
oobabooga-macOS
Optimizing performance, building and installing packages required for oobabooga, AI and Data Science on Apple Silicon GPU. The goal is to optimize wherever possible, from the ground up.
Stars: 55
README:
This stared out as a guide to getting oobabooga working with Apple Silicon better, but has turned out to contain now useful information regarding how to get numerical analysis, data science, and AI core software running to take advantage of the Apple Silicon M1 and M2 processor technologies. There is information in the guides for installing OpenBLAS, LAPACK, Pandas, NumPy, PyTorch/Torch and llama-cpp-python. I will probably create a new repository for all things Apple Silicon in the interest of getting maximum performance out of the M1 and M2 architecture.
You probably want this: Building Apple Silicon Support for oobabooga text-generation-webui
If you hate standing in line at the bank: oobabooga macOS Apple Silicon Quick Start for the Impatient
In the test-scripts directory, there are some random Python scripts using tensors to test things like data types for MPS and other compute engines. Nothing special, just hacked together in a few minutes for checking GPU utilization and AutoCast Data Typing. BLAS and LAPACK are no longer required to be build.
The new VENV build process here is, venvutil. It's a set of shell functions and hopefully soon a way to get reproducible builds. Using Git, pip, conda and user definable functions. There's still a few issues I need to work out, but it will eventually track your installed python packages and even do diffs between different VENV's and points in time. Not quite there yet, but hoping for this to be a way to track and rebuild VENV's no matter if you use Conda, pip, and possibly a few others at some point.
There's also a lot of helpful shell functions in there, one in particular if a way to lookup and use POSIX return codes for return values and exit codes - errno and errfind. There's also errno_warn and errno_exit for scripts. If you have program which uses POSIX return codes, you would be able to do this:
someprogram
errno $?Let's say it returned 15 as an exit code, you would get this sent to STDERR:
errno 15
(ENOTBLK: 15): Block device required
errno_warn will return after sending the code and message to STDERR, and errno_exit will cause your script to exit after writing the error code and message to STDERR.
Anyone wishing to provide any additional information or assistance, pleas feel free. If you are interested in working on this with me, please let me know as well. It's still only myself and a few volunteers assisting me at the moment. Keeping up with call this does take a good bit of time to keep up with and organize in this rapidly changing world, so any help would be appreciated.
Rolled back to prior working version, should be fine now.
I have a problem between my user and the test user. Wait to download and install, unless you can debug the issue and you are welcome to do so.
I'm updating my instructions to use the main branch of the repository as I've done some housekeeping and all are in sync at this point.
Actually, not a whole lot has changed except for an updated to oobabooga being folded in. to the dev version of oobabooga dev from 20 May 2024. I will try to merge in other bits as soon as possible. But this is ready for anyone brave enough to test.
I have created a clone of the AllTalk TTS extension modified to use MPS instead of CUDA. It's not the speediest thing, but it works and has lots of features I haven't really had a chance to explore, like using your own clones/samples voices, and much more. This also depends on CoQui TTS, which I have also been able to get running using MPS as well and must be installed from a local clone. I will try to get that in a repository.
I am looking into possibly getting GPTQ, Transformers working, but I am thinking it might be nicer to build a native MLX module for macOS, so that is in the works a bit too. I think that might be a better pursuit instead of trying to worm all the CUDA code out of the other modules, though I was working on a package which could install and intercept PyTorch CUDA calls, provide a traceback indicating where the code was intercepted for future revision, and route them to MPS. If there is interest in any of these, let me know.
There are a number of things I'd like to do with this, so get in the GitHub Discussion for this project or open an "Issue' with an enhancement or fix request. As always contributions are welcome
See the updated instruction for install in the places at the top of this page. Please leave your comments, suggestions and issues which I will get back to as soon as I can.
I am also still looking for a paying gig, is if anyone knows someone who is hiring someone like me or you could use some assistance with a project, please get in touch. I have just set up a new LLC and am willing to work with anyone to help keep a roof over my head and the lights on.
I have set up a Discord which you are welcome to join and help build a community around oobabooga for macOS. I am on Discord a lot recently as I am testing the OpenAI app for macOS and providing feedback. The community link is here unixwzrd Discord Community
NOTE I have updated the install instructions with the latest build information.
NumPy on Apple Silicon GPUs (M1/M2/M3):
- NumPy has improved its compatibility with Apple Silicon GPUs.
- Installation still requires specific steps beyond a simple pip install.
- Key Points:
- NumPy now uses the Accelerate Framework.
- Special flags are needed for
llama.cppduring build. - PyTorch should be installed from daily builds.
- Numpy's build process has transitioned to Meson.
- Beware of library conflicts; NumPy might prioritize pre-existing libraries over the macOS Accelerate Framework.
- New switches have replaced environment variables for recompiling NumPy.
- A basic benchmarking tool,
numpybench, is available to test the GPU build. - Despite certain outputs suggesting otherwise, the recompiled NumPy does link to the Accelerate Framework.
- As of NumPy version 1.26.1, a straightforward compile might yield similar results to a custom compile, but using force flags is still recommended.
- Avoid simple Pip installs without specific flags as they may not optimize for the GPU and could over-utilize the CPU.
I've been doing a good bit of testing to see what configurations work using the GPU on Apple Silicon machines and while it's still not as straightforward as just doing a plain pip install, the changes to getting NumPy to run taking advantage of Apple Silicon GPU's has stabilized. I stated in another update that I'd been taking some time to allow things to settle, and it appears they have to some extent. Here's where things are now.
-
PyTorch still needs to be installed from the daily builds
Alright, let's take each of those things in order. Numpy changed their build process from what they had to using Meson to generate the build files and actually build. We used to use
NPY_BLAS_ORDERandNPY_LAPACK_ORDER, well as I mentioned before, the new build will try to determine if you have a libBLAS and libLAPACK dynamic library installed on your system. There is a set order of precedence it will use to search for these libraries and I discovered that it would use previously installed libraries in /usr/local/lib if it found them there before it would use the Accelerate Framework on macOS. I haven't tested the updated Meson install to see if it checks for the framework first or if it just grabs the first library it sees, in any event, I moved the OpenBLAS and BLIS libraries I'd build previously out of the way to be sure.Instead of environment variables there are now switches which need to be used when recompiling NumPy with Pip, and I would suggest doing a forced install if your NumPy is ever overlaid. I will show some rough numbers from my very basic benchmark, found in this repository in the test-scripts directory called
numpybenchwhich will give you the build configuration of your NumPy as well as do som every simple tests to exercise the GPU. At one point I needed the NPY environment variables to build, but now it's just like this:pip install numpy --force-reinstall --no-deps --no-cache --no-binary :all: --compile \ -Csetup-args=-Dblas=accelerate \ -Csetup-args=-Dlapack=accelerate \ -Csetup-args=-Duse-ilp64=trueThis will build and Accelerate Framework capable NumPy. When you do this install, depending on how you do it, like in verbose mode, you may notice and in the output of numpybench that it is not using accelerate for
lapack, but this very strange thing,dep4365539152which is some internal symbol which points toliblapack_litewhich is included in the NumPy package, but is not linked to the Accelerate Framework but an internallibblasorlibcblas, I forget which, but when you do the recompile as specified above, you do indeed get the Accelerate Framework linked in, even though it's just a wrapper. In macOS,otoolwill confirm this and on other systems, such as Linux or Unix you would likely useldd. The only thing this does not seem to respect is the ilp64, 64 bit integers, bit because the Accelerate Framework doesn't support it, it's becauselapack_litedoesn't for Accelerate.HOWEVER, I was just double checking all this and it seems NumPy has gone to 1.26.1 now and what I just wrote, which still works, it seems to get the same results as doing a straight compile when installing with Pip. It appears this will work just as well to install using Pip, feel free to use, but I'm going to stick with the forced flags. Either way 64 bit is not enabled in either one. I would not recommend installing with a simple Pip without the
--no-binaryand--compilealso set. Here is the install with and without the compiles.pip install numpy --force-reinstall --no-deps --no-cache --no-binary :all: --compile
and without, really not a good idea because this includes a copy of the
libopenblaslibrary precompiled, and it will run all over your CPU.pip install numpy --force-reinstall --no-deps --no-cache
Another interesting observation is it seems linking with the Accelerate Framework actually uses no GPU or CPU, I can only guess they are using the Neural Engine in the SOC. I would be curious to see the performance of llama-cpp-python if it was linked with the Accelerate Framework's
libBLAS, right nowligggmlis taking care of any linear algebra issues. Thelibllamacppuses a lot of GPU for processing, in fact it usually has the GPU pegged at 100%.llama-cpp-pythonwill insist on getting a new NumPy for you, but we can no longer compile NumPy during the rebuild ofllama-cpp-pythonor rather the sub-packagellama.cpp, and needs to be done the same as before, it's just we cannot specify the extra flags to Pip and using CFLAGS didn't work. I'm not a Meson expert or a Pip expert, but how enough to be dangerous. The procedure for rebuildingllama-cpp-pythonis like this still, but not installing its dependencies with--no-deps. Don't even bother trying the-Csetup-argswith this, it will fail.CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 \ pip install llama-cpp-python --force-reinstall --no-cache --no-binary :all: --compile --no-depsNot really anything new about this one, it's still taken from the daily build until they get the PyPi and Conda packages up to date with the next release.
pip install --pre torch torchvision torchaudio \ --index-url https://download.pytorch.org/whl/nightly/cpuA word about the GPU, and this first part applies to any GPU you might be using. The output of llama.cpp called from llama-cpp-python gives this message in verbose mode:
AVX = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 |
It is not the
BLAS = 1which indicates you are using the SIMD or ASIMD extensions in the M1/M2/M3 AARM processor, but theNEON = 1To quote Introducing NEON Development Article from the arm developer documentation,
What is NEON?
ARMv7 architecture introduced the Advanced SIMD extension as an optional extension to the ARMv7-A and ARMv7-R profiles. It extends the SIMD concept by defining groups of instructions operating on vectors stored in 64-bit D, doubleword, registers and 128-bit Q, quadword, vector registers.
The implementation of the Advanced SIMD extension used in ARM processors is called NEON, and this is the common terminology used outside architecture specifications. NEON technology is implemented on all current ARM Cortex-A series processors.
The BLAS simply indicates that it linked with a Basic Linear Algebra System, could be any of them
libblas, libBLAS, libcblas, libopenblas, libcublas, libblis... Could be any of them really, so you need to look further to determine whether you're using the GPU, on any machine really.numpybenchactually gives more information than that and it has a number of options. running it from the command line with the help option you get this:(numpy.07.oobacurrentnpy216llama211) [unixwzrd@xanax characters]$ numpybench --help usage: numpybench [-h] [-d [DATAFILE]] [-s] [-c COUNT] Run NumPy benchmarks and output results. options: -h, --help show this help message and exit -d [DATAFILE], --datafile [DATAFILE] Specify the datafile to write the output to. -s, --skip-tests Skip time-consuming tests. -c COUNT, --count COUNT Number of iterations. (numpy.07.oobacurrentnpy216llama211) [unixwzrd@xanax characters]$ numpybench -d /dev/null -c 20 2023-11-01 03:17:02 Producing information for VENV ----> numpy.07.oobacurrentnpy216llama211 2023-11-01 03:17:02 Build Dependencies: 2023-11-01 03:17:02 blas: 2023-11-01 03:17:02 detection method: system 2023-11-01 03:17:02 found: true 2023-11-01 03:17:02 include directory: unknown 2023-11-01 03:17:02 lib directory: unknown 2023-11-01 03:17:02 name: accelerate 2023-11-01 03:17:02 openblas configuration: unknown 2023-11-01 03:17:02 pc file directory: unknown 2023-11-01 03:17:02 version: unknown 2023-11-01 03:17:02 lapack: 2023-11-01 03:17:02 detection method: internal 2023-11-01 03:17:02 found: true 2023-11-01 03:17:02 include directory: unknown 2023-11-01 03:17:02 lib directory: unknown 2023-11-01 03:17:02 name: dep4364251104 2023-11-01 03:17:02 openblas configuration: unknown 2023-11-01 03:17:02 pc file directory: unknown 2023-11-01 03:17:02 version: 1.26.1 2023-11-01 03:17:02 Compilers: 2023-11-01 03:17:02 c: 2023-11-01 03:17:02 commands: cc 2023-11-01 03:17:02 linker: ld64 2023-11-01 03:17:02 name: clang 2023-11-01 03:17:02 version: 15.0.0 2023-11-01 03:17:02 c++: 2023-11-01 03:17:02 commands: c++ 2023-11-01 03:17:02 linker: ld64 2023-11-01 03:17:02 name: clang 2023-11-01 03:17:02 version: 15.0.0 2023-11-01 03:17:02 cython: 2023-11-01 03:17:02 commands: cython 2023-11-01 03:17:02 linker: cython 2023-11-01 03:17:02 name: cython 2023-11-01 03:17:02 version: 3.0.5 2023-11-01 03:17:02 Machine Information: 2023-11-01 03:17:02 build: 2023-11-01 03:17:02 cpu: aarch64 2023-11-01 03:17:02 endian: little 2023-11-01 03:17:02 family: aarch64 2023-11-01 03:17:02 system: darwin 2023-11-01 03:17:02 host: 2023-11-01 03:17:02 cpu: aarch64 2023-11-01 03:17:02 endian: little 2023-11-01 03:17:02 family: aarch64 2023-11-01 03:17:02 system: darwin 2023-11-01 03:17:02 Python Information: 2023-11-01 03:17:02 path: /Users/unixwzrd/miniconda3/envs/numpy.07.oobacurrentnpy216llama211/bin/python 2023-11-01 03:17:02 version: '3.10' 2023-11-01 03:17:02 SIMD Extensions: 2023-11-01 03:17:02 baseline: 2023-11-01 03:17:02 - NEON 2023-11-01 03:17:02 - NEON_FP16 2023-11-01 03:17:02 - NEON_VFPV4 2023-11-01 03:17:02 - ASIMD 2023-11-01 03:17:02 found: 2023-11-01 03:17:02 - ASIMDHP 2023-11-01 03:17:02 not found: 2023-11-01 03:17:02 - ASIMDFHM 2023-11-01 03:17:02 2023-11-01 03:17:02 2023-11-01 03:17:02 BEGIN TEST: Matrix multiplication 2023-11-01 03:17:03 Time for matrix multiplication: 1.0580 seconds 2023-11-01 03:17:03 END TEST / BEGIN NEXT TEST 2023-11-01 03:17:03 BEGIN TEST: Matrix transposition 2023-11-01 03:17:03 Time for matrix transposition: 0.0000 seconds 2023-11-01 03:17:03 END TEST / BEGIN NEXT TEST 2023-11-01 03:17:03 BEGIN TEST: Eigenvalue computation 2023-11-01 03:17:52 Time for eigenvalue computation: 49.0088 seconds 2023-11-01 03:17:52 END TEST / BEGIN NEXT TEST 2023-11-01 03:17:52 BEGIN TEST: Fourier transformation 2023-11-01 03:17:53 Time for fourier transformation: 0.7249 seconds 2023-11-01 03:17:53 END TEST / BEGIN NEXT TEST 2023-11-01 03:17:53 BEGIN TEST: Summation 2023-11-01 03:17:53 Time for summation: 0.0221 seconds 2023-11-01 03:17:53 END TEST / BEGIN NEXT TESTWhat you should really beconcerned about here is the
blasandlapackentries. You can see that it is using the Accelerate Framework by this line:2023-11-01 03:17:02 name: accelerateHowever, hereps what the output looks like from a NumPy whic hhas been installed from PyPi:
(dbug.01.torchtest) [unixwzrd@xanax include]$ numpybench -d /dev/null -c 20 2023-11-01 03:54:27 Producing information for VENV ----> dbug.01.torchtest 2023-11-01 03:54:27 Build Dependencies: 2023-11-01 03:54:27 blas: 2023-11-01 03:54:27 detection method: pkgconfig 2023-11-01 03:54:27 found: true 2023-11-01 03:54:27 include directory: /opt/arm64-builds/include 2023-11-01 03:54:27 lib directory: /opt/arm64-builds/lib 2023-11-01 03:54:27 name: openblas64 2023-11-01 03:54:27 openblas configuration: USE_64BITINT=1 DYNAMIC_ARCH=1 DYNAMIC_OLDER= NO_CBLAS= 2023-11-01 03:54:27 NO_LAPACK= NO_LAPACKE= NO_AFFINITY=1 USE_OPENMP= SANDYBRIDGE MAX_THREADS=3 2023-11-01 03:54:27 pc file directory: /usr/local/lib/pkgconfig 2023-11-01 03:54:27 version: 0.3.23.dev 2023-11-01 03:54:27 lapack: 2023-11-01 03:54:27 detection method: internal 2023-11-01 03:54:27 found: true 2023-11-01 03:54:27 include directory: unknown 2023-11-01 03:54:27 lib directory: unknown 2023-11-01 03:54:27 name: dep4364960240 2023-11-01 03:54:27 openblas configuration: unknown 2023-11-01 03:54:27 pc file directory: unknown 2023-11-01 03:54:27 version: 1.26.1 2023-11-01 03:54:27 Compilers: 2023-11-01 03:54:27 c: 2023-11-01 03:54:27 commands: cc 2023-11-01 03:54:27 linker: ld64 2023-11-01 03:54:27 name: clang 2023-11-01 03:54:27 version: 14.0.0 2023-11-01 03:54:27 c++: 2023-11-01 03:54:27 commands: c++ 2023-11-01 03:54:27 linker: ld64 2023-11-01 03:54:27 name: clang 2023-11-01 03:54:27 version: 14.0.0 2023-11-01 03:54:27 cython: 2023-11-01 03:54:27 commands: cython 2023-11-01 03:54:27 linker: cython 2023-11-01 03:54:27 name: cython 2023-11-01 03:54:27 version: 3.0.3 2023-11-01 03:54:27 Machine Information: 2023-11-01 03:54:27 build: 2023-11-01 03:54:27 cpu: aarch64 2023-11-01 03:54:27 endian: little 2023-11-01 03:54:27 family: aarch64 2023-11-01 03:54:27 system: darwin 2023-11-01 03:54:27 host: 2023-11-01 03:54:27 cpu: aarch64 2023-11-01 03:54:27 endian: little 2023-11-01 03:54:27 family: aarch64 2023-11-01 03:54:27 system: darwin 2023-11-01 03:54:27 Python Information: 2023-11-01 03:54:27 path: /private/var/folders/76/zy5ktkns50v6gt5g8r0sf6sc0000gn/T/cibw-run-27utctq_/cp310-macosx_arm64/build/venv/bin/python 2023-11-01 03:54:27 version: '3.10' 2023-11-01 03:54:27 SIMD Extensions: 2023-11-01 03:54:27 baseline: 2023-11-01 03:54:27 - NEON 2023-11-01 03:54:27 - NEON_FP16 2023-11-01 03:54:27 - NEON_VFPV4 2023-11-01 03:54:27 - ASIMD 2023-11-01 03:54:27 found: 2023-11-01 03:54:27 - ASIMDHP 2023-11-01 03:54:27 not found: 2023-11-01 03:54:27 - ASIMDFHM 2023-11-01 03:54:27 2023-11-01 03:54:27 2023-11-01 03:54:27 BEGIN TEST: Matrix multiplication 2023-11-01 03:54:30 Time for matrix multiplication: 2.8783 seconds 2023-11-01 03:54:30 END TEST / BEGIN NEXT TEST 2023-11-01 03:54:30 BEGIN TEST: Matrix transposition 2023-11-01 03:54:30 Time for matrix transposition: 0.0000 seconds 2023-11-01 03:54:30 END TEST / BEGIN NEXT TEST 2023-11-01 03:54:30 BEGIN TEST: Eigenvalue computation 2023-11-01 03:55:58 Time for eigenvalue computation: 87.9183 seconds 2023-11-01 03:55:58 END TEST / BEGIN NEXT TEST 2023-11-01 03:55:58 BEGIN TEST: Fourier transformation 2023-11-01 03:55:58 Time for fourier transformation: 0.7570 seconds 2023-11-01 03:55:58 END TEST / BEGIN NEXT TEST 2023-11-01 03:55:58 BEGIN TEST: Summation 2023-11-01 03:55:58 Time for summation: 0.0219 seconds 2023-11-01 03:55:58 END TEST / BEGIN NEXT TEST
