
aitools_client
Seth's AI Tools: A Unity based front end that uses ComfyUI and LLMs to create stories, images, movies, quizzes and posters
Stars: 163
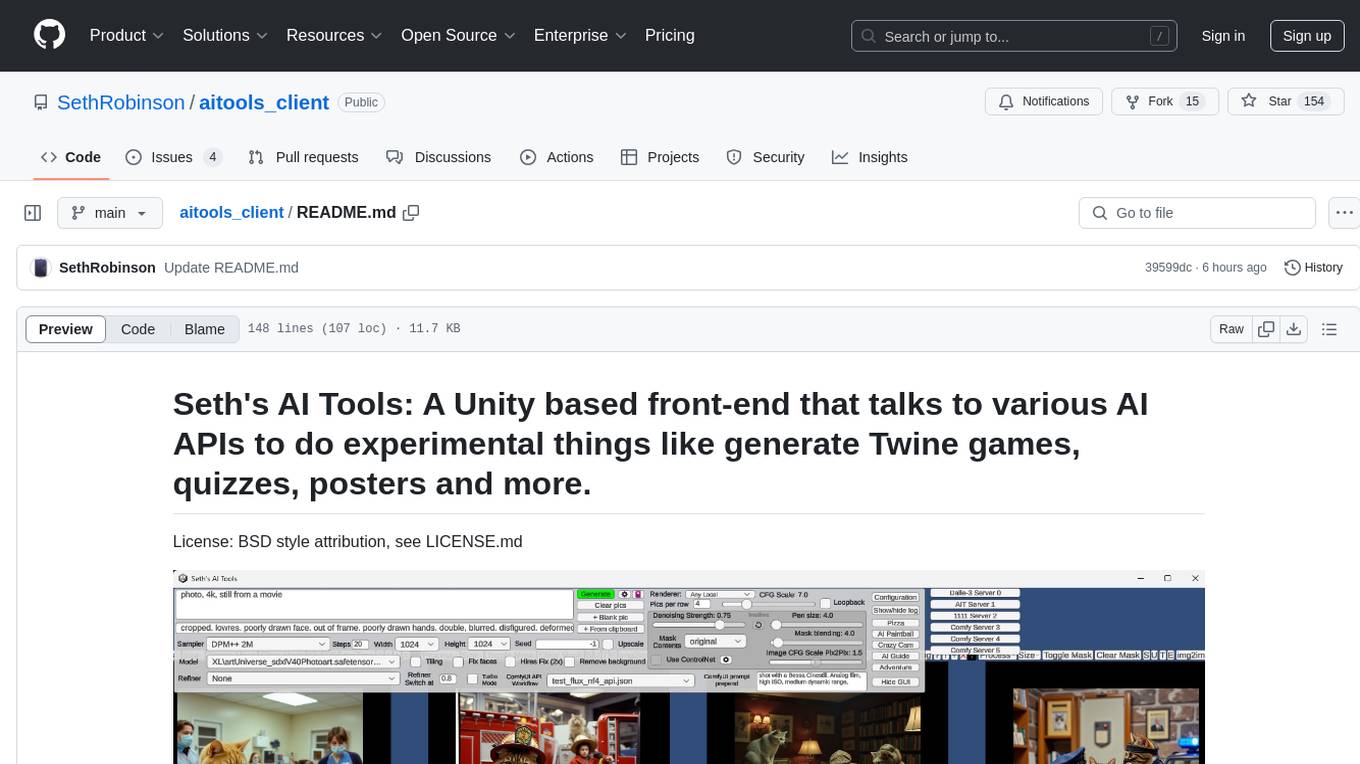
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
README:
Seth's AI Tools: A Unity based front-end for ComfyUI and Ollama (and others) that does things like generate photos and movies, Twine games, quizzes, posters and more.
License: BSD style attribution, see LICENSE.md

Download the latest version: V2.00 (Feb 25th, 2025) AI Tools Client (Windows, 62 MB)
Need an old version? The last pre-V2 version (that still supports Auto1111) can be downloaded here.
To use this, you'll need to connect to something that can generate images, and hopefully an LLM too. A single OpenAI key is enough to do a lot (LLM and Dale3 rendering), you can also use Claude (via API key), or best yet, your own local ComfyUI server(s) and Ollama.
