
kitops
An open source DevOps tool from the CNCF for packaging and versioning AI/ML models, datasets, code, and configuration into an OCI Artifact.
Stars: 1186
KitOps is a CNCF open standards project for packaging, versioning, and securely sharing AI/ML projects. It provides a unified solution for packaging, versioning, and managing assets in security-conscious enterprises, governments, and cloud operators. KitOps elevates AI artifacts to first-class, governed assets through ModelKits, which are tamper-proof, signable, and compatible with major container registries. The tool simplifies collaboration between data scientists, developers, and SREs, ensuring reliable and repeatable workflows for both development and operations. KitOps supports packaging for various types of models, including large language models, computer vision models, multi-modal models, predictive models, and audio models. It also facilitates compliance with the EU AI Act by offering tamper-proof, signable, and auditable ModelKits.
README:


KitOps is a CNCF open standards project for packaging, versioning, and securely sharing AI/ML projects. Built on the OCI (Open Container Initiative) standard, it integrates seamlessly with your existing AI/ML, software development, and DevOps tools.
It’s the preferred solution for packaging, versioning, and managing assets in security-conscious enterprises, governments, and cloud operators who need to self-host AI models and agents.
KitOps is a CNCF project, and is governed by the same organization and policies that manage Kubernetes, OpenTelemetry, and Prometheus. This video provides an outline of KitOps in the CNCF.
KitOps is also the reference implementation of the CNCF's ModelPack specification for a vendor-neutral AI/ML interchange format.
KitOps packages your project into a ModelKit — a self-contained, immutable bundle that includes everything required to reproduce, test, or deploy your AI/ML model.
ModelKits can include code, model weights, datasets, prompts, experiment run results and hyperparameters, metadata, environment configurations, and more.
ModelKits are:
- Tamper-proof – Ensuring consistency and traceability
- Signable – Enabling trust and verification
- Compatible – Natively stored and retrieved in all major container registries
ModelKits elevate AI artifacts to first-class, governed assets — just like application code.
A Kitfile defines your ModelKit. Written in YAML, it maps where each artifact lives and how it fits into the project.
The Kit CLI not only enables you to create, manage, run, and deploy ModelKits -- it lets you pull only the pieces you need.
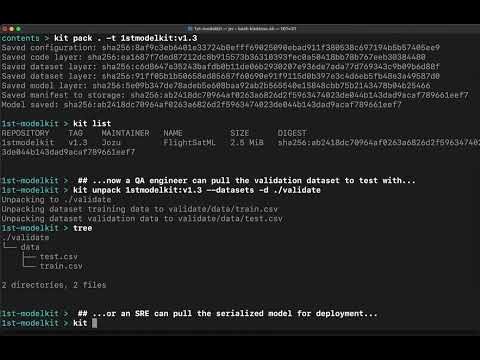
This video shows how KitOps streamlines collaboration between data scientists, developers, and SREs using ModelKits.
- Install the CLI: for MacOS, Windows, and Linux.
- Pack your first ModelKit: Learn how to pack, push, and pull using our Getting Started guide.
- Explore a Quick Start: Try pre-built ModelKits for LLMs, CVs, and more.
For those who prefer to build from the source, follow these steps to get the latest version from our repository.
KitOps was built to bring discipline to productizing AI/ML projects, with:
- 📦 Unified packaging and versioning of AI/ML assets
- 🔐 Secure, signed distribution
- 🛠️ Toolchain compatibility via OCI
- ⚙️ Production-ready for enterprise ML workflows
- 🚢 Create runnable containers for Kubernetes or docker
- 📈 Audit-ready lineage tracking
To get the most out of KitOps' ModelKits, use them with the Jozu Hub. Jozu Hub can be installed behind your firewall and use your existing OCI registry in a private cloud, datacenter, or even in an air-gapped environment.
ModelKits streamline handoffs between:
- Data scientists preparing and training models
- Application developers integrating models into services
- SREs deploying and maintaining models in production
This ensures reliable, repeatable workflows for both development and operations.
KitOps supports packaging for a wide variety of models:
- Large language models
- Computer vision models
- Multi-modal models
- Predictive models
- Audio models
- etc...
