
MicroLens
A Large Short-video Recommendation Dataset with Raw Text/Audio/Image/Videos (Talk Invited by DeepMind).
Stars: 155
MicroLens is a content-driven micro-video recommendation dataset at scale. It provides a large dataset with multimodal data, including raw text, images, audio, video, and video comments, for tasks such as multi-modal recommendation, foundation model building, and fairness recommendation. The dataset is available in two versions: MicroLens-50K and MicroLens-100K, with extracted features for multimodal recommendation tasks. Researchers can access the dataset through provided links and reach out to the corresponding author for the complete dataset. The repository also includes codes for various algorithms like VideoRec, IDRec, and VIDRec, each implementing different video models and baselines.
README:
Quick Links: 🗃️Dataset | 📭Citation | 🛠️Code | 🚀Baseline Evaluation | 🤗Video Understanding Meets Recommender Systems | 💡News
Talks & Slides: Invited Talk by Google DeepMind & YouTube & Alipay (Slides)
Download links: https://recsys.westlake.edu.cn/MicroLens-50k-Dataset/ and https://recsys.westlake.edu.cn/MicroLens-100k-Dataset/
Email us if you find the link is not available.

-
🚀2025/01/27: We release MicroLens-1M to support the Multimodal Information Retrieval Challenge (MIRC) at WWW 2025! Please see MicroLens_1M_MMCTR and MIRC for more details!
-
💡2025/01/26: We have fixed the value error of "likes_and_views" data, please see MicroLens-50k_likes_and_views.txt and MicroLens-100k_likes_and_views.txt.
-
💡2024/05/31: The "like" and "view" data for each video has been uploaded, please see MicroLens-50k_likes_and_views.txt and MicroLens-100k_likes_and_views.txt.
-
🚀2024/04/15: Our dataset has been added to the MMRec framework! Please see https://github.com/enoche/MMRec/tree/master/data for more details!
-
💡2024/04/04: We have provided extracted multi-modal features (text/images/videos) of MicroLens-100k for multimodal recommendation tasks, see https://recsys.westlake.edu.cn/MicroLens-100k-Dataset/extracted_modality_features/. The preprocessed code is uploaded, see video_feature_extraction_(from_lmdb).py.
-
💡2024/03/01: We have updated the command example for automatically downloading all videos, see https://github.com/westlake-repl/MicroLens/blob/master/Downloader/quick_download.txt.
-
💡2023/10/21: We also release a subset of our MicroLens with extracted features for multimodal fairness recommendation, which can be downloaded from https://recsys.westlake.edu.cn/MicroLens-Fairness-Dataset/
-
💡2023/09/28: We have temporarily released MicroLens-50K (50,000 users) and MicroLens-100K (100,000 users) along with their associated multimodal data, including raw text, images, audio, video, and video comments. You can access them through the provided link. To acquire the complete MicroLens dataset, kindly reach out to the corresponding author via email. If you have an innovative idea for building a foundational recommendation model but require a large dataset and computational resources, consider joining our lab as an intern. We can provide access to 100 NVIDIA 80G A100 GPUs and a billion-level dataset of user-video/image/text interactions.
If you use our dataset, code or find MicroLens useful in your work, please cite our paper as:
@article{ni2023content,
title={A Content-Driven Micro-Video Recommendation Dataset at Scale},
author={Ni, Yongxin and Cheng, Yu and Liu, Xiangyan and Fu, Junchen and Li, Youhua and He, Xiangnan and Zhang, Yongfeng and Yuan, Fajie},
journal={arXiv preprint arXiv:2309.15379},
year={2023}
}
⚠️ Caution: It's prohibited to privately modify the dataset and then offer secondary downloads. If you've made alterations to the dataset in your work, you are encouraged to open-source the data processing code, so others can benefit from your methods. Or notify us of your new dataset so we can put it on this Github with your paper.
We have released the codes for all algorithms, including VideoRec (which implements all 15 video models in this project), IDRec, and VIDRec. For more details, please refer to the following paths: "Code/VideoRec", "Code/IDRec", and "Code/VIDRec". Each folder contains multiple subfolders, with each subfolder representing the code for a baseline.
In VideoRec, if you wish to switch to a different training mode, please execute the following Python scripts: 'run_id.py', 'run_text.py', 'run_image.py', and 'run_video.py'. For testing, you can use 'run_id_test.py', 'run_text_test.py', 'run_image_test.py', and 'run_video_test.py', respectively. Please see the path "Code/VideoRec/SASRec" for more details.
Before running the training script, please make sure to modify the dataset path, item encoder, pretrained model path, GPU devices, GPU numbers, and hyperparameters. Additionally, remember to specify the best validation checkpoint (e.g., 'epoch-30.pt') before running the test script.
Note that you will need to prepare an LMDB file and specify it in the scripts before running image-based or video-based VideoRec. To assist with this, we have provided a Python script for LMDB generation. Please refer to 'Data Generation/generate_cover_frames_lmdb.py' for more details.
In IDRec, see IDRec\process_data.ipynb to process the interaction data. Execute the following Python scripts: 'main.py' under each folder to run the corresponding baselines. The data path, model parameters can be modified by changing the yaml file under each folder.
python==3.8.12
Pytorch==1.8.0
cudatoolkit==11.1
torchvision==0.9.0
transformers==4.23.1