The numbers here to really take note of is that for 20 iterations of the tests I have in my Python script, the NumPy install from PyPi precompiled, takes almost twice as long due to the pre-compiled OpenBLAS library which in brings with it. Here they are, and standing out specifically for the Eigenvalue computation:
Pip installed NumPy Binaries 2023-11-01 03:55:58 Time for eigenvalue computation: 87.9183 seconds Locally Compiled NumPy 2023-11-01 03:17:52 Time for eigenvalue computation: 49.0088 seconds
I have the discussions turned on for this repository and the subject was brought up regarding CoreML and I weighed with a rather lengthy response. Please feel free to add to the discussion if you like. it was regarding this paper about Swift and CoreML LLMs and rather use an Apple native solution rather than the patchwork of python and C libraries we have here. Well, it's complicated, you can read all about it here. GPT-4 was nice enough to give this...
- Apple's CoreML is powerful but remains largely within the Apple ecosystem, making it niche.
- llama.cpp aims for model portability and could become a standard for running models, especially with its GGUF file format.
- oobabooga is feature-rich but has performance and stability issues, and it's too PC-focused.
- Dependency hell and update cycles are significant challenges, especially with libraries like NumPy and PyTorch.
- ctransformers could be a game-changer, but you haven't had a chance to explore it yet.
- You're considering a new project that would be more modular and flexible than oobabooga, possibly using a message-passing architecture.
I haven't gone away, still around, but waiting on the dust to settle before updating. Lots of things have changed.
- PyTorch has had a few updates and is for-the-most-part, able to run using Apple Silicon M1/M2 GPU
- NumPy has had a major update, but last time I updated, the Python distributions did not have NumPy using Apple Silicon GPU by default.
- llama.cpp is using the Apple Silicon GPU and has reasonable performance. While for llama-cpp-python there is a dependency for NumPy, it doesn't require it for integrating it into oobabooga, though other things require NumPy.
- BLAS/LAPACK for NumPy, last I checked, point to the Accelerate Framework in macOS 13.5 (I have tested 13.5 thru 13.6.) and higher.
- macOS sent it an upgrade for their OS macOS 14.0. I have not tested this but I had numerous things change on my system and break with the 13.6 update. So, I decided to give things a rest until things settled down. Everything was running in my config below, and I didn't need the latest and greatest features of anything, so I decided to wait until things stabilized.
- iOS Updates. Yeah, that too. If it wasn't enough for everything else, Apple also put out iOS updates to iOS 17.
Basically, I was bouncing from one update to the next and hardly time to take a break. The repo I have for oobabooga-macos had a buglet or two patched, but it does llama2 support, though with configurations I have specified below and on my instructions, it is supported to version 1.6 as far as I can tell, and should run fine. If you have any problems with it, feel free to reach out and let me know.
I'm also staying away from macOS 14.0 until I am sure everything works. MAcGPG MAil is broken with the new release, Mail.app changed the way it handles plugins. I'm waiting until that works before I upgrade my OS. A lot of things have changed in macSO 14, but I'll wait a bit until everything works for me.
Ok, so lots of things broke over the weekend. llama-cpp-python went to 02.26, NumPy sometime this morning went to 1.26.0 and I need to gather the Metal/MPS build instructions and test. Guaranteed there will be something else this week that breaks things. People gotta figure out whether they want the latest and greatest or "stable and works." then pick the one that meets your needs. The latest and greatest may have cool new features, but at the cost of time. I will have updates later, probably tomorrow.
So many dependencies between packages each needing the other version of each other sometimes incompatible. Containers and VENV's offer a good way of handling all this, but here's the latest news in moving targets. It seems llama.cpp is moving very quickly, and the llama-cpp-python is behind, or there are bad links to vendor packages on GitHub, or really who knows. Bottom line is things don't work. After a bit of debugging and chasing package chasing here's what I have as the latest information on building a stack which will run oobabooga on macOS with Apple Silicon M1/M2 GPU Acceleration.
Basically, there's no change from my last update. The order is still the same, but the versions are moving targets right now. SO, real quickly, just a few paragraphs down, thee are the actual instruction in the proper order for stacking the libraries and packages.
- Build a clean VENV with Python 3.10
- pip install the daily PyTorch build. It will not have total Apple Silicon GPU support in it, and it adds some libraries for BLAS and LAPACK. These are opaque and might link with something else you use as they are kind of drop-in replacements for the NumPy libraries, in a sub-package called numpy-base which is installed with their flavor of NumPy. I have experienced problems removing PyTorch's NumPy completely due to this.
- pip install the oobabooga requirements.txt
- pip rebuild in one shot llama-cpp-python and NumPu together with Metal/Accelerate Framework. Using anything else will be considerably slower.
The only thing new to add is to specify which version of llama-cpp-python you need like this for version 0.2.5 which his the most current and works as far as my testing is concerned. The line for llama-cpp-python needs to have the version number put on the end like this (works for every other package this way for version numbers too):
llama-cpp-python==0.2.5That's it for llama.cpp and the Python API. Nothing else as it seems that some versions didn't. Be aware that the llama.cpp person/team, is not the same as the llama-cpp-python. llama.cpp is cranking out code with commits sometimes hourly throughout the day. With this quick a release cycle, you have to expect something may not go as planned, especially with all the moving ports. No package is necessarily better than another right now, things are changing that quickly. But this is one argument in favor of not always being on the latest and greatest version of software as it may not be fully integrated or tested yet.
