Best AI tools for< Run Training Scripts >
20 - AI tool Sites
NVIDIA Run:ai
NVIDIA Run:ai is an enterprise platform for AI workloads and GPU orchestration. It accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. The platform significantly enhances GPU efficiency and workload capacity by pooling resources across environments and utilizing advanced orchestration. NVIDIA Run:ai provides unparalleled flexibility and adaptability, supporting public clouds, private clouds, hybrid environments, or on-premises data centers.
Sessions
Sessions is a cloud-based video conferencing and webinar platform that offers a range of features to help businesses run successful online meetings and events. With Sessions, users can create interactive agendas, share screens, record meetings, and host webinars with up to 1000 participants. Sessions also integrates with a variety of third-party tools, including Google Drive, Dropbox, and Slack, making it easy to collaborate with colleagues and share files. Additionally, Sessions offers a number of AI-powered features, such as automatic transcription and translation, to help users get the most out of their meetings.
Stablematic
Stablematic is a web-based platform that allows users to run Stable Diffusion and other machine learning models without the need for local setup or hardware limitations. It provides a user-friendly interface, pre-installed plugins, and dedicated GPU resources for a seamless and efficient workflow. Users can generate images and videos from text prompts, merge multiple models, train custom models, and access a range of pre-trained models, including Dreambooth and CivitAi models. Stablematic also offers API access for developers and dedicated support for users to explore and utilize the capabilities of Stable Diffusion and other machine learning models.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
Paperspace
Paperspace is an AI tool designed to develop, train, and deploy AI models of any size and complexity. It offers a cloud GPU platform for accelerated computing, with features such as GPU cloud workflows, machine learning solutions, GPU infrastructure, virtual desktops, gaming, rendering, 3D graphics, and simulation. Paperspace provides a seamless abstraction layer for individuals and organizations to focus on building AI applications, offering low-cost GPUs with per-second billing, infrastructure abstraction, job scheduling, resource provisioning, and collaboration tools.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
Synthace
Synthace is a software and expertise platform designed for Discovery Biology Teams to streamline and optimize their experiments in assay development, media optimization, and purification process development. The platform offers software solutions, training, and on-site support from specialists to help scientists conduct experiments more efficiently and effectively. By leveraging multifactorial methods and automation, Synthace aims to accelerate drug discovery processes and deliver faster, definitive results.
AI Art Generator
AI Art Generator is an online platform that leverages state-of-the-art Stable Diffusion technology to quickly turn users' imaginations into amazing artistic creations with just simple text prompts. Users can create unique images by providing text descriptions, and the AI model generates original artworks in seconds. The platform allows anyone to easily create stunning AI-generated artworks without needing artistic skills or training. AI Art Generator aims to provide a seamless and creative experience for users to explore the future of art through advanced technology.
RunPod
RunPod is a cloud platform specifically designed for AI development and deployment. It offers a range of features to streamline the process of developing, training, and scaling AI models, including a library of pre-built templates, efficient training pipelines, and scalable deployment options. RunPod also provides access to a wide selection of GPUs, allowing users to choose the optimal hardware for their specific AI workloads.
