Best AI tools for< Audio Researcher >
Infographic
20 - AI tool Sites
Free Audio to Text Converter
The Free Audio to Text Converter is an AI-powered tool that allows users to quickly and accurately transcribe audio files into text. It supports various audio formats and offers features like multi-speaker identification, multiple export formats, and precise timestamps. The tool is designed to enhance productivity by providing high-quality transcriptions for a wide range of needs, from content creation to academic research and sales analysis. Users can trust the tool's accuracy and efficiency to save time and improve workflow.
Clip.audio
Clip.audio is an AI-powered audio search engine that allows users to search for and discover audio clips from a variety of sources, including podcasts, music, and sound effects. The platform uses advanced machine learning algorithms to analyze and index audio content, making it easy for users to find the specific audio clips they are looking for.
Article.Audio
Article.Audio is a web application that allows users to convert articles into audio files, enabling them to listen to the content instead of reading it. Users can easily convert text documents, PDFs, and web links into audio format using natural-sounding human voices. The application offers a user-friendly interface and supports multiple languages and voice styles. Article.Audio is powered by Thundercontent and aims to provide a convenient and accessible way for users to consume written content on the go.
Transkriptor
Transkriptor is an AI-powered tool that allows users to convert audio or video files into text with high accuracy and efficiency. It supports over 100 languages and offers features like automatic transcription, translation, rich export options, and collaboration tools. With state-of-the-art AI technology, Transkriptor simplifies the transcription process for various purposes such as meetings, interviews, lectures, and more. The platform ensures fast, accurate, and affordable transcription services, making it a valuable tool for professionals and students across different industries.
Ermine.ai
Ermine.ai is an AI-powered tool for local audio recording and transcription. It allows users to transcribe audio files into text with high accuracy and efficiency. The tool is designed to work seamlessly with Chrome browser, with Firefox support coming soon. Users can easily transcribe audio files in English by allowing microphone access and initializing the transcription model. Ermine.ai provides a convenient solution for transcribing audio content for various purposes, such as meetings, interviews, lectures, and more.
VidText AI
VidText AI is an advanced tool that offers video and audio to text transcription services with high accuracy and speed. It supports multiple languages, speaker recognition, and secure file management. Users can convert recordings, meetings, and videos into text or mind maps, making it convenient for various scenarios such as learning, meetings, and content creation. The tool also allows for easy summarization, chat interaction, and quick access to specific video positions from the transcribed text.
Shownotes Summarize with ChatGPT
Shownotes Summarize with ChatGPT is an AI-powered tool that helps you summarize long-form audio and video content. With just a few clicks, you can get a concise and accurate summary of any podcast, lecture, or meeting. Shownotes Summarize with ChatGPT is the perfect tool for busy professionals who want to stay up-to-date on the latest information without having to spend hours listening to or watching content.
Ragobble
Ragobble is an audio to LLM data tool that allows you to easily convert audio files into text data that can be used to train large language models (LLMs). With Ragobble, you can quickly and easily create high-quality training data for your LLM projects.
Trint
Trint is an AI transcription software that converts video, audio, and speech to text in over 40 languages with up to 99% accuracy. It allows users to transcribe, translate, edit, and collaborate seamlessly in a single workflow. Trint is trusted by professionals in various industries for its efficiency and accuracy in transcription tasks.
Gladia
Gladia provides a fast and accurate way to turn unstructured audio data into valuable business knowledge. Its Audio Intelligence API helps capture, enrich, and leverage hidden insights in audio data, powered by optimized Whisper ASR. Key features include highly accurate audio and video transcription, speech-to-text translation in 99 languages, in-depth insights with add-ons, and secure hosting options. Gladia's AI transcription and multilingual audio intelligence features enhance user experience and boost retention in various industries, including content and media, virtual meetings, workspace collaboration, and call centers. Developers can easily integrate cutting-edge AI into their products without AI expertise or setup costs.