🇪🇺 EU AI Act Compliance 🔒
For our friends in the EU - ModelKits are the perfect way to create a library of model versions for EU AI Act compliance because they're tamper-proof, signable, and auditable.
For support, release updates, and general KitOps discussion, please join the KitOps Discord. Follow KitOps on X for daily updates.
If you need help there are several ways to reach our community and Maintainers outlined in our support doc
We ❤️ our KitOps community and contributors. To learn more about the many ways you can contribute (you don't need to be a coder) and how to get started see our Contributor's Guide. Please read our Governance and our Code of Conduct before contributing.
Your insights help KitOps evolve as an open standard for AI/ML. We deeply value the issues and feature requests we get from users in our community 💖. To contribute your thoughts, navigate to the Issues tab and click the New Issue button.
📅 Wednesdays @ 13:30 – 14:00 (America/Toronto)
- 🔗 Google Meet
- ☎️ +1 647-736-3184 (PIN: 144 931 404#)
- 🌐 More numbers
At KitOps, inclusivity, empathy, and responsibility are at our core. Please read our Code of Conduct to understand the values guiding our community.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kitops
Similar Open Source Tools
kitops
KitOps is a CNCF open standards project for packaging, versioning, and securely sharing AI/ML projects. It provides a unified solution for packaging, versioning, and managing assets in security-conscious enterprises, governments, and cloud operators. KitOps elevates AI artifacts to first-class, governed assets through ModelKits, which are tamper-proof, signable, and compatible with major container registries. The tool simplifies collaboration between data scientists, developers, and SREs, ensuring reliable and repeatable workflows for both development and operations. KitOps supports packaging for various types of models, including large language models, computer vision models, multi-modal models, predictive models, and audio models. It also facilitates compliance with the EU AI Act by offering tamper-proof, signable, and auditable ModelKits.
apo
AutoPilot Observability (APO) is an out-of-the-box observability platform that provides one-click installation and ready-to-use capabilities. APO's OneAgent supports one-click configuration-free installation of Tracing probes, collects application fault scene logs, infrastructure metrics, network metrics of applications and downstream dependencies, and Kubernetes events. It supports collecting causality metrics based on eBPF implementation. APO integrates OpenTelemetry probes, otel-collector, Jaeger, ClickHouse, and VictoriaMetrics, reducing user configuration work. APO innovatively integrates eBPF technology with the OpenTelemetry ecosystem, significantly reducing data storage volume. It offers guided troubleshooting using eBPF technology to assist users in pinpointing fault causes on a single page.

genkit
Firebase Genkit (beta) is a framework with powerful tooling to help app developers build, test, deploy, and monitor AI-powered features with confidence. Genkit is cloud optimized and code-centric, integrating with many services that have free tiers to get started. It provides unified API for generation, context-aware AI features, evaluation of AI workflow, extensibility with plugins, easy deployment to Firebase or Google Cloud, observability and monitoring with OpenTelemetry, and a developer UI for prototyping and testing AI features locally. Genkit works seamlessly with Firebase or Google Cloud projects through official plugins and templates.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.
OpenContracts
OpenContracts is a free and open-source document analytics platform designed to empower knowledge owners and subject matter experts. It supports multiple document formats, ingestion pipelines, and custom document analytics tools. Users can manage documents, define metadata schemas, extract layout features, generate vector embeddings, deploy custom analyzers, support new document formats, annotate documents, extract bulk data, and create bespoke data extraction workflows. The tool aims to provide a standardized architecture for analyzing contracts and making data portable, with a focus on PDF and text-based formats. It includes features like document management, layout parsing, pluggable architectures, human annotation interface, and a custom LLM framework for conversation management and real-time streaming.

