
scrape-it-now
Web scraper made for AI and simplicity in mind. It runs as a CLI that can be parallelized and outputs high-quality markdown content.
Stars: 452
Scrape It Now is a versatile tool for scraping websites with features like decoupled architecture, CLI functionality, idempotent operations, and content storage options. The tool includes a scraper component for efficient scraping, ad blocking, link detection, markdown extraction, dynamic content loading, and anonymity features. It also offers an indexer component for creating AI search indexes, chunking content, embedding chunks, and enabling semantic search. The tool supports various configurations for Azure services and local storage, providing flexibility and scalability for web scraping and indexing tasks.
README:
A website to scrape? There's a simple way.


Shared:
- [x] Decoupled architecture with Azure Queue Storage or local sqlite
- [x] Executable as a CLI with a standalone binary
- [x] Idenpotent operations that can be run in parallel
- [x] Scraped content is stored in Azure Blob Storage or local disk
Scraper:
- [x] Avoid re-scrape a page if it hasn't changed
- [x] Block ads to lower network costs with The Block List Project
- [x] Explore pages in depth by detecting links and de-duplicating them
- [x] Extract markdown content from a page with Pandoc
- [x] Load dynamic JavaScript content with Playwright
- [x] Preserve anonymity with a random user agent, random viewport size and no client hints headers
- [x] Show progress with a status command
- [x] Track progress of total network usage
- [ ] Enhance anonymity with proxies
- [ ] Respect
robots.txt
Indexer:
- [x] AI Search index is created automatically
- [x] Chunk markdown while keeping the content coherent
- [x] Embed chunks with OpenAI embeddings
- [x] Indexed content is semantically searchable with Azure AI Search
Download the latest release from the releases page. Binaries are available for Linux, macOS and Windows.
For configuring the CLI (including authentication to the backend services), use environment variables, a .env file or command line options.
Application must be run with Python 3.12 or later. If this version is not installed, an easy way to install it is pyenv.
# Download the source code
git clone https://github.com/clemlesne/scrape-it-now.git
# Move to the directory
cd scrape-it-now
# Run install scripts
make install dev
# Run the CLI
scrape-it-now --helpUsage with Azure Blob Storage and Azure Queue Storage:
# Azure Storage configuration
export AZURE_STORAGE_CONNECTION_STRING=xxx
# Run the job
scrape-it-now scrape run https://nytimes.comUsage with Local Disk Blob and Local Disk Queue:
# Local disk configuration
export BLOB_PROVIDER=local_disk
export QUEUE_PROVIDER=local_disk
# Run the job
scrape-it-now scrape run https://nytimes.comExample output:
❯ Start scraping job 7yz91ma
Queued 71/71 links for referrer https://www.google.com/search (1)
3 workers started
Browser chromium launched
...
Queued 15/28 links for referrer https://www.nytimes.com/2024/08/15/business/economy/kamala-harris-inflation-price-gouging.html (2)
Scraped https://www.nytimes.com/2024/08/15/business/economy/kamala-harris-inflation-price-gouging.html (2)Most frequent options are:
Options |
Description | Environment variable |
|---|---|---|
--azure-storage-connection-string-ascs
|
Azure Storage connection string | AZURE_STORAGE_CONNECTION_STRING |
--blob-provider-bp
|
Blob provider | BLOB_PROVIDER |
--job-name-jn
|
Job name | JOB_NAME |
--max-depth-md
|
Maximum depth | MAX_DEPTH |
--queue-provider-qp
|
Queue provider | QUEUE_PROVIDER |
--whitelist-w
|
Whitelist | WHITELIST |
For documentation on all available options, run:
scrape-it-now scrape run --helpUsage with Azure Blob Storage:
# Azure Storage configuration
export AZURE_STORAGE_CONNECTION_STRING=xxx
# Show the job status
scrape-it-now scrape status [job_name]Usage with Local Disk Blob:
# Local disk configuration
export BLOB_PROVIDER=local_disk
# Show the job status
scrape-it-now scrape status [job_name]Example output:
❯ {"created_at":"2024-08-16T15:33:06.602922Z","last_updated":"2024-08-16T16:17:51.571136Z","network_used_mb":5.650620460510254,"processed":1263,"queued":3120}Most frequent options are:
Options |
Description | Environment variable |
|---|---|---|
--azure-storage-connection-string-ascs
|
Azure Storage connection string | AZURE_STORAGE_CONNECTION_STRING |
--blob-provider-bp
|
Blob provider | BLOB_PROVIDER |
For documentation on all available options, run:
scrape-it-now scrape status --helpUsage with Azure Blob Storage, Azure Queue Storage and Azure AI Search:
# Azure OpenAI configuration
export AZURE_OPENAI_API_KEY=xxx
export AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME=xxx
export AZURE_OPENAI_EMBEDDING_DIMENSIONS=xxx
export AZURE_OPENAI_EMBEDDING_MODEL_NAME=xxx
export AZURE_OPENAI_ENDPOINT=xxx
# Azure Search configuration
export AZURE_SEARCH_API_KEY=xxx
export AZURE_SEARCH_ENDPOINT=xxx
# Azure Storage configuration
export AZURE_STORAGE_CONNECTION_STRING=xxx
# Run the job
scrape-it-now index run [job_name]Usage with Local Disk Blob, Local Disk Queue and Azure AI Search:
# Azure OpenAI configuration
export AZURE_OPENAI_API_KEY=xxx
export AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME=xxx
export AZURE_OPENAI_EMBEDDING_DIMENSIONS=xxx
export AZURE_OPENAI_EMBEDDING_MODEL_NAME=xxx
export AZURE_OPENAI_ENDPOINT=xxx
# Azure Search configuration
export AZURE_SEARCH_API_KEY=xxx
export AZURE_SEARCH_ENDPOINT=xxx
# Local disk configuration
export BLOB_PROVIDER=local_disk
export QUEUE_PROVIDER=local_disk
# Run the job
scrape-it-now index run [job_name]Example output:
❯ Start indexing job 7yz91ma
5 workers started
...