I'm guilty of this to some extent, I have things I need to get released, but something else pops up. Right now, my oobabooga webui "main" branch is a bit stale, and probably best left alone. Right now the most stable version is in my "test" branch, dev is fairly stable, but might break as I am working on it. both dev and test branches need to be promoted. So, if you want it, grab the test branch until I announce a change, but I will likely promote dev all the way up to "main" since version 1.5 is no longer very relevant and I've squashed a few macOS issues with CUDA code.
For some reason the distribution of PyTorch, llama-cpp-python, and something in the oobabooga requirements.txt, all conflict with each other, including installing over an existing NumPy install or even downgrading it from 1.25.3 to 1.24.0. The PyTorch distribution at PyTorch also had some conflicting dependencies with other things as well, so you can't just do a --force-reinstall/install with things, and get the daily build of PyTorch because something has change in the distribution. I did manage to fins a combination which works solves the problems ad posted it in the #macOS-setup of the oobabooga Discord server. To save a bit, here's what I wrote:
RuntimeError: MPS does not support cumsum op with int64 input. This has something to do with PyTorch and their Metal support on macOS using the Accelerate Framework for the M1/M2 GPU acceleration, in particular the version of NumPy and associated "numpy-base" package which is distributed with PyTorch is also problematic. Some time ago, this problem was solved, but seems to have returned. There are several issues with the install process you followed and most of it is due to ever-changing libraries, modules and dependencies. Not only all that, but it does not seem to use the Apple Silicon M1/M2 GPU acceleration, so simply installing things in the proper order doesn't particularly help either.
You could probably repair the modules and libraries in your Python installation, but the quickest and probably the easiest way will be to create a new VENV and install things in this order:
- Create new VENV and make it active.
pip install --upgrade --no-deps --force-reinstall --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cpupip install -r requirements_nocuda.txt- (suggested)
NPY_BLAS_ORDER='accelerate' NPY_LAPACK_ORDER='accelerate' CMAKE_ARGS='-DLLAMA_METAL=on' FORCE_CMAKE=1 pip install --force-reinstall --no-cache --no-binary :all: --compile llama-cpp-python
All of these things may be done at the command line and in the directory you installed the webui. Hopefully I have them in the correct order and haven't forgotten anything, and I did check this a couple of times.
The torch install will install the one from the nightly build of PyTorch. Though if you are re-installing/upgrading torch from a prior install, you probably want to do it like this as well using the --no-deps option, though no guarantee that you don't need to reinstall everything which comes along with PyTorch. (including it's NumPy as versions other than 1.25.2 will produce an error)
The install of requirements_nocuda.txt will downgrade your NumPy version to 1.24.0 if you have 1.25.2 installed so you may want to re-install or upgrade your NumPy version anyway. Upgrades of NumPy will complain that you have a incompatible versions of torch, torchvision and torchaudio, all of which I think can be safely ignored as those packages are not aware of the new development builds of PyTorch. So the warning may be safely ignored, even though it's in nice red text.
The last, (optional) instruction will get you llama-cpp-python so you can use GGUF models with M1/M2 GPU acceleration on Apple Silicon. It will also build a new NumPy which is one of the requirements for llama-cpp-python. The accelerated NumPy will speed up anything like PyTorch or other modules which use NumPy fro matrix manipulation. A word of caution is that NumPy team had this initially in NumPy, but dropped it in version 1.20 or 1.21, I forget which, due to inconsistent results. However, while it fails some of its regression tests, this is typical of NumPy to fail a couple, but I haven't had a chance to look into the exact failures. NumPy pre-built fails some regression tests as well, and it looks like it may be the same regression tests.
My latest oobabooga-macOS was going to be a merge of the tagged release of oobabooga 1.5, but I have added some basic level of support for Llama2 and now that the GGUF file format is out, I am right now getting many of the new oobabooga features in their current main branch incorporated into mine for macOS and have stopped adding things to the 1.3.1a version in my test tree on GitHub, but GGUF and Llama2 support are in my dev branch and are working just fine, but not all the changes are implemented. If you'd like this my "in dev" version of oobabooga-macOS, you can clone the repository, even better, if you haven't modified any of the distribution files, you may be able to do a fetch, but here's how to clone.
# cd to directory wheer you want the clone to be placed.
git clone --branch dev https://github.com/unixwzrd/text-generation-webui-macos.git webui-macOS
cd webui-macOS
python server.py --chatFollow the link to the PR, and I was wrong in my reply, it's been almost two months. Time certainly does fly by...
@101is5 you get a special mention here because this made my day.
Some people have reviewed the installation instructions and given me changes. They have been updated. Hopefully you were able to work through it, though comments and suggestions are always welcome. The scripted method for installing is coming soon. I know I keep saying this, but I am in final testing of it and will let everyone know here when it's complete.
Thanks again to all who have helped out!
GPT-4 was offline a good portion of the week last week, and I have my Internet connection upgraded. The upgrade to my connection was so I could download more than 1.2TB per month. The good folks at Comcast/Xfinity were kind enough to add an additional $25 to my monthly bill for this. I've never heard of a cap like this and it was amazing that about 20 years ago in Japan, I could get Fibre to MY HOUSE for about $70/month with 100MB speed up and down. Toss in an extra $10 and you could get 1GB up and down (Yes, that's Giga). That was way more than mu WiFi router could handle, but the machines directly connected, it was AMAZING! There were about 5 companies all competing for business, wchih was good for the consumer and drove prices down. With Comcast/Xfinity, I pay more and get worse service, they are the only provider I can get where I live, so they have me over the proverbial barrel.
I've updated the instructions quite a bit and I've been given some feedback from testing and walkthroughs of the instructions. I haven't had much time to get things running and play with the new llama.cpp, but it is quite fast and looks like it has many new features, including being able to convert just about any model into the new GGUF format.
Still working on the scripted VENV builds. Hope to have them up this week, but that';s the hope every week. I also and working through the GitHub Workflows to determine what needs to be done to create pre-built binaries and installs for the llama.cpp,python wheels to support oobabooga and macOS. Ive never created GitHub workflows before or wheels for Python, it may take a bit to get this going, but doesn't look like too much to get done.
It's been a very busy couple of weeks for me as things change quickly every day. Please feel free to comment in the discussions, and as always thanks goes out to the oobabooga team.
Living the dream of high speed Internet and unlimited data.
- NOTICE GGML File Format Change to GGUF
The new llama.cpp is quite fast now and seems to take advantage of MPS now nicely. But in order to use the latest, any GGML files will need to be converted to GGUF files. It's quite simple to do. The script to do the conversion is in the llama.cpp repo and there is only one requirement is to import gguf into your Python installation.
then run the script:
convert-llama-ggmlv3-to-gguf.py
There are other conversion scripts in the llama.cpp for converting other formats. There is a notice regarding the latest repository to support GGML and that GGUF will be given a priority for now. This is great news for everyone who wants to use models.
Last llama.cpp commit to support GGML: master-ef3f333
This is the PR Discussing the new GGUF format: PR: #2398
Added and changed a few things in the instructions. Updated the dev and main repositories with new requirements. A few other items, not really significant. Continuing to test performance and for any issues or problems.
There does seem to be an inconsistency with one of my llama builds with torch, and I'm tracking it down now, but the one which is the base packages before rebuilding anything is due to the SciPy support that gets loaded with the oobabooga requirements, they took a different approach to their builds and combining their own Numpy embedded with the SciPy package somehow, or at least that's what it appears to be to me. I will continue to investigate and have an update soon.
- UPDATED QUICK INSTALL. PLEASE NOTE REGARDING GGML FILES, 0.1.78 llama-cpp-python must be used with GGML files. Both that version and the latest will work with LLaMa2.
Have spent much time looking at Python packages for numerical analysis, data analytics and AI. There are many different combinations of libraries, depending on which order you install them and whether you compile in the Accelerate Framework. I believe it is working for the most part, but I haven't tested it completely. However, PyTorch now fully supports Apple Silicon, but other Python modules dance on some of the libraries installed by NumPy and PyTorch, specifically the BLAS libraries. I have a configuration tool I was putting together in Bash, but the logic ran me into a wall regarding graph traversal, so I am planning to have that re-done in Python.
I will be putting up the Bash script, likely in its own repository, since other VENV build tools will be added and I plan to add benchmarking and regression testing to the process. There is value in it now as it can help simplify your builds for your VENVs and create consistent builds every time and in a sequence you configure. It also contains a portion for setting up/updating your personal Conda. Through this process I have discovered a lot about the state of Linear Algebra packages available, who uses them and what configurations they support.
Presently, there are no BLAS packages which directly support Apple Silicon which I am able to find. If someone does discover one, I will add it to the mix. The build configurations I've checked are OpenBLAS, BLIS, Apple's Accelerate Framework, and the various libraries included with Python packages. There is a lot here and I will have more on that, hopefully soon.
The library which llama.cpp uses, formerly GGML, is now GGUF, and will require any GGML models to be converted to GGUF format. This process is fairly quick, but involves installing a Python package from source, though it may be available soon on PyPi or other location. I will write that up as soon as I have time. This new version seems to be very fast, relative to things from the past, especially on Apple Silicon, making use of the Unified Memory and M1/M2 GPU. I am updating my "dev" version of oobabooga, specifically for macOS, and it is now available for download and will run with LLaMa2. It will even load the 70B LLaMa2 model on a MacBook Pro with 96GB Unified Memory.
I know it's been a little while since I had anything to write, but there's a lot to report. I am planning on more updates later today and over the next few days. Please feel free to take advantage of the "Discussions" here on my GitHub if you like or you can reach out to me as I am usually in the oobabooga Discord in the #mac-setup channel.
Thank you to all who have helped support me in working on this project, your kind assistance is very much appreciated, of all varieties.
While most of this may seem like a moving target, I have discovered inconsistencies in how packages will overlay each other's dynamic linked libraries and will also not completely uninstall themselves using either Pip or Conda. I have searched most everywhere I can find information about linear algebra and matrix manipulation. It was way more than I ever really wanted to, but it's given me more understanding of how things work inside language models and given me a deeper appreciation for understanding less about how they store and retrieve information the way they do. I completely understand the theory of how they are seeking a minima in the matrix space, but exactly how things get coded in their matrix and how they can retrieve things, still amazes me. I suppose those who say they are simply statistical models which are good at predicting the next token in sequence, but even considering that, it opens up a whole can of worms, technically and even philosophically. Maybe everything is deterministic and it's tru we have no free will, only the illusion of it. Anyway, that's an entirely different discussion.
I am texting my VENV build, benchmarking, and regression test automation. I have run through the process manually for a few iterations, but it quickly become error-prone to continue manually. I have automated all aspects of the VENV build down to the BLAS libraries I'll be using. I know I keep saying it will be just another few days, but I want to make sure everything is tested and I have a flexible enough build and test framework constructed so if new conditions arise, the framework is still usable or rather re-usable when new situations arise.
I also updated the information in the build process regarding some of my findings about package managers which only support my view that they can cause more problems than they solve if they are not carefully coordinated between various packages and package build teams. Sometimes common areas are subject to pollution.
So far it's taken a bit more than a week and I've been in contact with a few others to tests do of our ideas on optimizing the various Python modules/packages on Apple Silicon and here my progress so far:
- Put development and work on next release of oobabooga for macOS on hold until performance issues are investigated. This means merging oobagooba code for their 1.5 release into my codebase is on hold along with any changes I am putting into the code until there was an explanation or understanding of the performance issues.
- Test a full build of the environment using modules which are required by the oobabooga/text-generation-webui.
- Collecting some basic timing metrics along the way as the environment is built up.
- Look for changes in those metrics in order to identify possible issues.
- Compare GGML models running in obabooga and native llama.cpp to see if there is any difference between them.
- Gather as much information from as many sources regarding performance and issues arising from using the M1/M2 GPU.
- NumPy rejected using the Apple Accelerate Framework, stating it was giving inaccurate results during testing, so in their 1.20.1 release, they deprecated its use.
- There are numerous BLAS and LAPACK packages, including BLIS, which I have tested, though primarily to see if they were using the GPU for processing and so far I cannot see any using it.
- Apple's Accelerate Framework is "kinda" built into many of the numerical analysis packages, but it is difficult to see if they actually support it or not.
- NumPy who officially state they do not approve use of Accelerate, include it in their build, if you build it in a particular manner. I discovered this by accident after doing a recompile without any BLAS/LAPACK libraries in a searchable location for it to link with. It linked with the Accelerate framework.
- While things seem to compile with the Accelerate Framework, it is unclear to me where the libraries are I am linking to exist. Running otool on my final linked package reveals that I am linking to a location where symbolic links exist for the libraries, but they are all broken.
My conclusions so far is there are performance issues related to inefficient processing is, there are problems, they need more investigation, there is much contradictory information floating around, there is more testing to be done. These issues should not hold up further release of code into the "dev" tree for my branch of oobabooga. I intend to do this very soon, in the next day or two. After that, it will be available for download by anyone to test and report any issues related to running on macOS. I will go back to looking for performance issues again in the various modules.
My reasons for releasing is to allow people to use and test some of the new features like increased context length, and llama2 support mainly. This seems to make sense because the issues will still be with us in the near future, and holding up any software release doesn't change that. Further, even though NumPy doesn't "officially" support the Accelerate Framework, the latest releases of PyTorch and I assume SciPy as well both support Apple Silicon and both of these sit on top of NumPy, so, if they certify things work on Apple Silicon, then I can only assume they are happy with the NumPy ability to work with it too.
I'll continue testing and benchmarking things and will try to get some real numbers produced and presented soon. No matter what, keep watching this spot for my latest updates on this issue.
Well, I haven't tried the latest main branch of oobagooba as I'm still on a working 1.3.1 I have in my repository. I'm sorting some performance and library compatibility issues out now, but hope to be back to getting a 1.5 release which is tested and running on macOS using Metal. Metal also happens to be the piece I'm looking into deeply because there seem yo be issues about it using GPU or CPU or both, I have just about got a test framework setup for different combinations of things like NumPy, Pandas, PyTorch, and will test them in various configurations.
One item I discovered is depending on what was installed when and whether you have BLAS and LAPACK libraries, you can get distinctly different results, so I'll also run the regression tests for NymPy especially.
There are two options for matrix manipulation, use GGML (in llama.cpp) or use LAPACK and BLAS, all available from different places. I have not found a BLAS/LAPACK which runs on the Apple Silicon GPU, which is why GGML exists, as far as I can read. The only thing which does run on the M1/M2 GPU is the BLAS and LAPACK Apple includes with their Accelerate Framework. NumPy does not recommend using this as it gives inconsistent results past version 1.20.1 of NumPy, however, I'm trying the newer versions of the libraries because the speedup is about 5-7x.
There are so many funny interdependencies in the libraries and library managers between pip and conda, sometimes they leave bits of what they installed after you uninstall them. This only makes matters worse, because if you are using NumPy, you could be using a library from just about anywhere.
I'm also writing the Apple Dev Team a letter letting them know I am not particularly thrilled with their response to problems with Accelerate being basically the same as the NumPy, PyTorch and SciPy people give is "Oh, it's not out problem, contact the vendor (Apple)" When I look at Apple's site, their response is, "Oh, it's not our problem, contact the developer (Open Source Team)." Both groups need to talk with each other otherwise nothing will get done. and Apple should be much more supportive of the OpenSource Community or they will loose out to Nvidia and Hugging Face.
Wanted to give an update. Have found an issue with re-installing and installing new modules and packages. All seems to be linked back to BLAS and LAPACK. it seems the installation order affects how the BLAS and LAPACK libraries are handles, even when not doing a recompile of the module or package. I'm able to reproduce my results, but haven't found any definite answer to the performance issues encountered using oobabooga. Many people with many different opinions on the cause, but I haven't seen a real solution yet.
I've been combing through anything I can find, but it's all very limited in content. Apple doesn't seem to be talking about how to use their high performance architecture and I even found in the release notes for NumPy that they had issues a couple of releases ago regarding inconsistent results from the Accelerate Framework, advising anyone who had a problem with this to contact Apple. Not cool on either party's part in pointing fingers. From what I can tell, no one from the NumPy team or Apple has actually tried to sit down and resolve the issues together, though this is speculation gathered from what I have read and been able to find on the Internet, which is sparse.
I have other conjectures as well, that the whole reason that llama-cpp-python exists if due to this dependency issue and it comes with its own required linear algebra support library. Probably due to what I discovered that packages which need this will bring it along and drop it in the Python library, but also don't uninstall it when they are installed, so there's a libblas sitting in the lib directory of your venv's "root" hierarchy.
