
ScholarCopilot
Scholar Copilot is an intelligent academic writing assistant that enhances the research writing process through AI-powered text completion and citation suggestions
Stars: 86
Scholar Copilot is an intelligent academic writing assistant that enhances the research writing process through AI-powered text completion and citation suggestions. It aims to streamline academic writing while maintaining high scholarly standards. The tool provides features such as smart text generation with next-3-sentence suggestions, full section auto-completion, and context-aware writing. It also offers intelligent citation management with real-time citation suggestions, one-click citation insertion, and citation Bibtex generation. Scholar Copilot employs a unified model architecture that integrates retrieval and generation through a dynamic switching mechanism, ensuring coherent text generation with appropriate citation points.
README:
| 🚀Project Page | 📖Paper | 🤗Data | 🤗Model | 🤗Demo |
Scholar Copilot is an intelligent academic writing assistant that enhances the research writing process through AI-powered text completion and citation suggestions. Built by TIGER-Lab, it aims to streamline academic writing while maintaining high scholarly standards.
- Next-3-Sentence Suggestions: Get contextually relevant suggestions for your next three sentences
- Full Section Auto-Completion: Generate complete sections with appropriate academic structure and flow
- Context-Aware Writing: All generations consider your existing text to maintain coherence
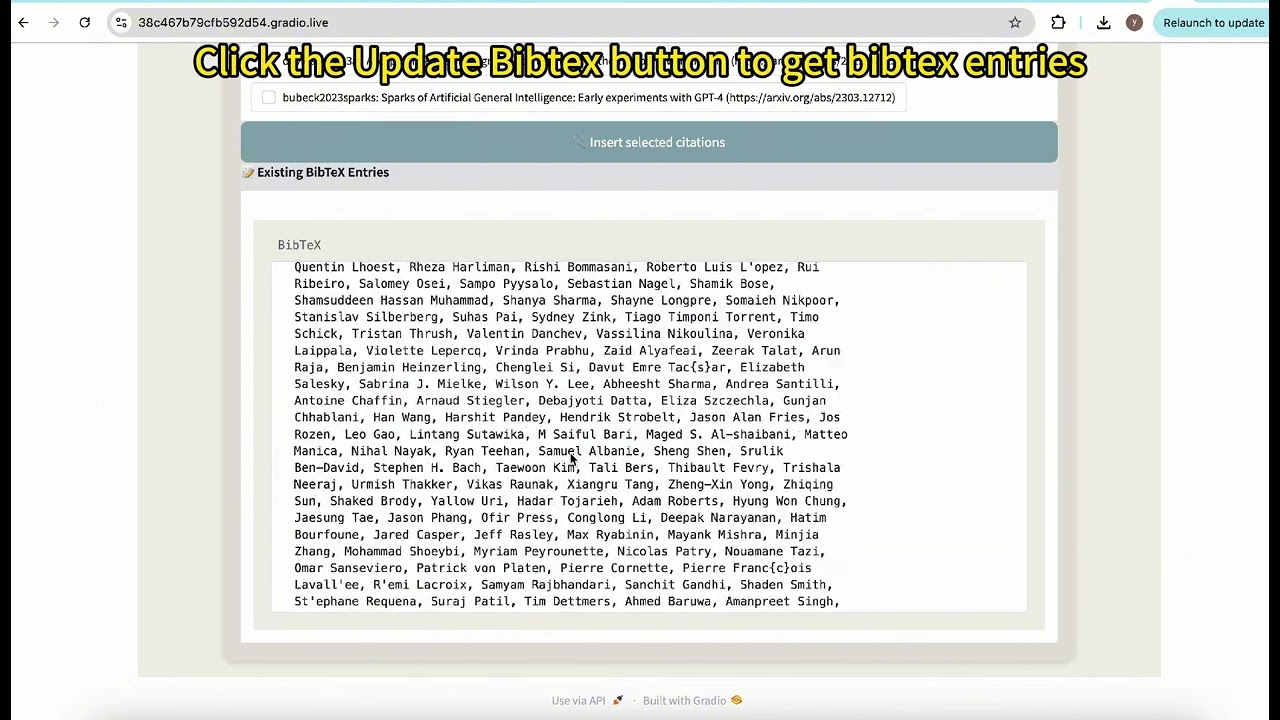
- Real-time Citation Suggestions: Receive relevant paper citations based on your writing context
- One-Click Citation Insertion: Easily select and insert citations in proper academic format
- Citation Bibtex Generation: Automatically generate and export bibtex entries for your citations
Scholar Copilot employs a unified model architecture that seamlessly integrates retrieval and generation through a dynamic switching mechanism. During the generation process, the model autonomously determines appropriate citation points using learned citation patterns. When a citation is deemed necessary, the model temporarily halts generation, utilizes the hidden states of the citation token to retrieve relevant papers from the corpus, inserts the selected references, and then resumes coherent text generation.
To set up the ScholarCopilot demo on your own server, follow these simple steps:
- Clone the repository:
git clone [email protected]:TIGER-AI-Lab/ScholarCopilot.git
cd ScholarCopilot/run_demo- Set up the environment:
pip install -r requirements.txt- Download the required model and data:
bash download.sh- Launch the demo:
bash run_demo.sh
- Download the training data:
cd train/
bash download.sh- Configure and run the training script (To reproduce our results, you can use the hyperparameters in the script and 4 machines with 8 GPUs each (32 GPUs in total).)
cd src/
bash start_train.sh@article{wang2024scholarcopilot,
title={ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations},
author = {Wang, Yubo and Ma, Xueguang and Nie, Ping and Zeng, Huaye and Lyu, Zhiheng and Zhang, Yuxuan and Schneider, Benjamin and Lu, Yi and Yue, Xiang and Chen, Wenhu},
journal={arXiv preprint arXiv:2504.00824},
year={2025}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ScholarCopilot
Similar Open Source Tools
ScholarCopilot
Scholar Copilot is an intelligent academic writing assistant that enhances the research writing process through AI-powered text completion and citation suggestions. It aims to streamline academic writing while maintaining high scholarly standards. The tool provides features such as smart text generation with next-3-sentence suggestions, full section auto-completion, and context-aware writing. It also offers intelligent citation management with real-time citation suggestions, one-click citation insertion, and citation Bibtex generation. Scholar Copilot employs a unified model architecture that integrates retrieval and generation through a dynamic switching mechanism, ensuring coherent text generation with appropriate citation points.

