
yet-another-applied-llm-benchmark
A benchmark to evaluate language models on questions I've previously asked them to solve.
Stars: 790
Yet Another Applied LLM Benchmark is a collection of diverse tests designed to evaluate the capabilities of language models in performing real-world tasks. The benchmark includes tests such as converting code, decompiling bytecode, explaining minified JavaScript, identifying encoding formats, writing parsers, and generating SQL queries. It features a dataflow domain-specific language for easily adding new tests and has nearly 100 tests based on actual scenarios encountered when working with language models. The benchmark aims to assess whether models can effectively handle tasks that users genuinely care about.
README:
This is a benchmark I made, for me, to test how well language models perform on tasks I care about. I know I care about them because each test is directly derived from something I've asked a LLM to perform for me in the last year.
For example, there are tests in this benchmark that evaluate the ability of a model to:
- convert a python function to an equivalent-but-faster c function;
- decompile python bytecode to functional source code;
- explain the functionality of minified javascript;
- identify the encoding format (in this case, uuencoded) of some data;
- write a parser from a BNF-like grammar;
- convert some english sentences to SQL queries; or,
- write some bash oneliners
There are two defining features of this benchmark that make it interesting:
-
I've implemented a simple dataflow domain specific language to make it easy for me (or anyone else!) to add new tests that realistically evaluate model capabilities.
-
Directly as a result of this, I've written nearly 100 tests for different situations I've actually encountered when working with LLMs as assistants.
For example, here's a complete test to evaluate if a model can write a "hello world" program.
'Write a "hello world" program in python' >> LLMRun() >> PythonRun() >> SubstringEvaluator("hello world")I first ask the model to write hello world, then run that program (in a docker
container, seamlessly behind the scenes), and then check if stdout contains "hello world".
(You should read the >> operator as "and then do". So "a >> b" means "do a, and then do b".)
More interestingly, here's a test case that first asks a model to produce code that draws a flag. To evaluate it, I run the code, partially judge it with another language model, and then fully evaluate the output by comparing to a reference solution.
"Write a C program that draws an american flag to stdout." >> LLMRun() >> CRun() >> \
LLMRun("What flag is shown in this image?") >> \
(SubstringEvaluator("United States") | SubstringEvaluator("USA") | SubstringEvaluator("America"))This DSL makes it easy for me to evaluate significantly more diverse and more sophisticated behavior than any other evaluation benchmark I'm aware of. This is helpful for determining whether or not models are capable of performing tasks I actually care about.
I've evaluated a few models on this benchmark. Here's how they perform:
- Claude 3.5 Sonnet: 48% passed
- GPT 4o: 47% passed
- Claude 3 Opus: 42% passed
- Claude 3 Sonnet: 32% passed
- Gemini 1.5 Pro: 32% passed
- Mistral Large: 28% passed
- GPT 3.5: 26% passed
- Mistral Medium: 23% passed
- Gemini 1.0 Pro: 17% passed
A complete evaluation grid is available here.
A serious academic benchmark.
In more words: this is not meant to try to rigorously evaluate the capabilities of models on any particular task. It's not meant to be something you can use to decide which model is more capable, more knowledgeable, more factual, less biased, less harmful, more aligned, more helpful, or anything else.
The questions are not optimally prompt-engineered. It is entirely possible---and indeed likely!---that a better phrasing of some of the questions would allow the model to give a better answer.
But I am lazy.
I do not want to remind the model it is AN EXPERT IN PYTHON and tell it that I'll give it a $100,000 tip for giving the right answer OR I WILL MURDER A KITTEN but please pause....take a deep breath....and think step by step by step before answering. (Or whatever the current incantation is people use to get models to work best.)
I just want to type my question and get the right answer. So this benchmark tests for that, on types of questions I've actually cared about having answered.
As a result of my (often intentional) lack of prompt engineering, when a model fails a question, you won't learn very much. Maybe my question was just poorly worded. Maybe it was ambiguous in some way.
