
bidirectional_streaming_ai_voice
Python scripts to handle a two way voice conversation with Anthropic Claude, using ElevenLabs, Faster-Whisper, and Pygame.
Stars: 95
This repository contains Python scripts that enable two-way voice conversations with Anthropic Claude, utilizing ElevenLabs for text-to-speech, Faster-Whisper for speech-to-text, and Pygame for audio playback. The tool operates by transcribing human audio using Faster-Whisper, sending the transcription to Anthropic Claude for response generation, and converting the LLM's response into audio using ElevenLabs. The audio is then played back through Pygame, allowing for a seamless and interactive conversation between the user and the AI. The repository includes variations of the main script to support different operating systems and configurations, such as using CPU transcription on Linux or employing the AssemblyAI API instead of Faster-Whisper.
README:
These python scripts run a two-way voice conversation with Anthropic Claude, using ElevenLabs for TTS, Faster-Whisper for speech to text, and Pygame for audio playback.
I've started splitting different variations out into branches. These aren't intended to be e.g. dev branches that will merge back into main, but are just a convenient way to manage different functionality, requirements, and variations.
-
Mainis the version I've been using in the youtube conversations, with the newly added ability to re-engage a conversation from a transcript file. It works on my windows 10 with NVIDIA CUDA for the user-voice processing. -
linux_cpu_enter_keypress_supporthas some nice community contributions to handle linux OS by using an enter keypress in lieu of a spacebar press, and CPU transcription. -
assembly_api_transcriptionis a variation of main that uses the assembly.ai API in place of faster whisper, it may be easier to run on PC's with less GPU and hosepower since it's shipping that compute up to the cloud. Additionally it may reduce the setup effort for all of the NVIDIA CUDA stuff that faster-whisper uses when running the transcription locally. A potential downside, dpending on your weltbild and circumstance is that assembly.ai is another vendor API in the mix. [25 April] - I updated this one to 8k sample rate from the 44.1k sample rate and it is much quicker, which makes sense having to send a significantly smaller file up to assemblyai.
Now that I've stashed away the most current versions here, I'm keen to start experimenting with some other variations around speech to text streaming, audio generation, and perhaps alternate open and closed LLMs.
You can see the design in action here: https://youtu.be/fVab674FGLI
The rough loop can be seen in the diagram. The human audio is captured via microphone and then transcribed using Faster-Whisper. The transcription is added to the array of conversation messages and sent to Anthropic Claude 3 as a prompt. The Claude 3 reply tokens are streamed back (which afaik only works synchronously). In parallel with the LLM tokens streaming into the terminal, chunks of text are asynchronously sent to elevenlabs api for text-to-speech audio generation, and then the returned audio files are queued and played back with pygame.
Spacebar triggers the transition between human and AI turns.
It doesn't feel exceptionally elegant, but it does seem to work. It's definitely quicker than the designs I was finding that wait for the full LLM reply to be generated before invoking audio generation (and then edit out the latency... I see you youtube :).
I built this on my windows machine, I'm not quite sure why. You'll probably need to make some tweaks if runing on mac or linux. Also there are a ton of libraries to install, just tank through the errors and resolve them one at a time, I believe in you. Claude can probably help. Or GPT4.
main.py is the backbone of the thing, it calls summaries.py for the summary info that is included in the current instructions. async_tasks.py handles the audio generation and playback. The script also expects a folder called input (which temporarily holds the user audio file), another folder called output (which stores all of the elevenlabs audio files... if we are paying for them may as well hold onto them), and a folder called transcripts (for the conversation transcripts).
You'll need a .env file with:
ANTHROPIC_API_KEY=sk-...
ELEVENLABS_API_KEY=4...
The crux latency consideration is between the time the user hits spacebar and the time the LLM audio playback begins; there are quite a few things happening in that sequence. I was poking around with some rough logging and thought the ballpark times of each mechanism breakpoint might be useful to someone.