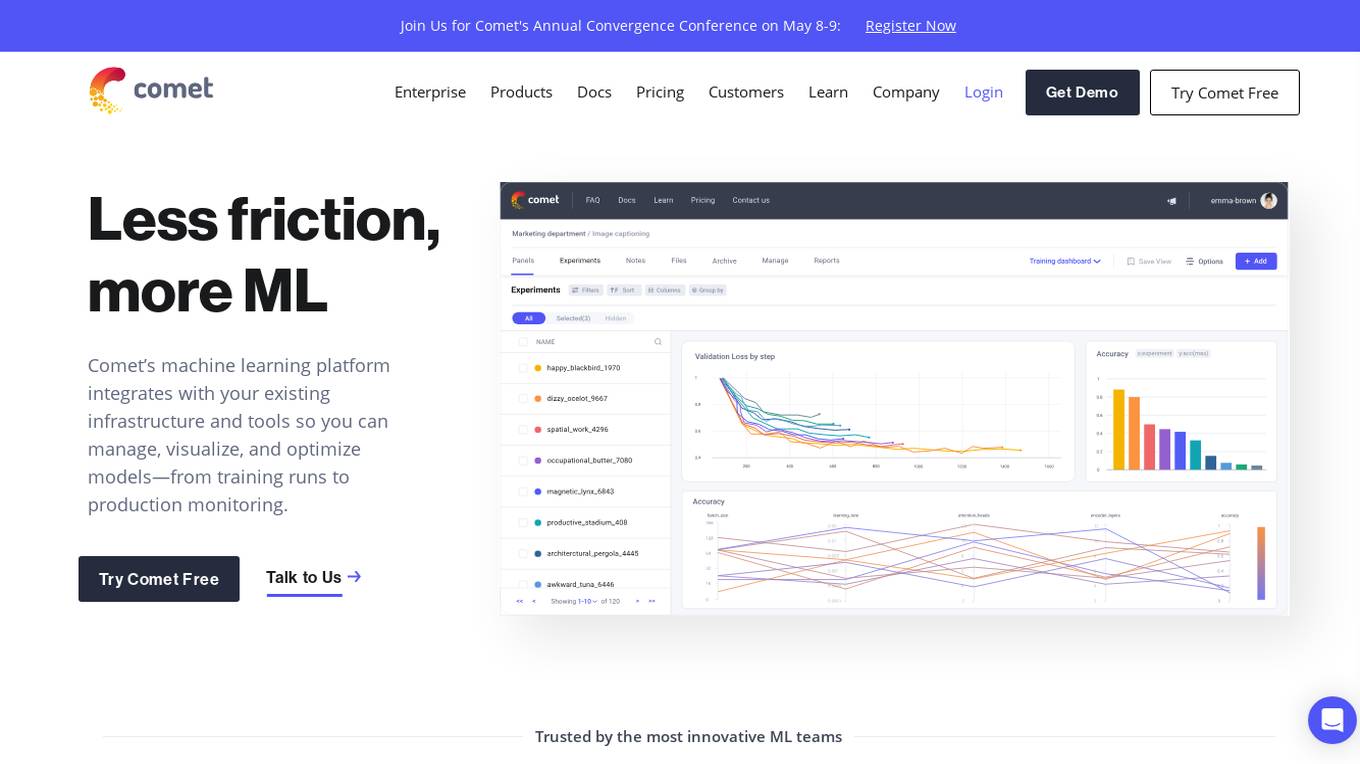
Comet ML
Comet ML is an extensible, fully customizable machine learning platform that aims to move ML forward by supporting productivity, reproducibility, and collaboration. It integrates with existing infrastructure and tools to manage, visualize, and optimize models from training runs to production monitoring. Users can track and compare training runs, create a model registry, and monitor models in production all in one platform. Comet's platform can be run on any infrastructure, enabling users to reshape their ML workflow and bring their existing software and data stack.
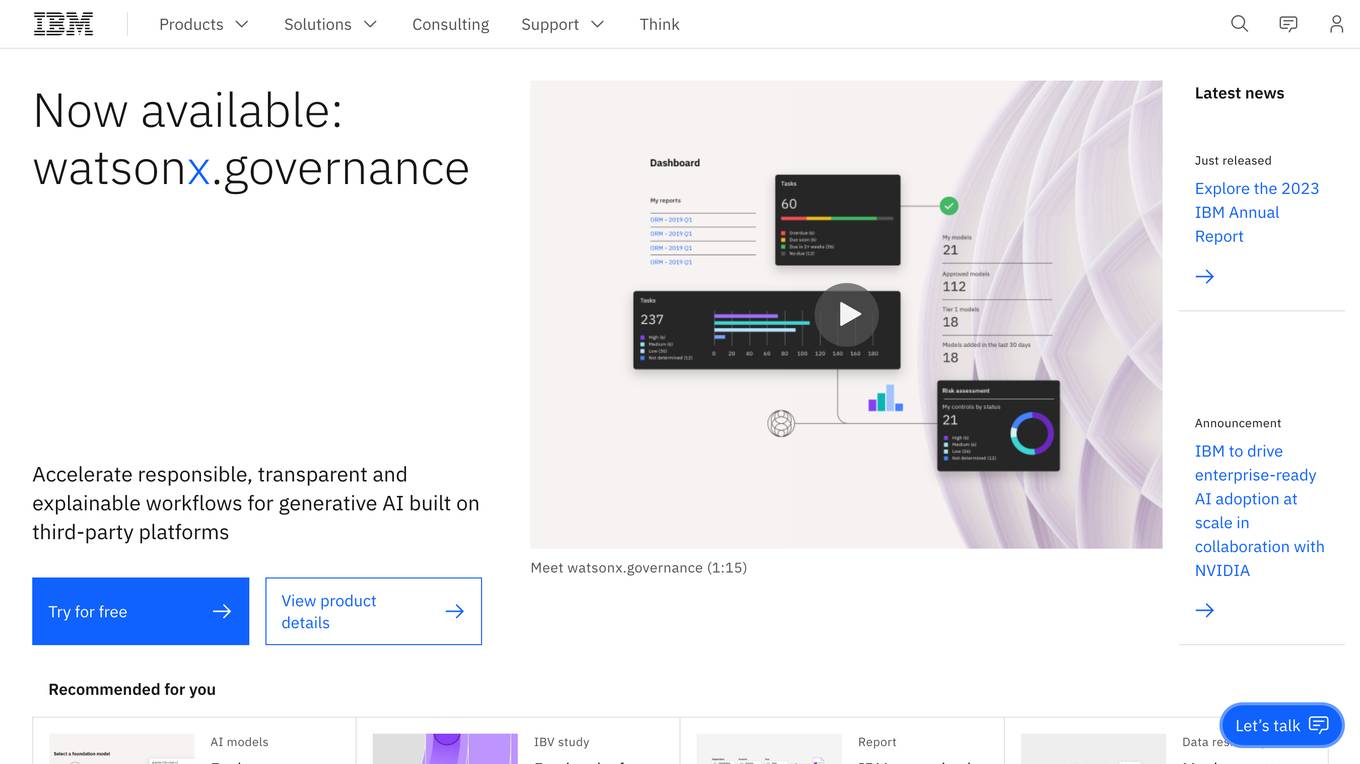
IBM
IBM is a leading technology company that offers a wide range of AI and machine learning solutions to help businesses innovate and grow. From AI models to cloud services, IBM provides cutting-edge technology to address various business challenges. The company also focuses on AI ethics and offers training programs to enhance skills in cybersecurity and data analytics. With a strong emphasis on research and development, IBM continues to push the boundaries of technology to solve real-world problems and drive digital transformation across industries.
Skim AI
Skim AI is a machine learning and artificial intelligence solution that provides custom AI and ML solutions to help businesses make better decisions. The platform offers services such as AI advisory, AI development, and AI as a service, catering to various industries from media to medical, content creation to crypto & blockchain. Skim AI aims to make AI and ML accessible to all sectors, even for those with limited knowledge in the field. The platform also offers training options for users who prefer to manage AI operations themselves.
Machinet
Machinet is an AI Agent designed for full-stack software developers. It serves as an AI-based IDE that assists developers in various tasks, such as code generation, terminal access, front-end debugging, architecture suggestions, refactoring, and mentoring. The tool aims to enhance productivity and streamline the development workflow by providing intelligent assistance and support throughout the coding process. Machinet prioritizes security and privacy, ensuring that user data is encrypted, secure, and never stored for training purposes.