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MicroLens
Similar Open Source Tools
MicroLens
MicroLens is a content-driven micro-video recommendation dataset at scale. It provides a large dataset with multimodal data, including raw text, images, audio, video, and video comments, for tasks such as multi-modal recommendation, foundation model building, and fairness recommendation. The dataset is available in two versions: MicroLens-50K and MicroLens-100K, with extracted features for multimodal recommendation tasks. Researchers can access the dataset through provided links and reach out to the corresponding author for the complete dataset. The repository also includes codes for various algorithms like VideoRec, IDRec, and VIDRec, each implementing different video models and baselines.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
ha-llmvision
LLM Vision is a Home Assistant integration that allows users to analyze images, videos, and camera feeds using multimodal LLMs. It supports providers such as OpenAI, Anthropic, Google Gemini, LocalAI, and Ollama. Users can input images and videos from camera entities or local files, with the option to downscale images for faster processing. The tool provides detailed instructions on setting up LLM Vision and each supported provider, along with usage examples and service call parameters.

NineRec
NineRec is a benchmark dataset suite for evaluating transferable recommendation models. It provides datasets for pre-training and transfer learning in recommender systems, focusing on multimodal and foundation model tasks. The dataset includes user-item interactions, item texts in multiple languages, item URLs, and raw images. Researchers can use NineRec to develop more effective and efficient methods for pre-training recommendation models beyond end-to-end training. The dataset is accompanied by code for dataset preparation, training, and testing in PyTorch environment.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

ChatDev
ChatDev is a virtual software company powered by intelligent agents like CEO, CPO, CTO, programmer, reviewer, tester, and art designer. These agents collaborate to revolutionize the digital world through programming. The platform offers an easy-to-use, highly customizable, and extendable framework based on large language models, ideal for studying collective intelligence. ChatDev introduces innovative methods like Iterative Experience Refinement and Experiential Co-Learning to enhance software development efficiency. It supports features like incremental development, Docker integration, Git mode, and Human-Agent-Interaction mode. Users can customize ChatChain, Phase, and Role settings, and share their software creations easily. The project is open-source under the Apache 2.0 License and utilizes data licensed under CC BY-NC 4.0.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

datasets
Datasets is a repository that provides a collection of various datasets for machine learning and data analysis projects. It includes datasets in different formats such as CSV, JSON, and Excel, covering a wide range of topics including finance, healthcare, marketing, and more. The repository aims to help data scientists, researchers, and students access high-quality datasets for training models, conducting experiments, and exploring data analysis techniques.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.

CogAgent
CogAgent is an advanced intelligent agent model designed for automating operations on graphical interfaces across various computing devices. It supports platforms like Windows, macOS, and Android, enabling users to issue commands, capture device screenshots, and perform automated operations. The model requires a minimum of 29GB of GPU memory for inference at BF16 precision and offers capabilities for executing tasks like sending Christmas greetings and sending emails. Users can interact with the model by providing task descriptions, platform specifications, and desired output formats.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.