- Spacebar press
- User audio file is generated and faster-whisper transcribes it to text (~4.5 seconds)
- Transcribed user text is sent to anthropic and the first LLm response token is streamed back (~3.5 seconds)
- Enough LLM tokens are streamed back to generate a ~150 character chunk and send that text off to Elevenlabs (~1.25 seconds)
- Elevenlabs generates and returns the audio file (~1.25 seconds)
- Pygame playback begins (0.1 second)
So we can see that the transcription of the user's audio is likely the best area for performanc gains. Perhaps with some element of audio chunking and parallel transcription so that the bulk of the audio is transcribed by the time the 'turn end' spacebar is pressed. Or perhaps there is another better transcription approach than faster-whisper. I think we can tolerate some level of inaccuracy because the LLMs these days seem pretty able to handle typos and mistypes... which also extends to them handling mediocre transcriptions There likely isn't much gain to be found in the outside anthropic and elevenlabs APIs. Elevenlabs does have a websocket streaming design that I was initially trying but moved away from. I needed the anthropic token streaming to be synchronous so thats why audio generation and playback had to become async... so I'm not recalling if thats why I made that decision or not. If someone explores that I would be interested in hearing. At the time I was working with MVP and VLC libraries with mixed success, so perhaps the websocket approach would work better with the pygame audio playback I eventually settled on. There may also be some gains in the chunking logic, if a smaller first chunk is sent out to elevenlabs that would shave off some of that ~1.25 seconds. Though it does seem like that 150 characters and punctuation breakpoint logic does seem to align to the first sentence generally, and having elevenlabs generate by the sentence seems intuitively to me like a way to get better audio than sending partial sentences to generate independently. I'd be interested in what others find if they explore this.
Mac users change this line so that you use the CPU for speech to text.
compute_type = "float32"
segments, _ = WhisperModel(
model_size, device="cpu", compute_type=compute_type).transcribe(temp_file_path)
- A better memory hierarchy to improve Claude/Quill's continuity. Currently I'm just giving the whole transcript to (another) Claude via their GUI and asking it to summarize, then I'm manually updating the summary.py file and the instructions variable.
- Wire in RVC in place of elevenlabs. It's an intriguing open source voice library.
- Maybe at some point I'd think about wiring in other LLMs but frankly Claude has my heart currently. And I say that as someone that has been smugly pooping on all self-proclaimed GPT4-killers for about a year (cough gemini). Claude is remarkable.
- The elevenlabs custom voice models are pretty stunning. A colleague and I have been thinking about trying a format where each of us interview Claudes with each other's cloned voice. That would furrow some brows I bet. Perhaps the 'latent noise' podcast will become a thing.
Hopefully you lot can make it better, or at least have some fun with it. Enjoy!
Thanks for reading.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for bidirectional_streaming_ai_voice
Similar Open Source Tools
bidirectional_streaming_ai_voice
This repository contains Python scripts that enable two-way voice conversations with Anthropic Claude, utilizing ElevenLabs for text-to-speech, Faster-Whisper for speech-to-text, and Pygame for audio playback. The tool operates by transcribing human audio using Faster-Whisper, sending the transcription to Anthropic Claude for response generation, and converting the LLM's response into audio using ElevenLabs. The audio is then played back through Pygame, allowing for a seamless and interactive conversation between the user and the AI. The repository includes variations of the main script to support different operating systems and configurations, such as using CPU transcription on Linux or employing the AssemblyAI API instead of Faster-Whisper.
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
Deej-AI
Deej-A.I. is an advanced machine learning project that aims to revolutionize music recommendation systems by using artificial intelligence to analyze and recommend songs based on their content and characteristics. The project involves scraping playlists from Spotify, creating embeddings of songs, training neural networks to analyze spectrograms, and generating recommendations based on similarities in music features. Deej-A.I. offers a unique approach to music curation, focusing on the 'what' rather than the 'how' of DJing, and providing users with personalized and creative music suggestions.