After looking at the release notes for NumPy, I figured it would be a good idea to get the source for NumPy and try the regression tests from the various configurations I find being installed. I even just today found a new one which gets configured and not really mentioned anywhere I can recall, of "openblas64" which was pulled from my /usr/local/lib build I did of OpenBLAS. To muddy things further, depending on which libraries and where they come from, there are differences in the results of regression testing. Even when using the stock standard NumPy install. All needs tracking down which I am working on doing as quickly as possible.
Not alone in this, several have approached me willing to assist in testing in with various configurations. So far, we replicated my results, but still not sure how to proceed. Bottom line is, I am hopeful regarding using the Accelerate Framework, but I must do more testing on the combinations, ordering and dependencies of the Python modules and packages. I'll keep updating here with my progress. More to come...
I Spent a good portion of today and yesterday evening rebuilding my machine learning and data analytics Python packages required for oobabooga support, the information is also helpful for anyone who uses Apple Silicon Macs for these purposes.
Need to look into this some more. Don't want to lead anyone down a blind alley, but I think I have found a significant performance solution for Python Data Analytics and AI packages. I'll need to collect more information, but I have repeatable tests which show dramatic increases and performance with NumPy and very reduced CPU utilization. More to come...
I'm have to rebuild my venv because I accidentally created inconsistencies in my Python packages, and this seems like a good a point as any to try to optimize the packages. In doing this I found something interesting when getting NumPy installed. Looking for a faster alternative to OpenBLAS or a way to have use the Apple Silicon GPU, I discovered BLIS, a faster linear algebra library. To compare I put together a quick Python script t benchmark different builds of NumPy but noticed when Pip does a recompile of NumPy, it actually looks for and finds the Apple Accelerate Framework which leverages their superscalar GPU and Neural engine technology for processing vectors and tensors. I assume this is due in part by the recent upgrade to macOS 13.5 and the NumPy team putting it into their package when you compile at install time using Pip.
More info to come as I try to optimize these packages which are used for AI, but also Data Science and Analytics. Keep an eye out here and you will see updated information posted in this repository regarding package optimization soon.
THIS IS IMPORTANT Whatever terminal package you use to access the command line, make absolutely sure the "Open using Rosetta" checkbox is unchecked in the "Get Info" pop-up. Someone reported an issue with the pip installation instructions, and I was able to replicate the issue I believe because I had set iTerm2 to open in Rosetta a while back to do some testing and forgot to change it back. I was in the process of rebuilding my venvs have to rebuild a couple of them because running in Rosetta can produce inconsistent results, especially for things like builds. Also, if your Python packages and libraries are installed in this manner, they will perform slower because the Intel code has to be translated to run.
Another thing, NOT DO the macOS 13.5 update, it is broken in many ways. WebKit crashes every now and then, Private Relay breaks things like accessing OpenAI and more, there are issues with the overall UI as well.
Currently I am finishing up changes to the release 1.5 oobabooga and integrating them into my fork and may or may not have additional performance improvements I have identified for Apple Silicon M1/M2 GPU acceleration. I hope by the end of this week. I will release it in my test fork I created to allow people to test and provide feedback.
I also got distracted earlier in the week by looking for another TTS alternative to Elevenlabs which runs locally and am also working on incorporating full Apple Silicon into Coqui TTS soon as well, first as a stand-alone system, but then as an extension alternative for Elevenlabs and Silero. Getting sidetracked with Coqui delayed ny progress on the 1.5 oobabooga effort. However, I should have a complete set of modifications for Coqui to support Apple Silicon GPU acceleration and I plan to create a pull request for Coqui, so they may integrate my changes. Honestly, their code seems very well written and it was very easy to read and comprehend. They did a great job with it.
As always, please leave comments, suggestions and issues you find so I can make sure they are addressed. Testers, developers and volunteers are also welcome to help out. Please let me know if you would like to help out.
I forked the last working oobagooba/text-generation-webui I knew of that worked with macOS. I had to make some change=s to its code so it would process most of the model using Apple Silicon M1/M2 GPU. I am working on adding some of the new features of the latest oobabooga release, and have found further areas for optimization with Apple Silicon and macOS. I am working as fast as I can to get it upgraded as GGML encoded models are working quite well in my release. I have found some issues with object references in Python being corrupted and causing some processing to fall back to CPU. This is likely a problem for CUDA users due to the extensive use of global variables in the core oobabooga code. It's taking quite a bit of effort to decouple things, but after I do some of that, performance should improve even more. Once I have that done, I want to incorporate RoPE, SupertHOT 8K context windows, and new Llama2 support. the last item shouldn’t be terribly difficult since it's built into the GGML libraries which hare part of llama.cpp.
If you are interested in trying out the macOS patched version, please grab it from here: text-generation-webui-macos
I hope to have an update out within the week. Again, anyone who want to test, provide feedback, comments, or ideas, let me know or use the "Discussions", at the top of the GitHub page and add to the discussion or start a new one. Let's help the personal AI on Apple Silicon and macOS grow together.
I've had a fe more people contact me with issues and that's a good thing because it shows me there is an interest in what I am trying to do here and that people are actually trying my procedures out and having decent success.
I want to start getting more features into the fork I created like Llama2 support. If I can do that, the next ting I will likely do is start looking at some of the performance enhancements I have thought of as well as trying to fix a couple of UI/UX annoyances and a scripted installation and...
If anyone would like to help out, please let me know.
Earlier problems with the new llama-cpp-python worked out. Seems setting --n-gpu-layers to very big numbers is not good anymore. It will result in overallocation of the context's memory pool and this error:
ggml_new_tensor_impl: not enough space in the context's memory pool (needed 19731968, available 16777216) Segmentation fault: 11
An easy way to see how many layers a model uses is to turn on verbose mode and look for this in the output of STDERR:
llama_model_load_internal: n_layer = 60
It's right near the start of the output when loading the model. Apparently the huge numbers above the number of layers is not best to, "Set this to 1000000000 to offload all layers to the GPU." breaks the context's memory pool. I haven't figured out the proper high setting for this, but you can get the number easily enough by loading your model and looking for the n_layer line, then unload the model and put that into n-gpu-layers in the Models tab. BE sure to set it so it's save for the nest time you load the same model.
The output of STDERR is also a good place to validate if your GPU is actually being accessed if you see lines with ggml_metal_init at the start of them. It doesn't necessarily mean it's being used, only that llamacpp sees it and is loading supported code for it. Unload the model and then load it again with the new settings.
Someone gets a HUGE thank you for being the first person to give feedback and help me make things better! They actually went through my instructions and gave me some feedback, spotted a few typos and found things to be useful. You know who you are! 👍
Someone else also asked if this would work for Intel, I tried, but the python which comes with Conda is compiled for i386, which should work(?) but doesn't and should be x86_64. Might work for Intel macOS, but would be difficult when you try getting Conda to install PyTorch, that won't work well. I'm sure I could hack it to make it work, but that would be a nasty hack. Not only that, I was trying to run things on a 32GB MacBook Pro and having memory issues, I doubt many Intel Macs out there have much more than 32GB and even though they have unified memory, my bet is they would still be slow. I gave up when I figured out that Conda wouldn't install on my 16GB Intel MacBook Pro. Never thought I'd need tat much RAM, but initially I was going to get 64GB and then swapped my 36GB Apple Silicon MBP for 96BG. 😮
If anyone is interested in helping out with this effort, please let me know. I'm in the oobaboga Discord #mac-setup channel a good bit, or you may reach me through GitHub.
I managed to get the code back together from an unwanted pull of future commits, I had things mis-configured on my side. The patches are applied and it just needs some testing. So far I have only really briefly tested with a llama 30B 4bit quantized model and I am getting very reasonable response times, though there it is running a range of 1-12 tokens per second. It seemed like more yesterday, but it's still reasonable.
I have not tested much more than a basic llama which was 4 bit quantized. I will try to test more today and tomorrow.
If anyone else is interested in testing and validating what works and what doesn't, please let me know.
I merged with one commit too far ahead when I created the created the dev-ms branch with a merge back to the oobabooga main branch. I'll need a bit of time to sort the code out. Until then, I don't know of a working version around. I'll have to sort through my local repository and see if I have something I can create a new repository with or revert to a previous commit.
I'll update the status on my repository and here when I get it sorted out.
The new oobabooga does not support macOS anymore. I am removing the fork I was working on because there are code changed specifically for Windows and Linux which are not installed on macOS, so the default repository is now the one I generated a pull request for to fix things so Apple Silicon M1 and M2 machines would use GPU's. It's going to get it sorted out, but I will do it as soon as I can. Here's the command to clone the repository and if you have any problems with it, let me know.
git clone https://github.com/unixwzrd/text-generation-webui-macos.gitNew Python llama-cpp-python out. Need to be installed before loading running the new version of oobabooga with Llama2 support.