Controllable-RAG-Agent
This repository contains a sophisticated deterministic graph-based solution for answering complex questions using a controllable autonomous agent. The solution is designed to ensure that answers are solely based on the provided data, avoiding hallucinations. It involves various steps such as PDF loading, text preprocessing, summarization, database creation, encoding, and utilizing large language models. The algorithm follows a detailed workflow involving planning, retrieval, answering, replanning, content distillation, and performance evaluation. Heuristics and techniques implemented focus on content encoding, anonymizing questions, task breakdown, content distillation, chain of thought answering, verification, and model performance evaluation.

Docs2KG
Docs2KG is a tool designed for constructing a unified knowledge graph from heterogeneous documents. It addresses the challenges of digitizing diverse unstructured documents and constructing a high-quality knowledge graph with less effort. The tool combines bottom-up and top-down approaches, utilizing a human-LLM collaborative interface to enhance the generated knowledge graph. It organizes the knowledge graph into MetaKG, LayoutKG, and SemanticKG, providing a comprehensive view of document content. Docs2KG aims to streamline the process of knowledge graph construction and offers metrics for evaluating the quality of automatic construction.

Macaw-LLM
Macaw-LLM is a pioneering multi-modal language modeling tool that seamlessly integrates image, audio, video, and text data. It builds upon CLIP, Whisper, and LLaMA models to process and analyze multi-modal information effectively. The tool boasts features like simple and fast alignment, one-stage instruction fine-tuning, and a new multi-modal instruction dataset. It enables users to align multi-modal features efficiently, encode instructions, and generate responses across different data types.

long-llms-learning
A repository sharing the panorama of the methodology literature on Transformer architecture upgrades in Large Language Models for handling extensive context windows, with real-time updating the newest published works. It includes a survey on advancing Transformer architecture in long-context large language models, flash-ReRoPE implementation, latest news on data engineering, lightning attention, Kimi AI assistant, chatglm-6b-128k, gpt-4-turbo-preview, benchmarks like InfiniteBench and LongBench, long-LLMs-evals for evaluating methods for enhancing long-context capabilities, and LLMs-learning for learning technologies and applicated tasks about Large Language Models.