Instead, these tests are designed so that I learn something when the model passes. You don't luck your way into correctly compiling Rust programs without having some skill at the language. But you might luck your way into failing by naming the function something I didn't expect and so your correct code just is never invoked.
Again, it's just a collection of questions I've actually asked language models to solve for me
to help with various programming tasks,
interspursed with a few questions I've asked language models just for fun.
The questions are, for the most part, unmodified questions as I typed them.
This means they may not be the most clearly worded
(e.g., In python what __thing__ do I use for ~, kind of like how __add__ is for +,
with the answser I'm expecting is __inv__).
Other questions are "unfair" because they require recent knowledge
(e.g., "what is the hidden dimension of llama-2 70b?").
But I care if a model can answer these correctly for me.
Getting this benchmark up and running is fairly straightforward.
On the python side you'll just need to run
pip install -r requirements.txt to install the python dependencies.
If you want to run it and evaluate a wide range of models you'll also need
pip install -r requirements-extra.txt to install the other models.
I want to run things in a container to keep them basically safe. Docker is nicer and has slightly better security controls (and so you can use that if you want below) but on linux you need to be root or give your user almost-root permissions to start new docker jobs. This scares me a bit.
So I prefer to use podman. Install it however you're supposed to for your system.
Again this is fairly system dependent so you'll have to go somewhere else to find out how to install it for your system.
The test cases in this benchmark are evaluated by directly executing code that comes out of a language model. Some tests ask the model to rename files, move files around, or make other state-changing operations to your machine.
While I don't think these models have it out for us and will emit rm -rf / out of
malice or spite, it's entirely possible (and even likely!) that they'll produce buggy
code that will just accidentally trash your computer.
So, to safeguard against this, all LLM output is evaluated from within a
temporary docker container that gets deleted immediately after the test is complete.
(There's also another reason, though: some of the tests assume a fresh install of Ubuntu with particular dependencies in various places. These tests might behave differently on your local machine than they do from within the docker VM.)
If you like to live dangerously (VERY MUCH NOT RECOMENDED) then there is
a flag in the code
I_HAVE_BLIND_FAITH_IN_LLMS_AND_AM_OKAY_WITH_THEM_BRICKING_MY_MACHINE_OR_MAKING_THEM_HALT_AND_CATCH_FIRE
that you can set to True and then this will just eval() everything that comes
out of the LLMs on your machine directly.
Once you've installed everything, there are a few setup steps before you can run the benchmark.
You should add API keys for any model you want to evaluate. The keys are stored in the config.json file. You can find a template at config.json.example
Whatever model you are testing, you will also need to load API keys for OpenAI as the default evaluation model. This is because a few of the questions require evaluation by a second language model to judge correctness. These secondary evaluations are as simple as possible, but using a high-quality model here is helpful to ensure consistency in the results.
I have had good success using gpt-4-turbo as the evaluation model, but you can configure any model that you want as the evaluator. In my experiments, I had almost identical results with the (cheaper) gpt-3.5-turbo, but in a few cases having the more capable evaluation model gives more reliable results.
To start you'll need to create the docker container where the tests will run. This will first require that you install docker on your machine. Once you've done that, you can then build the image:
docker build -t llm-benchmark-image . # if you're using docker
podman build -t llm-benchmark-image . # if you're using podmanA few test cases require Selenium and Chrome to test if models can generate valid html/javascript programs. Installing the requirements file should install selenium for you, but you'll also need to make sure you install chrome. If you're on ubuntu then you can just run
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome-stable_current_amd64.debOnce you've set up your environment, you can run the entire benchmark in just one line:
python main.py --model gpt-3.5-turbo --run-tests --generate-reportThis command will run every single test that's configured on one model.
It will therefore take some time, and also will cost you a few dollars in
language model queries. After you can view the full reslt html file in the
directory evaluation_examples.