- It's not a web app, it's a native locally run Windows .exe
- It's kind of like lego, is can run ComfyUI workflows that chain together. You need to understand ComyUI and workflow tweaking as you'll still need to install all the needed custom nodes and models there. (you do have ComfyUI Manager installed, right?!)
- Drag and drop images in as well as paste images from the windows clipboard
- Built-in image processing like cropping and resizing, mask painting
- Pan/zoom with thousands of images on the screen
- Built to utilize many ComfyUI servers at once
- Privacy respected - does not phone home or collect any statistics, purely local usage. (it does check a single file on github.com to check for newer versions, but that's it)
- Includes "experiments", little built-in games and apps designed to test AI
- AI Guide feature harnesses the power of AI to create motivational posters, illustrated stories or whatever
- Adventure mode has presets to various modes - generate ready to upload illustrated web quiz from prompt, simple Twine game project from a prompt, and "Adventure", a sort of illustrated AI Dungeon type of toy
- Includes presets and workflows for Flux, SDXL, Hunyuan, Wan 2.1, MMAudio, SAM2, BiRef
- By default strips tags when continuing LLM work for Deepseek/thinking models
- For developers, using Unity and C# to do powerful things with AI instead of banging your head against the wall with ComfyUI workflows and python is pretty sweet
- You can drag in a bunch of pictures and have it turn them into tiny movies with sound. How cool is that?
- I ripped out the A1111 support, it's ComfyUI all the way now. It's a big step and it broke things, so the paintball game and pizza thing are removed. Most of the other things still work. Crazy Camera sort of works, I fix it up later when I need it, it works using the new workflow/joblist system but it's too slow. I've versions to V2 to make it clear it's not the old version anymore.
- Introduces a whole new preset "joblist" system that strings together ComfyUI workflows, there are too many changes to list. Making your own presets and worklows should be much simpler now.
- This project is entirely for fun, please pardon the lack of documentation and ease of use. I'll try to help if you post problems here as issues or in the discussion area though!
- I suspect certain workflows won't work on Windows because I have a subdir in the model filename and the whole "/" vs "\" thing rears its ugly head. Why wouldn't ComfyUI fix those based on the system it's running on? Anyway, you can either use a @replace to fix them in AITools, or edit the workflow's .json with a text editor, or drag the workflow into ComfyUI and edit the path there. I only test on Windows, with the servers running on Ubuntu.
- Lack of documentation etc due to laziness
- CrazyCam (where the webcam is being used for realtime image processing) is half broken and slow
- Expect things to break and change, it's very alpha and probably always will be
- Probably a ton of bugs, I haven't tested it much
- The SDXL Inpainting ComfyUI workflow sometimes fails, tweaking the alpha mask fixes it, no idea what's up but it's not happening on my app's side
- The SAM2 based "select things by name" segmentation is pretty sketch, best I could find though. Also, it can only select ONE thing in the image, I don't see a way to fix it without writing a custom node. Use the including BiRef workflow instead if you can, it can only do "foreground" and "background" but it works much better in general.
- It can use all of OpenAI's APIs unless you set it to o1-mini, OpenAI doesn't like the format and gives an error. gpt-4o and o3-mini work fine so whatever I guess.
You only need to download the zip and run the .exe to use this, However, the source might be useful to generate a build for other platforms, fork or steal pieces to use for yourself. Go ahead!










Your ComfyUI server needs to be started using the --listen parm, so the API can be accessed.
After running it, a config.txt will be made. There is an config edit button inside the app, your config will look like this:
#add as many add_server commands as you want, just replace the localhost:7860 part with the
#server name/ip and port. You can control any number of renderer servers at the same time.
#This is where you add rendering servers. (ComfyUI servers run with --listen parm) For Dalle-3, don't set here, just enter your OpenAI key below.
#Uncomment below and put your renderer server. Add more add_server commands to add as many as you want. The second parm is
#an optional name so you can keep track of which server has which video card.
