
vts
VTS is a tool designed for the transformation and transportation of vectors and unstructured data.
Stars: 71
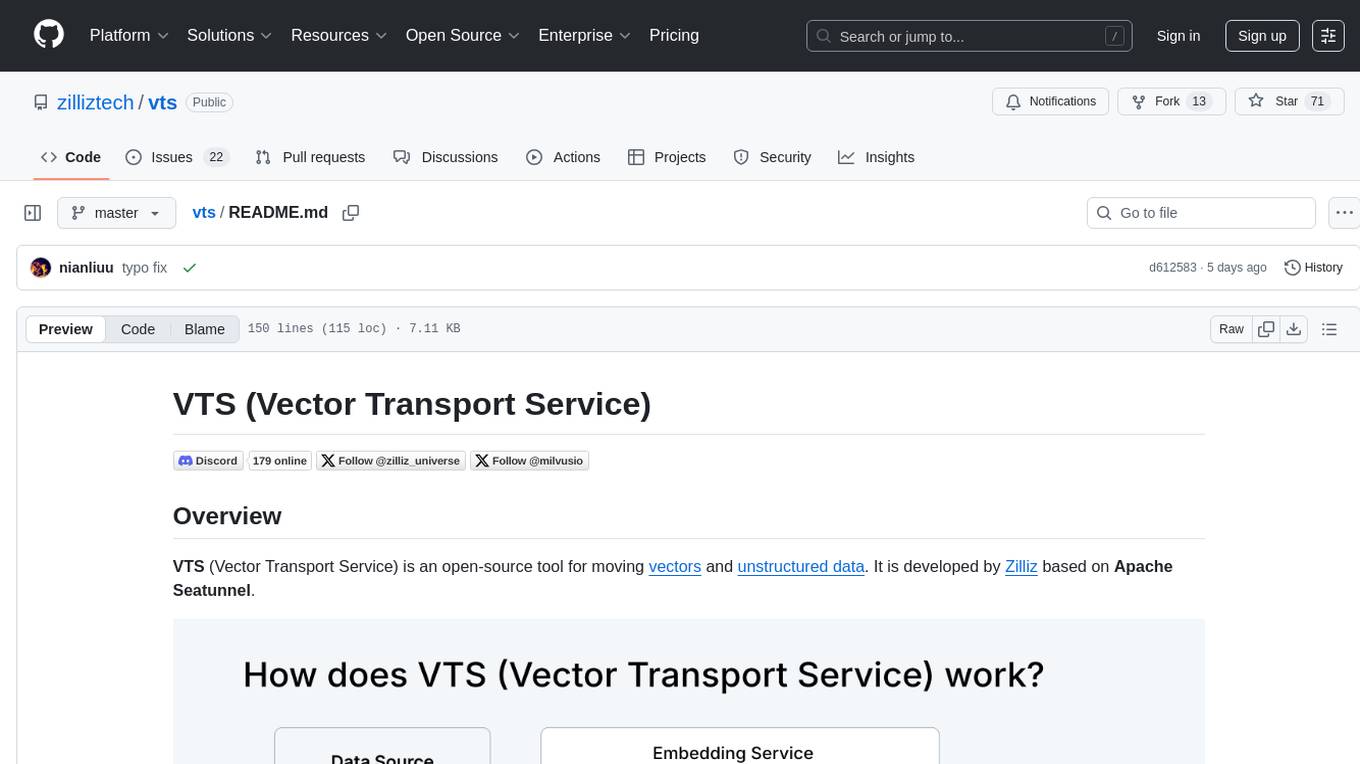
VTS (Vector Transport Service) is an open-source tool developed by Zilliz based on Apache Seatunnel for moving vectors and unstructured data. It addresses data migration needs, supports real-time data streaming and offline import, simplifies unstructured data transformation, and ensures end-to-end data quality. Core capabilities include rich connectors, stream and batch processing, distributed snapshot support, high performance, and real-time monitoring. Future developments include incremental synchronization, advanced data transformation, and enhanced monitoring. VTS supports various connectors for data migration and offers advanced features like Transformers, cluster mode deployment, RESTful API, Docker deployment, and more.
README:



VTS (Vector Transport Service) is an open-source tool for moving vectors and unstructured data. It is developed by Zilliz based on Apache Seatunnel.

- Meeting the Growing Data Migration Needs: VTS evolves from our Milvus Migration Service, which has successfully helped over 100 organizations migrate data between Milvus clusters. User demands have grown to include migrations from different vector databases, traditional search engines like Elasticsearch and Solr, relational databases, data warehouses, document databases, and even S3 and data lakes to Milvus.
- Supporting Real-time Data Streaming and Offline Import: As vector database capabilities expand, users require both real-time data streaming and offline batch import options.
- Simplifying Unstructured Data Transformation: Unlike traditional ETL, transforming unstructured data requires AI and model capabilities. VTS, in conjunction with the Zilliz Cloud Pipelines, enables vector embedding, tagging, and complex transformations, significantly reducing data cleaning costs and operational complexity.
- Ensuring End-to-End Data Quality: Data integration and synchronization processes are prone to data loss and inconsistencies. VTS addresses these critical data quality concerns with robust monitoring and alerting mechanisms.
Built on top of Apache Seatunnel, Vector-Transport-Service offers:
- Rich, extensible connectors
- Unified stream and batch processing for real-time synchronization and offline batch imports
- Distributed snapshot support for data consistency
- High performance, low latency, and scalability
- Real-time monitoring and visual management
Additionally, Vector-Transport-Service introduces vector-specific capabilities such as multiple data source support, schema matching, and basic data validation.
Future developments include:
- Incremental synchronization
- Combined one-time migration and change data capture
- Advanced data transformation capabilities
- Enhanced monitoring and alerting

- Docker installed
- Access to source and target databases
- Required credentials and permissions
- Milvus Version >= 2.3.6
- Pull the VTS Image Fetch the prebuilt VTS container (built on Apache SeaTunnel) and open an interactive shell inside the image so you can run jobs without building from source.
docker pull zilliz/vector-transport-service:latest
docker run -it zilliz/vector-transport-service:latest /bin/bash-
Configure Your Migration Create a job configuration (e.g.,
migration.conf) that declares the execution env, a source connector, and a sink connector. Start with small batches and a single collection/table to validate connectivity before scaling up.
env {
parallelism = 1
job.mode = "BATCH"
}
source {
# Source configuration (e.g., Milvus, Elasticsearch, etc.)
Milvus {
url = "https://your-source-url:19530"
token = "your-token"
database = "default"
collections = ["your-collection"]
batch_size = 100
}
}
sink {
# Target configuration
Milvus {
url = "https://your-target-url:19530"
token = "your-token"
database = "default"
batch_size = 10
}
}- Run the Migration Run in cluster mode for production‑like workloads, or local mode for quick validation. Watch the console output to confirm progress.
Cluster Mode (Recommended):
# Start the cluster
mkdir -p ./logs
./bin/seatunnel-cluster.sh -d
# Submit the job
./bin/seatunnel.sh --config ./migration.confLocal Mode:
./bin/seatunnel.sh --config ./migration.conf -m local- Adjust
parallelismbased on your data volume - Configure appropriate
batch_sizefor optimal performance - Set up proper authentication and security measures
- Monitor system resources during migration
VTS supports various connectors for data migration:
- Milvus (example config)
- Elasticsearch (example config)
- Pinecone (example config)
- Qdrant (example config)
- Postgres Vector (example config)
- Tencent VectorDB (example config)
- Weaviate(example config)
- S3 Vector(example config)
For more advanced features, refer to our Tutorial.md and the Apache SeaTunnel Documentation:
- Transformers (TablePathMapper, FieldMapper, Embedding)
- Cluster mode deployment
- RESTful API for job management
- Docker deployment
- Advanced configuration options
For development setup and contribution guidelines, see Development.md.
Need help? Contact our support team:
- Email: [email protected]
- Discord: Join our community
SeaTunnel is a next-generation, high-performance, distributed data integration tool. It's:
- Capable of synchronizing vast amounts of data daily
- Trusted by numerous companies for efficiency and stability
- Released under Apache 2 License
- A top-level project of the Apache Software Foundation (ASF)
For more information, visit the Apache Seatunnel website.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for vts
Similar Open Source Tools
vts
VTS (Vector Transport Service) is an open-source tool developed by Zilliz based on Apache Seatunnel for moving vectors and unstructured data. It addresses data migration needs, supports real-time data streaming and offline import, simplifies unstructured data transformation, and ensures end-to-end data quality. Core capabilities include rich connectors, stream and batch processing, distributed snapshot support, high performance, and real-time monitoring. Future developments include incremental synchronization, advanced data transformation, and enhanced monitoring. VTS supports various connectors for data migration and offers advanced features like Transformers, cluster mode deployment, RESTful API, Docker deployment, and more.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
Mooncake
Mooncake is a serving platform for Kimi, a leading LLM service provided by Moonshot AI. It features a KVCache-centric disaggregated architecture that separates prefill and decoding clusters, leveraging underutilized CPU, DRAM, and SSD resources of the GPU cluster. Mooncake's scheduler balances throughput and latency-related SLOs, with a prediction-based early rejection policy for highly overloaded scenarios. It excels in long-context scenarios, achieving up to a 525% increase in throughput while handling 75% more requests under real workloads.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
aistore
AIStore is a lightweight object storage system designed for AI applications. It is highly scalable, reliable, and easy to use. AIStore can be deployed on any commodity hardware, and it can be used to store and manage large datasets for deep learning and other AI applications.

NeMo-Curator
NeMo Curator is a GPU-accelerated open-source framework designed for efficient large language model data curation. It provides scalable dataset preparation for tasks like foundation model pretraining, domain-adaptive pretraining, supervised fine-tuning, and parameter-efficient fine-tuning. The library leverages GPUs with Dask and RAPIDS to accelerate data curation, offering customizable and modular interfaces for pipeline expansion and model convergence. Key features include data download, text extraction, quality filtering, deduplication, downstream-task decontamination, distributed data classification, and PII redaction. NeMo Curator is suitable for curating high-quality datasets for large language model training.
workflows-py
LlamaIndex Workflows is a framework for orchestrating and chaining together complex systems of steps and events. It shines in orchestrating complex, multi-step processes involving AI models, APIs, and decision-making. The async-first, event-driven architecture allows building workflows that can route between different capabilities, implement parallel processing patterns, loop over complex sequences, and maintain state across multiple steps. Key features include async-first design, event-driven structure, state management, and observability through tools like Arize Phoenix and OpenTelemetry.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.

AIL-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.

ail-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).
FinRobot
FinRobot is an open-source AI agent platform designed for financial applications using large language models. It transcends the scope of FinGPT, offering a comprehensive solution that integrates a diverse array of AI technologies. The platform's versatility and adaptability cater to the multifaceted needs of the financial industry. FinRobot's ecosystem is organized into four layers, including Financial AI Agents Layer, Financial LLMs Algorithms Layer, LLMOps and DataOps Layers, and Multi-source LLM Foundation Models Layer. The platform's agent workflow involves Perception, Brain, and Action modules to capture, process, and execute financial data and insights. The Smart Scheduler optimizes model diversity and selection for tasks, managed by components like Director Agent, Agent Registration, Agent Adaptor, and Task Manager. The tool provides a structured file organization with subfolders for agents, data sources, and functional modules, along with installation instructions and hands-on tutorials.
