
LLM-Planner
[ICCV'23] LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
Stars: 167
LLM-Planner is a tool for few-shot grounded planning for embodied agents using large language models. It includes a high-level prompt generator and kNN dataset, allowing users to generate high-level plans for tasks by bringing their low-level controller and an LLM. The tool has been used in various research projects and provides implementation examples from different conferences. Users can cite the tool using the provided information and the tool is available under the MIT License. For questions or issues, users can contact Luke Song.
README:
Code for LLM-Planner.
Check project website for an overview and a demo.
- A high-level prompt generator and kNN dataset from our paper. Just bring your low-level controller (and an LLM)!
python hlp_planner.py
This commands uses the KNN dataset to generate a high-level plan for an example task. Check out the code for more details.
We provide examples of how the community has been using our work. We appreciate everyone's interest!
- DEDER – ICML 2024
- ReALFRED – ECCV 2024
- ExRAP – NeurIPS 2024
- FLARE – AAAI 2025
- NeSyC – ICLR 2025
- Socratic Planner – ICRA 2025
@InProceedings{song2023llmplanner,
author = {Song, Chan Hee and Wu, Jiaman and Washington, Clayton and Sadler, Brian M. and Chao, Wei-Lun and Su, Yu},
title = {LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
}
We thank OSUNLP for providing valuable feedback and suggestions.
- LLM-Planner - MIT License
Questions or issues? File an issue or contact Luke Song
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-Planner
Similar Open Source Tools
LLM-Planner
LLM-Planner is a tool for few-shot grounded planning for embodied agents using large language models. It includes a high-level prompt generator and kNN dataset, allowing users to generate high-level plans for tasks by bringing their low-level controller and an LLM. The tool has been used in various research projects and provides implementation examples from different conferences. Users can cite the tool using the provided information and the tool is available under the MIT License. For questions or issues, users can contact Luke Song.

MathCoder
MathCoder is a repository focused on enhancing mathematical reasoning by fine-tuning open-source language models to use code for modeling and deriving math equations. It introduces MathCodeInstruct dataset with solutions interleaving natural language, code, and execution results. The repository provides MathCoder models capable of generating code-based solutions for challenging math problems, achieving state-of-the-art scores on MATH and GSM8K datasets. It offers tools for model deployment, inference, and evaluation, along with a citation for referencing the work.
oat
Oat is a simple and efficient framework for running online LLM alignment algorithms. It implements a distributed Actor-Learner-Oracle architecture, with components optimized using state-of-the-art tools. Oat simplifies the experimental pipeline of LLM alignment by serving an Oracle online for preference data labeling and model evaluation. It provides a variety of oracles for simulating feedback and supports verifiable rewards. Oat's modular structure allows for easy inheritance and modification of classes, enabling rapid prototyping and experimentation with new algorithms. The framework implements cutting-edge online algorithms like PPO for math reasoning and various online exploration algorithms.
slime
Slime is an LLM post-training framework for RL scaling that provides high-performance training and flexible data generation capabilities. It connects Megatron with SGLang for efficient training and enables custom data generation workflows through server-based engines. The framework includes modules for training, rollout, and data buffer management, offering a comprehensive solution for RL scaling.
