
WeeaBlind
A program to dub non-english media with modern AI speech synthesis, diarization, and voice cloning!
Stars: 168
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
README:
A program to dub multi-lingual media and anime using modern AI speech synthesis, diarization, language identification, and voice cloning.
![]()
You can try the first binary version which has access to basic dubbing features with the non-AI based libraries for Windows and Linux. This is a good way to try out the program and you can still do basic dubbing with the system voices. If you want to use the advanced features' you'll have to try out the advanced features as described in the setup tutorial.
I made this video to show off how to use all the features and everything the softwwware can do presently

Many shows, movies, news segments, interviews, and videos will never receive proper dubs to other languages, and dubbing something from scratch can be an enormous undertaking. This presents a common accessibility hurdle for people with blindness, dyslexia, learning disabilities, or simply folks that don't enjoy reading subtitles. This program aims to create a pleasant alternative for folks facing these struggles.
This software is a product of war. My sister turned me onto my now-favorite comedy anime "The Disastrous Life of Saiki K." but Netflix never ordered a dub for the 2nd season. I'm blind and cannot and will not ever be able to read subtitles, but I MUST know how the story progresses! Netflix has forced my hand and I will bring AI-dubbed anime to the blind!
This project relies on some rudimentary slapping together of some state of the art technologies. It uses numerous audio processing libraries and techniques to analyze and synthesize speech that tries to stay in-line with the source video file. It primarily relies on ffmpeg and pydub for audio and video editing, Coqui TTS for speech synthesis, speechbrain for language identification, and pyannote.audio for speaker diarization.
You have the option of dubbing every subtitle in the video, setting the s tart and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
This project is currently what some might call in alpha. The major, core functionality is in place, and it's possible to use by cloning the repo, but it's only starting to be ready for a first release. There are numerous optimizations, UX, and refactoring that need to be done before I would call it finished. Stay tuned for regular updates, and feel free to extend a hand with contributions, testing, or suggestions if this is something you're interested in.
I had the idea to call the software Weeablind as a portmanteaux of Weeaboo (someone a little too obsessed with anime), and blind. I might change it to something else in the future like Blindtaku, DubHub, or something similar and more catchy because the software can be used for far more than just anime.
There are currently no prebuilt-binaries to download, this is something I am looking into, but many of these dependencies are not easy to bundle with something like PyInstaller
The program works best on Linux, but will also run on Windows.
You will need to install FFmpeg on your system and make sure it's callable from terminal or in your system PATH
For using Coqui TTS, you will also need Espeak-NG which you can get from your package manager on Linux or here on Windows
On Windows, pip requires MSVC Build Tools to build Coqui. You can install it here: https://visualstudio.microsoft.com/visual-cpp-build-tools/
Coqui TTS and Pyannote diarization will also both perform better if you have CUDA set up on your system to use your GPU. This should work out of the box on Linux but getting it set up on Windows takes some doing. This blog post should walk you through the process. If you can't get it working, don't fret, you can still use them on your CPU.
The latest version of Python works on Linux, but Spleeter only works on 3.10 and Pyannote can be finicky with that too. 3.10 seems to work the best on on Windows. You can get it from the Microsoft Store.
To use the project, you'll need to clone the repository and install the dependencies in a virtual enviormonet.
git clone https://github.com/FlorianEagox/weeablind.git
cd weeablind
python3.10 -m venv venv
# Windows
.\venv\Scripts\activate
# Linux
source ./venv/bin/activate
This project has a lot of dependencies, and pip can struggle with conflicts, so it's best to install from the lock file like this:
pip install -r requirements-win-310.txt --no-deps
You can try from the regular requirements file, but it can take a heck of a long time and requires some rejiggering sometimes.
Installing the dependencies can take a hot minute and uses a lot of space (~8 GB).
If you don't need certain features for instance, language filtering, you can omit speechbrain from the readme.
once this is completed, you can run the program with
python weeablind.py
Start by either selecting a video from your computer or pasting a link to a YT video and pressing enter. It should download the video and lot the subs and audio.
Once a video is loaded, you can preview the subtitles that will be dubbed. If the wrong language is loaded, or the wrong audio stream, switch to the streams tab and select the correct ones.