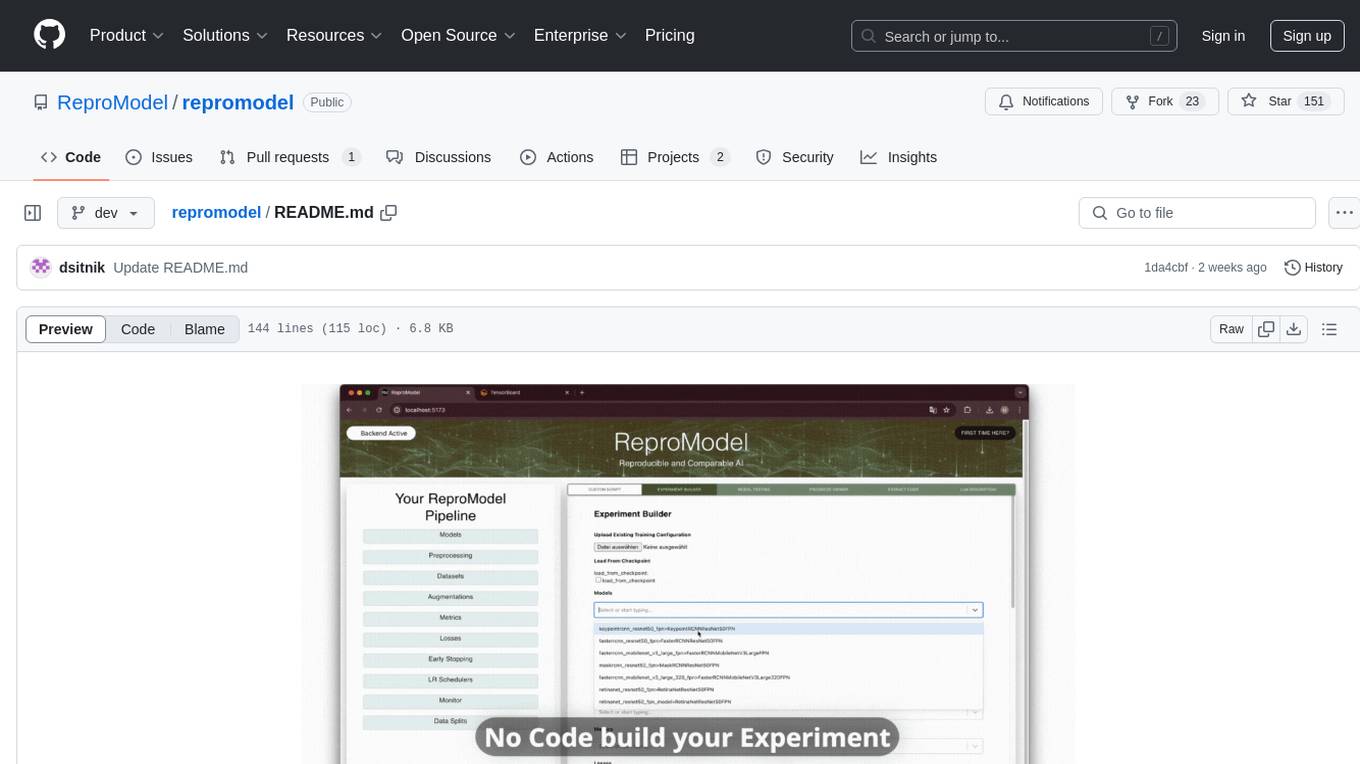
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.

aigne-framework
AIGNE Framework is a functional AI application development framework designed to simplify and accelerate the process of building modern applications. It combines functional programming features, powerful artificial intelligence capabilities, and modular design principles to help developers easily create scalable solutions. With key features like modular design, TypeScript support, multiple AI model support, flexible workflow patterns, MCP protocol integration, code execution capabilities, and Blocklet ecosystem integration, AIGNE Framework offers a comprehensive solution for developers. The framework provides various workflow patterns such as Workflow Router, Workflow Sequential, Workflow Concurrency, Workflow Handoff, Workflow Reflection, Workflow Orchestration, Workflow Code Execution, and Workflow Group Chat to address different application scenarios efficiently. It also includes built-in MCP support for running MCP servers and integrating with external MCP servers, along with packages for core functionality, agent library, CLI, and various models like OpenAI, Gemini, Claude, and Nova.