Recast
Recast is a platform that transforms articles into rich audio summaries, making it easier for users to consume content on the go, while working out, or simply looking for a more convenient way to stay informed. It provides entertaining, informative, and easy-to-understand audio conversations, helping users save time, reduce screen-time, understand content more deeply, discover interesting stories, and clear their reading list. Recast aims to enhance the reading experience by converting long articles into engaging podcasts, enabling users to enjoy content in a conversational format.
Alphy
Alphy is an AI-powered tool that helps users transcribe, summarize, and generate content from audio and video files. It offers a range of features such as high-accuracy transcription, multiple export options, language translation, and the ability to create custom AI agents. Alphy is designed to save users time and effort by automating tasks and providing valuable insights from audio content.
OneAudio
OneAudio is an AI-powered tool that allows users to summarize, transcribe, and convert audio files into notes. With features like recording, summarization, and language selection, OneAudio helps users organize and transform their ideas efficiently. The tool leverages OpenAI GPT-4 and GPT-4o models to provide accurate transcriptions and summaries. Users can choose from different pricing plans based on their needs, from a free tier to a premium plan with unlimited features. OneAudio is designed to streamline the process of converting audio content into written notes, making it ideal for students, professionals, and anyone looking to enhance their productivity.
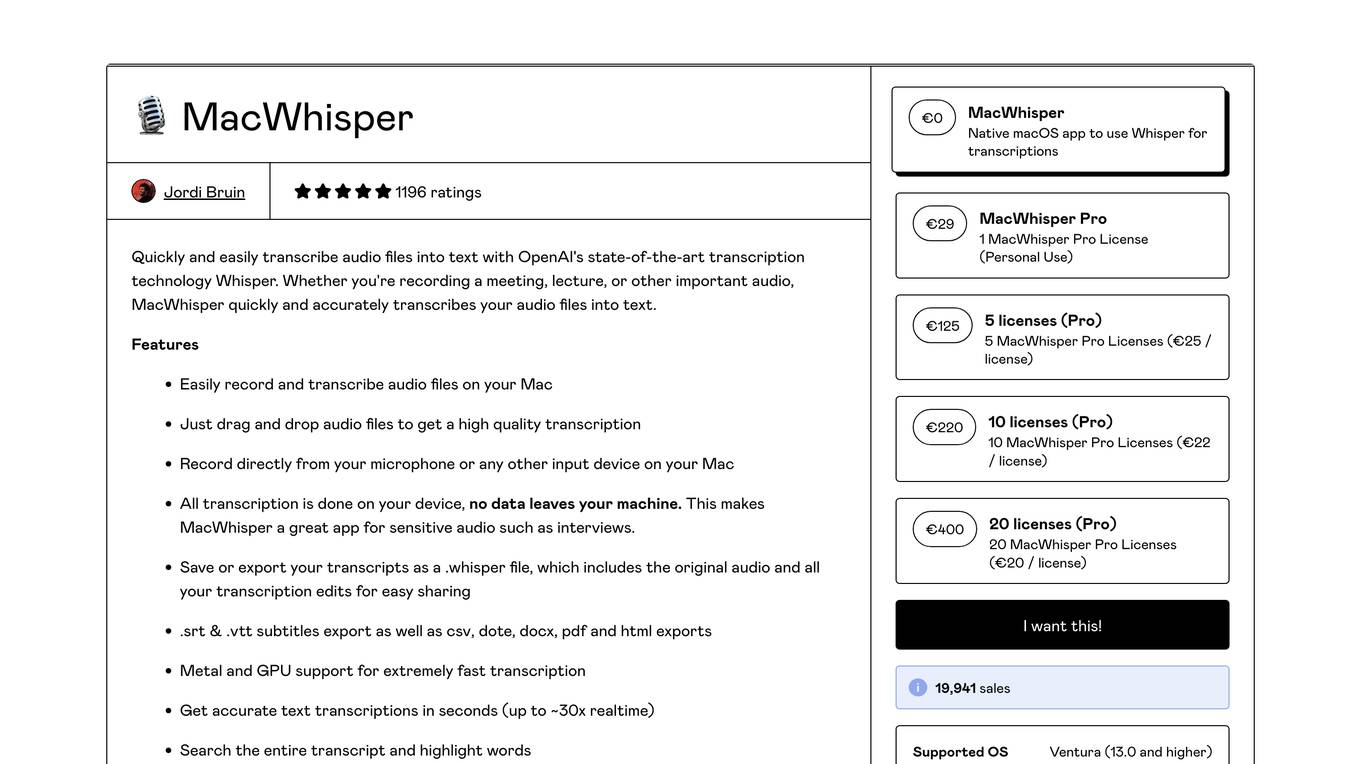
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
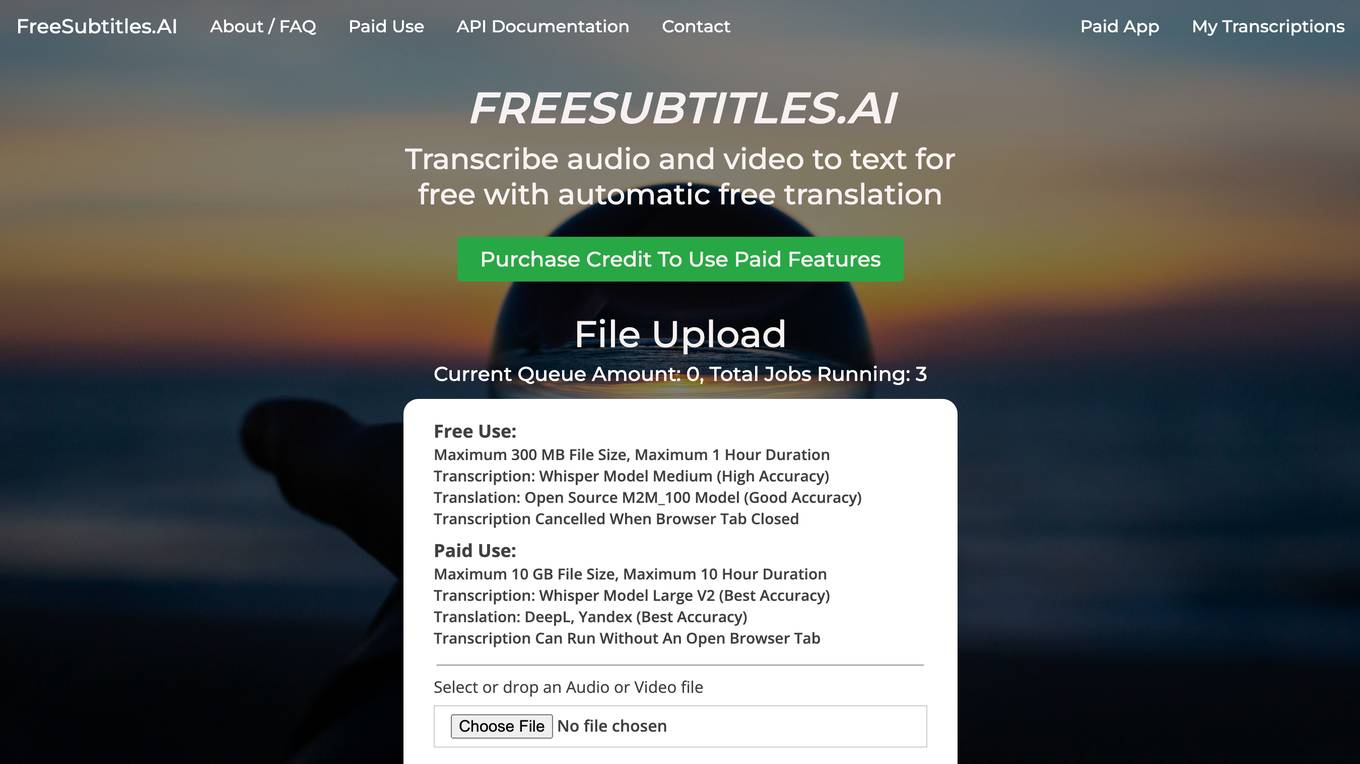
FreeSubtitles.AI
FreeSubtitles.AI is a free online tool that allows users to transcribe audio and video files to text. It supports a wide range of file formats and languages, and offers both free and paid transcription services. The free service allows users to transcribe files up to 300 MB in size and 1 hour in duration, while the paid service offers more advanced features such as larger file size limits, longer transcription durations, and higher accuracy models.
Verbit
Verbit is an AI transcription and captioning tool that utilizes advanced artificial intelligence technology to convert audio and video files into accurate text. The platform offers high-quality transcription services for various industries, including legal, media, education, and more. Verbit's AI algorithms ensure fast and precise transcriptions, saving time and effort for users. With a user-friendly interface and customizable features, Verbit is a reliable solution for all transcription needs.