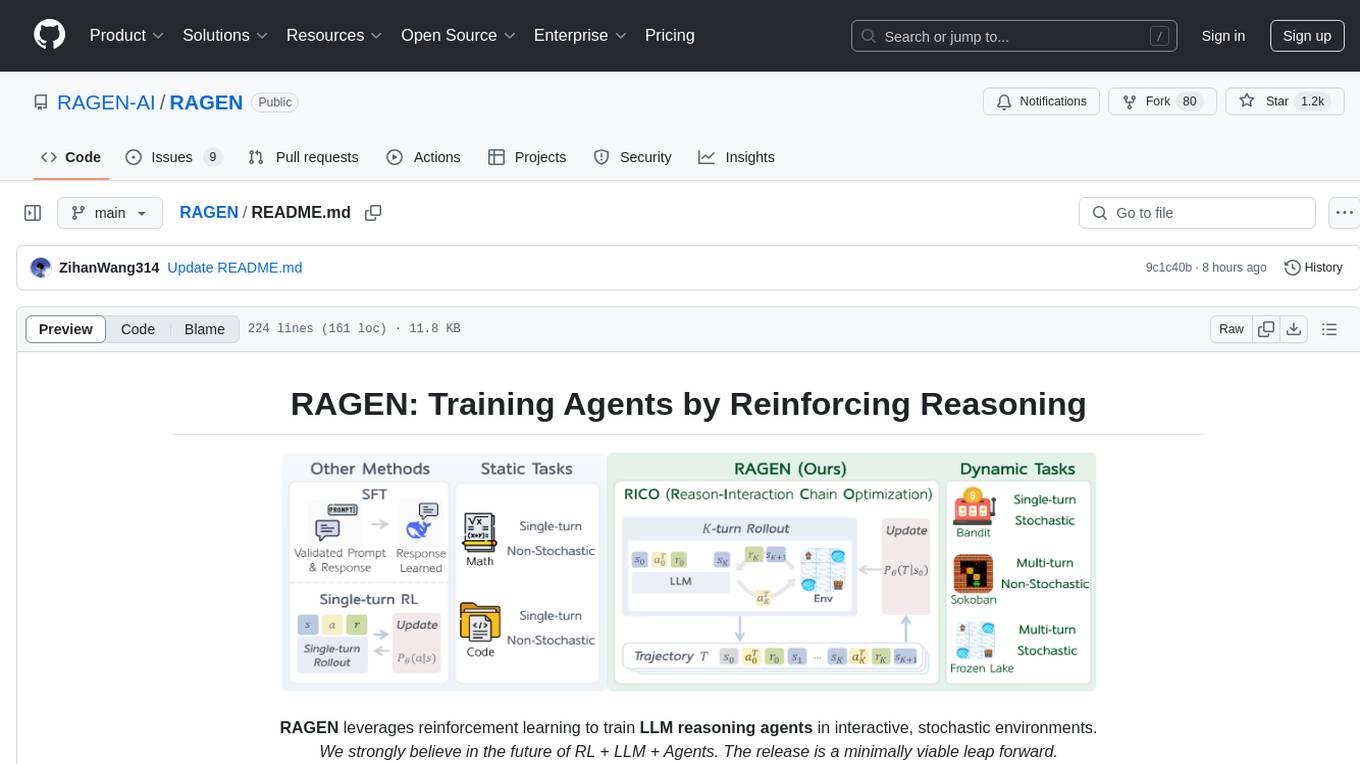
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework consists of MDP formulation, RICO algorithm with rollout and update stages, and reward normalization strategies to stabilize training. RAGEN aims to optimize reasoning and action strategies for LLM agents operating in complex environments.
ScholarCopilot
Scholar Copilot is an intelligent academic writing assistant that enhances the research writing process through AI-powered text completion and citation suggestions. It aims to streamline academic writing while maintaining high scholarly standards. The tool provides features such as smart text generation with next-3-sentence suggestions, full section auto-completion, and context-aware writing. It also offers intelligent citation management with real-time citation suggestions, one-click citation insertion, and citation Bibtex generation. Scholar Copilot employs a unified model architecture that integrates retrieval and generation through a dynamic switching mechanism, ensuring coherent text generation with appropriate citation points.
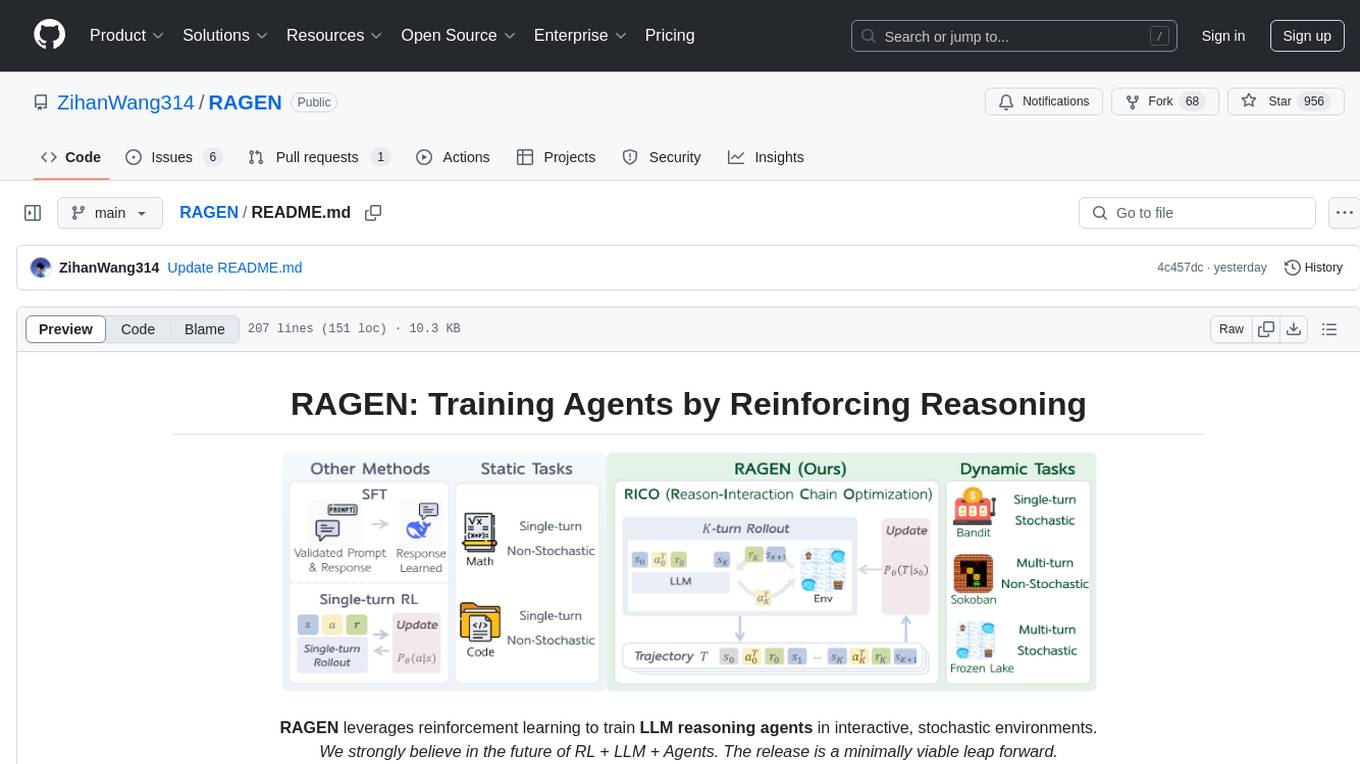
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.

RetouchGPT
RetouchGPT is a novel framework designed for interactive face retouching using Large Language Models (LLMs). It leverages instruction-driven imperfection prediction and LLM-based embedding to guide the retouching process. The tool allows users to interactively modify imperfection features in face images, achieving high-fidelity retouching results. RetouchGPT outperforms existing methods by integrating textual and visual features to accurately identify imperfections and replace them with normal skin features.
Mooncake
Mooncake is a serving platform for Kimi, a leading LLM service provided by Moonshot AI. It features a KVCache-centric disaggregated architecture that separates prefill and decoding clusters, leveraging underutilized CPU, DRAM, and SSD resources of the GPU cluster. Mooncake's scheduler balances throughput and latency-related SLOs, with a prediction-based early rejection policy for highly overloaded scenarios. It excels in long-context scenarios, achieving up to a 525% increase in throughput while handling 75% more requests under real workloads.