#add_server|http://localhost:7860|5090!|
#Set the below path and .exe to an image editor to use the Edit option. Changed files will auto
#update in here.
set_image_editor|C:\Program Files\Adobe\Adobe Photoshop 2025\Photoshop.exe
#To generate text with the AI Guide features, you need at least one LLM. (or all, you can switch between them in the app)
#OPENAI (works for LLM and Dalle-3 as renderer)
set_openai_gpt4_key|<key goes here>|
set_openai_gpt4_model|gpt-4o|
set_openai_gpt4_endpoint|https://api.openai.com/v1/chat/completions|
#address of your generic LLM to use, can be local, on your LAN, remote, etc (text-generation-webui or TabbyAPI API format)
set_generic_llm_address|localhost:5000|
#if your generic LLM needs a key, enter it here (or leave as "none")
set_generic_llm_api_key|none|
#what we tell the model to use. If you notice the llm is forgetting things or messing up, your model might not be an instruct-compatible model, try llama 3.3 with Ollama as a test.
set_generic_llm_mode|chat-instruct|
#this is needed if using an ollama server, otherwise you'll see a "model is required" error. Note that might cause the model to be loaded which means a huge delay at first.
add_generic_llm_parm|model|"llama3.3"|#needed for ollama, the model you want to use
#add_generic_llm_parm|num_ctx|131072|#needed for ollama, the context size you want the model to load with (we'll create a custom profile with an _ait extension)
#add_generic_llm_parm|temperature|1.0|#allows you to globally override LLM temperatures
#add_generic_llm_parm|max_tokens|4096|
#some things you could play with
#add_generic_llm_parm|stop|["<`eot_id`>", "<`eom_id`>", "<`end_header_id`>"]|#Note that ` gets turned into |
#add_generic_llm_parm|stopping_strings|["<`eot_id`>", "<`eom_id`>", "<`end_header_id`>"]|
#the following allow you to override the default system, assistant, and user keywords for the generic LLM, if needed.
#different LLMs are trained on different words, if the llm server you use doesn't hide this from you, you might notice weird
#or buggy behavior if these aren't changed to match what that specific llm wants
#set_generic_llm_system_keyword|system|#default is system
#set_generic_llm_assistant_keyword|assistant|#default is assistant
#set_generic_llm_user_keyword|user|#default is user
#Anthropic LLM
set_anthropic_ai_key|<key goes here>|
set_anthropic_ai_model|claude-3-7-sonnet-latest|
set_anthropic_ai_endpoint|https://api.anthropic.com/v1/messages|
#if you're using a ComfyUI workflow that creates audio, and you don't have AITOOLS_AUDIO_PROMPT or AITOOLS_AUDIO_NEGATIVE_PROMPT set in the ComfyUI workflow, these are used as defaults:
set_default_audio_prompt|audio that perfectly matches the onscreen action|
set_default_audio_negative_prompt|music|
First, install ComfyUI and get it rendering stuff in Flux and/or Hunyuan using tutorials out there.
Don't move on until it's working and you can generate images (Flux is good) and/or videos in ComfyUI directly!
Next, just for a test to make sure the workflows included with AITools are going to work, inside ComfyUI's web GUI, drag in aitools_client/ComfyUI/FullWorkflowVersions/text_to_img_flux.json or any others. The neat thing about ComfyUI is it will read this and convert it to its visual workflow format, ready to run. (you might want to change the prompt from <AITOOLS_PROMPT> to something else during testing here) - Click Queue. Does it work? Oh, if you see an Image Loader set to the file "<AITOOLS_INPUT_1>" you'll need to change that to a file on your ComfyUI server if you want to test.
You'll probably see a bunch of red nodes and errors - no problem! Make sure you have ComfyUI-Manager installed, you can use it to install any missing nodes. You'll probably have to track down various model files though, but at least when you try to render it will shows exactly the filenames that are missing. (look for red boxes around certain nodes)
Adjust it until it works (change paths or models or whatever you need, you could even start with a totally different workflow you found somewhere else), and make sure the prompt is set to <AITOOLS_PROMPT>. (<AITOOLS_NEGATIVE_PROMPT> can be used if your workflow has a place for that too) Then do Workflow->Export (API) if you wanted to save your own. Note: You need to have enabled "Dev mode" in the ComfyUI settings to see the "Export (API)" option.
So you don't have to create custom workflows for every checkpoint/filesize etc, you can use AITools' "@replace" to change any part of a workflow before it's sent to ComfyUI's API. You'll see it used in various presets.
Check discussions for some more info here
- Requires Unity 6+
- Open the scene "Main" and click play to run
- Assets/GUI/GOTHIC.TFF and Assets/GUI/times.ttf are not included and might break the build because I was having trouble and switched some settings around that might require them now (dynamic vs static TMPro font settings...)
Credits and links
- Audio: "Chee Zee Jungle"
Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0
http://creativecommons.org/licenses/by/3.0/
- NotoSansCJKjp-VF font licensed under the Open Font License (OFL)
- Audio: JOHN_MICHEL_CELLO-BACH_AVE_MARIA.mp3 performed by John Michel. Licensed under Creative Commons: By Attribution 3.0
http://creativecommons.org/licenses/by/3.0/
- Written by Seth A. Robinson ([email protected]) twitter: @rtsoft - Codedojo, Seth's blog
- Special thanks to the awesome people working on AUTOMATIC1111's stable-diffusion-webui project
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aitools_client
Similar Open Source Tools
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.

chaiNNer
ChaiNNer is a node-based image processing GUI aimed at making chaining image processing tasks easy and customizable. It gives users a high level of control over their processing pipeline and allows them to perform complex tasks by connecting nodes together. ChaiNNer is cross-platform, supporting Windows, MacOS, and Linux. It features an intuitive drag-and-drop interface, making it easy to create and modify processing chains. Additionally, ChaiNNer offers a wide range of nodes for various image processing tasks, including upscaling, denoising, sharpening, and color correction. It also supports batch processing, allowing users to process multiple images or videos at once.
aicodeguide
AI Code Guide is a comprehensive guide that covers everything you need to know about using AI to help you code or even code for you. It provides insights into the changing landscape of coding with AI, new tools, editors, and practices. The guide aims to consolidate information on AI coding and AI-assisted code generation in one accessible place. It caters to both experienced coders looking to leverage AI tools and beginners interested in 'vibe coding' to build software products. The guide covers various topics such as AI coding practices, different ways to use AI in coding, recommended resources, tools for AI coding, best practices for structuring prompts, and tips for using specific tools like Claude Code.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
Aimmy
Aimmy is a universal AI-Based Aim Alignment Mechanism developed by BabyHamsta, MarsQQ & Taylor to make gaming more accessible for users who have difficulty aiming. It utilizes DirectML, ONNX, and YOLOV8 for player detection, offering high accuracy and fast performance. Aimmy features an easy-to-use UI, extensive customizability, and is free of ads and paywalls. It is designed for gamers facing challenges like physical or mental disabilities, poor hand-eye coordination, or aiming difficulties due to environmental factors. Aimmy provides various features like AI detection, customizability, anti-recoil system, mouse movement methods, hotswappability, and a model/configuration store with repository support.
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.

local-chat
LocalChat is a simple, easy-to-set-up, and open-source local AI chat tool that allows users to interact with generative language models on their own computers without transmitting data to a cloud server. It provides a chat-like interface for users to experience ChatGPT-like behavior locally, ensuring GDPR compliance and data privacy. Users can download LocalChat for macOS, Windows, or Linux to chat with open-weight generative language models.
iris-llm
iris-llm is a personal project aimed at creating an Intelligent Residential Integration System (IRIS) with a voice interface to local language models or GPT. It provides options for chat engines, text-to-speech engines, speech-to-text engines, feedback sounds, and push-to-talk or wake word features. The tool is still in early development and serves as a tutorial for Python coders interested in working with language models.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.
wingman-ai
Wingman AI allows you to use your voice to talk to various AI providers and LLMs, process your conversations, and ultimately trigger actions such as pressing buttons or reading answers. Our _Wingmen_ are like characters and your interface to this world, and you can easily control their behavior and characteristics, even if you're not a developer. AI is complex and it scares people. It's also **not just ChatGPT**. We want to make it as easy as possible for you to get started. That's what _Wingman AI_ is all about. It's a **framework** that allows you to build your own Wingmen and use them in your games and programs. The idea is simple, but the possibilities are endless. For example, you could: * **Role play** with an AI while playing for more immersion. Have air traffic control (ATC) in _Star Citizen_ or _Flight Simulator_. Talk to Shadowheart in Baldur's Gate 3 and have her respond in her own (cloned) voice. * Get live data such as trade information, build guides, or wiki content and have it read to you in-game by a _character_ and voice you control. * Execute keystrokes in games/applications and create complex macros. Trigger them in natural conversations with **no need for exact phrases.** The AI understands the context of your dialog and is quite _smart_ in recognizing your intent. Say _"It's raining! I can't see a thing!"_ and have it trigger a command you simply named _WipeVisors_. * Automate tasks on your computer * improve accessibility * ... and much more

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.
maxheadbox
Max Headbox is an open-source voice-activated LLM Agent designed to run on a Raspberry Pi. It can be configured to execute a variety of tools and perform actions. The project requires specific hardware and software setups, and provides detailed instructions for installation, configuration, and usage. Users can create custom tools by making JavaScript modules and backend API handlers. The project acknowledges the use of various open-source projects and resources in its development.