You can specify a start and end time if you only need to dub a section of the video, for example to skip the opening theme and credits of a show. Use timecode syntax like 2:17 and press enter.
By default, a "Sample" voice should be initialized. You can play around with different configurations and test the voice before dubbing with the "Sample Voice" button in the "Configure Voices" tab. When you have parameters you're happy with, clicking "Update Voices" will re-asign it to that slot. If you choose the SYSTEM tts engine, the program will use Windows' SAPI5 Narrorator or Linux espeak voices by default. This is extremely fast but sounds very robotic. Selecting Coqui gives you a TON of options to play around with, but you will be prompted to download often very heavy TTS models. VCTK/VITS is my favorite model to dub with as it's very quick, even on CPU, and there are hundreds of speakers to choose from. It is loaded by default. If you have ran diarization, you can select different voices from the listbox and change their properties as well.
In the subtitles tab, you filter the subtitles to exclude lines spoken in your selected language so only the foreign language gets dubbed. This is useful for multi-lingual videos, but not videos all in one language.
Running diarization will attempt to assign the correct speaker to all the subtitles and generate random voices for the total number of speakers detected. In the futre, you'll be able to specify the diarization pipeline and number of speakers if you know ahead of time. Diarization is only useful for videos with multiple speakers and the accuracy can very massively.
In the "Streams" tab, you can run vocal isolation which will attempt to remove the vocals from your source video track but retain the background. If you're using a multi-lingual video and running language filtering as well, you'll need to run that first to keep the english (or whatever source language's vocals).
Once you've configured things how you like, you can press the big, JUICY run dubbing button. This can take a while to run. Once completed, you should have something like "MyVideo-dubbed.mkv" in the output directory. This is your finished video!
A better filtering system for language detection. Maybe inclusive and exclusive or confidence threshhold- Find some less copyrighted multi-lingual / non-english content to display demos publicly
de-anglicanization it so the user can select their target language instead of just English- FIX PYDUB'S STUPID ARRAY DISTORTION so we don't have to perform 5 IO operations per dub!!!
run a vocal isolation / remover on the source audio to remove / mitigate the original speakers?A proper setup guide for all platformsremove or fix the broken espeak implementation to be cross-platformUninitialized, singletons for heavy models upon startup (e.g. only intialize pyannote/speechbrain pipelines when needed)- Abstraction for singletons of Coqui voices using the same model to reduce memory footprint
GUI tab to list and select audio / subtitle streams w/ FFMPEGMove the tabs into their own classesAdd labels and screen reader landmarks to all the controlsSingle speaker or multi speaker control switchDownload YouTube video with Closed CaptionsGUI to select start and end time for dubbing- Throw up a Flask server on my website so you can try it with minimal features.
Use OCR to generate subtitles for videos that don't have sub streamsUse OCR for non-text based subtitlesMake a cool logo?Learn how to package python programs as binaries to make releasesRemove the copyrighted content from this repo (sorry not sorry TV Tokyo)Support for all subtitle formats- Maybe slap in an ASR library for videos without subtitles?
- Maybe support for magnet URLs or the arrLib to pirate media (who knows???)
- Filter subtitles by the selected voice from the listbox
- Select from multiple diarization models / pipelines
- Optimize audio trakcs for diarizaiton by isolating lines speech based on subtitle timings
- Investigate Diart?
Rework the speed control to use PyDub to speed up audio.match the volume of the speaker to TTS- Checkbox to remove sequential subtitle entries and entries that are tiny, e.g. "nom" "nom" "nom" "nom"~~
investigate voice conversion?- Build an asynchronous queue of operations to perform
Asynchronous GUI for Coqui model downloads- Add support for MyCroft Mimic 3
- Add Support for PiperTTS
Create a cloning mode to select subtitles and export them to a dataset or wav compilation for Coqui XTTS- Use diaries and subtitles to isolate and build training datasets
- Build a tool to streamline the manual creation of datasets
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for WeeaBlind
Similar Open Source Tools
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
bidirectional_streaming_ai_voice
This repository contains Python scripts that enable two-way voice conversations with Anthropic Claude, utilizing ElevenLabs for text-to-speech, Faster-Whisper for speech-to-text, and Pygame for audio playback. The tool operates by transcribing human audio using Faster-Whisper, sending the transcription to Anthropic Claude for response generation, and converting the LLM's response into audio using ElevenLabs. The audio is then played back through Pygame, allowing for a seamless and interactive conversation between the user and the AI. The repository includes variations of the main script to support different operating systems and configurations, such as using CPU transcription on Linux or employing the AssemblyAI API instead of Faster-Whisper.
