
autobe
AI Vibe Coding Agent of TS backend server, enhanced by compiler skills, generating 100% working code
Stars: 642
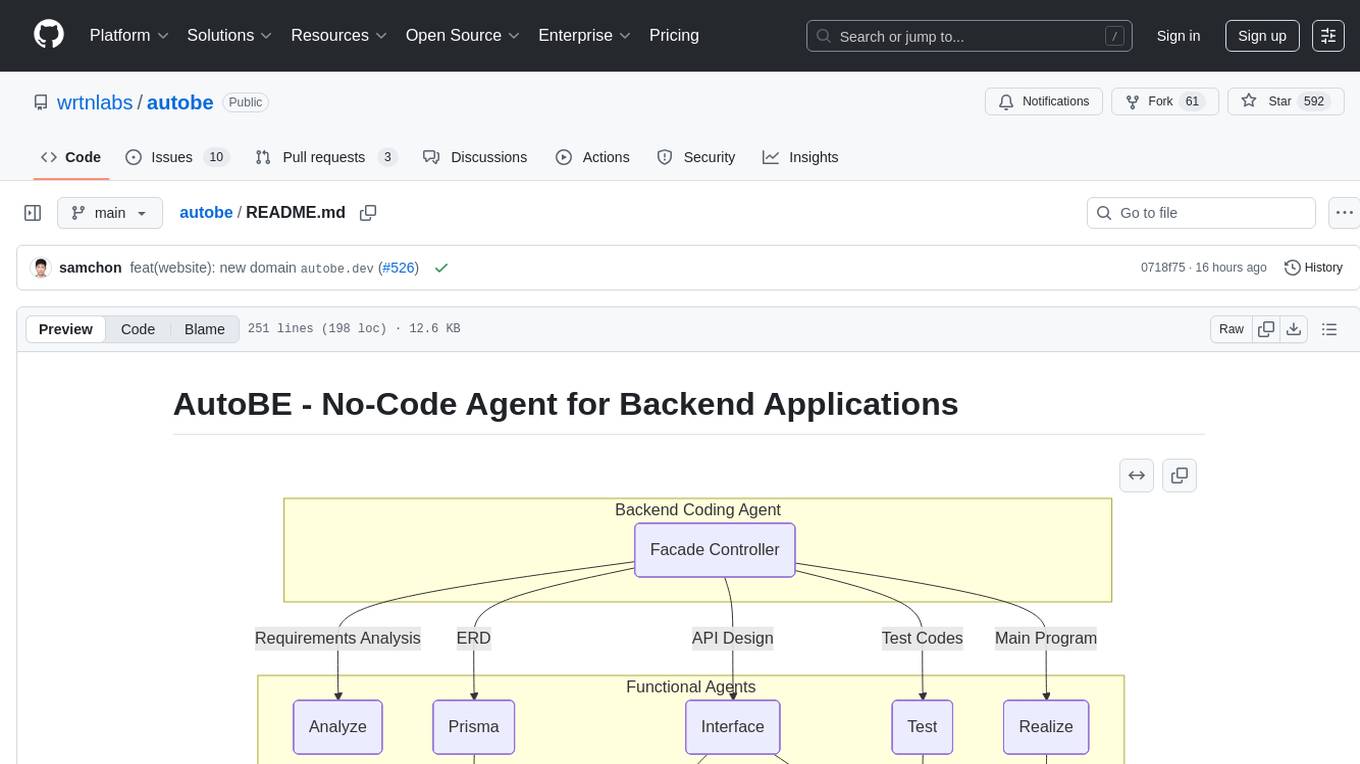
AutoBE is an AI-powered no-code agent that builds backend applications, enhanced by compiler feedback. It automatically generates backend applications using TypeScript, NestJS, and Prisma following a waterfall development model. The generated code is validated by review agents and OpenAPI/TypeScript/Prisma compilers, ensuring 100% working code. The tool aims to enable anyone to build backend servers, AI chatbots, and frontend applications without coding knowledge by conversing with AI.
README:


![]()
Describe your backend requirements in natural language through AutoBE's chat interface.
AutoBE will analyze your requirements and build the backend application for you. The generated backend application is designed to be 100% buildable by AI-friendly compilers and ensures stability through powerful e2e test functions.
With such AutoBE, build your first backend application quickly, then maintain and extend it with AI code assistants like Claude Code for enhanced productivity and stability.
AutoBE will generate complete specifications, detailed database and API documentation, comprehensive test coverage for stability, and clean implementation logic that serves as a learning foundation for juniors while significantly improving senior developer productivity.
