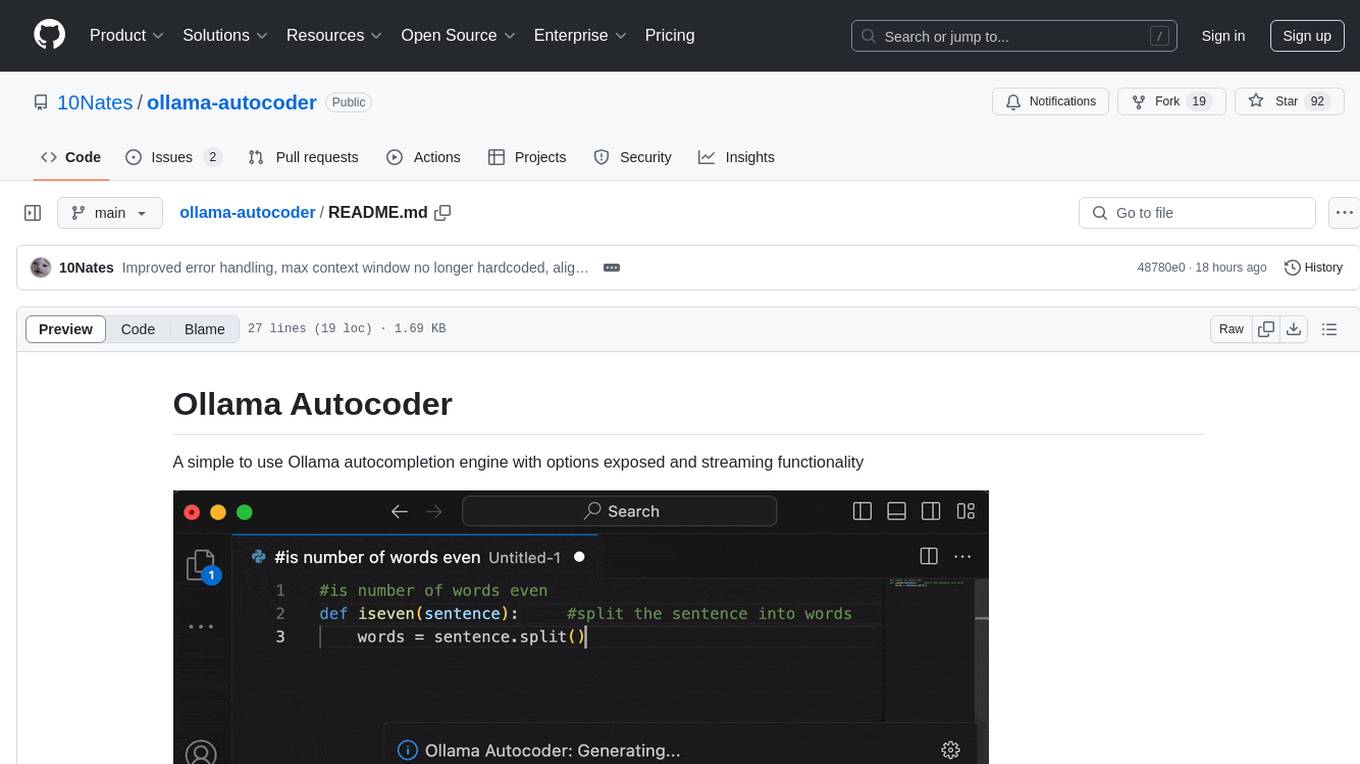
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.
witsy
Witsy is a generative AI desktop application that supports various models like OpenAI, Ollama, Anthropic, MistralAI, Google, Groq, and Cerebras. It offers features such as chat completion, image generation, scratchpad for content creation, prompt anywhere functionality, AI commands for productivity, expert prompts for specialization, LLM plugins for additional functionalities, read aloud capabilities, chat with local files, transcription/dictation, Anthropic Computer Use support, local history of conversations, code formatting, image copy/download, and more. Users can interact with the application to generate content, boost productivity, and perform various AI-related tasks.
codegate
CodeGate is a local gateway that enhances the safety of AI coding assistants by ensuring AI-generated recommendations adhere to best practices, safeguarding code integrity, and protecting individual privacy. Developed by Stacklok, CodeGate allows users to confidently leverage AI in their development workflow without compromising security or productivity. It works seamlessly with coding assistants, providing real-time security analysis of AI suggestions. CodeGate is designed with privacy at its core, keeping all data on the user's machine and offering complete control over data.

cline-based-code-generator
HAI Code Generator is a cutting-edge tool designed to simplify and automate task execution while enhancing code generation workflows. Leveraging Specif AI, it streamlines processes like task execution, file identification, and code documentation through intelligent automation and AI-driven capabilities. Built on Cline's powerful foundation for AI-assisted development, HAI Code Generator boosts productivity and precision by automating task execution and integrating file management capabilities. It combines intelligent file indexing, context generation, and LLM-driven automation to minimize manual effort and ensure task accuracy. Perfect for developers and teams aiming to enhance their workflows.
Skills-Manager
Skills Manager is a unified desktop application designed to centralize and manage AI coding assistant skills for tools like Claude Code, Codex, and Opencode. It offers smart synchronization, granular control, high performance, cross-platform support, multi-tool compatibility, custom tools integration, and a modern UI. Users can easily organize, sync, and share their skills across different AI tools, enhancing their coding experience and productivity.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.