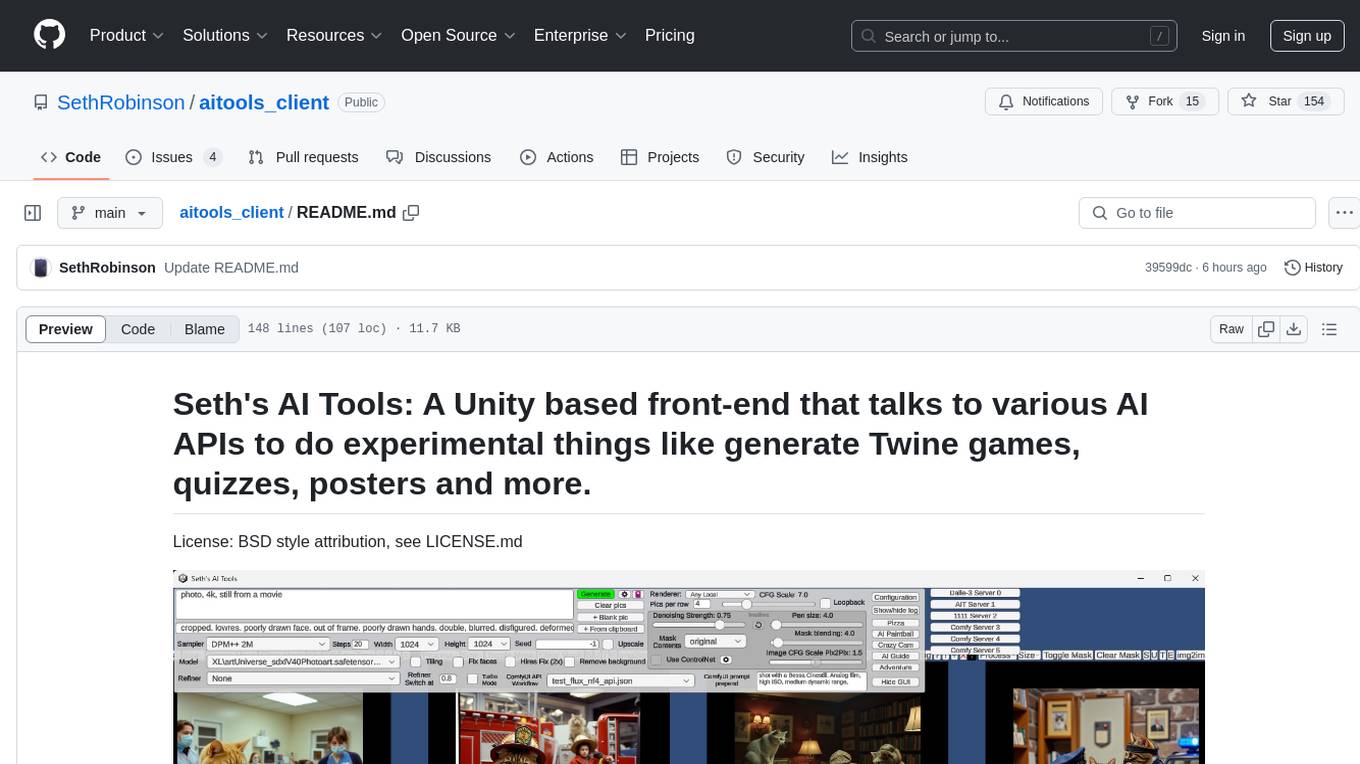
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
aicodeguide
AI Code Guide is a comprehensive guide that covers everything you need to know about using AI to help you code or even code for you. It provides insights into the changing landscape of coding with AI, new tools, editors, and practices. The guide aims to consolidate information on AI coding and AI-assisted code generation in one accessible place. It caters to both experienced coders looking to leverage AI tools and beginners interested in 'vibe coding' to build software products. The guide covers various topics such as AI coding practices, different ways to use AI in coding, recommended resources, tools for AI coding, best practices for structuring prompts, and tips for using specific tools like Claude Code.