It will also save a cache of this run, so that the next time you can run a new model and view the two results side-by-side. These are saved by default in the directory results/[current git commit hash]/[model name].
If you want to run individual test cases, you can do that too in two ways. One is to just directly run test
PYTHONPATH='.' python tests/print_hello.py- Explore the
run_a_simple_testcase.ipynbnotebook to quickly run a sample test case on Colab.
The other, if you want to save the result of this run so you can load it later, is to run the main script and specify which test(s) you want to run. (Be careful if you do this, though, beacuse it will overwrite any prior run.)
python main.py --run-tests --test print_hello --model gpt-3.5-turbo-0125If you've run generated many saved runs previously, you can load them into one grid with
python main.py --load-saved --generate-report --model [model1] --model [model2]And finally, if you've run the tests previously at one git commit, and want to just run any tests that have changed since then, you can run
python main.py --run-tests --only-changed [commit hash] --model gpt-3.5-turbo-0125This framework is fairly modular. If you'd like to test a new LLM, you'll just need to add a new file to llms/[model_name]_model.py which implements an inference function. From there, modify llm.py to include the appropriate model.
As discussed above, I've built a small dataflow DSL to implement test cases. This should let anyone add new test cases fairly easily. Let me repeat the initial test case examples in full:
TestHelloWorld = 'Print "hello world" in python' >> LLMRun() >> \
ExtractCode() >> PythonRun() >> SubstringEvaluator("hello world")Recall that you should read the >> operator as "and then do".
If you're a bash person, it's like a | pipe.
If you're a haskel person, it's like the $ operator.
- We start by running the LLM we want to test with the prompt: Print "hello world" in python.
- The model will probably give some code, but might also give an explanation or start by saying "Sure! I can answer your question." So we take whatever output came out of the model and pass it through a function to just extract the first code block.
- We then actually go and run this python code, whatever it is. To be somewhat safe we do this by spawning a new docker env and run the code there.
- And finally, we verify that the code was correct, and the output of the python contains a substring of "hello world".
This dataflow pipeline also lets you do more complex verification. Below is the same example as from the top where I evaluate a model's ability to understand how to draw .bmp images.
TestFlagDraw = "Write a C program that draws an american flag to stdout as a bmp." >> \
ExtractCode() >> CRun() >> LLMVisionRun("What flag is shown in this image?") >> \
(SubstringEvaluator("United States") | \
SubstringEvaluator("USA") | \
SubstringEvaluator("America"))Here, after asking the model to draw the flag and running the resulting C code, I evaluate the model by asking another model what flag has been drawn, and checking if it says something like the US flag. Is this a perfect check? No. But verification is usually easier than generation, and so it's probably a good enough approximation of what I want.
If you'd like to add your own tests to this benchmark feel free to open a PR! I'd be happy to accept basically anything interesting.
There are only a few requirements for adding a test.
-
Test cases must be mechanistically verifiable. This is very limiting, I know. A whole lot of what I use LLMs for isn't verifiable in this way. Especially when I'm giving them large blocks of code and asking for specific changes that are hard to unit test. But in order for these to be useful your test must be easy to verify.
-
Test cases should complete quickly. I don't want to wait several minutes just for one test to run.
-
Tests should not be evaluated against LLMs during construction. Don't modify the test because the model gave an answer you didn't like. Most LLMs are stochastic enough that there is some way to elicit most behavior with enough trial and error. I want to see how the model answers with a human-written test, as they are normally asked, before LM refinement.
-
Tests should be designed so that passing demonstrates some interesting model capability. Making "gotcha" tests that are designed to show models fail in some way are not useful in this setup.
-
Test cases must not download large amounts of data from the internet. Someone else shouldn't have to pay for each run of this benchmark. If you need to test a library add it to the Dockerfile.
Are there any tests here that are broken? I tried my best to make them all correct but can't guarantee correctness for sure. If so I'd be happy to accept fixes.