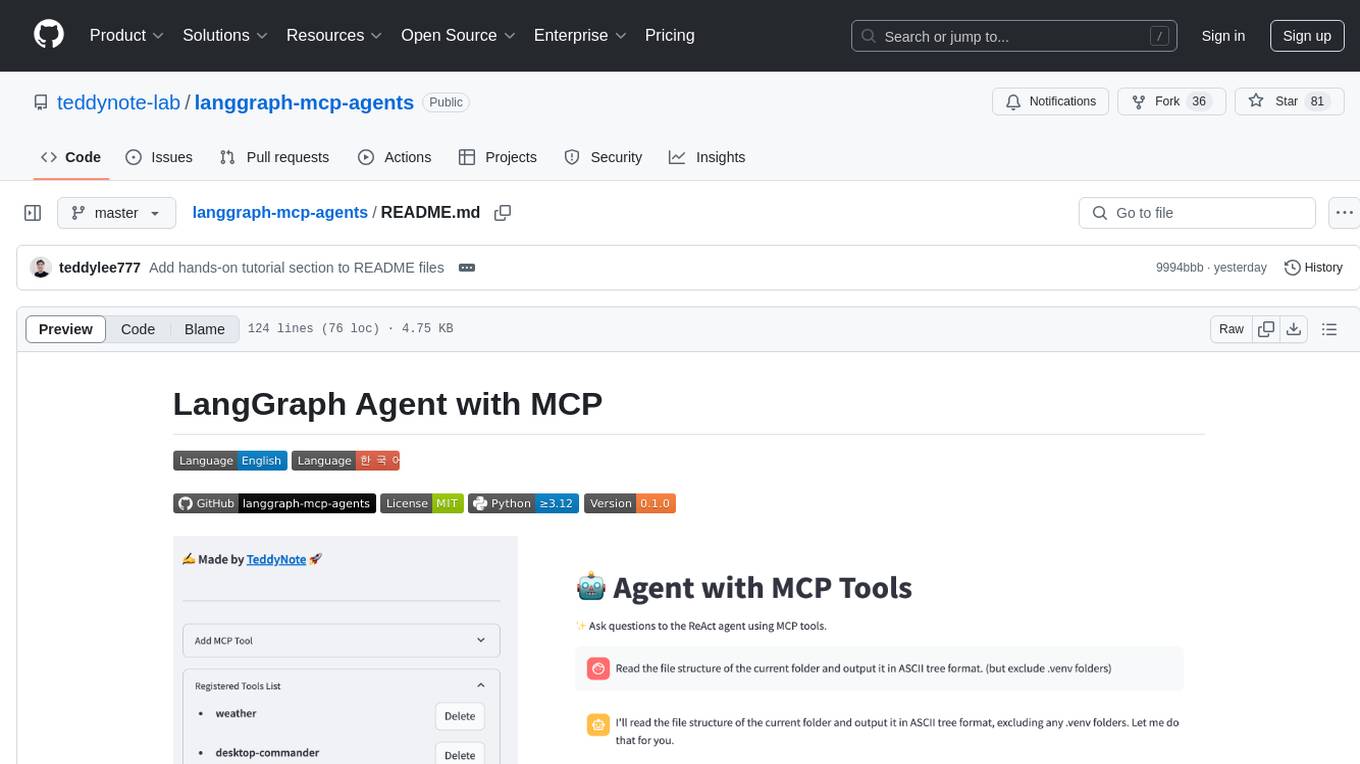
langgraph-mcp-agents
LangGraph Agent with MCP is a toolkit provided by LangChain AI that enables AI agents to interact with external tools and data sources through the Model Context Protocol (MCP). It offers a user-friendly interface for deploying ReAct agents to access various data sources and APIs through MCP tools. The toolkit includes features such as a Streamlit Interface for interaction, Tool Management for adding and configuring MCP tools dynamically, Streaming Responses in real-time, and Conversation History tracking.
HAMi
HAMi is a Heterogeneous AI Computing Virtualization Middleware designed to manage Heterogeneous AI Computing Devices in a Kubernetes cluster. It allows for device sharing, device memory control, device type specification, and device UUID specification. The tool is easy to use and does not require modifying task YAML files. It includes features like hard limits on device memory, partial device allocation, streaming multiprocessor limits, and core usage specification. HAMi consists of components like a mutating webhook, scheduler extender, device plugins, and in-container virtualization techniques. It is suitable for scenarios requiring device sharing, specific device memory allocation, GPU balancing, low utilization optimization, and scenarios needing multiple small GPUs. The tool requires prerequisites like NVIDIA drivers, CUDA version, nvidia-docker, Kubernetes version, glibc version, and helm. Users can install, upgrade, and uninstall HAMi, submit tasks, and monitor cluster information. The tool's roadmap includes supporting additional AI computing devices, video codec processing, and Multi-Instance GPUs (MIG).