iris-llm
iris-llm is a personal project aimed at creating an Intelligent Residential Integration System (IRIS) with a voice interface to local language models or GPT. It provides options for chat engines, text-to-speech engines, speech-to-text engines, feedback sounds, and push-to-talk or wake word features. The tool is still in early development and serves as a tutorial for Python coders interested in working with language models.
ai-agents-masterclass
AI Agents Masterclass is a repository dedicated to teaching developers how to use AI agents to transform businesses and create powerful software. It provides weekly videos with accompanying code folders, guiding users on setting up Python environments, using environment variables, and installing necessary packages to run the code. The focus is on Large Language Models that can interact with the outside world to perform tasks like drafting emails, booking appointments, and managing tasks, enabling users to create innovative applications with minimal coding effort.
wtffmpeg
wtffmpeg is a command-line tool that uses a Large Language Model (LLM) to translate plain-English descriptions of video or audio tasks into actual, executable ffmpeg commands. It aims to streamline the process of generating ffmpeg commands by allowing users to describe what they want to do in natural language, review the generated command, optionally edit it, and then decide whether to run it. The tool provides an interactive REPL interface where users can input their commands, retain conversational context, and history, and control the level of interactivity. wtffmpeg is designed to assist users in efficiently working with ffmpeg commands, reducing the need to search for solutions, read lengthy explanations, and manually adjust commands.
ClipboardConqueror
Clipboard Conqueror is a multi-platform omnipresent copilot alternative. Currently requiring a kobold united or openAI compatible back end, this software brings powerful LLM based tools to any text field, the universal copilot you deserve. It simply works anywhere. No need to sign in, no required key. Provided you are using local AI, CC is a data secure alternative integration provided you trust whatever backend you use. *Special thank you to the creators of KoboldAi, KoboldCPP, llamma, openAi, and the communities that made all this possible to figure out.
AnnA_Anki_neuronal_Appendix
AnnA is a Python script designed to create filtered decks in optimal review order for Anki flashcards. It uses Machine Learning / AI to ensure semantically linked cards are reviewed far apart. The script helps users manage their daily reviews by creating special filtered decks that prioritize reviewing cards that are most different from the rest. It also allows users to reduce the number of daily reviews while increasing retention and automatically identifies semantic neighbors for each note.

local-chat
LocalChat is a simple, easy-to-set-up, and open-source local AI chat tool that allows users to interact with generative language models on their own computers without transmitting data to a cloud server. It provides a chat-like interface for users to experience ChatGPT-like behavior locally, ensuring GDPR compliance and data privacy. Users can download LocalChat for macOS, Windows, or Linux to chat with open-weight generative language models.

chaiNNer
ChaiNNer is a node-based image processing GUI aimed at making chaining image processing tasks easy and customizable. It gives users a high level of control over their processing pipeline and allows them to perform complex tasks by connecting nodes together. ChaiNNer is cross-platform, supporting Windows, MacOS, and Linux. It features an intuitive drag-and-drop interface, making it easy to create and modify processing chains. Additionally, ChaiNNer offers a wide range of nodes for various image processing tasks, including upscaling, denoising, sharpening, and color correction. It also supports batch processing, allowing users to process multiple images or videos at once.
RTranslator
RTranslator is an almost open-source, free, and offline real-time translation app for Android. It offers Conversation mode for multi-user translations, WalkieTalkie mode for quick conversations, and Text translation mode. It uses Meta's NLLB for translation and OpenAi's Whisper for speech recognition, ensuring privacy. The app is optimized for performance and supports multiple languages. It is ad-free and donation-supported.