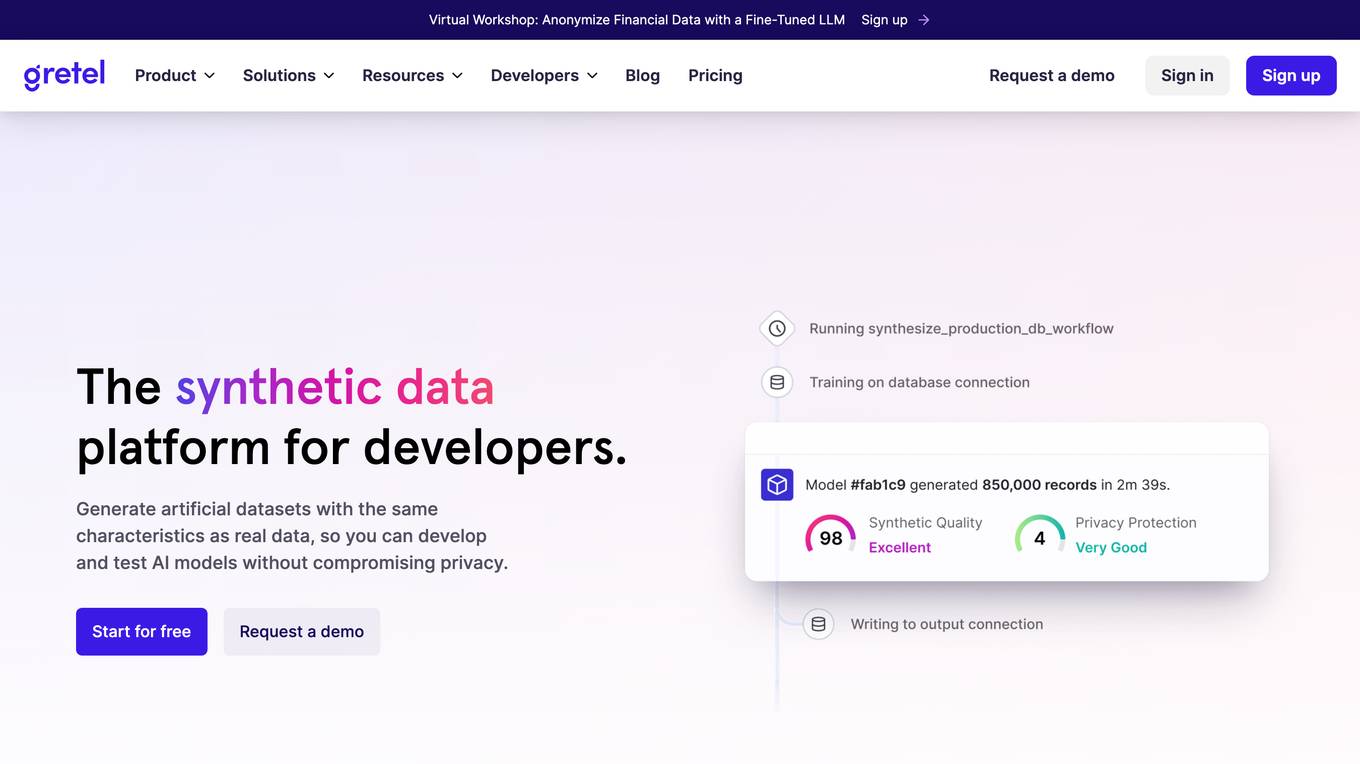
Gretel.ai
Gretel.ai is a synthetic data platform purpose-built for AI applications. It allows users to generate artificial, synthetic datasets with the same characteristics as real data, enabling the improvement of AI models without compromising privacy. The platform offers APIs for generating anonymized and safe synthetic data, training generative AI models, and validating models with quality and privacy scores. Users can deploy Gretel for enterprise use cases and run it on various cloud platforms or in their own environment.
Run Recommender
The Run Recommender is a web-based tool that helps runners find the perfect pair of running shoes. It uses a smart algorithm to suggest options based on your input, giving you a starting point in your search for the perfect pair. The Run Recommender is designed to be user-friendly and easy to use. Simply input your shoe width, age, weight, and other details, and the Run Recommender will generate a list of potential shoes that might suit your running style and body. You can also provide information about your running experience, distance, and frequency, and the Run Recommender will use this information to further refine its suggestions. Once you have a list of potential shoes, you can click on each shoe to learn more about it, including its features, benefits, and price. You can also search for the shoe on Amazon to find the best deals.
Practice Run AI
Practice Run AI is an online platform that offers AI-powered tools for various tasks. Users can utilize the application to practice and run AI algorithms without the need for complex setups or installations. The platform provides a user-friendly interface that allows individuals to experiment with AI models and enhance their understanding of artificial intelligence concepts. Practice Run AI aims to democratize AI education and make it accessible to a wider audience by simplifying the learning process and providing hands-on experience.
Dora
Dora is a no-code 3D animated website design platform that allows users to create stunning 3D and animated visuals without writing a single line of code. With Dora, designers, freelancers, and creative professionals can focus on what they do best: designing. The platform is tailored for professionals who prioritize design aesthetics without wanting to dive deep into the backend. Dora offers a variety of features, including a drag-and-connect constraint layout system, advanced animation capabilities, and pixel-perfect usability. With Dora, users can create responsive 3D and animated websites that translate seamlessly across devices.
