Best AI tools for< Audio Editor >
Infographic
23 - AI tool Sites
AI Jingle Maker
AI Jingle Maker is the #1 AI Radio Jingle & DJ Drops Generator that allows users to create royalty-free jingles, DJ drops, sweepers, station IDs, podcast intros, and promos effortlessly. With over 65 voices, 1000+ sound effects, and unlimited variations, users can input their text and let the JINGLEMAKER magically generate their creations in seconds. The platform offers 100% royalty-free content that can be downloaded instantly, catering to both personal and commercial use. Additionally, users can leverage the generative AI to create longer promos and bespoke sung jingles, making it a versatile tool for audio production.
Audio.co
Audio.co is an AI-powered platform that enables users to create high-quality audio content effortlessly. Formerly known as RadioNewsAI, Audio.co offers tools for producing news, ads, weather reports, and traffic updates with the help of AI technology. Users can customize voices, add backing music, and generate content ready for broadcast. The platform is user-friendly, affordable, and trusted by radio stations worldwide.

Voice-Swap
Voice-Swap is an AI voice transformation tool designed for musicians and creators. It allows users to create custom AI voice models using the Model Studio, share them via a free VST Plugin, and embed AI voices in apps using the API. With high-quality AI voices, Voice-Swap has gained popularity among professional creators and companies. The platform offers a range of features and benefits for transforming voices with AI, making it a valuable tool for music production and content creation.
Vocalremover.org
Vocalremover.org is a website that offers a tool to remove vocals from music tracks. Users can upload their audio files and the tool will process them to create a version with the vocals removed. The site aims to provide a simple and efficient solution for users looking to create karaoke tracks or instrumental versions of songs. Vocalremover.org ensures security by verifying user connections and requires enabling JavaScript and cookies for smooth operation.
Outcast
Outcast is an AI-powered platform that helps podcasters and content creators to easily create clips, notes, and posts from their episodes. With features like Prompt Packs, Audiogram Maker, Episode Transcript, Episode Chatbot, and AI Studio, Outcast streamlines the process of podcast creation and repurposing. It offers a 7-day free trial with 60 minutes of uploads, supports content imports from YouTube links, RSS feeds, and file uploads, and provides transcription in 17 languages. Outcast aims to enhance podcasters' workflow by automating tasks and facilitating collaboration among team members.
GoodListen
GoodListen is an AI tool designed for podcast studios. It offers a platform for both listeners and creators to discover, learn, and enjoy valuable short clips from podcasts and YouTube videos with the help of AI. GoodListen Studio utilizes generative AI technology to repurpose long podcast audio into highlights, chapters, and clips in a single click. The tool is powered by cutting-edge AI models and seamlessly integrates with platforms like Spotify and YouTube. Created by engineers and scientists from Spotify and Semrush, GoodListen is constantly improving through research and development in AI, Natural Language Processing, and audio processing.