flow-like
Flow-Like is an enterprise-grade workflow operating system built upon Rust for uncompromising performance, efficiency, and code safety. It offers a modular frontend for apps, a rich set of events, a node catalog, a powerful no-code workflow IDE, and tools to manage teams, templates, and projects within organizations. With typed workflows, users can create complex, large-scale workflows with clear data origins, transformations, and contracts. Flow-Like is designed to automate any process through seamless integration of LLM, ML-based, and deterministic decision-making instances.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).
kgateway
Kgateway is a feature-rich, fast, and flexible Kubernetes-native API gateway built on top of Envoy proxy and the Kubernetes Gateway API. It excels in function-level routing, supports legacy apps, microservices, and serverless, offers robust discovery capabilities, integrates seamlessly with open-source projects, and is designed to support hybrid applications with various technologies, architectures, protocols, and clouds.
dapr-agents
Dapr Agents is a developer framework for building production-grade resilient AI agent systems that operate at scale. It enables software developers to create AI agents that reason, act, and collaborate using Large Language Models (LLMs), while providing built-in observability and stateful workflow execution to ensure agentic workflows complete successfully. The framework is scalable, efficient, Kubernetes-native, data-driven, secure, observable, vendor-neutral, and open source. It offers features like scalable workflows, cost-effective AI adoption, data-centric AI agents, accelerated development, integrated security and reliability, built-in messaging and state infrastructure, and vendor-neutral and open source support. Dapr Agents is designed to simplify the development of AI applications and workflows by providing a comprehensive API surface and seamless integration with various data sources and services.
higress
Higress is an open-source cloud-native API gateway built on the core of Istio and Envoy, based on Alibaba's internal practice of Envoy Gateway. It is designed for AI-native API gateway, serving AI businesses such as Tongyi Qianwen APP, Bailian Big Model API, and Machine Learning PAI platform. Higress provides capabilities to interface with LLM model vendors, AI observability, multi-model load balancing/fallback, AI token flow control, and AI caching. It offers features for AI gateway, Kubernetes Ingress gateway, microservices gateway, and security protection gateway, with advantages in production-level scalability, stream processing, extensibility, and ease of use.
languine
Languine is a CLI tool that helps developers streamline the localization process by providing AI-powered translations, automation features, and developer-centric design. It allows users to easily manage translation files, maintain consistency in tone and style, and save time by automating tasks. With support for over 100 languages and smart detection capabilities, Languine simplifies the localization workflow for developers.
languine
Languine is a CLI tool powered by AI that helps developers streamline the localization process by providing AI-powered translations, automation features, consistent localization, developer-centric design, and time-saving workflows. It automates the identification of translation keys, supports multiple file formats, delivers accurate translations in over 100 languages, aligns translations with the original text's tone and intent, extracts translation keys from codebase, and supports hooks for content formatting with Biome or Prettier. Languine is designed to simplify and enhance the localization experience for developers.
agentsociety
AgentSociety is an advanced framework designed for building agents in urban simulation environments. It integrates LLMs' planning, memory, and reasoning capabilities to generate realistic behaviors. The framework supports dataset-based, text-based, and rule-based environments with interactive visualization. It includes tools for interviews, surveys, interventions, and metric recording tailored for social experimentation.
hopsworks
Hopsworks is a data platform for ML with a Python-centric Feature Store and MLOps capabilities. It provides collaboration for ML teams, offering a secure, governed platform for developing, managing, and sharing ML assets. Hopsworks supports project-based multi-tenancy, team collaboration, development tools for Data Science, and is available on any platform including managed cloud services and on-premise installations. The platform enables end-to-end responsibility from raw data to managed features and models, supports versioning, lineage, and provenance, and facilitates the complete MLOps life cycle.

enthusiast
Enthusiast is a production-ready agentic AI framework for E-commerce, offering tools like Retrieval-Argumented Generation (RAG), vector search, and workflow orchestrator. It helps in building AI-powered tools with customized agents for tasks like smart information search, customer support, content generation, and knowledge base automation. Enthusiast provides validation and evaluation components to ensure responses are grounded in actual data, reducing time, cost, and complexity in AI development.
For similar tasks
kitops
KitOps is a CNCF open standards project for packaging, versioning, and securely sharing AI/ML projects. It provides a unified solution for packaging, versioning, and managing assets in security-conscious enterprises, governments, and cloud operators. KitOps elevates AI artifacts to first-class, governed assets through ModelKits, which are tamper-proof, signable, and compatible with major container registries. The tool simplifies collaboration between data scientists, developers, and SREs, ensuring reliable and repeatable workflows for both development and operations. KitOps supports packaging for various types of models, including large language models, computer vision models, multi-modal models, predictive models, and audio models. It also facilitates compliance with the EU AI Act by offering tamper-proof, signable, and auditable ModelKits.

