
taipy
Turns Data and AI algorithms into production-ready web applications in no time.
Stars: 18715
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.
README:



No more compromises on performance, customization, and scalability.
- Taipy? What for?
- Taipy and its ecosystem
- Quickstart
- Documentation and resources
- Contributing
- Code of Conduct
- License
Taipy is designed for data scientists and machine learning engineers to create data & AI driven web applications.
⭐️ Enables building production-ready web applications.
⭐️ No need to learn new languages; only Python is needed.
⭐️ Focus on data and AI algorithms. Delegates development complexities to Taipy.
⭐️ Simplifies production operations (hosting, deployments, maintenance, etc.).
Taipy includes the Taipy Python library enabling developers to easily empower their end-users with:
- User interface generation
- Data Integration
- Pipeline orchestration
- What-if analysis and scenario management
- Authentication, roles and user management
- Cron jobs and scheduling
Besides the Taipy Library, the Taipy Ecosystem includes:
- Taipy Designer
- Taipy Studio
- Predefined templates
- Data platform integration
Taipy comes with a set of materials to facilitate production operations and maintenance.
- Command line interface.
- Deployment scripts.
- Version Management.
- Data migration.
- Telemetry and monitoring.
To install the stable release of Taipy, run:
pip install taipyFor alternative installation methods, an
Installation Guide
provides step-by-step instructions.
A comprehensive documentation set is available at Taipy Documentation to help you with Taipy tools.
It includes Tutorials, user manuals, API references, and Galleries.
Want to help build Taipy? Check out our Contributing Guide.
Want to be part of the Taipy community? Check out our Code of Conduct
Copyright 2021-2025 Avaiga Private Limited
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at Apache License
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for taipy
Similar Open Source Tools
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
OpenContracts
OpenContracts is a free and open-source document analytics platform designed to empower knowledge owners and subject matter experts. It supports multiple document formats, ingestion pipelines, and custom document analytics tools. Users can manage documents, define metadata schemas, extract layout features, generate vector embeddings, deploy custom analyzers, support new document formats, annotate documents, extract bulk data, and create bespoke data extraction workflows. The tool aims to provide a standardized architecture for analyzing contracts and making data portable, with a focus on PDF and text-based formats. It includes features like document management, layout parsing, pluggable architectures, human annotation interface, and a custom LLM framework for conversation management and real-time streaming.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
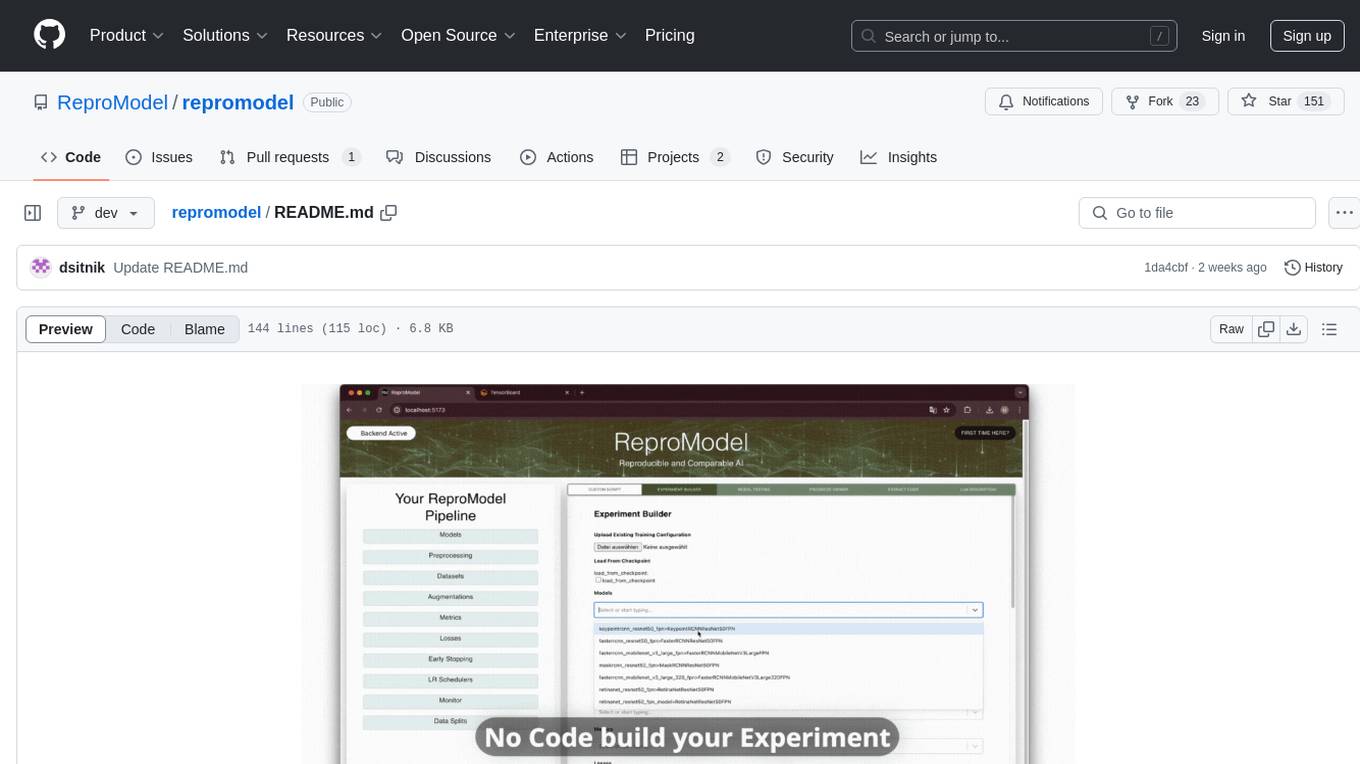
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
BotServer
General Bot is a chat bot server that accelerates bot development by providing code base, resources, deployment to the cloud, and templates for creating new bots. It allows modification of bot packages without code through a database and service backend. Users can develop bot packages using custom code in editors like Visual Studio Code, Atom, or Brackets. The tool supports creating bots by copying and pasting files and using favorite tools from Office or Photoshop. It also enables building custom dialogs with BASIC for extending bots.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.
openfoodfacts-ai
The openfoodfacts-ai repository is dedicated to tracking and storing experimental AI endeavors, models training, and wishlists related to nutrition table detection, category prediction, logos and labels detection, spellcheck, and other AI projects for Open Food Facts. It serves as a hub for integrating AI models into production and collaborating on AI-related issues. The repository also hosts trained models and datasets for public use and experimentation.
ten_framework
TEN Framework, short for Transformative Extensions Network, is the world's first real-time multimodal AI agent framework. It offers native support for high-performance, real-time multimodal interactions, supports multiple languages and platforms, enables edge-cloud integration, provides flexibility beyond model limitations, and allows for real-time agent state management. The framework facilitates the development of complex AI applications that transcend the limitations of large models by offering a drag-and-drop programming approach. It is suitable for scenarios like simultaneous interpretation, speech-to-text conversion, multilingual chat rooms, audio interaction, and audio-visual interaction.

CosmosAIGraph
CosmosAIGraph is an AI-powered graph and RAG implementation of OmniRAG pattern, utilizing Azure Cosmos DB and other sources. It includes presentations, reference application documentation, FAQs, and a reference dataset of Python libraries pre-vectorized. The project focuses on Azure Cosmos DB for NoSQL and Apache Jena implementation for the in-memory RDF graph. It provides DockerHub images, with plans to add RBAC and Microsoft Entra ID/AAD authentication support, update AI model to gpt-4.5, and offer generic graph examples with a graph generation solution.
kitops
KitOps is a CNCF open standards project for packaging, versioning, and securely sharing AI/ML projects. It provides a unified solution for packaging, versioning, and managing assets in security-conscious enterprises, governments, and cloud operators. KitOps elevates AI artifacts to first-class, governed assets through ModelKits, which are tamper-proof, signable, and compatible with major container registries. The tool simplifies collaboration between data scientists, developers, and SREs, ensuring reliable and repeatable workflows for both development and operations. KitOps supports packaging for various types of models, including large language models, computer vision models, multi-modal models, predictive models, and audio models. It also facilitates compliance with the EU AI Act by offering tamper-proof, signable, and auditable ModelKits.

trainer
Kubeflow Trainer is a Kubernetes-native project for fine-tuning large language models (LLMs) and enabling scalable, distributed training of machine learning (ML) models across various frameworks. It allows integration with ML libraries like HuggingFace, DeepSpeed, or Megatron-LM to orchestrate ML training on Kubernetes. Develop LLMs effortlessly with the Kubeflow Python SDK and build Kubernetes-native Training Runtimes with Kubernetes Custom Resources APIs.

koordinator
Koordinator is a QoS based scheduling system for hybrid orchestration workloads on Kubernetes. It aims to improve runtime efficiency and reliability of latency sensitive workloads and batch jobs, simplify resource-related configuration tuning, and increase pod deployment density. It enhances Kubernetes user experience by optimizing resource utilization, improving performance, providing flexible scheduling policies, and easy integration into existing clusters.
legacy-sourcegraph
Sourcegraph is a tool that simplifies reading, writing, and fixing code in large and complex codebases. It offers features such as code search across repositories and hosts, code intelligence for navigation and references, and the ability to roll out large-scale changes and track migrations. Sourcegraph can be used on the cloud or self-hosted, with public code search available on Sourcegraph.com. The tool provides high-level architecture documentation, database setup best practices, Go and documentation style guides, tips for modifying the GraphQL API, and guidelines for contributing.
For similar tasks
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.

AirPower4T
AirPower4T is a development base library based on Vue3 TypeScript Element Plus Vite, using decorators, object-oriented, Hook and other front-end development methods. It provides many common components and some feedback components commonly used in background management systems, and provides a lot of enums and decorators.
hongbomiao.com
hongbomiao.com is a personal research and development (R&D) lab that facilitates the sharing of knowledge. The repository covers a wide range of topics including web development, mobile development, desktop applications, API servers, cloud native technologies, data processing, machine learning, computer vision, embedded systems, simulation, database management, data cleaning, data orchestration, testing, ops, authentication, authorization, security, system tools, reverse engineering, Ethereum, hardware, network, guidelines, design, bots, and more. It provides detailed information on various tools, frameworks, libraries, and platforms used in these domains.
plate-playground-template
This repository contains a Next.js 15 template with Plate AI integration, plugins, and components. It provides a playground environment for developers to experiment with Plate editor and shadcn/ui. The template offers easy installation methods and development setup to quickly get started with building applications that utilize Plate AI functionality.
continew-admin
Continew-admin is a responsive admin dashboard template built with Bootstrap 4. It provides a clean and intuitive user interface for managing and visualizing data in web applications. The template includes various components and widgets that can be easily customized to suit different project requirements. With Continew-admin, developers can quickly set up a professional-looking admin panel for their web applications.
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.