But please note: a broken test means one where the answer is objectively wrong. Like a test that says 6 is prime. A test that just expects a specific answer to an ambiguous question is not wrong. For example, one test asks "What do I do to fix AutoModel.from_pretrained to make it auto model with lm head" and expects the model to tell me that I should be using the class "AutoModelForCausalLM"; even though the class "AutoModelWithLMHead" exists, that's not what I was looking for.
No you probably don't. At least, you probably don't if you're trying to compare why your new model is better or something. This is not meant to be something for academic papers and only evaluates a very specific set of capabilities. For all the reasons mentioned earlier I don't think this benchmark will accurately capture what academic people should care about for their models. Good for "useful for me?": yes. Good for "is my model better?": I don't think so. But I've now had at least a few people ask me about this who appear unswayed by the above argument.
So here's my answer: if you want to user this in a paper, then link to this github project AND INCLUDE THE GIT COMMIT HASH YOU USED. I make NO GUARANTEES that I won't just arbitrarily edit test cases without warning. In fact, it's already happened in #1! And #3! And #6. So if you want your paper to be at all scientific make sure to include the git commit hash.
Copyright (C) 2024, Nicholas Carlini [email protected].
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program. If not, see http://www.gnu.org/licenses/.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for yet-another-applied-llm-benchmark
Similar Open Source Tools
yet-another-applied-llm-benchmark
Yet Another Applied LLM Benchmark is a collection of diverse tests designed to evaluate the capabilities of language models in performing real-world tasks. The benchmark includes tests such as converting code, decompiling bytecode, explaining minified JavaScript, identifying encoding formats, writing parsers, and generating SQL queries. It features a dataflow domain-specific language for easily adding new tests and has nearly 100 tests based on actual scenarios encountered when working with language models. The benchmark aims to assess whether models can effectively handle tasks that users genuinely care about.
aicodeguide
AI Code Guide is a comprehensive guide that covers everything you need to know about using AI to help you code or even code for you. It provides insights into the changing landscape of coding with AI, new tools, editors, and practices. The guide aims to consolidate information on AI coding and AI-assisted code generation in one accessible place. It caters to both experienced coders looking to leverage AI tools and beginners interested in 'vibe coding' to build software products. The guide covers various topics such as AI coding practices, different ways to use AI in coding, recommended resources, tools for AI coding, best practices for structuring prompts, and tips for using specific tools like Claude Code.
wtffmpeg
wtffmpeg is a command-line tool that uses a Large Language Model (LLM) to translate plain-English descriptions of video or audio tasks into actual, executable ffmpeg commands. It aims to streamline the process of generating ffmpeg commands by allowing users to describe what they want to do in natural language, review the generated command, optionally edit it, and then decide whether to run it. The tool provides an interactive REPL interface where users can input their commands, retain conversational context, and history, and control the level of interactivity. wtffmpeg is designed to assist users in efficiently working with ffmpeg commands, reducing the need to search for solutions, read lengthy explanations, and manually adjust commands.
AnnA_Anki_neuronal_Appendix
AnnA is a Python script designed to create filtered decks in optimal review order for Anki flashcards. It uses Machine Learning / AI to ensure semantically linked cards are reviewed far apart. The script helps users manage their daily reviews by creating special filtered decks that prioritize reviewing cards that are most different from the rest. It also allows users to reduce the number of daily reviews while increasing retention and automatically identifies semantic neighbors for each note.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
coding-with-ai
Coding-with-ai is a curated collection of techniques and best practices for utilizing AI coding tools to achieve transformative results in coding projects. It bridges the gap between AI coding demos and daily coding reality by providing insights into specific patterns like memory files, test-driven regeneration, and parallel AI sessions. The repository offers guidance on setting up memory files, writing detailed specs, drafting solutions before using assistants, getting multiple options, choosing stable libraries, and triggering careful planning. It also covers UI prototyping, coding practices, debugging strategies, testing methodologies, and cross-stage techniques for efficient coding with AI tools.