AnnA_Anki_neuronal_Appendix
AnnA is a Python script designed to create filtered decks in optimal review order for Anki flashcards. It uses Machine Learning / AI to ensure semantically linked cards are reviewed far apart. The script helps users manage their daily reviews by creating special filtered decks that prioritize reviewing cards that are most different from the rest. It also allows users to reduce the number of daily reviews while increasing retention and automatically identifies semantic neighbors for each note.
iris-llm
iris-llm is a personal project aimed at creating an Intelligent Residential Integration System (IRIS) with a voice interface to local language models or GPT. It provides options for chat engines, text-to-speech engines, speech-to-text engines, feedback sounds, and push-to-talk or wake word features. The tool is still in early development and serves as a tutorial for Python coders interested in working with language models.
aicodeguide
AI Code Guide is a comprehensive guide that covers everything you need to know about using AI to help you code or even code for you. It provides insights into the changing landscape of coding with AI, new tools, editors, and practices. The guide aims to consolidate information on AI coding and AI-assisted code generation in one accessible place. It caters to both experienced coders looking to leverage AI tools and beginners interested in 'vibe coding' to build software products. The guide covers various topics such as AI coding practices, different ways to use AI in coding, recommended resources, tools for AI coding, best practices for structuring prompts, and tips for using specific tools like Claude Code.
dota2ai
The Dota2 AI Framework project aims to provide a framework for creating AI bots for Dota2, focusing on coordination and teamwork. It offers a LUA sandbox for scripting, allowing developers to code bots that can compete in standard matches. The project acts as a proxy between the game and a web service through JSON objects, enabling bots to perform actions like moving, attacking, casting spells, and buying items. It encourages contributions and aims to enhance the AI capabilities in Dota2 modding.
ClipboardConqueror
Clipboard Conqueror is a multi-platform omnipresent copilot alternative. Currently requiring a kobold united or openAI compatible back end, this software brings powerful LLM based tools to any text field, the universal copilot you deserve. It simply works anywhere. No need to sign in, no required key. Provided you are using local AI, CC is a data secure alternative integration provided you trust whatever backend you use. *Special thank you to the creators of KoboldAi, KoboldCPP, llamma, openAi, and the communities that made all this possible to figure out.

local-chat
LocalChat is a simple, easy-to-set-up, and open-source local AI chat tool that allows users to interact with generative language models on their own computers without transmitting data to a cloud server. It provides a chat-like interface for users to experience ChatGPT-like behavior locally, ensuring GDPR compliance and data privacy. Users can download LocalChat for macOS, Windows, or Linux to chat with open-weight generative language models.