swiftide
Swiftide is a fast, streaming indexing and query library tailored for Retrieval Augmented Generation (RAG) in AI applications. It is built in Rust, utilizing parallel, asynchronous streams for blazingly fast performance. With Swiftide, users can easily build AI applications from idea to production in just a few lines of code. The tool addresses frustrations around performance, stability, and ease of use encountered while working with Python-based tooling. It offers features like fast streaming indexing pipeline, experimental query pipeline, integrations with various platforms, loaders, transformers, chunkers, embedders, and more. Swiftide aims to provide a platform for data indexing and querying to advance the development of automated Large Language Model (LLM) applications.
For similar tasks
MicroLens
MicroLens is a content-driven micro-video recommendation dataset at scale. It provides a large dataset with multimodal data, including raw text, images, audio, video, and video comments, for tasks such as multi-modal recommendation, foundation model building, and fairness recommendation. The dataset is available in two versions: MicroLens-50K and MicroLens-100K, with extracted features for multimodal recommendation tasks. Researchers can access the dataset through provided links and reach out to the corresponding author for the complete dataset. The repository also includes codes for various algorithms like VideoRec, IDRec, and VIDRec, each implementing different video models and baselines.
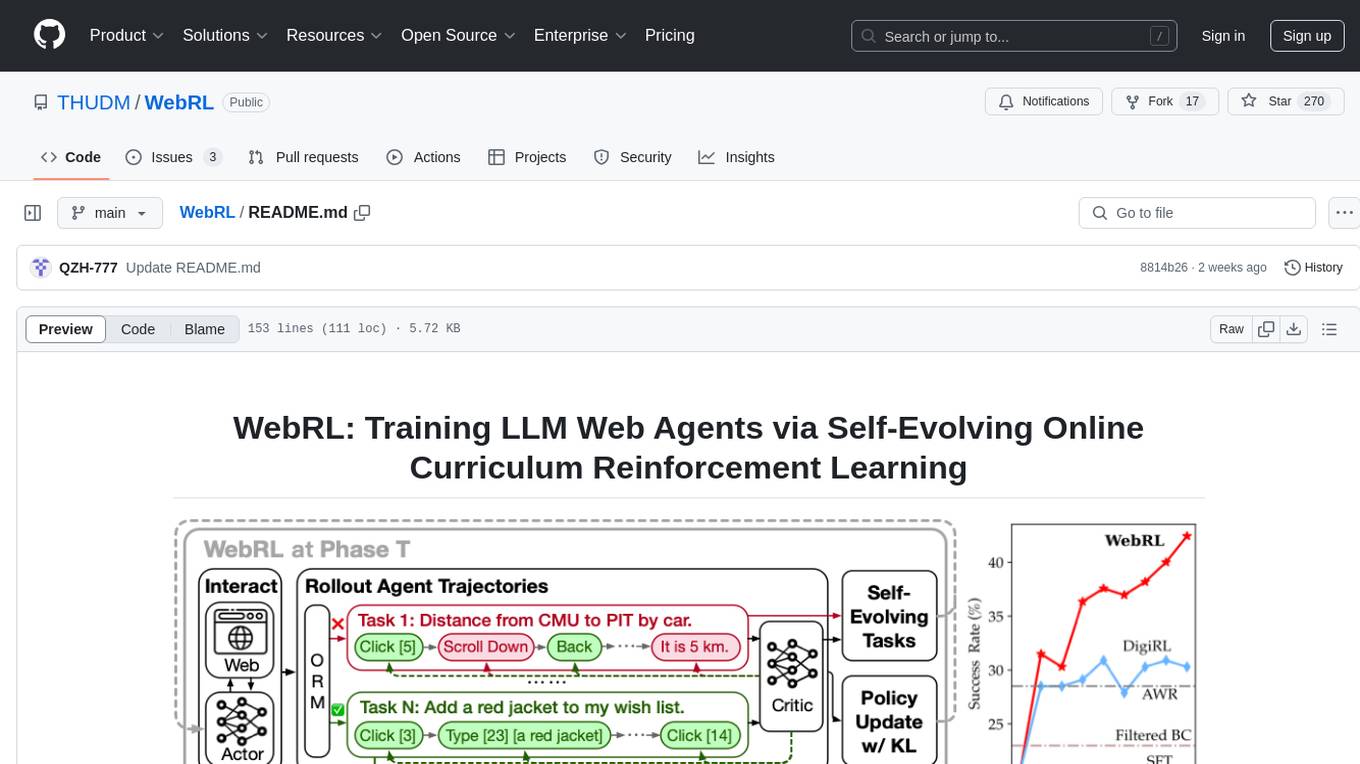
WebRL
WebRL is a self-evolving online curriculum learning framework designed for training web agents in the WebArena environment. It provides model checkpoints, training instructions, and evaluation processes for training the actor and critic models. The tool enables users to generate new instructions and interact with WebArena to configure tasks for training and evaluation.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.