discourse-chatbot
The discourse-chatbot is an original AI chatbot for Discourse forums that allows users to converse with the bot in posts or chat channels. Users can customize the character of the bot, enable RAG mode for expert answers, search Wikipedia, news, and Google, provide market data, perform accurate math calculations, and experiment with vision support. The bot uses cutting-edge Open AI API and supports Azure and proxy server connections. It includes a quota system for access management and can be used in RAG mode or basic bot mode. The setup involves creating embeddings to make the bot aware of forum content and setting up bot access permissions based on trust levels. Users must obtain an API token from Open AI and configure group quotas to interact with the bot. The plugin is extensible to support other cloud bots and content search beyond the provided set.
aiohomekit
aiohomekit is a Python library that implements the HomeKit protocol for controlling HomeKit accessories using asyncio. It is primarily used with Home Assistant, targeting the same versions of Python and following their code standards. The library is still under development and does not offer API guarantees yet. It aims to match the behavior of real HAP controllers, even when not strictly specified, and works around issues like JSON formatting, boolean encoding, header sensitivity, and TCP packet splitting. aiohomekit is primarily tested with Phillips Hue and Eve Extend bridges via Home Assistant, but is known to work with many more devices. It does not support BLE accessories and is intended for client-side use only.
llm_engineering
LLM Engineering is an 8-week course designed to help learners master AI and LLMs through a series of projects that gradually increase in complexity. The course covers setting up the environment, working with APIs, using Google Colab for GPU processing, and building an autonomous Agentic AI solution. Learners are encouraged to actively participate, run code cells, tweak code, and share their progress with the community. The emphasis is on practical, educational projects that teach valuable business skills.
iris-llm
iris-llm is a personal project aimed at creating an Intelligent Residential Integration System (IRIS) with a voice interface to local language models or GPT. It provides options for chat engines, text-to-speech engines, speech-to-text engines, feedback sounds, and push-to-talk or wake word features. The tool is still in early development and serves as a tutorial for Python coders interested in working with language models.
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.
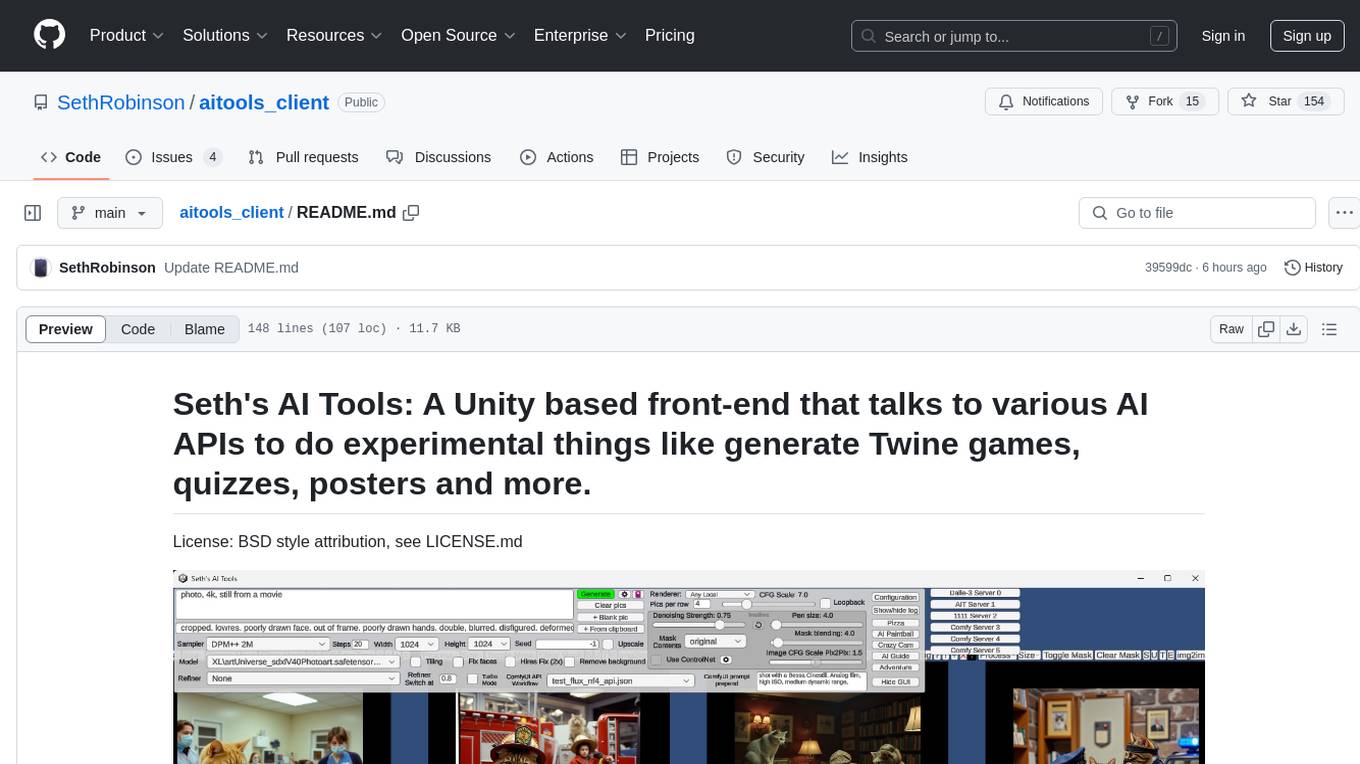
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
dota2ai