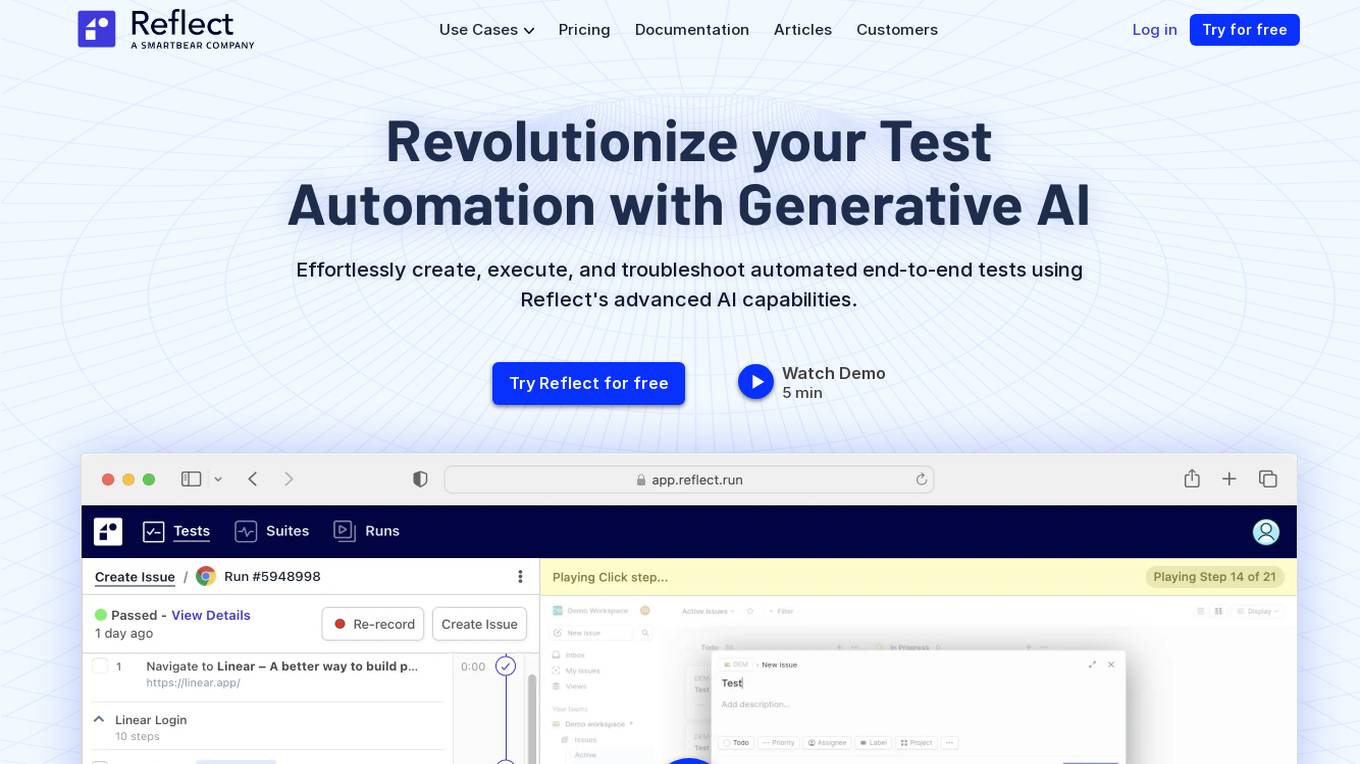
Reflect
Reflect is an AI-powered test automation tool that revolutionizes the way end-to-end tests are created, executed, and maintained. By leveraging Generative AI, Reflect eliminates the need for manual coding and provides a seamless testing experience. The tool offers features such as no-code test automation, visual testing, API testing, cross-browser testing, and more. Reflect aims to help companies increase software quality by accelerating testing processes and ensuring test adaptability over time.

Error Handling Application
The website is currently experiencing an application error, indicating a server-side exception. Users encountering this error are advised to check the server logs for more information. The error digest number provided is 3308662818.