LLocalSearch
LLocalSearch is a completely locally running search aggregator using LLM Agents. The user can ask a question and the system will use a chain of LLMs to find the answer. The user can see the progress of the agents and the final answer. No OpenAI or Google API keys are needed.
discourse-chatbot
The discourse-chatbot is an original AI chatbot for Discourse forums that allows users to converse with the bot in posts or chat channels. Users can customize the character of the bot, enable RAG mode for expert answers, search Wikipedia, news, and Google, provide market data, perform accurate math calculations, and experiment with vision support. The bot uses cutting-edge Open AI API and supports Azure and proxy server connections. It includes a quota system for access management and can be used in RAG mode or basic bot mode. The setup involves creating embeddings to make the bot aware of forum content and setting up bot access permissions based on trust levels. Users must obtain an API token from Open AI and configure group quotas to interact with the bot. The plugin is extensible to support other cloud bots and content search beyond the provided set.
dota2ai
The Dota2 AI Framework project aims to provide a framework for creating AI bots for Dota2, focusing on coordination and teamwork. It offers a LUA sandbox for scripting, allowing developers to code bots that can compete in standard matches. The project acts as a proxy between the game and a web service through JSON objects, enabling bots to perform actions like moving, attacking, casting spells, and buying items. It encourages contributions and aims to enhance the AI capabilities in Dota2 modding.

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
For similar tasks
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

TeroSubtitler
Tero Subtitler is an open source, cross-platform, and free subtitle editing software with a user-friendly interface. It offers fully fledged editing with SMPTE and MEDIA modes, support for various subtitle formats, multi-level undo/redo, search and replace, auto-backup, source and transcription modes, translation memory, audiovisual preview, timeline with waveform visualizer, manipulation tools, formatting options, quality control features, translation and transcription capabilities, validation tools, automation for correcting errors, and more. It also includes features like exporting subtitles to MP3, importing/exporting Blu-ray SUP format, generating blank video, generating video with hardcoded subtitles, video dubbing, and more. The tool utilizes powerful multimedia playback engines like mpv, advanced audio/video manipulation tools like FFmpeg, tools for automatic transcription like whisper.cpp/Faster-Whisper, auto-translation API like Google Translate, and ElevenLabs TTS for video dubbing.
open-dubbing
Open dubbing is an AI dubbing system that uses machine learning models to automatically translate and synchronize audio dialogue into different languages. It is designed as a command line tool. The project is experimental and aims to explore speech-to-text, text-to-speech, and translation systems combined. It supports multiple text-to-speech engines, translation engines, and gender voice detection. The tool can automatically dub videos, detect source language, and is built on open-source models. The roadmap includes better voice control, optimization for long videos, and support for multiple video input formats. Users can post-edit dubbed files by manually adjusting text, voice, and timings. Supported languages vary based on the combination of systems used.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
Synthalingua
Synthalingua is an advanced, self-hosted tool that leverages artificial intelligence to translate audio from various languages into English in near real time. It offers multilingual outputs and utilizes GPU and CPU resources for optimized performance. Although currently in beta, it is actively developed with regular updates to enhance capabilities. The tool is not intended for professional use but for fun, language learning, and enjoying content at a reasonable pace. Users must ensure speakers speak clearly for accurate translations. It is not a replacement for human translators and users assume their own risk and liability when using the tool.
duolingo-clone
Lingo is an interactive platform for language learning that provides a modern UI/UX experience. It offers features like courses, quests, and a shop for users to engage with. The tech stack includes React JS, Next JS, Typescript, Tailwind CSS, Vercel, and Postgresql. Users can contribute to the project by submitting changes via pull requests. The platform utilizes resources from CodeWithAntonio, Kenney Assets, Freesound, Elevenlabs AI, and Flagpack. Key dependencies include @clerk/nextjs, @neondatabase/serverless, @radix-ui/react-avatar, and more. Users can follow the project creator on GitHub and Twitter, as well as subscribe to their YouTube channel for updates. To learn more about Next.js, users can refer to the Next.js documentation and interactive tutorial.
For similar jobs
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
talk-to-chatgpt
Talk-To-ChatGPT is a Google Chrome and Microsoft Edge extension that enables users to interact with the ChatGPT AI using voice commands for speech recognition and text-to-speech responses. The tool enhances the conversational experience by allowing users to speak to the AI and receive spoken responses, making interactions more natural and engaging. It also supports ElevenLabs API integration for creating custom voices for text-to-speech. The extension provides settings for voice, language, and more, and can be installed from the Chrome and Edge web stores or manually. While the project has been discontinued due to upcoming desktop apps from OpenAI, it has been used to assist individuals with disabilities and the elderly in interacting with ChatGPT.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.