Same command top update as yesterday, it will grab llama-cpp-python.0.1.77.
I'm trying things out now here.
Ok, a big week for LLaMa users, increased context size roiling out with RoPE and LLaMA 2. I think I have a new recipe which works for getting the llama-cpp-python package working with MPS/Metal support on Apple Silicon. I will go into it in more detail in another document, but wanted to get this out to as many as possible, as soon as possible. It seems to work and I am getting reasonable response times, though some hallucinating. CAn't be sure where the hallucinations are coming from, my hyperparameter settings, or incompatibilities in various submodule versions which will take a bit of time to catch up. Here's how to update llama-cpp-python quickly. I will go into more detail later.
# Take a checkpoint of your venv, incase you have to roll back.
conda create --clone ${CONDA_DEFAULT_ENV} -n new-llama-cpp
conda activate new-llama-cpp
pip uninstall -y llama-cpp-python
CMAKE_ARGS="--fresh -DLLAMA_METAL=ON -DLLAMA_OPENBLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" \
FORCE_CMAKE=1 \
pip install --no-cache --no-binary :all: --upgrade --compile llama-cpp-pythonThe --fresh in the CMAKE_FLAGS is not really necessary, but won't affect anything unless you decide to download the llama-cpp-python repository, build, and install from source. That's bleeding edge, but if you want to do that you also need to use this git command line and update your local package source directory of just create a new one with teh git clone. The BLAS setting changed and only apply if you've built and installed OpenBlAS yourself. Instructions are in my two guides mentioned above.
conda create --clone ${CONDA_DEFAULT_ENV} --n new-llama-cpp
conda activate new-llama-cpp
git clone --recurse-submodules https://github.com/abetlen/llama-cpp-python.git
pip uninsatll -y llama-cpp-python
cd llama-cpp-python
CMAKE_ARGS="--fresh -DLLAMA_METAL=ON -DLLAMA_OPENBLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" \
FORCE_CMAKE=1 \
pip install --no-cache --no-binary :all: --upgrade --compile -e .NOTE when you run this you will need to make sure whatever application is using this is specifying number of GPU or GPU layers greater than zero, it should be at least one for teh GGML library to allocate space in the Apple Silicon M1 or M2 GPU space.
It seems that there have been many updates the past few days to account for handling the LLaMa 2 release and the software is so new, not all the bugs are out yet. In the past three days, I have updated my llama-cpp-python module about 3 times and now I'm on release 0.1.74. I'm not sure when things will stabilize, but right before the flurry of LLaMa updates, I saw much improved performance on language models using the modules and packages installed using my procedures here. My token generation was up to a fairly consistent 6 tokens/sec with good response time for inference. I'm going to see how this new llama-cpp-python works and then turn my attention elsewhere until the dust settles.
I submitted a couple of changes to oobabooga/text-generation-webui, but not sure when those changes will be pushed out. I will probably fork a copy of the repository and path it here, making it available until my changes are incorporated into the main branch for general availability. I should, hopefully have that a little later today, as long as git cooperates with me. I will be the first to admit I am not great with Git, so learning VSCode and using Git have been kinda rough on me as I come from a very non-Windows environment and have used many other version control systems, but never used Git much. I will probably get the hang of it soon and finish making the transition from using vi in a terminal window to a GUI development environment like VSCode. At least it has a Vim module to plugin, now if they can get "focus follows mouse" to work within a window for the different frames, I'll be very happy.
Many modules were bumped in version and some support was added for the new LLaMa 2 models. I don't seem to have everything working, but did identify one application issue which will increase performance fro MPS, if not for CUDA.
The two TTS modules use the same Global model variable in them, so model gets clobbered if you use them. I've submitted a pull request for this. Dev ms #3232 and filed a bug report Use of global variable model in ElevenLabs and Silero extensions clobbers application global model. This was my first time submitting a pull request and submitting a bug report, took a long time to actually figure out how to do it, but maybe there is an easier way than what I did. Anyway, with this fix, macOS users with M1/M2 processors should see a vast performance improvement if you are using either of these TTS extensions.
Instructions have been updated. Also, there were some corrections as I was rushed getting this done. If you find any errors are think or a better way to do things, let me know.
Haven't tested it yet, but here's how to update yours. Will change this with the results of my testing.
CMAKE_ARGS="-DLLAMA_METAL=on -DLLAMA_OPENBLAS=on -DLLAMA_BLAS_VENDOR=OpenBLAS" \
FORCE_CMAKE=1 \
pip install --no-cache --no-binary :all: --force-reinstall --upgrade --compile llama-cpp-pythonFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for oobabooga-macOS
Similar Open Source Tools
yet-another-applied-llm-benchmark
Yet Another Applied LLM Benchmark is a collection of diverse tests designed to evaluate the capabilities of language models in performing real-world tasks. The benchmark includes tests such as converting code, decompiling bytecode, explaining minified JavaScript, identifying encoding formats, writing parsers, and generating SQL queries. It features a dataflow domain-specific language for easily adding new tests and has nearly 100 tests based on actual scenarios encountered when working with language models. The benchmark aims to assess whether models can effectively handle tasks that users genuinely care about.
llm_engineering
LLM Engineering is an 8-week course designed to help learners master AI and LLMs through a series of projects that gradually increase in complexity. The course covers setting up the environment, working with APIs, using Google Colab for GPU processing, and building an autonomous Agentic AI solution. Learners are encouraged to actively participate, run code cells, tweak code, and share their progress with the community. The emphasis is on practical, educational projects that teach valuable business skills.
AnnA_Anki_neuronal_Appendix
AnnA is a Python script designed to create filtered decks in optimal review order for Anki flashcards. It uses Machine Learning / AI to ensure semantically linked cards are reviewed far apart. The script helps users manage their daily reviews by creating special filtered decks that prioritize reviewing cards that are most different from the rest. It also allows users to reduce the number of daily reviews while increasing retention and automatically identifies semantic neighbors for each note.

local-chat
LocalChat is a simple, easy-to-set-up, and open-source local AI chat tool that allows users to interact with generative language models on their own computers without transmitting data to a cloud server. It provides a chat-like interface for users to experience ChatGPT-like behavior locally, ensuring GDPR compliance and data privacy. Users can download LocalChat for macOS, Windows, or Linux to chat with open-weight generative language models.
aiohomekit
aiohomekit is a Python library that implements the HomeKit protocol for controlling HomeKit accessories using asyncio. It is primarily used with Home Assistant, targeting the same versions of Python and following their code standards. The library is still under development and does not offer API guarantees yet. It aims to match the behavior of real HAP controllers, even when not strictly specified, and works around issues like JSON formatting, boolean encoding, header sensitivity, and TCP packet splitting. aiohomekit is primarily tested with Phillips Hue and Eve Extend bridges via Home Assistant, but is known to work with many more devices. It does not support BLE accessories and is intended for client-side use only.