Check out these complete backend application examples generated by AutoBE:
https://github.com/user-attachments/assets/b995dd2a-23bd-43c9-96cb-96d5c805f19f
- Discussion Board: https://github.com/wrtnlabs/autobe-example-bbs
- To Do List: https://github.com/wrtnlabs/autobe-example-todo
- Reddit Community: https://github.com/wrtnlabs/autobe-example-reddit
-
E-Commerce: https://github.com/wrtnlabs/autobe-example-shopping
- Requirements Analysis: Report
- Database Design: Entity Relationship Diagram / Prisma Schema
- API Design: API Controllers / DTO Structures
- E2E Test Functions:
test/features/api - API Implementations:
src/providers
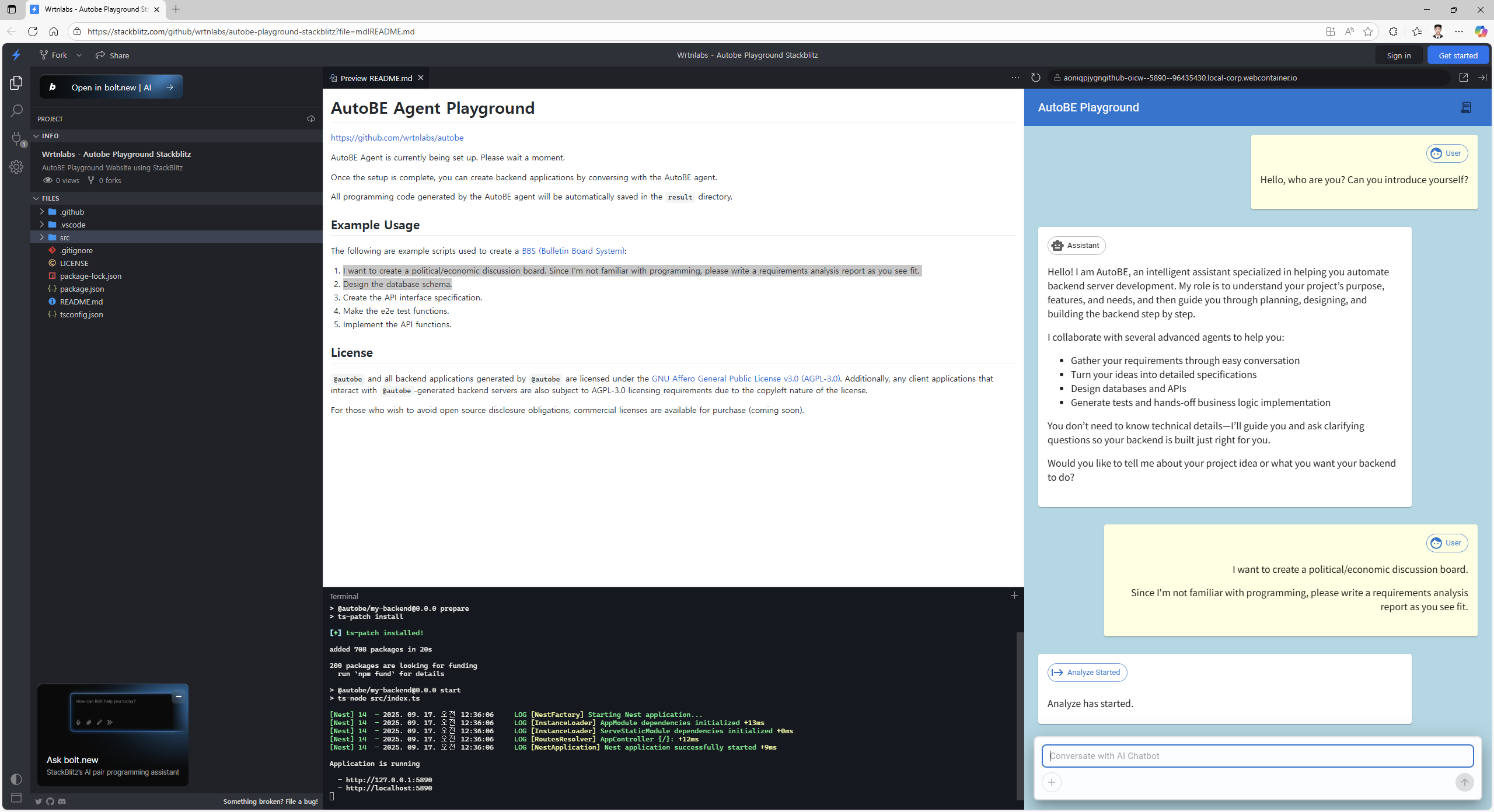
https://stackblitz.com/github/wrtnlabs/autobe-playground-stackblitz
Visit the site above to use AutoBE directly through the StackBlitz website. Simply discuss the topic you want to build, and AutoBE will create a backend application for you.