The Dota2 AI Framework project aims to provide a framework for creating AI bots for Dota2, focusing on coordination and teamwork. It offers a LUA sandbox for scripting, allowing developers to code bots that can compete in standard matches. The project acts as a proxy between the game and a web service through JSON objects, enabling bots to perform actions like moving, attacking, casting spells, and buying items. It encourages contributions and aims to enhance the AI capabilities in Dota2 modding.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.
pythagora
Pythagora is an automated testing tool designed to generate unit tests using GPT-4. By running a single command, users can create tests for specific functions in their codebase. The tool leverages AST parsing to identify related functions and sends them to the Pythagora server for test generation. Pythagora primarily focuses on JavaScript code and supports Jest testing framework. Users can expand existing tests, increase code coverage, and find bugs efficiently. It is recommended to review the generated tests before committing them to the repository. Pythagora does not store user code on its servers but sends it to GPT and OpenAI for test generation.
For similar tasks

ivy
Ivy is an open-source machine learning framework that enables you to: * 🔄 **Convert code into any framework** : Use and build on top of any model, library, or device by converting any code from one framework to another using `ivy.transpile`. * ⚒️ **Write framework-agnostic code** : Write your code once in `ivy` and then choose the most appropriate ML framework as the backend to leverage all the benefits and tools. Join our growing community 🌍 to connect with people using Ivy. **Let's** unify.ai **together 🦾**
yet-another-applied-llm-benchmark
Yet Another Applied LLM Benchmark is a collection of diverse tests designed to evaluate the capabilities of language models in performing real-world tasks. The benchmark includes tests such as converting code, decompiling bytecode, explaining minified JavaScript, identifying encoding formats, writing parsers, and generating SQL queries. It features a dataflow domain-specific language for easily adding new tests and has nearly 100 tests based on actual scenarios encountered when working with language models. The benchmark aims to assess whether models can effectively handle tasks that users genuinely care about.
aide
Aide is a Visual Studio Code extension that offers AI-powered features to help users master any code. It provides functionalities such as code conversion between languages, code annotation for readability, quick copying of files/folders as AI prompts, executing custom AI commands, defining prompt templates, multi-file support, setting keyboard shortcuts, and more. Users can enhance their productivity and coding experience by leveraging Aide's intelligent capabilities.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.