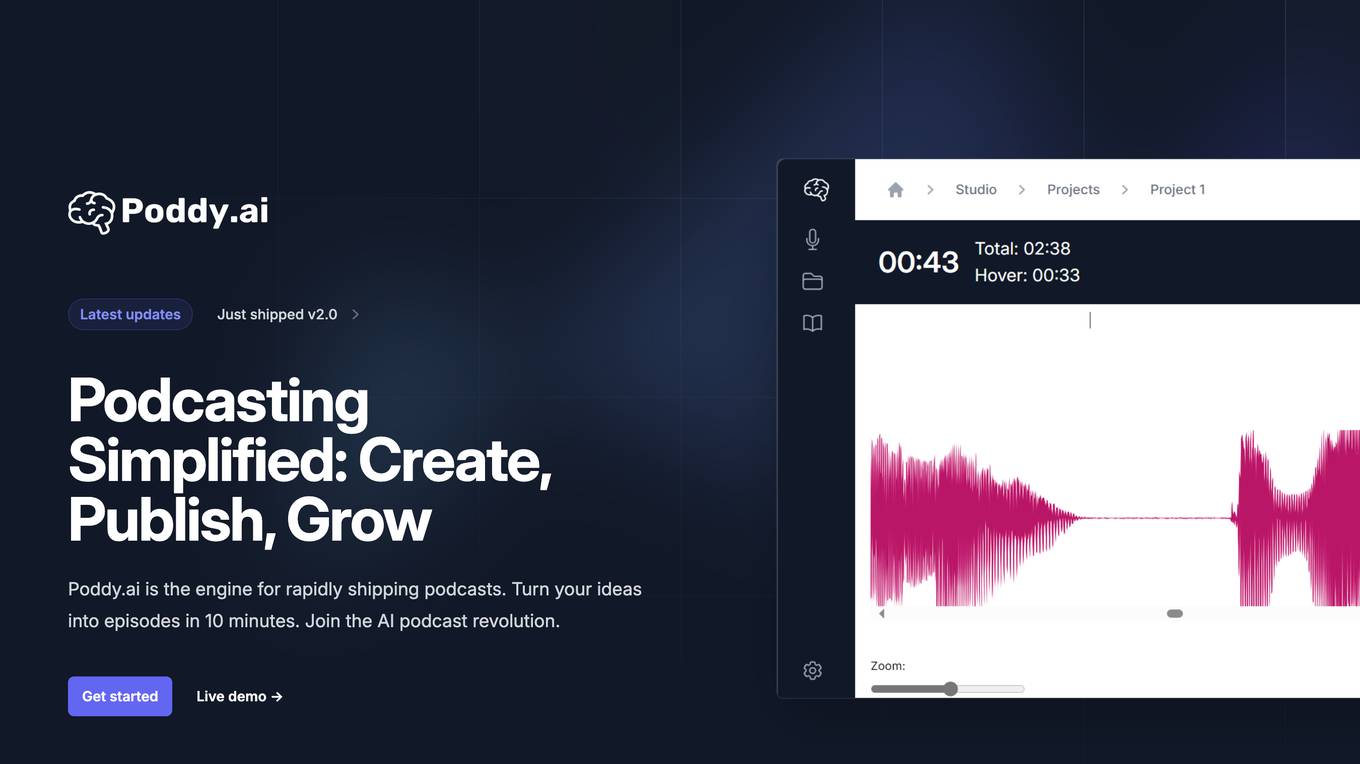
Poddy.ai
Poddy.ai is an AI-powered platform that simplifies podcasting by providing end-to-end solutions for creating, publishing, and growing podcasts. With features like automatic episode generation, podcast series creation, and AI voices, Poddy.ai offers a comprehensive toolkit for podcasters to bring their vision to life. The platform is completely free to use and ensures advanced security for podcast data.
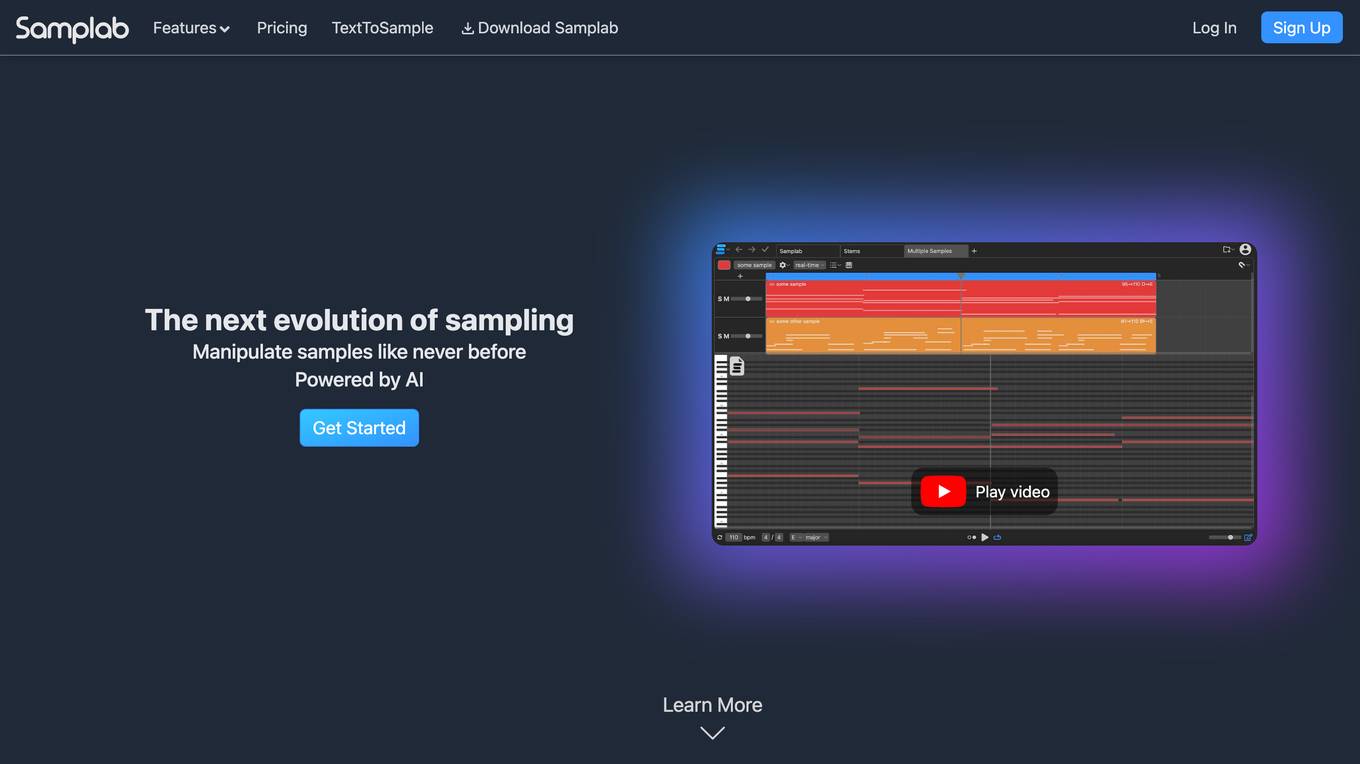
Samplab
Samplab is an AI-powered audio editing tool that allows users to manipulate audio samples with advanced features such as note editing, chord detection, stem separation, audio to MIDI conversion, and audio warping. It offers a seamless integration with digital audio workstations (DAWs) as a plugin or desktop app, enabling producers to enhance their music production workflow. Samplab's AI technology revolutionizes the way users interact with audio samples, providing unprecedented control over notes, chords, and melodies.
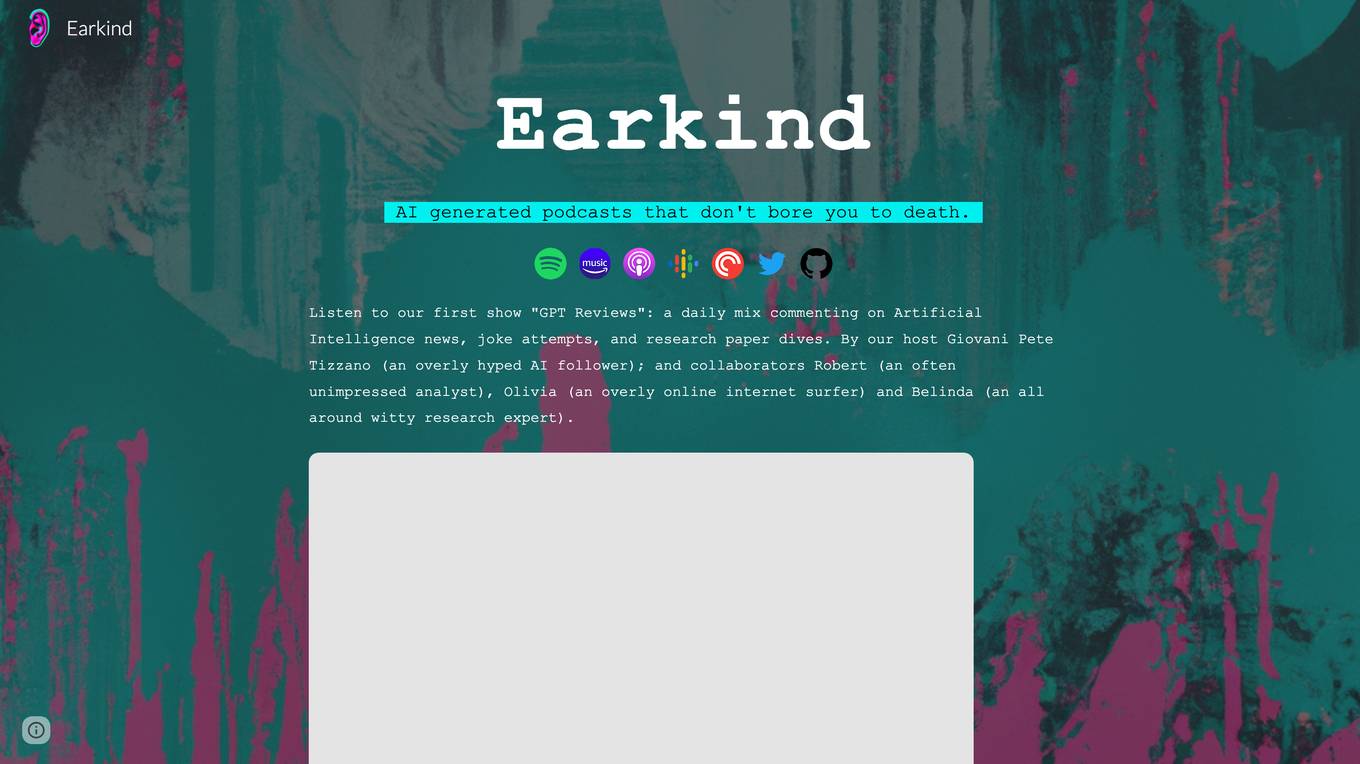
Earkind