Vscoped
Vscoped is an AI-powered audio to text transcribing service that provides fast and accurate transcriptions in over 90 languages. It also offers transcription insights and translation services. Vscoped is suitable for various types of audio content, including business meetings, interviews, sales calls, and videos. With its exceptional accuracy, multilingual capabilities, and intuitive user experience, Vscoped helps businesses and individuals boost productivity and gain insights from their audio data.
WavoAI
WavoAI is an AI-powered transcription and summarization tool that helps users transcribe audio recordings quickly and accurately. It offers features such as speaker identification, annotations, and interactive AI insights, making it a valuable tool for a wide range of professionals, including academics, filmmakers, podcasters, and journalists.
Ecango
Ecango is an AI-powered audio and video transcription tool that allows users to convert audio and video files into text in over 133 languages. It is easy to use, accurate, and affordable, making it a great choice for businesses and individuals alike.

NutshellPro
NutshellPro is an AI-powered tool that allows users to summarize any video or audio file. It uses advanced natural language processing and machine learning algorithms to extract the key points and generate a concise, easy-to-read summary. NutshellPro is designed to help users save time and effort by quickly getting the gist of any video or audio content.
2 - Open Source Tools

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.
neutone_sdk
The Neutone SDK is a tool designed for researchers to wrap their own audio models and run them in a DAW using the Neutone Plugin. It simplifies the process by allowing models to be built using PyTorch and minimal Python code, eliminating the need for extensive C++ knowledge. The SDK provides support for buffering inputs and outputs, sample rate conversion, and profiling tools for model performance testing. It also offers examples, notebooks, and a submission process for sharing models with the community.
20 - OpenAI Gpts
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!
ArtGPT
Doing art design and research, including fine arts, audio arts and video arts, designed by Prof. Dr. Fred Y. Ye (Ying Ye)

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.



Ethical AI Insights
Expert in Ethics of Artificial Intelligence, offering comprehensive, balanced perspectives based on thorough research, with a focus on emerging trends and responsible AI implementation. Powered by Breebs (www.breebs.com)
Solidity Sage
Your personal Ethereum magician — Simply ask a question or provide a code sample for insights into vulnerabilities, gas optimizations, and best practices. Don't be shy to ask about tooling and legendary attacks.
Professor Arup Das Ethics Coach
Supportive and engaging AI Ethics tutor, providing practical tips and career guidance.


DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages