Best AI tools for< Translate Speech >
12 - AI tool Sites
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
Gladia
Gladia provides a fast and accurate way to turn unstructured audio data into valuable business knowledge. Its Audio Intelligence API helps capture, enrich, and leverage hidden insights in audio data, powered by optimized Whisper ASR. Key features include highly accurate audio and video transcription, speech-to-text translation in 99 languages, in-depth insights with add-ons, and secure hosting options. Gladia's AI transcription and multilingual audio intelligence features enhance user experience and boost retention in various industries, including content and media, virtual meetings, workspace collaboration, and call centers. Developers can easily integrate cutting-edge AI into their products without AI expertise or setup costs.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
SpeakShift
SpeakShift is a language translation business that provides a comprehensive suite of software and solutions that enable real-time translation of speech, video, and live streaming presentations. Their AI-powered voice translation technology enables seamless communication between people who speak different languages. SpeakShift's video dubbing services make it easy to create multilingual content that resonates with viewers worldwide. Their perception-enabled language analytics technology provides real-time insights about the language used in your content.
Interpre-X
Interpre-X is a real-time speech translation tool powered by AI. It offers speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation in over 10 languages. Interpre-X is designed to break down language barriers and facilitate communication between people who speak different languages. It is suitable for both personal and professional use, and it can be used in a variety of settings, such as travel, business meetings, and language learning.

NNAT
NNAT is a near-native artificial translator chat widget that can help you communicate with people from all over the world. With NNAT, you can easily translate text and speech in real-time, making it easy to have conversations with people who speak different languages. NNAT is also able to learn and adapt to your specific needs, so the more you use it, the better it will become at translating for you.
Shook
Shook is an app that allows you to hear your voice in different languages. It is a fun and easy way to learn new languages or to simply hear how your voice sounds in a different language.

OdiaGenAI
OdiaGenAI is a collaborative initiative focused on conducting research on Generative AI and Large Language Models (LLM) for the Odia Language. The project aims to leverage AI technology to develop Generative AI and LLM-based solutions for the overall development of Odisha and the Odia language through collaboration among Odia technologists. The initiative offers pre-trained models, codes, and datasets for non-commercial and research purposes, with a focus on building language models for Indic languages like Odia and Bengali.
Woy AI Tools
Woy AI Tools is a free AI voice cloning application that allows users to instantly clone voices with high similarity and realism. Users can upload a 10-second voice sample to generate and download cloned voices in multiple languages and accents. The tool ensures secure privacy and offers a simple interface for easy usage.
Reka
Reka is a cutting-edge AI application offering next-generation multimodal AI models that empower agents to see, hear, and speak. Their flagship model, Reka Core, competes with industry leaders like OpenAI and Google, showcasing top performance across various evaluation metrics. Reka's models are natively multimodal, capable of tasks such as generating textual descriptions from videos, translating speech, answering complex questions, writing code, and more. With advanced reasoning capabilities, Reka enables users to solve a wide range of complex problems. The application provides end-to-end support for 32 languages, image and video comprehension, multilingual understanding, tool use, function calling, and coding, as well as speech input and output.
Aya Data
Aya Data is an AI tool that offers services such as data annotation, computer vision, natural language annotation, 3D annotation, AI data acquisition, and AI consulting. They provide cutting-edge tools to transform raw data into training datasets for AI models, deliver bespoke AI solutions for various industries, and offer AI-powered products like AyaGrow for crop management and AyaSpeech for speech-to-speech translation. Aya Data focuses on exceptional accuracy, rapid development cycles, and high performance in real-world scenarios.
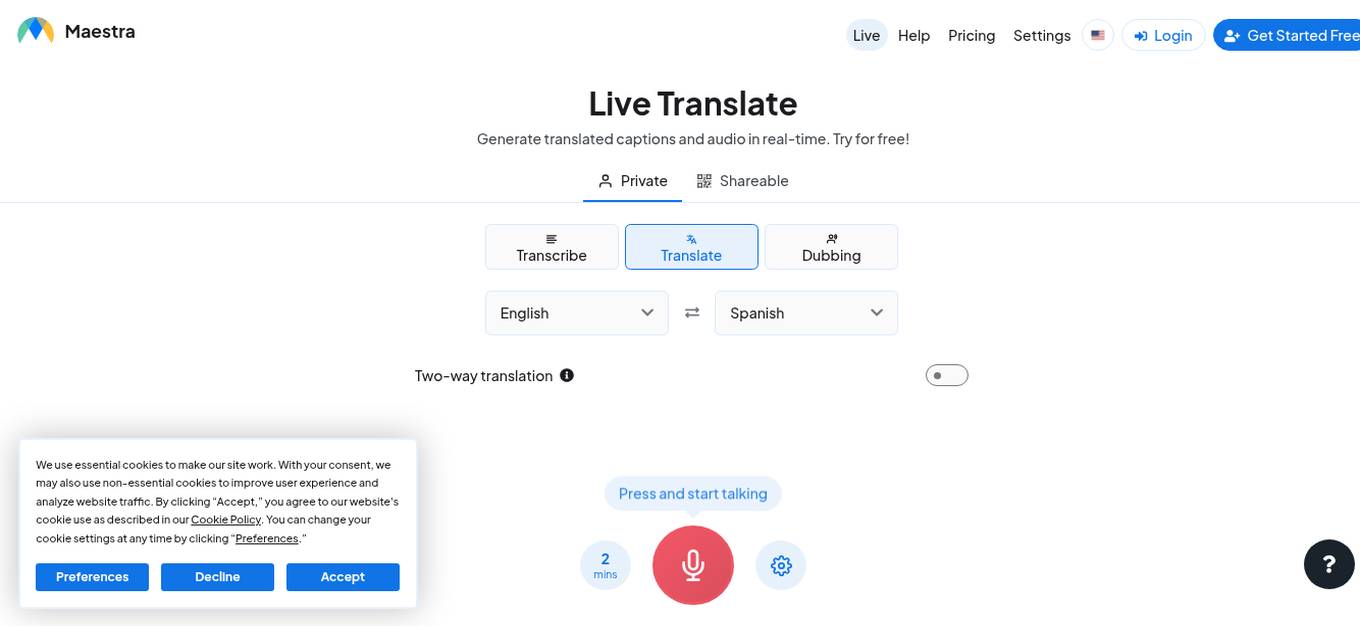
Maestra
Maestra is a real-time online voice translator that generates translated captions and audio instantly. It offers features like private shareable transcriptions, dubbing in multiple languages, two-way translation, and multi-speaker support. Maestra provides various pricing plans catering to different needs, including live event captioning, live support, and custom pricing options. Users can access their accounts from different devices, and the platform ensures secure payments through Stripe. The tool supports automatic language detection, diarization of multiple speakers, and custom dictionary for improved accuracy. Maestra is trusted by individuals and teams for its excellent AI translation services.
4 - Open Source AI Tools

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
20 - OpenAI Gpts

Ultimate Translator
Speak, snap, and understand the world. Your pocket-sized translator deciphers docs, images, and speech in a heartbeat with pronunciation guides and motivational boosts!

Cat Translator
Your Feline Language Specialist for translating human speech to cat sounds.
Animal Translator
Your expert in translating human speech into animal languages, with a playful and educational twist.
Tsugaruben Translator
Translates Japanese to Tsugaru-ben for academic and business contexts.

Universal Bilingual Translator
The universal bilingual translation GPT is suitable for dialogue between different languages, simultaneous interpretation, and other speaking scenarios. Starts with a pair of language name, such as "Chinese English", "English French"