Here's an example conversation script to use with AutoBE. Following this script will guide AutoBE to create an "Economic/Political Discussion Board":
- Requirements Analysis: "I want to create an economic/political discussion board. Since I'm not familiar with programming, please write a requirements analysis report as you see fit."
- Database Design: "Design the database schema."
- API Specification: "Create the API interface specification."
- Testing: "Make the e2e test functions."
- Implementation: "Implement API functions."
If you want to use Local LLMs like qwen3-80b-a3b or maintain multiple chat sessions for frequent conversations with AutoBE, run the following commands. You can install AutoBE locally, run the playground application directly, and manage your chat sessions:
git clone https://github.com/wrtnlabs/autobe
cd autobe
pnpm install
pnpm run playground
After installing AutoBE locally and running the playground, you can replay chat sessions from AutoBE development team's testing at http://localhost:5713/replay/index.html.
Find comprehensive resources at our official website.
- 🙋🏻♂️ Introduction
- 📦 Setup
- 🔍 Concepts
- 🤖 Agent Library
- 📡 WebSocket Protocol
- 🛠️ Backend Stack
- 🌐 No-Code Ecosystem
- 📅 Roadmap
- 🔧 API Documentation
flowchart
subgraph "Backend Coding Agent"
coder("Facade Controller")
end
subgraph "Functional Agents"
coder --"Requirements Analysis"--> analyze("Analyze")
coder --"ERD"--> prisma("Prisma")
coder --"API Design"--> interface("Interface")
coder --"Test Codes" --> test("Test")
coder --"Main Program" --> realize("Realize")
end
subgraph "Compiler Feedback"
prisma --"validates" --> prismaCompiler("<a href="https://github.com/wrtnlabs/autobe/blob/main/packages/interface/src/prisma/AutoBePrisma.ts" target="_blank">Prisma Compiler</a>")
interface --"generates" --> openapiCompiler("<a href="https://github.com/wrtnlabs/autobe/blob/main/packages/interface/src/openapi/AutoBeOpenApi.ts" target="_blank">OpenAPI Compiler</a>")
test --"analyzes" --> testCompiler("<a href="https://github.com/wrtnlabs/autobe/blob/main/packages/interface/src/test/AutoBeTest.ts" target="_blank">Test Compiler</a>")
realize --"compiles" --> realizeCompiler("TypeScript Compiler")
endAutoBE follows a waterfall methodology to generate backend applications, with 40+ specialized agents handling each phase. The agents work in coordinated teams throughout the development process.
Each waterfall stage includes AI-friendly compilers that guarantee type safety of the generated code. Rather than generating code directly, AutoBE's agents first construct language-neutral Abstract Syntax Trees using predefined schemas. Each AST node undergoes validation against type rules before any code generation occurs, catching structural errors at the conceptual level rather than during compilation.
This approach is designed to ensure that the final generated TypeScript and Prisma code is 100% buildable. Based on our testing with multiple example projects including e-commerce platforms, discussion boards, and task management systems, AutoBE maintains this compilation guarantee across diverse application types.
To illustrate this process, here are the phase outputs from our "Economic/Political Discussion Board" example:
- Requirements Analysis: Report
- Database Design: Entity Relationship Diagram / Prisma Schema
- API Specification: API Controllers / DTO Structures
-
E2E Test Functions:
test/features/api -
API Implementations:
src/providers
Also, you don't need to use all phases - stop at any stage that fits your needs. Whether you want just requirements analysis, database design, API specification, or e2e testing, AutoBE adapts to your workflow.
Additionally, if you're skipping the full pipeline because of language preference rather than workflow needs, this capability is in development - AutoBE's language-neutral AST structure will soon support additional programming languages beyond TypeScript.
Every AutoBE-generated backend automatically includes a type-safe client SDK, making frontend integration seamless and error-free. This SDK provides:
- Zero Configuration: SDK is auto-generated alongside your backend - no manual setup required
- 100% Type Safety: Full TypeScript support with autocomplete and compile-time validation
- Framework Agnostic: Works with React, Vue, Angular, or any TypeScript/JavaScript project
- E2E Test Integration: Powers AI-generated test suites for comprehensive backend testing
import api, { IPost } from "autobe-generated-sdk";
// Type-safe API calls with full autocomplete
const connection: api.IConnection = {
host: "http://localhost:1234",
};
await api.functional.users.login(connection, {
body: {
email: "[email protected]",
password: "secure-password",
},
});
// TypeScript catches errors at compile time
const post: IPost = await api.functional.posts.create(connection, {
body: {
title: "Hello World",
content: "My first post",
// authorId: "123" <- TypeScript error if this field is missing!