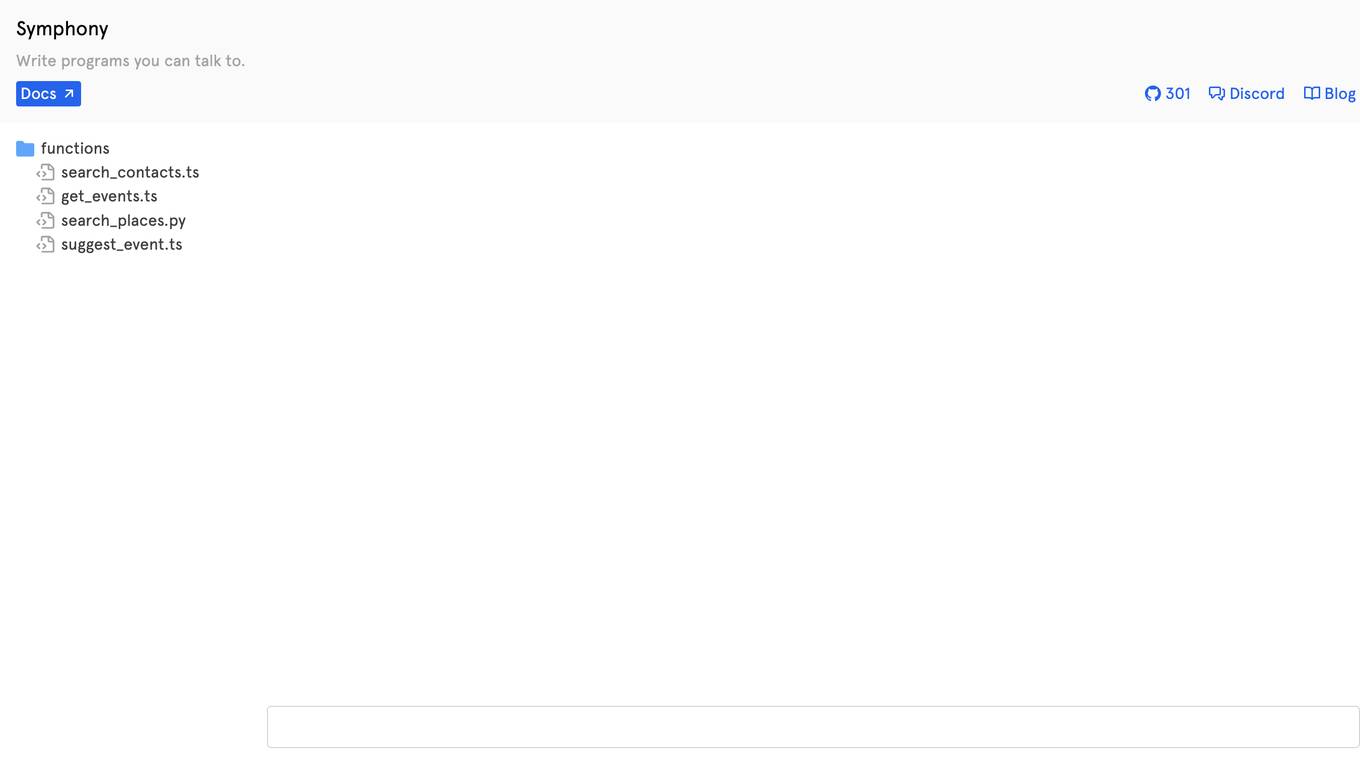
Symphony
Symphony is a platform that allows users to write programs using natural language. It enables users to interact with the system by talking to it, making programming more accessible and intuitive. Symphony simplifies the process of coding by translating spoken commands into executable code, providing a user-friendly programming experience.