FreeChat
FreeChat is a native LLM appliance for macOS that runs completely locally. Download it and ask your LLM a question without doing any configuration. A local/llama version of OpenAI's chat without login or tracking. You should be able to install from the Mac App Store and use it immediately.
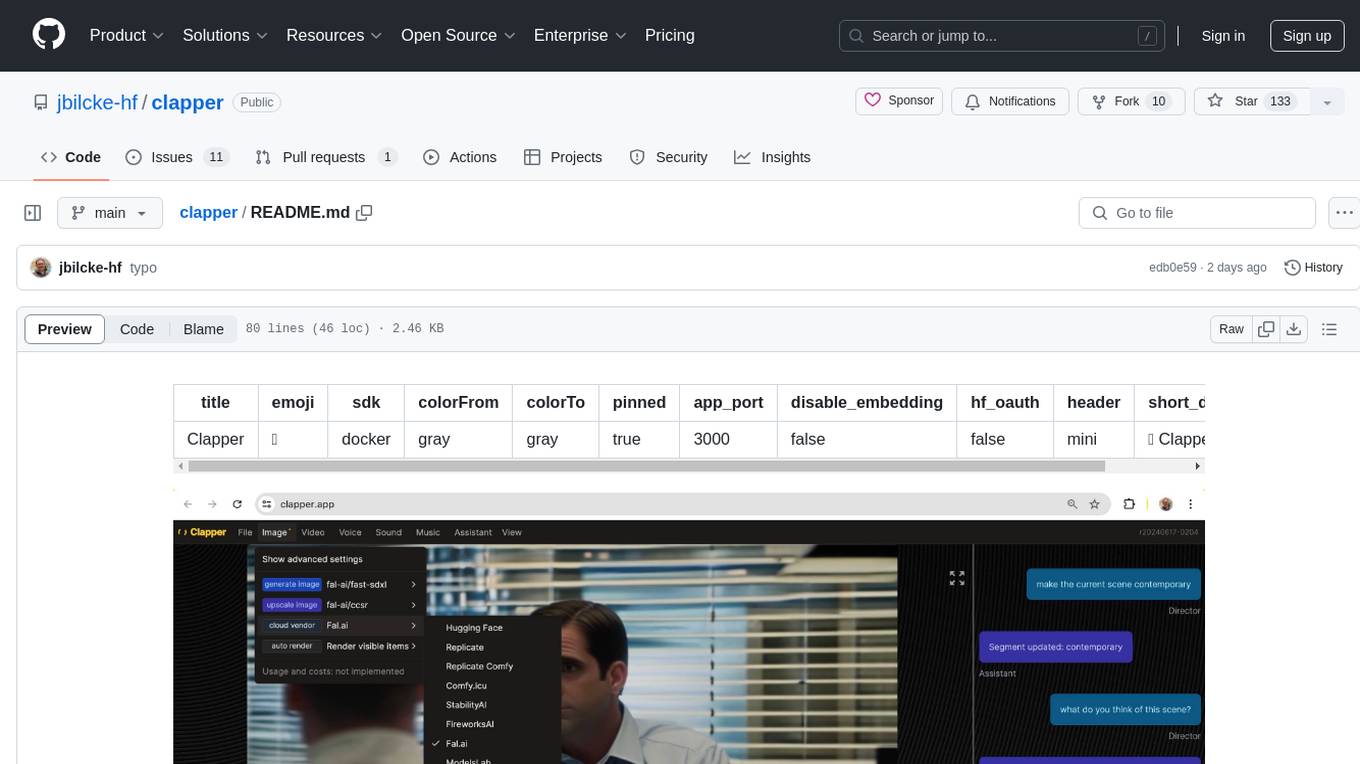
clapper
Clapper is an open-source AI story visualization tool that can interpret screenplays and render them into storyboards, videos, voice, sound, and music. It is currently in early development stages and not recommended for general use due to some non-functional features and lack of tutorials. A public alpha version is available on Hugging Face's platform. Users can sponsor specific features through bounties and developers can contribute to the project under the GPL v3 license. The tool lacks automated tests and code conventions like Prettier or a Linter.