dash-infer
DashInfer is a C++ runtime tool designed to deliver production-level implementations highly optimized for various hardware architectures, including x86 and ARMv9. It supports Continuous Batching and NUMA-Aware capabilities for CPU, and can fully utilize modern server-grade CPUs to host large language models (LLMs) up to 14B in size. With lightweight architecture, high precision, support for mainstream open-source LLMs, post-training quantization, optimized computation kernels, NUMA-aware design, and multi-language API interfaces, DashInfer provides a versatile solution for efficient inference tasks. It supports x86 CPUs with AVX2 instruction set and ARMv9 CPUs with SVE instruction set, along with various data types like FP32, BF16, and InstantQuant. DashInfer also offers single-NUMA and multi-NUMA architectures for model inference, with detailed performance tests and inference accuracy evaluations available. The tool is supported on mainstream Linux server operating systems and provides documentation and examples for easy integration and usage.

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.

Reflection_Tuning
Reflection-Tuning is a project focused on improving the quality of instruction-tuning data through a reflection-based method. It introduces Selective Reflection-Tuning, where the student model can decide whether to accept the improvements made by the teacher model. The project aims to generate high-quality instruction-response pairs by defining specific criteria for the oracle model to follow and respond to. It also evaluates the efficacy and relevance of instruction-response pairs using the r-IFD metric. The project provides code for reflection and selection processes, along with data and model weights for both V1 and V2 methods.

Adaptive-MT-LLM-Fine-tuning
The repository Adaptive-MT-LLM-Fine-tuning contains code and data for the paper 'Fine-tuning Large Language Models for Adaptive Machine Translation'. It focuses on enhancing Mistral 7B, a large language model, for real-time adaptive machine translation in the medical domain. The fine-tuning process involves using zero-shot and one-shot translation prompts to improve terminology and style adherence. The repository includes training and test data, data processing code, fuzzy match retrieval techniques, fine-tuning methods, conversion to CTranslate2 format, tokenizers, translation codes, and evaluation metrics.

FloTorch
FloTorch is an innovative product designed to simplify and optimize the decision-making process for leveraging Large Language Models (LLMs) in Retrieval Augmented Generation (RAG) systems. It focuses on providing a well-architected framework, maximizing efficiency, eliminating complexity, accelerating selection, and fostering innovation. The tool offers a streamlined, user-friendly approach to help users achieve efficiency, accuracy, and cost-effectiveness in the fast-paced digital landscape of AI.

siiRL
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.
For similar tasks
LLM-Planner
LLM-Planner is a tool for few-shot grounded planning for embodied agents using large language models. It includes a high-level prompt generator and kNN dataset, allowing users to generate high-level plans for tasks by bringing their low-level controller and an LLM. The tool has been used in various research projects and provides implementation examples from different conferences. Users can cite the tool using the provided information and the tool is available under the MIT License. For questions or issues, users can contact Luke Song.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.
GenAI-Showcase
The Generative AI Use Cases Repository showcases a wide range of applications in generative AI, including Retrieval-Augmented Generation (RAG), AI Agents, and industry-specific use cases. It provides practical notebooks and guidance on utilizing frameworks such as LlamaIndex and LangChain, and demonstrates how to integrate models from leading AI research companies like Anthropic and OpenAI.