},
});This SDK eliminates the traditional pain points of API integration - no more manual type definitions, no more runtime surprises, and no more API documentation lookups. Your frontend developers can focus on building features, not wrestling with API contracts.
Beyond Frontend Integration: The SDK powers both frontend development and E2E test generation. AutoBE uses the same type-safe SDK internally to generate comprehensive test suites, ensuring every API endpoint is thoroughly tested. This creates a robust feedback loop that enhances backend stability - AI writes tests using the SDK, the SDK ensures type safety, and your backend becomes more reliable with every generated test.
gantt
dateFormat YYYY-MM-DD
title AutoBE Roadmap Overview
section Alpha Release
Overall Design: done, 2025-05-01, 21d
Compiler Development: done, 2025-05-16, 30d
Prototype Agents: done, 2025-05-16, 30d
section Beta Release
Compiler Feedback: done, 2025-06-15, 29d
Test Agent: done, 2025-06-15, 92d
Realize Agent: done, 2025-07-01, 76d
Achieve 100% Compilation: done, 2025-07-16, 61d
Hackathon Contest: done, 2025-09-01, 21d
section v1.0 Official Release
Debate Enhancement: planned, 2025-09-15, 90d
RAG Optimization: planned, 2025-09-15, 90d
Achieve 100% Working: active, 2025-09-15, 90dAutoBE has successfully completed both Alpha and Beta development phases, establishing a solid foundation for production-ready backend generation.
The Alpha phase (May 2025) focused on core architecture design and compiler development, creating the foundational framework for AI-friendly code generation. We built the initial agent system and established the waterfall methodology that ensures reliable, structured development processes.
The Beta phase (June 15 - September 14, 2025) achieved our primary goal: 100% compilation success rate. Through extensive testing across diverse application types including e-commerce platforms, discussion boards, and task management systems, we validated that AutoBE's AI-friendly compilers can generate TypeScript and Prisma code that compiles successfully every time.
The v1.0 Official Release (starting September 15, 2025) now targets the next milestone: ensuring that AutoBE-generated backend applications not only compile successfully, but also run perfectly in production environments. This means achieving 100% runtime success alongside our existing compilation guarantee, delivering truly production-ready applications without manual intervention.
While AutoBE achieves 100% compilation success, please note these current limitations:
Runtime Behavior: Generated applications compile successfully, but runtime behavior may require testing and refinement. Unexpected runtime errors can occur during server execution, such as database connection issues, API endpoint failures, or business logic exceptions that weren't caught during compilation. We strongly recommend thorough testing in development environments before deploying to production. Our v1.0 release targets 100% runtime success to address these issues.
Design Interpretation: AutoBE's database and API designs may differ from your expectations. We recommend thoroughly reviewing generated specifications before proceeding with implementation, especially before production deployment.
Token Consumption: AutoBE requires significant AI token usage for complex projects. Based on our testing, projects typically consume 30M-250M+ tokens depending on complexity (simple todo apps use ~4M tokens, while complex e-commerce platforms may require 250M+ tokens). We are working on RAG optimization to reduce this overhead in future releases.
Maintenance: AutoBE focuses on initial generation and does not provide ongoing maintenance capabilities. Once your backend is generated, you'll need to handle bug fixes, feature additions, performance optimizations, and security updates manually. We recommend establishing a development workflow that combines the generated codebase with AI coding assistants like Claude Code for efficient ongoing development and maintenance tasks.
AutoBE is licensed under the GNU Affero General Public License v3.0 (AGPL-3.0). If you modify AutoBE itself or offer it as a network service, you must make your source code available under the same license.
However, backend applications generated by AutoBE can be relicensed under any license you choose, such as MIT. This means you can freely use AutoBE-generated code in commercial projects without open source obligations, similar to how other code generation tools work.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for autobe
Similar Open Source Tools
autobe
AutoBE is an AI-powered no-code agent that builds backend applications, enhanced by compiler feedback. It automatically generates backend applications using TypeScript, NestJS, and Prisma following a waterfall development model. The generated code is validated by review agents and OpenAPI/TypeScript/Prisma compilers, ensuring 100% working code. The tool aims to enable anyone to build backend servers, AI chatbots, and frontend applications without coding knowledge by conversing with AI.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

Upsonic
Upsonic offers a cutting-edge enterprise-ready framework for orchestrating LLM calls, agents, and computer use to complete tasks cost-effectively. It provides reliable systems, scalability, and a task-oriented structure for real-world cases. Key features include production-ready scalability, task-centric design, MCP server support, tool-calling server, computer use integration, and easy addition of custom tools. The framework supports client-server architecture and allows seamless deployment on AWS, GCP, or locally using Docker.