Earkind is an AI-generated podcast platform that offers engaging and entertaining content by combining language models with neural expressive text-to-speech and programmatic audio editing. The platform creates full podcast episodes based on selected news and research papers, featuring lively discussions between fictional characters. Earkind aims to provide a fun and non-serious approach to Artificial Intelligence news and research, with a focus on personalized audio content.
HitPaw Online
HitPaw Online is a website that provides a suite of AI-powered editing tools for photos, videos, and audio. The tools are easy to use and can be accessed online without the need to install any software. HitPaw Online's tools are powered by advanced AI algorithms that can automatically enhance the quality of your media files. For example, the Photo Enhancer tool can improve the resolution of images, remove noise, and adjust the colors. The Video Enhancer tool can upscale videos to 4K resolution, remove watermarks, and add subtitles. The Audio Enhancer tool can reduce background noise, extract audio from videos, and convert audio formats.
Cleanvoice AI
Cleanvoice AI is an artificial intelligence that removes filler sounds, background noise, and mouth sounds from your podcast or audio recording. It can detect and remove filler sounds such as "um's", "ah's", etc. in multiple languages like German or French. The algorithm can also work with accents from other countries, such as Australian ones or Irish. Cleanvoice can also automatically enhance your audio by removing unwanted background noise, such as cafe noise, traffic sounds, white noise, or any other kind of background noise. Additionally, Cleanvoice can help you create podcast summaries and show notes, and it can even generate automated chapter markers so that listeners can skip to their favorite part.
Adobe Podcast
Adobe Podcast is an AI-powered audio recording and editing tool that allows users to create and edit podcasts entirely on the web. With Adobe Podcast, users can record high-quality audio, add music and sound effects, and edit their recordings with ease. Adobe Podcast also offers a variety of features to help users promote and distribute their podcasts.
Adobe Firefly
Adobe Firefly is a cloud-based AI platform that helps businesses automate and accelerate their creative processes. It provides a suite of tools for image editing, video editing, and audio editing, all powered by AI. With Firefly, businesses can save time and money on their creative projects, while also improving the quality of their work.
CyberLink
CyberLink is a leading provider of multimedia software, including video editing, photo editing, and media playback software. The company's products are used by consumers, businesses, and professionals around the world. CyberLink's mission is to provide innovative and easy-to-use software that helps people create and enjoy their own multimedia content.
Melody ML
Melody ML is an AI-powered music processing tool that allows users to separate music tracks using machine learning technology. Users can upload songs, and the tool uses AI algorithms to extract vocals, drums, bass, and other instruments into separate stems. Melody ML offers a user-friendly platform for music enthusiasts, producers, and artists to enhance their music production process.
Mp3Converter AI
Mp3Converter AI is an online audio converter tool powered by AI technology. It allows users to convert various audio formats such as WAV, FLAC, and AAC to MP3 effortlessly. The tool provides high-quality audio conversions quickly and efficiently, making it a versatile solution for all audio conversion needs. With a user-friendly interface and batch conversion feature, Mp3Converter AI ensures a seamless experience for converting music files to MP3 format.
PodBot
PodBot is an AI-powered platform that enables users to create podcasts automatically. By leveraging artificial intelligence technology, PodBot simplifies the podcast creation process, allowing users to generate high-quality content efficiently. The platform offers a user-friendly interface and a range of features to enhance the podcasting experience.
MVSEP - Music & Voice Separation
MVSEP is an AI-powered application that specializes in music and voice separation. It offers users the ability to separate audio files into voice and music parts using advanced algorithms and models. Users can easily upload files through drag and drop or remote upload features. The application provides various separation types, HQ models, and output encoding options to cater to different user needs. MVSEP aims to enhance the audio editing experience by providing high-quality results and a user-friendly interface.
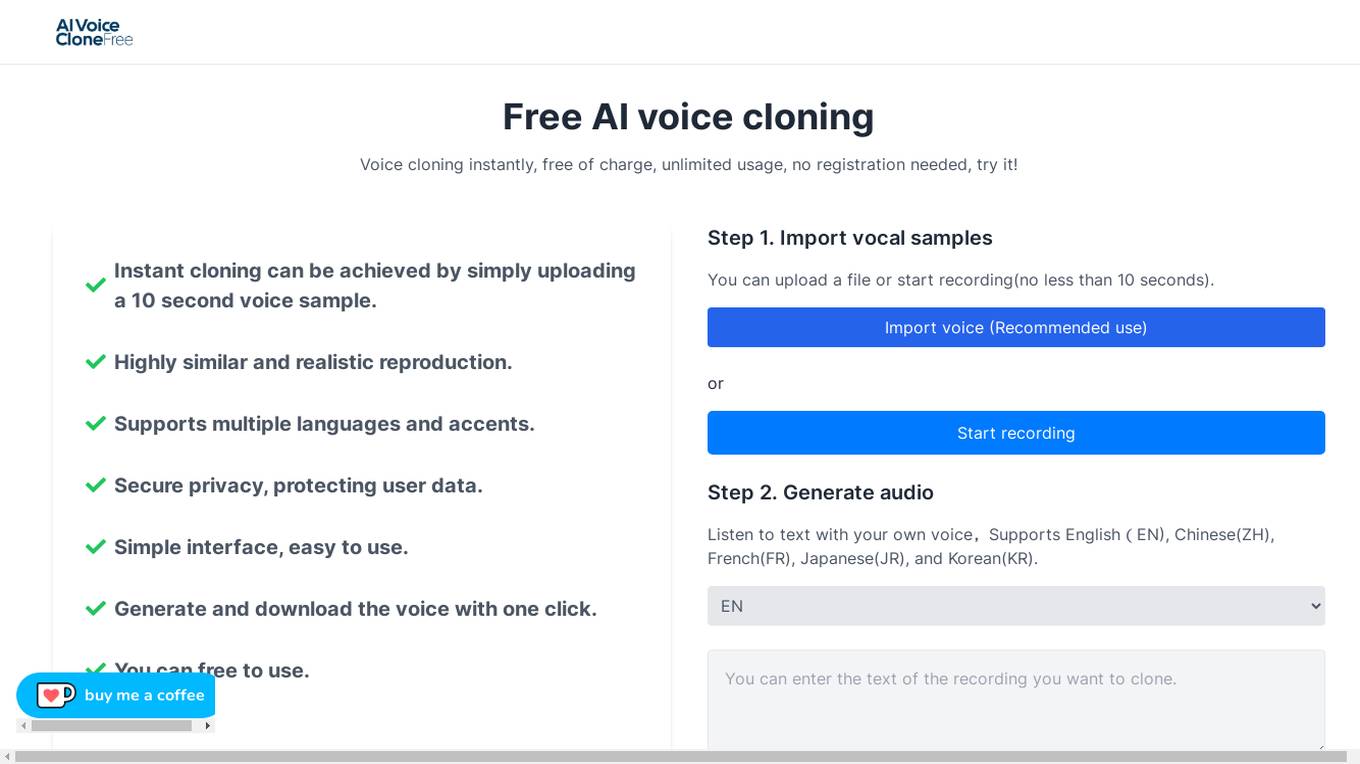
Woy AI Tools
Woy AI Tools is a free AI voice cloning application that allows users to instantly clone voices with high similarity and realism. Users can upload a 10-second voice sample to generate and download cloned voices in multiple languages and accents. The tool ensures secure privacy and offers a simple interface for easy usage.
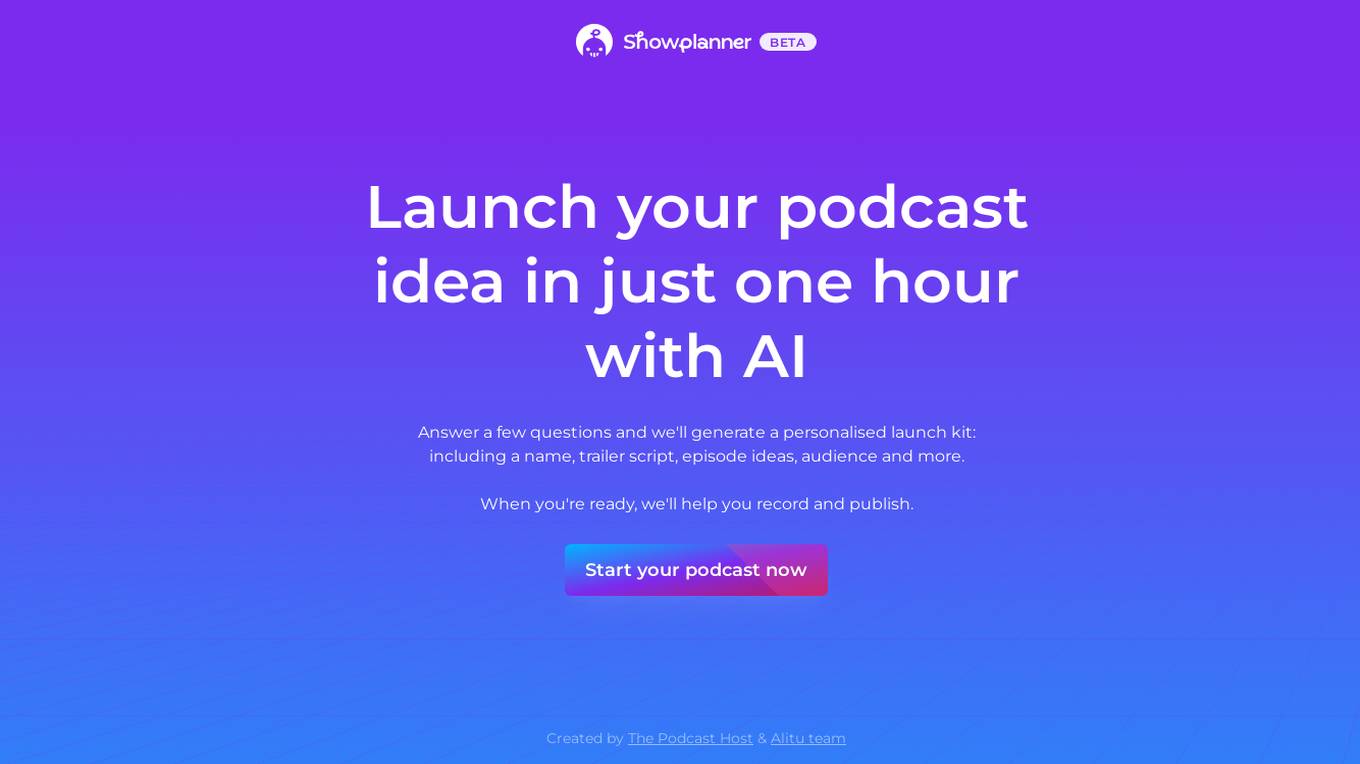
Alitu Showplanner
Alitu Showplanner is an AI-powered tool designed to help users launch their podcasts quickly and efficiently. By answering a few questions about their podcast idea, users can generate a personalized launch kit including a catchy name, trailer script, episode ideas, and more. The tool simplifies the podcast creation process by providing step-by-step guidance from planning to recording and publishing. Created by The Podcast Host & Alitu team, Alitu Showplanner aims to streamline the podcasting experience for beginners and experienced creators alike.
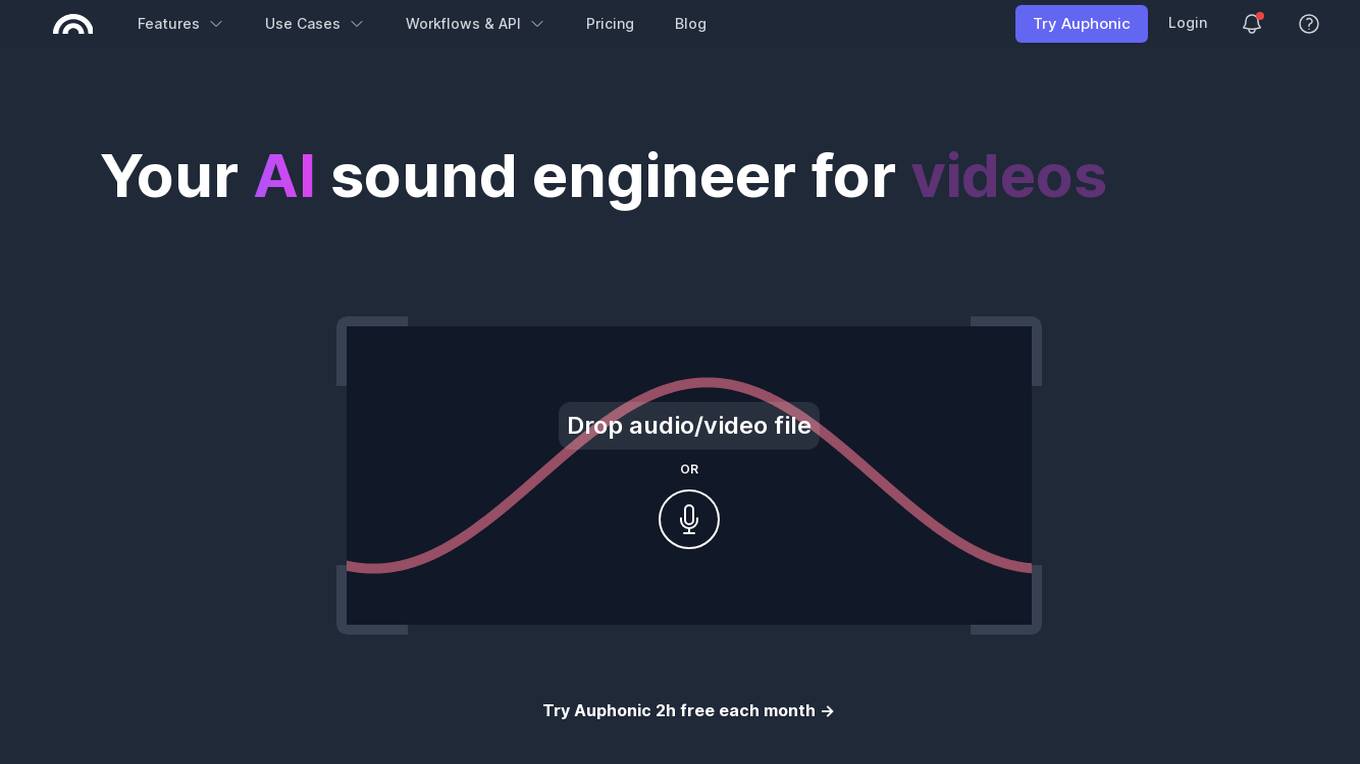
Auphonic
Auphonic is an AI-powered audio post-production web tool designed to help users achieve professional-quality audio results effortlessly. It offers a range of features such as Intelligent Leveler, Noise & Reverb Reduction, Filtering & AutoEQ, Cut Filler Words and Silence, Multitrack Algorithms, Loudness Specifications, Speech2Text & Automatic Shownotes, Video Support, Metadata & Chapters, and more. Auphonic is widely used by podcasters, educators, content creators, and audiobook producers to enhance their audio content and streamline their workflows. With its intuitive interface and advanced algorithms, Auphonic simplifies the audio editing process and ensures consistent audio quality across different platforms.
Pozotron Studio
Pozotron Studio is an AI-powered software suite designed to simplify scripted audio production processes for audiobooks, voiceovers, and other audio projects. It leverages state-of-the-art technology to enhance efficiency and accuracy in audio production, while allowing users to focus on creativity and core features. The tool automates tasks such as generating DAW marker files, pronunciation research, and script preparation, providing peace of mind about accuracy and highlighting errors for easy correction.

Moises