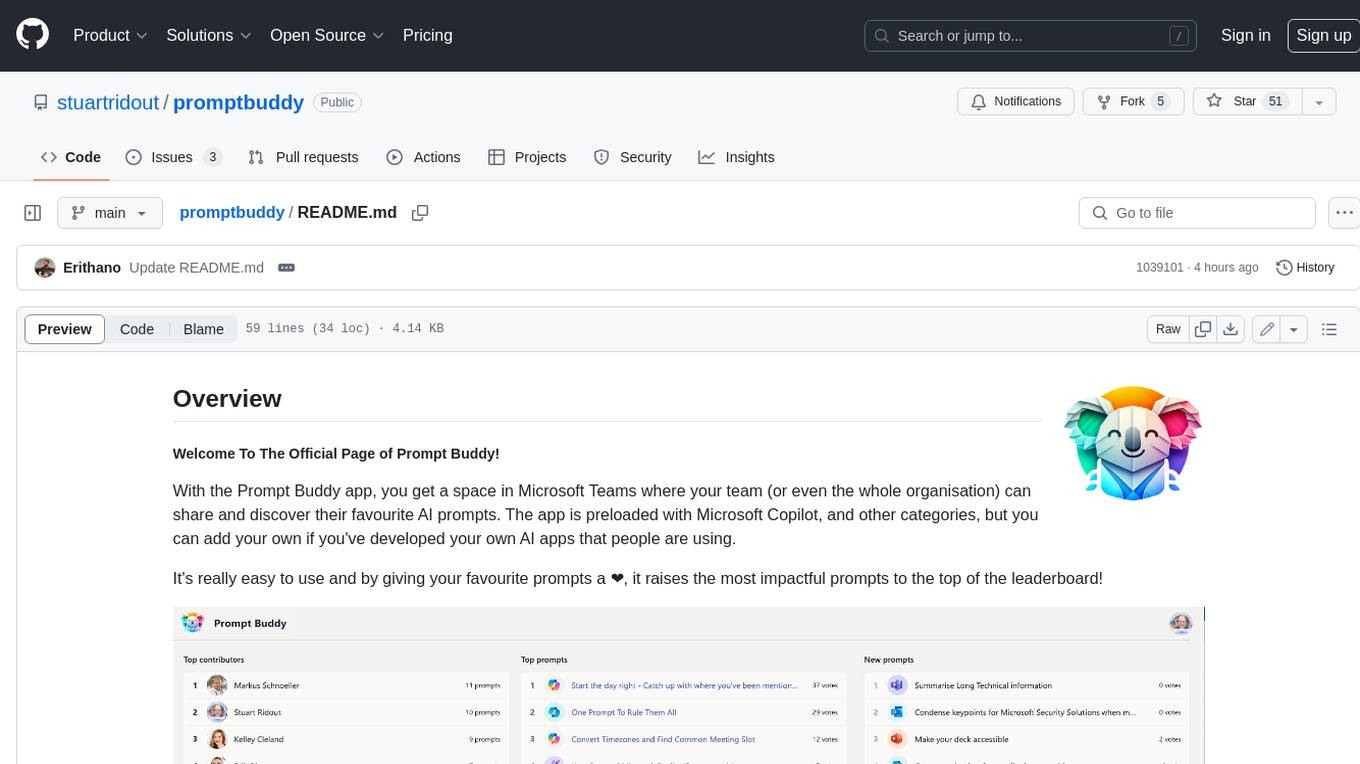
promptbuddy
Prompt Buddy is a Microsoft Teams app that provides a central location for teams to share and discover their favorite AI prompts. It comes preloaded with Microsoft Copilot and other categories, but users can also add their own custom prompts. The app is easy to use and allows users to upvote their favorite prompts, which raises them to the top of the leaderboard. Prompt Buddy also supports dark mode and offers a mobile layout for use on phones. It is built on the Power Platform and can be customized and extended by the installer.