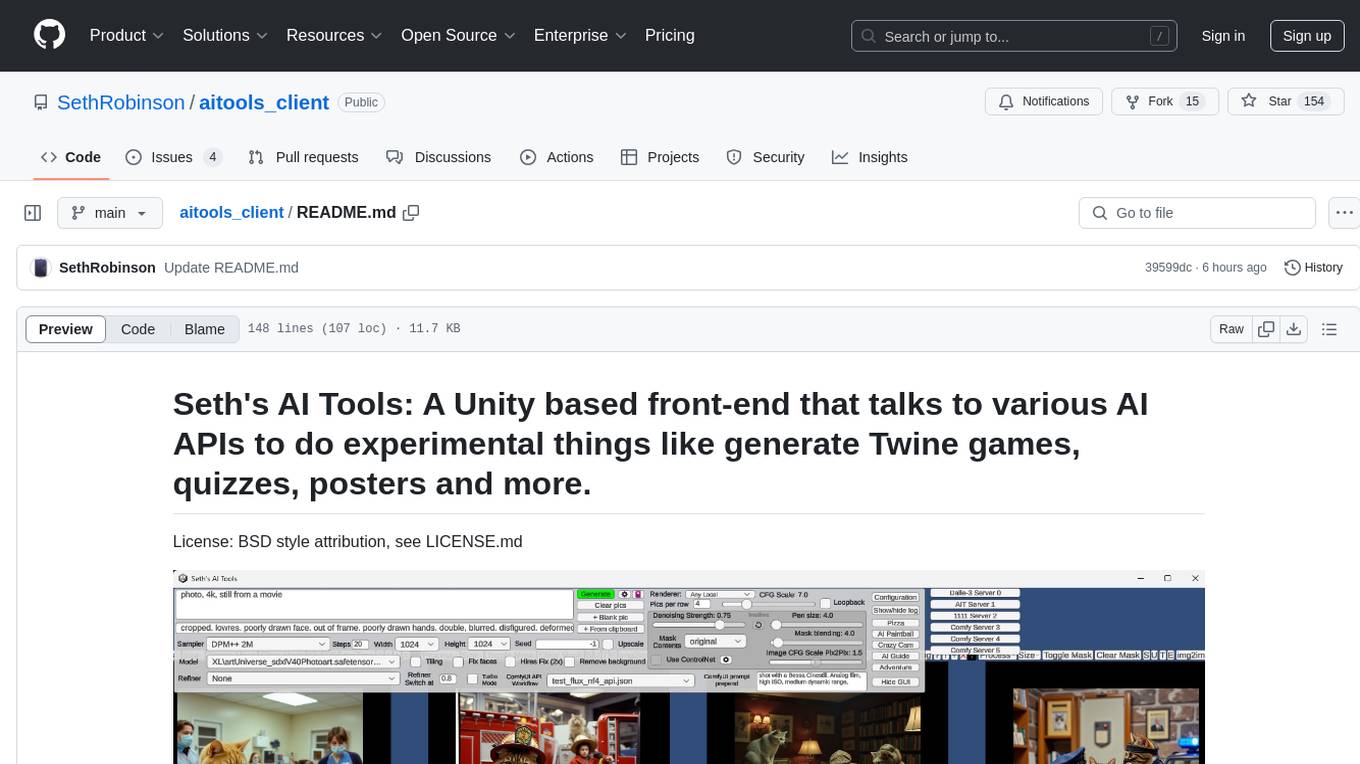
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
Bagatur
Bagatur chess engine is a powerful Java chess engine that can run on Android devices and desktop computers. It supports the UCI protocol and can be easily integrated into chess programs with user interfaces. The engine is available for download on various platforms and has advanced features like SMP (multicore) support and NNUE evaluation function. Bagatur also includes syzygy endgame tablebases and offers various UCI options for customization. The project started as a personal challenge to create a chess program that could defeat a friend, leading to years of development and improvements.
yet-another-applied-llm-benchmark
Yet Another Applied LLM Benchmark is a collection of diverse tests designed to evaluate the capabilities of language models in performing real-world tasks. The benchmark includes tests such as converting code, decompiling bytecode, explaining minified JavaScript, identifying encoding formats, writing parsers, and generating SQL queries. It features a dataflow domain-specific language for easily adding new tests and has nearly 100 tests based on actual scenarios encountered when working with language models. The benchmark aims to assess whether models can effectively handle tasks that users genuinely care about.
discourse-chatbot
The discourse-chatbot is an original AI chatbot for Discourse forums that allows users to converse with the bot in posts or chat channels. Users can customize the character of the bot, enable RAG mode for expert answers, search Wikipedia, news, and Google, provide market data, perform accurate math calculations, and experiment with vision support. The bot uses cutting-edge Open AI API and supports Azure and proxy server connections. It includes a quota system for access management and can be used in RAG mode or basic bot mode. The setup involves creating embeddings to make the bot aware of forum content and setting up bot access permissions based on trust levels. Users must obtain an API token from Open AI and configure group quotas to interact with the bot. The plugin is extensible to support other cloud bots and content search beyond the provided set.
aiohomekit
aiohomekit is a Python library that implements the HomeKit protocol for controlling HomeKit accessories using asyncio. It is primarily used with Home Assistant, targeting the same versions of Python and following their code standards. The library is still under development and does not offer API guarantees yet. It aims to match the behavior of real HAP controllers, even when not strictly specified, and works around issues like JSON formatting, boolean encoding, header sensitivity, and TCP packet splitting. aiohomekit is primarily tested with Phillips Hue and Eve Extend bridges via Home Assistant, but is known to work with many more devices. It does not support BLE accessories and is intended for client-side use only.