Moises is an AI-powered musician's app that allows users to remove vocals and instruments from any song. With Moises, musicians and music enthusiasts can isolate specific elements of a track for learning, remixing, or practicing purposes. The app utilizes advanced AI algorithms to provide high-quality audio separation, making it a valuable tool for music production and analysis. Moises offers a user-friendly interface and intuitive controls, making it accessible to both beginners and professionals in the music industry.
5 - Open Source Tools

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
podscript
Podscript is a tool designed to generate transcripts for podcasts and similar audio files using Language Model Models (LLMs) and Speech-to-Text (STT) APIs. It provides a command-line interface (CLI) for transcribing audio from various sources, including YouTube videos and audio files, using different speech-to-text services like Deepgram, Assembly AI, and Groq. Additionally, Podscript offers a web-based user interface for convenience. Users can configure keys for supported services, transcribe audio, and customize the transcription models. The tool aims to simplify the process of creating accurate transcripts for audio content.
20 - OpenAI Gpts



All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.

ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.
ConvertAnything
The ultimate tool for converting files, whether they are images, audio, video, documents, or other types. It can process single files or multiple files in bulk, accepts ZIP files, and offers a download link [Updated version].
AI Tools Navigator Genie
Your ultimate guide for navigating AI tools in fields like video, audio, writing, from beginner to expert.
ArtGPT
Doing art design and research, including fine arts, audio arts and video arts, designed by Prof. Dr. Fred Y. Ye (Ying Ye)