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.
For similar tasks
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
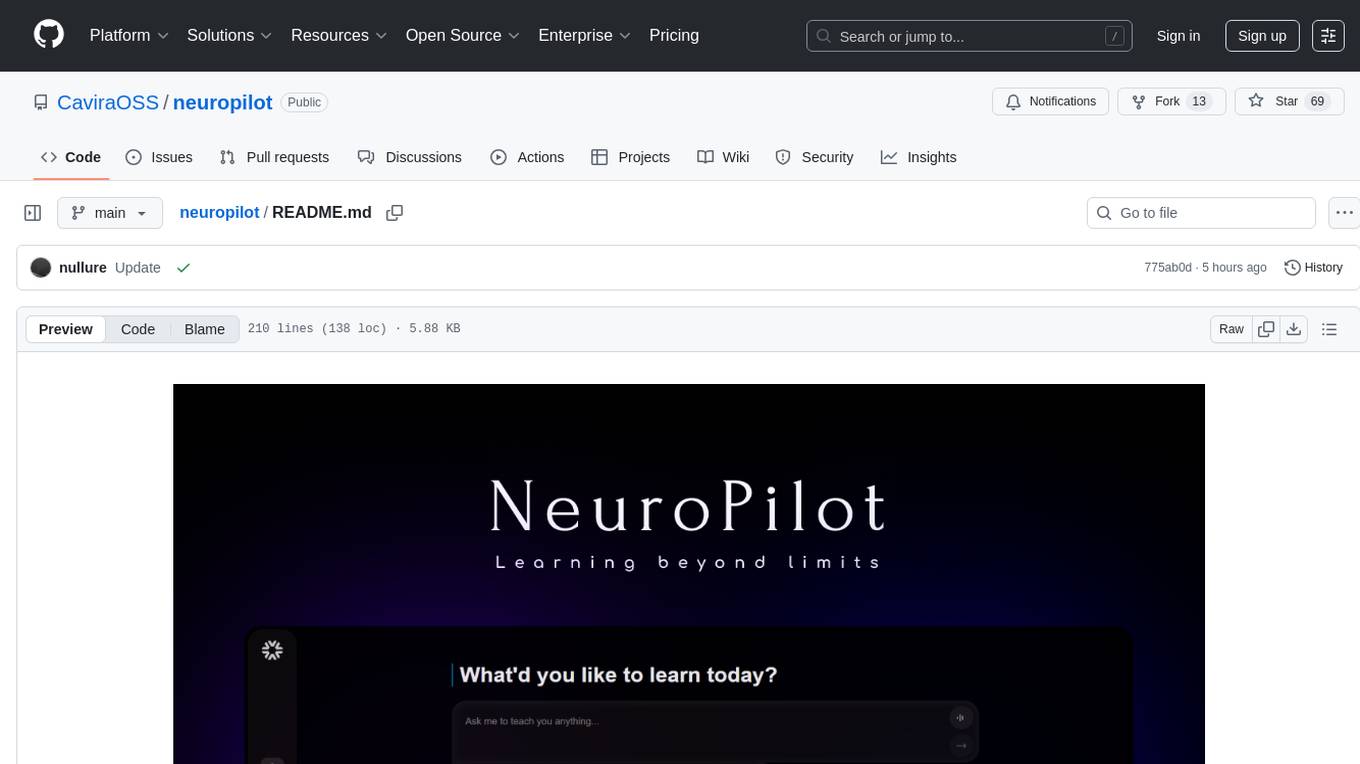
neuropilot
NeuroPilot is an open-source AI-powered education platform that transforms study materials into interactive learning resources. It provides tools like contextual chat, smart notes, flashcards, quizzes, and AI podcasts. Supported by various AI models and embedding providers, it offers features like WebSocket streaming, JSON or vector database support, file-based storage, and configurable multi-provider setup for LLMs and TTS engines. The technology stack includes Node.js, TypeScript, Vite, React, TailwindCSS, JSON database, multiple LLM providers, and Docker for deployment. Users can contribute to the project by integrating AI models, adding mobile app support, improving performance, enhancing accessibility features, and creating documentation and tutorials.

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.