ai-data-analysis-MulitAgent
AI-Driven Research Assistant is an advanced AI-powered system utilizing specialized agents for data analysis, visualization, and report generation. It integrates LangChain, OpenAI's GPT models, and LangGraph for complex research processes. Key features include hypothesis generation, data processing, web search, code generation, and report writing. The system's unique Note Taker agent maintains project state, reducing overhead and improving context retention. System requirements include Python 3.10+ and Jupyter Notebook environment. Installation involves cloning the repository, setting up a Conda virtual environment, installing dependencies, and configuring environment variables. Usage instructions include setting data, running Jupyter Notebook, customizing research tasks, and viewing results. Main components include agents for hypothesis generation, process supervision, visualization, code writing, search, report writing, quality review, and note-taking. Workflow involves hypothesis generation, processing, quality review, and revision. Customization is possible by modifying agent creation and workflow definition. Current issues include OpenAI errors, NoteTaker efficiency, runtime optimization, and refiner improvement. Contributions via pull requests are welcome under the MIT License.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |
Advanced-Prompt-Generator
This project is an LLM-based Advanced Prompt Generator designed to automate the process of prompt engineering by enhancing given input prompts using large language models (LLMs). The tool can generate advanced prompts with minimal user input, leveraging LLM agents for optimized prompt generation. It supports gpt-4o or gpt-4o-mini, offers FastAPI & Docker deployment for efficiency, provides a Gradio interface for easy testing, and is hosted on Hugging Face Spaces for quick demos. Users can expand model support to offer more variety and flexibility.
mldl.study
MLDL.Study is a free interactive learning platform focused on simplifying Machine Learning (ML) and Deep Learning (DL) education for students and enthusiasts. It features curated roadmaps, videos, articles, and other learning materials. The platform aims to provide a comprehensive learning experience for Indian audiences, with easy-to-follow paths for ML and DL concepts, diverse resources including video tutorials and articles, and a growing community of over 6000 users. Contributors can add new resources following specific guidelines to maintain quality and relevance. Future plans include expanding content for global learners, introducing a Python programming roadmap, and creating roadmaps for fields like Generative AI and Reinforcement Learning.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

AgentCPM
AgentCPM is a series of open-source LLM agents jointly developed by THUNLP, Renmin University of China, ModelBest, and the OpenBMB community. It addresses challenges faced by agents in real-world applications such as limited long-horizon capability, autonomy, and generalization. The team focuses on building deep research capabilities for agents, releasing AgentCPM-Explore, a deep-search LLM agent, and AgentCPM-Report, a deep-research LLM agent. AgentCPM-Explore is the first open-source agent model with 4B parameters to appear on widely used long-horizon agent benchmarks. AgentCPM-Report is built on the 8B-parameter base model MiniCPM4.1, autonomously generating long-form reports with extreme performance and minimal footprint, designed for high-privacy scenarios with offline and agile local deployment.
promptbook
Promptbook is a library designed to build responsible, controlled, and transparent applications on top of large language models (LLMs). It helps users overcome limitations of LLMs like hallucinations, off-topic responses, and poor quality output by offering features such as fine-tuning models, prompt-engineering, and orchestrating multiple prompts in a pipeline. The library separates concerns, establishes a common format for prompt business logic, and handles low-level details like model selection and context size. It also provides tools for pipeline execution, caching, fine-tuning, anomaly detection, and versioning. Promptbook supports advanced techniques like Retrieval-Augmented Generation (RAG) and knowledge utilization to enhance output quality.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

saga-reader
Saga Reader is an AI-driven think tank-style reader that automatically retrieves information from the internet based on user-specified topics and preferences. It uses cloud or local large models to summarize and provide guidance, and it includes an AI-driven interactive companion reading function, allowing you to discuss and exchange ideas with AI about the content you've read. Saga Reader is completely free and open-source, meaning all data is securely stored on your own computer and is not controlled by third-party service providers. Additionally, you can manage your subscription keywords based on your interests and preferences without being disturbed by advertisements and commercialized content.
For similar tasks
ScholarCopilot
Scholar Copilot is an intelligent academic writing assistant that enhances the research writing process through AI-powered text completion and citation suggestions. It aims to streamline academic writing while maintaining high scholarly standards. The tool provides features such as smart text generation with next-3-sentence suggestions, full section auto-completion, and context-aware writing. It also offers intelligent citation management with real-time citation suggestions, one-click citation insertion, and citation Bibtex generation. Scholar Copilot employs a unified model architecture that integrates retrieval and generation through a dynamic switching mechanism, ensuring coherent text generation with appropriate citation points.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
RAGHub
RAGHub is a community-driven project focused on cataloging new and emerging frameworks, projects, and resources in the Retrieval-Augmented Generation (RAG) ecosystem. It aims to help users stay ahead of changes in the field by providing a platform for the latest innovations in RAG. The repository includes information on RAG frameworks, evaluation frameworks, optimization frameworks, citation frameworks, engines, search reranker frameworks, projects, resources, and real-world use cases across industries and professions.
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.