For similar tasks
akeru
Akeru.ai is an open-source AI platform leveraging the power of decentralization. It offers transparent, safe, and highly available AI capabilities. The platform aims to give developers access to open-source and transparent AI resources through its decentralized nature hosted on an edge network. Akeru API introduces features like retrieval, function calling, conversation management, custom instructions, data input optimization, user privacy, testing and iteration, and comprehensive documentation. It is ideal for creating AI agents and enhancing web and mobile applications with advanced AI capabilities. The platform runs on a Bittensor Subnet design that aims to democratize AI technology and promote an equitable AI future. Akeru.ai embraces decentralization challenges to ensure a decentralized and equitable AI ecosystem with security features like watermarking and network pings. The API architecture integrates with technologies like Bun, Redis, and Elysia for a robust, scalable solution.
vts
VTS (Vector Transport Service) is an open-source tool developed by Zilliz based on Apache Seatunnel for moving vectors and unstructured data. It addresses data migration needs, supports real-time data streaming and offline import, simplifies unstructured data transformation, and ensures end-to-end data quality. Core capabilities include rich connectors, stream and batch processing, distributed snapshot support, high performance, and real-time monitoring. Future developments include incremental synchronization, advanced data transformation, and enhanced monitoring. VTS supports various connectors for data migration and offers advanced features like Transformers, cluster mode deployment, RESTful API, Docker deployment, and more.
verifiers
Verifiers is a tool designed to verify the correctness of data and information. It provides a set of functions to validate and check the accuracy of various types of data, such as text, numbers, dates, and more. With Verifiers, users can easily ensure the quality and integrity of their data by performing checks and validations according to predefined rules and criteria. The tool is versatile and can be used in a wide range of applications, including data processing, quality control, error detection, and data analysis. Verifiers simplifies the process of data verification and helps users identify and correct errors and inconsistencies in their datasets, leading to improved data quality and reliability.
n8n-docs
n8n is an extendable workflow automation tool that enables you to connect anything to everything. It is open-source and can be self-hosted or used as a service. n8n provides a visual interface for creating workflows, which can be used to automate tasks such as data integration, data transformation, and data analysis. n8n also includes a library of pre-built nodes that can be used to connect to a variety of applications and services. This makes it easy to create complex workflows without having to write any code.

hash
HASH is a self-building, open-source database which grows, structures and checks itself. With it, we're creating a platform for decision-making, which helps you integrate, understand and use data in a variety of different ways.
island-ai
island-ai is a TypeScript toolkit tailored for developers engaging with structured outputs from Large Language Models. It offers streamlined processes for handling, parsing, streaming, and leveraging AI-generated data across various applications. The toolkit includes packages like zod-stream for interfacing with LLM streams, stream-hooks for integrating streaming JSON data into React applications, and schema-stream for JSON streaming parsing based on Zod schemas. Additionally, related packages like @instructor-ai/instructor-js focus on data validation and retry mechanisms, enhancing the reliability of data processing workflows.
ezdata
Ezdata is a data processing and task scheduling system developed based on Python backend and Vue3 frontend. It supports managing multiple data sources, abstracting various data sources into a unified data model, integrating chatgpt for data question and answer functionality, enabling low-code data integration and visualization processing, scheduling single and dag tasks, and integrating a low-code data visualization dashboard system.
buildel
Buildel is an AI automation platform that empowers users to create versatile workflows without writing code. It supports multiple providers and interfaces, offers pre-built use cases, and allows users to bring their own API keys. Ideal for AI-powered document retrieval, conversational interfaces, and data integration. Users can get started at app.buildel.ai or run Buildel locally with Node.js, Elixir/Erlang, Docker, Git, and JQ installed. Join the community on Discord for support and discussions.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.