ap-plugin
AP-PLUGIN is an AI drawing plugin for the Yunzai series robot framework, allowing you to have a convenient AI drawing experience in the input box. It uses the open source Stable Diffusion web UI as the backend, deploys it for free, and generates a variety of images with richer functions.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
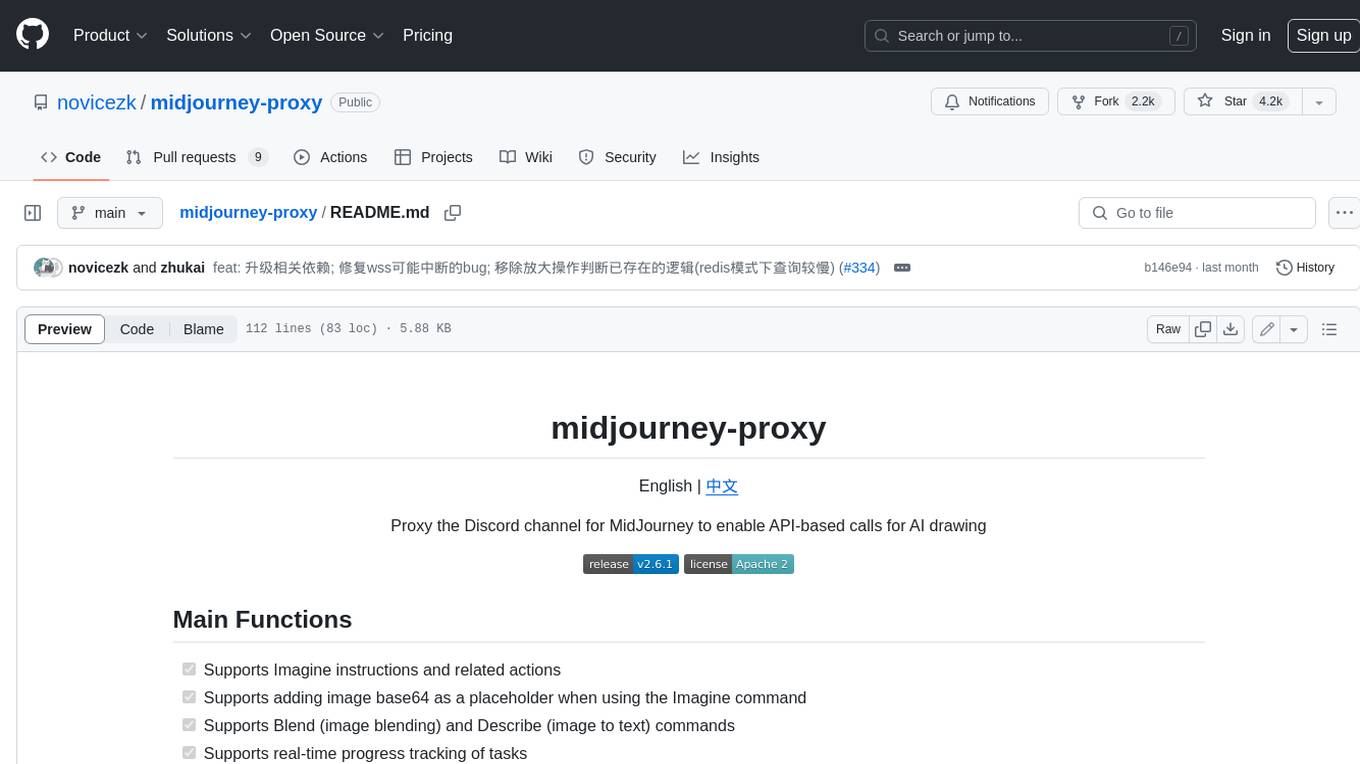
midjourney-proxy
Midjourney-proxy is a proxy for the Discord channel of MidJourney, enabling API-based calls for AI drawing. It supports Imagine instructions, adding image base64 as a placeholder, Blend and Describe commands, real-time progress tracking, Chinese prompt translation, prompt sensitive word pre-detection, user-token connection to WSS, multi-account configuration, and more. For more advanced features, consider using midjourney-proxy-plus, which includes Shorten, focus shifting, image zooming, local redrawing, nearly all associated button actions, Remix mode, seed value retrieval, account pool persistence, dynamic maintenance, /info and /settings retrieval, account settings configuration, Niji bot robot, InsightFace face replacement robot, and an embedded management dashboard.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.