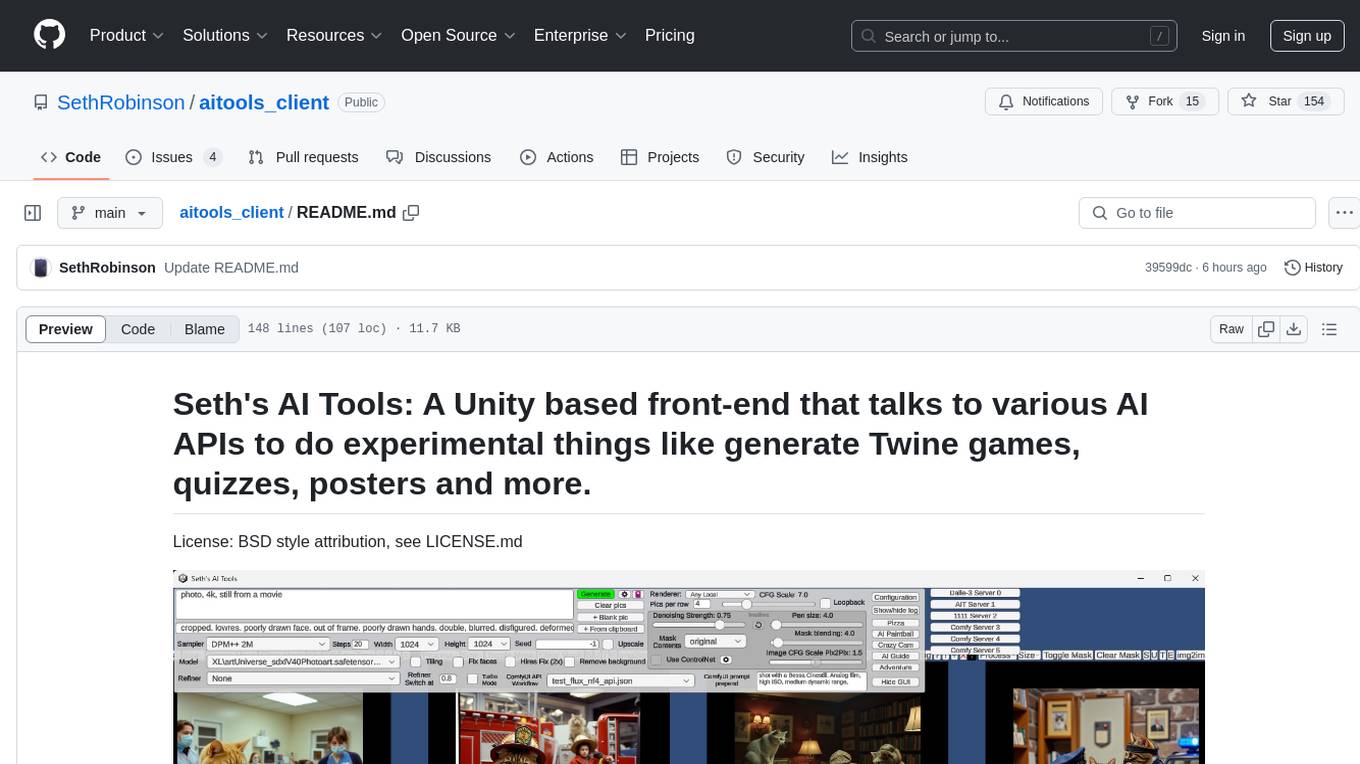
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
iris-llm
iris-llm is a personal project aimed at creating an Intelligent Residential Integration System (IRIS) with a voice interface to local language models or GPT. It provides options for chat engines, text-to-speech engines, speech-to-text engines, feedback sounds, and push-to-talk or wake word features. The tool is still in early development and serves as a tutorial for Python coders interested in working with language models.
shitspotter
The 'ShitSpotter' repository is dedicated to developing a poop-detection algorithm and dataset for creating a phone app that helps locate dog poop in outdoor environments. The project involves training a PyTorch network to detect poop in images and provides scripts for detecting poop in unseen images using a pretrained model. The dataset consists of mostly outdoor images taken with a phone, with a process involving before and after pictures of the poop. The project aims to enable various applications, such as AR glasses for poop detection and efficient cleaning of public areas by city governments. The code, dataset, and pretrained models are open source with permissive licensing and distributed via IPFS, BitTorrent, and centralized mechanisms.
coding-with-ai
Coding-with-ai is a curated collection of techniques and best practices for utilizing AI coding tools to achieve transformative results in coding projects. It bridges the gap between AI coding demos and daily coding reality by providing insights into specific patterns like memory files, test-driven regeneration, and parallel AI sessions. The repository offers guidance on setting up memory files, writing detailed specs, drafting solutions before using assistants, getting multiple options, choosing stable libraries, and triggering careful planning. It also covers UI prototyping, coding practices, debugging strategies, testing methodologies, and cross-stage techniques for efficient coding with AI tools.
femtoGPT
femtoGPT is a pure Rust implementation of a minimal Generative Pretrained Transformer. It can be used for both inference and training of GPT-style language models using CPUs and GPUs. The tool is implemented from scratch, including tensor processing logic and training/inference code of a minimal GPT architecture. It is a great start for those fascinated by LLMs and wanting to understand how these models work at deep levels. The tool uses random generation libraries, data-serialization libraries, and a parallel computing library. It is relatively fast on CPU and correctness of gradients is checked using the gradient-check method.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
bidirectional_streaming_ai_voice
This repository contains Python scripts that enable two-way voice conversations with Anthropic Claude, utilizing ElevenLabs for text-to-speech, Faster-Whisper for speech-to-text, and Pygame for audio playback. The tool operates by transcribing human audio using Faster-Whisper, sending the transcription to Anthropic Claude for response generation, and converting the LLM's response into audio using ElevenLabs. The audio is then played back through Pygame, allowing for a seamless and interactive conversation between the user and the AI. The repository includes variations of the main script to support different operating systems and configurations, such as using CPU transcription on Linux or employing the AssemblyAI API instead of Faster-Whisper.
ai-agents-masterclass
AI Agents Masterclass is a repository dedicated to teaching developers how to use AI agents to transform businesses and create powerful software. It provides weekly videos with accompanying code folders, guiding users on setting up Python environments, using environment variables, and installing necessary packages to run the code. The focus is on Large Language Models that can interact with the outside world to perform tasks like drafting emails, booking appointments, and managing tasks, enabling users to create innovative applications with minimal coding effort.
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
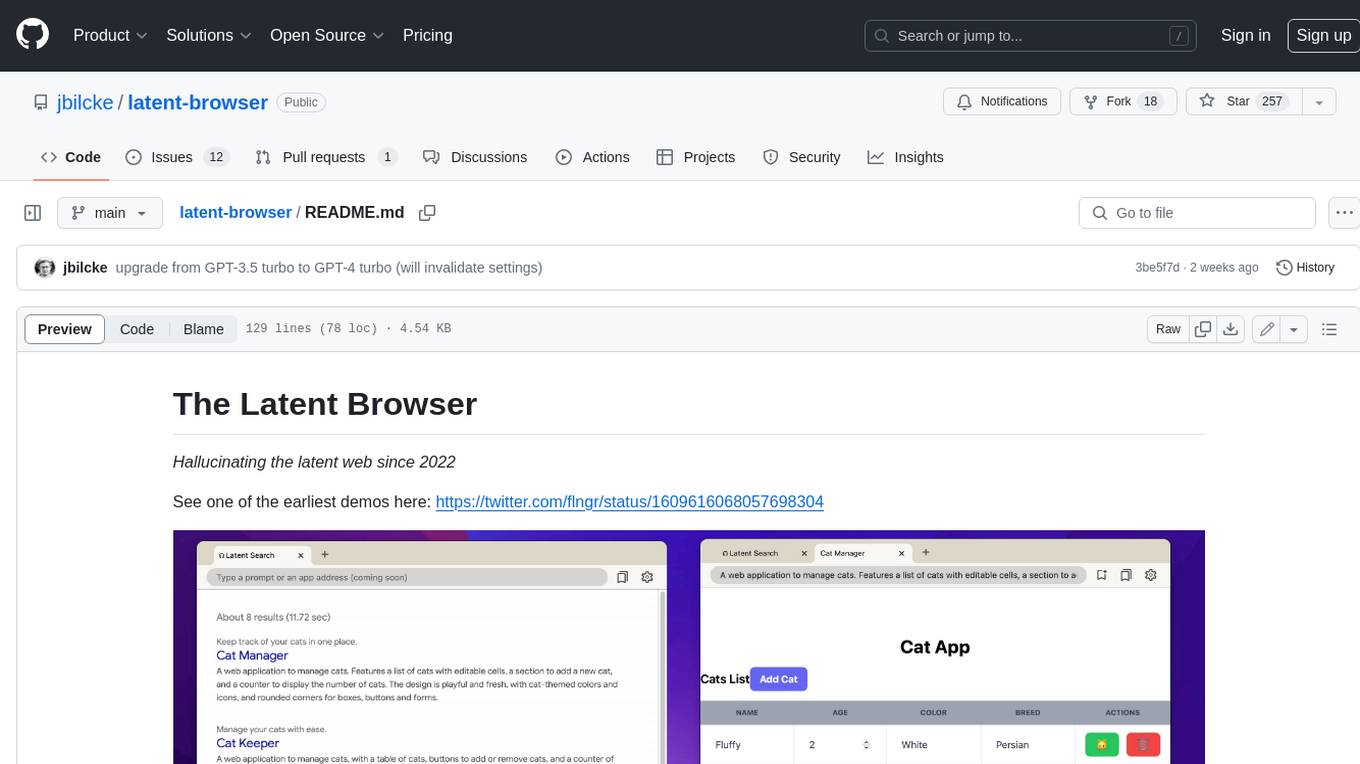
latent-browser
The Latent Browser is a desktop application designed like a web browser, which hallucinates web search results (the resultds are fictious and are generated by a LLM) and web pages. It is a web application designed to run locally on your machine and is 99% React, Tailwind, TypeScript, and NextJS. The runtime is Tauri, which is written in Rust. The Latent Browser is still under development and some things may be broken when you try it.