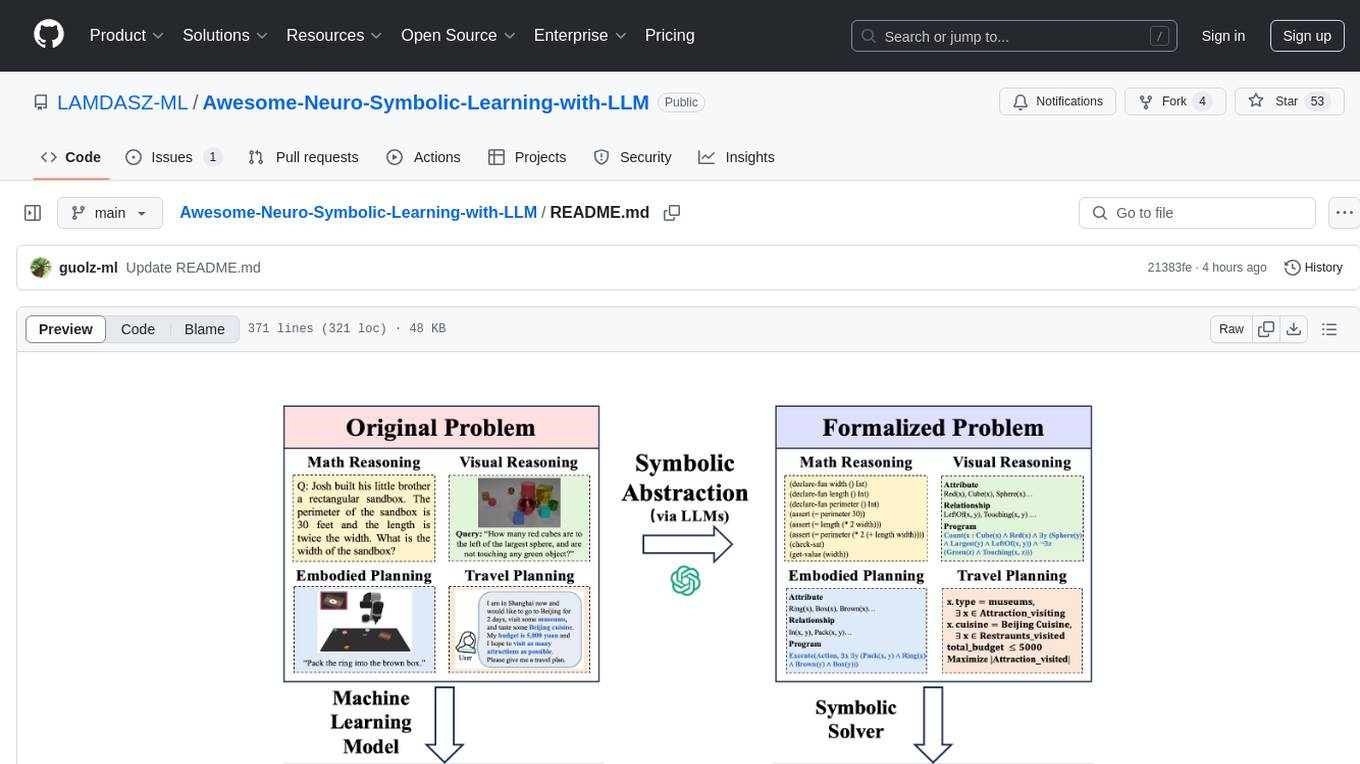
Awesome-Neuro-Symbolic-Learning-with-LLM
The Awesome-Neuro-Symbolic-Learning-with-LLM repository is a curated collection of papers and resources focusing on improving reasoning and planning capabilities of Large Language Models (LLMs) and Multi-Modal Large Language Models (MLLMs) through neuro-symbolic learning. It covers a wide range of topics such as neuro-symbolic visual reasoning, program synthesis, logical reasoning, mathematical reasoning, code generation, visual reasoning, geometric reasoning, classical planning, game AI planning, robotic planning, AI agent planning, and more. The repository provides a comprehensive overview of tutorials, workshops, talks, surveys, papers, datasets, and benchmarks related to neuro-symbolic learning with LLMs and MLLMs.
ST-Raptor
ST-Raptor is a powerful open-source tool for analyzing and visualizing spatial-temporal data. It provides a user-friendly interface for exploring complex datasets and generating insightful visualizations. With ST-Raptor, users can easily identify patterns, trends, and anomalies in their spatial-temporal data, making it ideal for researchers, analysts, and data scientists working with geospatial and time-series data.
dataset-viewer
Dataset Viewer is a modern, high-performance tool built with Tauri, React, and TypeScript, designed to handle massive datasets from multiple sources with efficient streaming for large files (100GB+) and lightning-fast search capabilities. It supports instant large file opening, real-time search, direct archive preview, multi-protocol and multi-format support, and features a modern interface with dark/light themes and responsive design. The tool is perfect for data scientists, log analysis, archive management, remote access, and performance-critical tasks.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.