1 - Open Source AI Tools
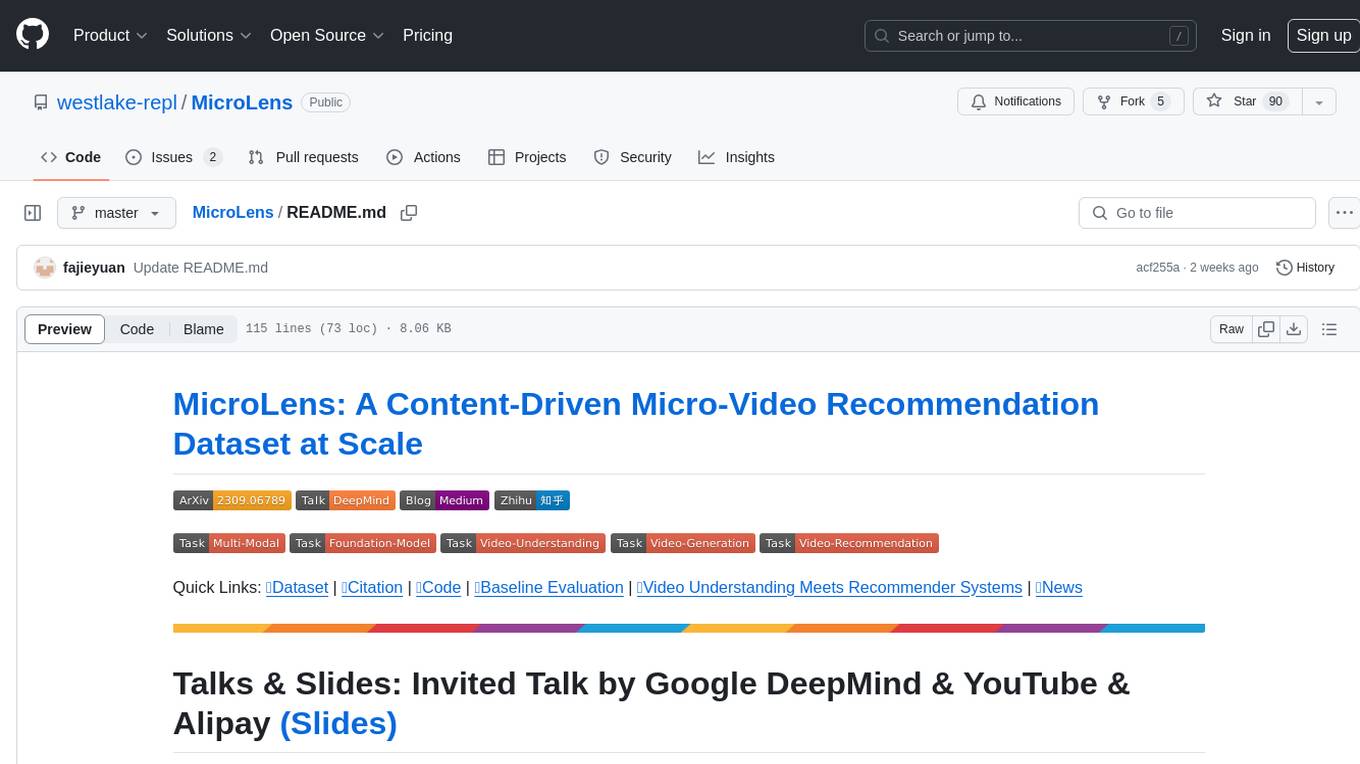
MicroLens
MicroLens is a content-driven micro-video recommendation dataset at scale. It provides a large dataset with multimodal data, including raw text, images, audio, video, and video comments, for tasks such as multi-modal recommendation, foundation model building, and fairness recommendation. The dataset is available in two versions: MicroLens-50K and MicroLens-100K, with extracted features for multimodal recommendation tasks. Researchers can access the dataset through provided links and reach out to the corresponding author for the complete dataset. The repository also includes codes for various algorithms like VideoRec, IDRec, and VIDRec, each implementing different video models and baselines.
20 - OpenAI Gpts

Consulting & Investment Banking Interview Prep GPT
Run mock interviews, review content and get tips to ace strategy consulting and investment banking interviews

Dungeon Master's Assistant
Your new DM's screen: helping Dungeon Masters to craft & run amazing D&D adventures.
Database Builder
Hosts a real SQLite database and helps you create tables, make schema changes, and run SQL queries, ideal for all levels of database administration.
Restaurant Startup Guide
Meet the Restaurant Startup Guide GPT: your friendly guide in the restaurant biz. It offers casual, approachable advice to help you start and run your own restaurant with ease.

Community Design™
A community-building GPT based on the wildly popular Community Design™ framework from Mighty Networks. Start creating communities that run themselves.
Code Helper for Web Application Development
Friendly web assistant for efficient code. Ask the wizard to create an application and you will get the HTML, CSS and Javascript code ready to run your web application.

Creative Director GPT
I'm your brainstorm muse in marketing and advertising; the creativity machine you need to sharpen the skills, land the job, generate the ideas, win the pitches, build the brands, ace the awards, or even run your own agency. Psst... don't let your clients find out about me! 😉
Pace Assistant
Provides running splits for Strava Routes, accounting for distance and elevation changes