data-to-paper
Data-to-paper is an AI-driven framework designed to guide users through the process of conducting end-to-end scientific research, starting from raw data to the creation of comprehensive and human-verifiable research papers. The framework leverages a combination of LLM and rule-based agents to assist in tasks such as hypothesis generation, literature search, data analysis, result interpretation, and paper writing. It aims to accelerate research while maintaining key scientific values like transparency, traceability, and verifiability. The framework is field-agnostic, supports both open-goal and fixed-goal research, creates data-chained manuscripts, involves human-in-the-loop interaction, and allows for transparent replay of the research process.
nlp-phd-global-equality
This repository aims to promote global equality for individuals pursuing a PhD in NLP by providing resources and information on various aspects of the academic journey. It covers topics such as applying for a PhD, getting research opportunities, preparing for the job market, and succeeding in academia. The repository is actively updated and includes contributions from experts in the field.
AcademicForge
Academic Forge is a collection of skills integrated for academic writing workflows. It provides a curated set of skills related to academic writing and research, allowing for precise skill calls, avoiding confusion between similar skills, maintaining focus on research workflows, and receiving timely updates from original authors. The forge integrates carefully selected skills covering various areas such as bioinformatics, clinical research, data analysis, scientific writing, laboratory automation, machine learning, databases, AI research, model architectures, fine-tuning, post-training, distributed training, optimization, inference, evaluation, agents, multimodal tasks, and machine learning paper writing. It is designed to streamline the academic writing and AI research processes by providing a cohesive and community-driven collection of skills.
lmms-lab-writer
LMMs-Lab Writer is an AI-native LaTeX editor designed for researchers who prioritize ideas over syntax. It offers a local-first approach with AI agents for editing assistance, one-click LaTeX setup with automatic package installation, support for multiple languages, AI-powered workflows with OpenCode integration, Git integration for modern collaboration, fully open-source with MIT license, cross-platform compatibility, and a comparison with Overleaf highlighting its advantages. The tool aims to streamline the writing and publishing process for researchers while ensuring data security and control.
For similar jobs
SLR-FC
This repository provides a comprehensive collection of AI tools and resources to enhance literature reviews. It includes a curated list of AI tools for various tasks, such as identifying research gaps, discovering relevant papers, visualizing paper content, and summarizing text. Additionally, the repository offers materials on generative AI, effective prompts, copywriting, image creation, and showcases of AI capabilities. By leveraging these tools and resources, researchers can streamline their literature review process, gain deeper insights from scholarly literature, and improve the quality of their research outputs.
paper-ai
Paper-ai is a tool that helps you write papers using artificial intelligence. It provides features such as AI writing assistance, reference searching, and editing and formatting tools. With Paper-ai, you can quickly and easily create high-quality papers.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and follows a process of embedding docs and queries, searching for top passages, creating summaries, scoring and selecting relevant summaries, putting summaries into prompt, and generating answers. Users can customize prompts and use various models for embeddings and LLMs. The tool can be used asynchronously and supports adding documents from paths, files, or URLs.

ChatData
ChatData is a robust chat-with-documents application designed to extract information and provide answers by querying the MyScale free knowledge base or uploaded documents. It leverages the Retrieval Augmented Generation (RAG) framework, millions of Wikipedia pages, and arXiv papers. Features include self-querying retriever, VectorSQL, session management, and building a personalized knowledge base. Users can effortlessly navigate vast data, explore academic papers, and research documents. ChatData empowers researchers, students, and knowledge enthusiasts to unlock the true potential of information retrieval.

noScribe
noScribe is an AI-based software designed for automated audio transcription, specifically tailored for transcribing interviews for qualitative social research or journalistic purposes. It is a free and open-source tool that runs locally on the user's computer, ensuring data privacy. The software can differentiate between speakers and supports transcription in 99 languages. It includes a user-friendly editor for reviewing and correcting transcripts. Developed by Kai Dröge, a PhD in sociology with a background in computer science, noScribe aims to streamline the transcription process and enhance the efficiency of qualitative analysis.
AIStudyAssistant
AI Study Assistant is an app designed to enhance learning experience and boost academic performance. It serves as a personal tutor, lecture summarizer, writer, and question generator powered by Google PaLM 2. Features include interacting with an AI chatbot, summarizing lectures, generating essays, and creating practice questions. The app is built using 100% Kotlin, Jetpack Compose, Clean Architecture, and MVVM design pattern, with technologies like Ktor, Room DB, Hilt, and Kotlin coroutines. AI Study Assistant aims to provide comprehensive AI-powered assistance for students in various academic tasks.
data-to-paper
Data-to-paper is an AI-driven framework designed to guide users through the process of conducting end-to-end scientific research, starting from raw data to the creation of comprehensive and human-verifiable research papers. The framework leverages a combination of LLM and rule-based agents to assist in tasks such as hypothesis generation, literature search, data analysis, result interpretation, and paper writing. It aims to accelerate research while maintaining key scientific values like transparency, traceability, and verifiability. The framework is field-agnostic, supports both open-goal and fixed-goal research, creates data-chained manuscripts, involves human-in-the-loop interaction, and allows for transparent replay of the research process.

k2
K2 (GeoLLaMA) is a large language model for geoscience, trained on geoscience literature and fine-tuned with knowledge-intensive instruction data. It outperforms baseline models on objective and subjective tasks. The repository provides K2 weights, core data of GeoSignal, GeoBench benchmark, and code for further pretraining and instruction tuning. The model is available on Hugging Face for use. The project aims to create larger and more powerful geoscience language models in the future.