kitops
KitOps is a packaging and versioning system for AI/ML projects that uses open standards so it works with the AI/ML, development, and DevOps tools you are already using. KitOps simplifies the handoffs between data scientists, application developers, and SREs working with LLMs and other AI/ML models. KitOps' ModelKits are a standards-based package for models, their dependencies, configurations, and codebases. ModelKits are portable, reproducible, and work with the tools you already use.
truss
Truss is a tool that simplifies the process of serving AI/ML models in production. It provides a consistent and easy-to-use interface for packaging, testing, and deploying models, regardless of the framework they were created with. Truss also includes a live reload server for fast feedback during development, and a batteries-included model serving environment that eliminates the need for Docker and Kubernetes configuration.
For similar jobs
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
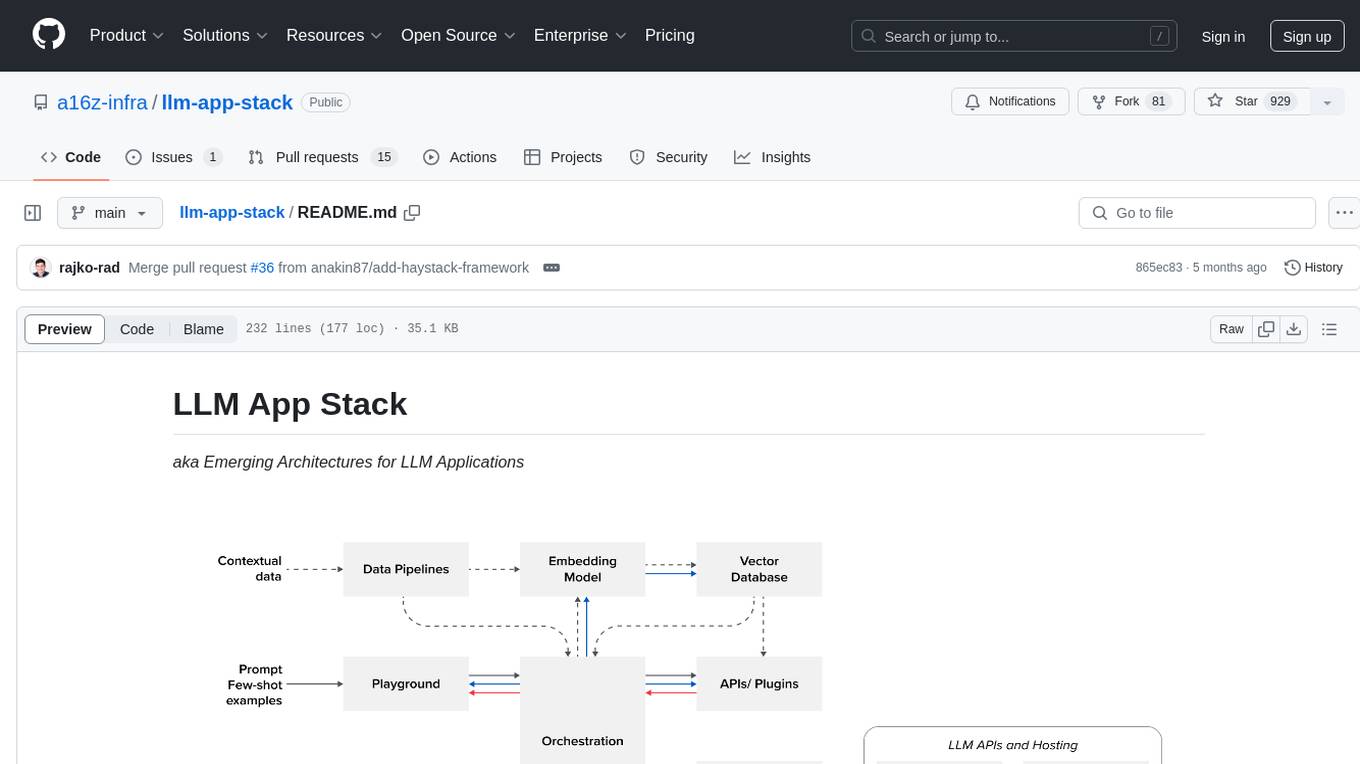
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
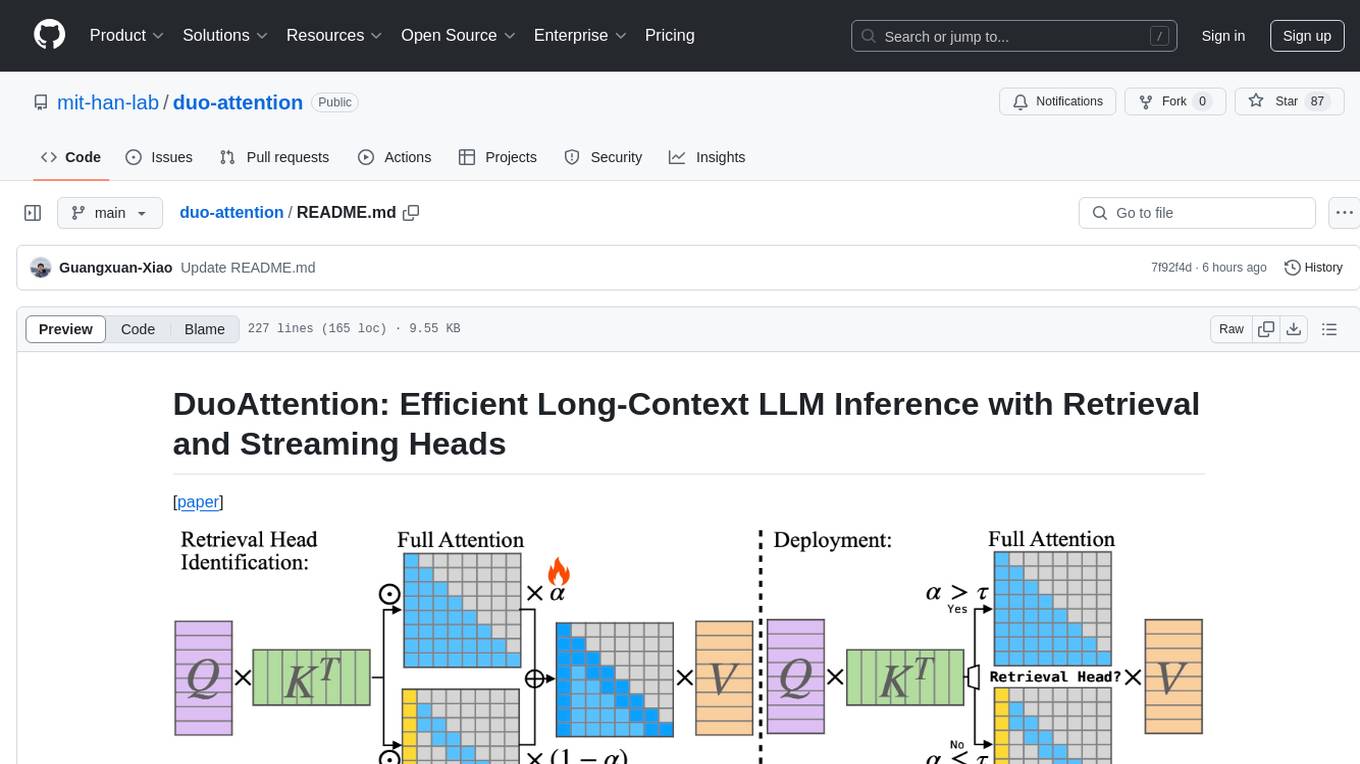
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
llm_note
LLM notes repository contains detailed analysis on transformer models, language model compression, inference and deployment, high-performance computing, and system optimization methods. It includes discussions on various algorithms, frameworks, and performance analysis related to large language models and high-performance computing. The repository serves as a comprehensive resource for understanding and optimizing language models and computing systems.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.