RTranslator
RTranslator is an almost open-source, free, and offline real-time translation app for Android. It offers Conversation mode for multi-user translations, WalkieTalkie mode for quick conversations, and Text translation mode. It uses Meta's NLLB for translation and OpenAi's Whisper for speech recognition, ensuring privacy. The app is optimized for performance and supports multiple languages. It is ad-free and donation-supported.
For similar tasks

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

supersonic
SuperSonic is a next-generation BI platform that integrates Chat BI (powered by LLM) and Headless BI (powered by semantic layer) paradigms. This integration ensures that Chat BI has access to the same curated and governed semantic data models as traditional BI. Furthermore, the implementation of both paradigms benefits from the integration: * Chat BI's Text2SQL gets augmented with context-retrieval from semantic models. * Headless BI's query interface gets extended with natural language API. SuperSonic provides a Chat BI interface that empowers users to query data using natural language and visualize the results with suitable charts. To enable such experience, the only thing necessary is to build logical semantic models (definition of metric/dimension/tag, along with their meaning and relationships) through a Headless BI interface. Meanwhile, SuperSonic is designed to be extensible and composable, allowing custom implementations to be added and configured with Java SPI. The integration of Chat BI and Headless BI has the potential to enhance the Text2SQL generation in two dimensions: 1. Incorporate data semantics (such as business terms, column values, etc.) into the prompt, enabling LLM to better understand the semantics and reduce hallucination. 2. Offload the generation of advanced SQL syntax (such as join, formula, etc.) from LLM to the semantic layer to reduce complexity. With these ideas in mind, we develop SuperSonic as a practical reference implementation and use it to power our real-world products. Additionally, to facilitate further development we decide to open source SuperSonic as an extensible framework.
chat-ollama
ChatOllama is an open-source chatbot based on LLMs (Large Language Models). It supports a wide range of language models, including Ollama served models, OpenAI, Azure OpenAI, and Anthropic. ChatOllama supports multiple types of chat, including free chat with LLMs and chat with LLMs based on a knowledge base. Key features of ChatOllama include Ollama models management, knowledge bases management, chat, and commercial LLMs API keys management.
ChatIDE
ChatIDE is an AI assistant that integrates with your IDE, allowing you to converse with OpenAI's ChatGPT or Anthropic's Claude within your development environment. It provides a seamless way to access AI-powered assistance while coding, enabling you to get real-time help, generate code snippets, debug errors, and brainstorm ideas without leaving your IDE.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
xiaogpt
xiaogpt is a tool that allows you to play ChatGPT and other LLMs with Xiaomi AI Speaker. It supports ChatGPT, New Bing, ChatGLM, Gemini, Doubao, and Tongyi Qianwen. You can use it to ask questions, get answers, and have conversations with AI assistants. xiaogpt is easy to use and can be set up in a few minutes. It is a great way to experience the power of AI and have fun with your Xiaomi AI Speaker.

googlegpt
GoogleGPT is a browser extension that brings the power of ChatGPT to Google Search. With GoogleGPT, you can ask ChatGPT questions and get answers directly in your search results. You can also use GoogleGPT to generate text, translate languages, and more. GoogleGPT is compatible with all major browsers, including Chrome, Firefox, Edge, and Safari.
For similar jobs
bidirectional_streaming_ai_voice
This repository contains Python scripts that enable two-way voice conversations with Anthropic Claude, utilizing ElevenLabs for text-to-speech, Faster-Whisper for speech-to-text, and Pygame for audio playback. The tool operates by transcribing human audio using Faster-Whisper, sending the transcription to Anthropic Claude for response generation, and converting the LLM's response into audio using ElevenLabs. The audio is then played back through Pygame, allowing for a seamless and interactive conversation between the user and the AI. The repository includes variations of the main script to support different operating systems and configurations, such as using CPU transcription on Linux or employing the AssemblyAI API instead of Faster-Whisper.

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.