momentum-core
Momentum is an open-source behavioral auditor for backend code that helps developers generate powerful insights into their codebase. It analyzes code behavior, tests it at every git push, and ensures readiness for production. Momentum understands backend code, visualizes dependencies, identifies behaviors, generates test code, runs code in the local environment, and provides debugging solutions. It aims to improve code quality, streamline testing processes, and enhance developer productivity.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
inngest
Inngest is a platform that offers durable functions to replace queues, state management, and scheduling for developers. It allows writing reliable step functions faster without dealing with infrastructure. Developers can create durable functions using various language SDKs, run a local development server, deploy functions to their infrastructure, sync functions with the Inngest Platform, and securely trigger functions via HTTPS. Inngest Functions support retrying, scheduling, and coordinating operations through triggers, flow control, and steps, enabling developers to build reliable workflows with robust support for various operations.

aigne-framework
AIGNE Framework is a functional AI application development framework designed to simplify and accelerate the process of building modern applications. It combines functional programming features, powerful artificial intelligence capabilities, and modular design principles to help developers easily create scalable solutions. With key features like modular design, TypeScript support, multiple AI model support, flexible workflow patterns, MCP protocol integration, code execution capabilities, and Blocklet ecosystem integration, AIGNE Framework offers a comprehensive solution for developers. The framework provides various workflow patterns such as Workflow Router, Workflow Sequential, Workflow Concurrency, Workflow Handoff, Workflow Reflection, Workflow Orchestration, Workflow Code Execution, and Workflow Group Chat to address different application scenarios efficiently. It also includes built-in MCP support for running MCP servers and integrating with external MCP servers, along with packages for core functionality, agent library, CLI, and various models like OpenAI, Gemini, Claude, and Nova.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
deep-research-web-ui
This web UI tool is designed to enhance the user experience of the deep-research repository by providing a safe and secure environment for conducting AI research. It offers features such as real-time feedback, search visualization, export as PDF, support for various AI models, and Docker deployment. Users can interact with multiple AI providers and web search services, making research processes more efficient and accessible. The tool also includes recent updates that improve functionality and fix bugs, ensuring a seamless experience for users.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.

clearml
ClearML is an auto-magical suite of tools designed to streamline AI workflows. It includes modules for experiment management, MLOps/LLMOps, data management, model serving, and more. ClearML offers features like experiment tracking, model serving, orchestration, and automation. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm for remote debugging. ClearML aims to simplify collaboration, automate processes, and enhance visibility in AI projects.

kodit
Kodit is a Code Indexing MCP Server that connects AI coding assistants to external codebases, providing accurate and up-to-date code snippets. It improves AI-assisted coding by offering canonical examples, indexing local and public codebases, integrating with AI coding assistants, enabling keyword and semantic search, and supporting OpenAI-compatible or custom APIs/models. Kodit helps engineers working with AI-powered coding assistants by providing relevant examples to reduce errors and hallucinations.

cline-based-code-generator
HAI Code Generator is a cutting-edge tool designed to simplify and automate task execution while enhancing code generation workflows. Leveraging Specif AI, it streamlines processes like task execution, file identification, and code documentation through intelligent automation and AI-driven capabilities. Built on Cline's powerful foundation for AI-assisted development, HAI Code Generator boosts productivity and precision by automating task execution and integrating file management capabilities. It combines intelligent file indexing, context generation, and LLM-driven automation to minimize manual effort and ensure task accuracy. Perfect for developers and teams aiming to enhance their workflows.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.

cosdata
Cosdata is a cutting-edge AI data platform designed to power the next generation search pipelines. It features immutability, version control, and excels in semantic search, structured knowledge graphs, hybrid search capabilities, real-time search at scale, and ML pipeline integration. The platform is customizable, scalable, efficient, enterprise-grade, easy to use, and can manage multi-modal data. It offers high performance, indexing, low latency, and high requests per second. Cosdata is designed to meet the demands of modern search applications, empowering businesses to harness the full potential of their data.
For similar tasks
autobe
AutoBE is an AI-powered no-code agent that builds backend applications, enhanced by compiler feedback. It automatically generates backend applications using TypeScript, NestJS, and Prisma following a waterfall development model. The generated code is validated by review agents and OpenAPI/TypeScript/Prisma compilers, ensuring 100% working code. The tool aims to enable anyone to build backend servers, AI chatbots, and frontend applications without coding knowledge by conversing with AI.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.