434b227 chunked into 6 parts
434b227 is indexed
f001b3e chunked into 86 parts
f001b3e is already indexedMost frequent options are:
Options |
Description | Environment variable |
|---|---|---|
--azure-openai-api-key-aoak
|
Azure OpenAI API key | AZURE_OPENAI_API_KEY |
--azure-openai-embedding-deployment-name-aoedn
|
Azure OpenAI embedding deployment name | AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME |
--azure-openai-embedding-dimensions-aoed
|
Azure OpenAI embedding dimensions | AZURE_OPENAI_EMBEDDING_DIMENSIONS |
--azure-openai-embedding-model-name-aoemn
|
Azure OpenAI embedding model name | AZURE_OPENAI_EMBEDDING_MODEL_NAME |
--azure-openai-endpoint-aoe
|
Azure OpenAI endpoint | AZURE_OPENAI_ENDPOINT |
--azure-search-api-key-asak
|
Azure Search API key | AZURE_SEARCH_API_KEY |
--azure-search-endpoint-ase
|
Azure Search endpoint | AZURE_SEARCH_ENDPOINT |
--azure-storage-connection-string-ascs
|
Azure Storage connection string | AZURE_STORAGE_CONNECTION_STRING |
--blob-provider-bp
|
Blob provider | BLOB_PROVIDER |
--queue-provider-qp
|
Queue provider | QUEUE_PROVIDER |
For documentation on all available options, run:
scrape-it-now index run --help---
title: Scrape process with Azure Storage
---
graph LR
cli["CLI"]
web["Website"]
subgraph "Azure Queue Storage"
to_chunk["To chunk"]
to_scrape["To scrape"]
end
subgraph "Azure Blob Storage"
subgraph "Container"
job["job"]
scraped["scraped"]
state["state"]
end
end
cli -- 1. Pull message --> to_scrape
cli -- 2. Get cache --> scraped
cli -- 3. Browse --> web
cli -- 4. Update cache --> scraped
cli -- 5. Push state --> state
cli -- 6. Add message --> to_scrape
cli -- 7. Add message --> to_chunk
cli -- 8. Update state --> job---
title: Scrape process with Azure Storage and Azure AI Search
---
graph LR
search["Azure AI Search"]
cli["CLI"]
embeddings["Azure OpenAI Embeddings"]
subgraph "Azure Queue Storage"
to_chunk["To chunk"]
end
subgraph "Azure Blob Storage"
subgraph "Container"
scraped["scraped"]
end
end
cli -- 1. Pull message --> to_chunk
cli -- 2. Get cache --> scraped
cli -- 3. Chunk --> cli
cli -- 4. Embed --> embeddings
cli -- 5. Push to search --> searchTo configure easily the CLI, source environment variables from a .env file. For example, for the --azure-storage-connection-string option:
AZURE_STORAGE_CONNECTION_STRING=xxxFor arguments that accept multiple values, use a space-separated list. For example, for the --whitelist option:
WHITELIST=learn\.microsoft\.com,^/(?!en-us).*,^/[^/]+/answers/,^/[^/]+/previous-versions/ go\.microsoft\.com,.*The cache directoty depends on the operating system:
-
~/.config/scrape-it-now(Unix) -
~/Library/Application Support/scrape-it-now(macOS) -
C:\Users\<user>\AppData\Roaming\scrape-it-now(Windows)
Browser binaries are automatically downloaded or updated at each run. Browser is Chromium and it is not configurable (feel free to open an issue if you need another browser), it weights around 450MB. Cache is stored in the cache directory.
Local Disk storage is used for both blob and queue. It is not recommended for production use, as it is not scalable, not fault-tolerant and not parallelizable.
Local Disk Blob uses a directory structure to store blobs. Each blob is stored in a file with the blob name as the file name. Lease is implemented with lock files. By default, files are stored in a directory relative to the command execution directory.
Local Disk Queue uses a SQLite database to store messages. Database is stored in the cache directory. SQL databases implement visibility timeout and deletion tokens to ensure consistency to the stateless queue services like Azure Queue Storage.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for scrape-it-now
Similar Open Source Tools
scrape-it-now
Scrape It Now is a versatile tool for scraping websites with features like decoupled architecture, CLI functionality, idempotent operations, and content storage options. The tool includes a scraper component for efficient scraping, ad blocking, link detection, markdown extraction, dynamic content loading, and anonymity features. It also offers an indexer component for creating AI search indexes, chunking content, embedding chunks, and enabling semantic search. The tool supports various configurations for Azure services and local storage, providing flexibility and scalability for web scraping and indexing tasks.
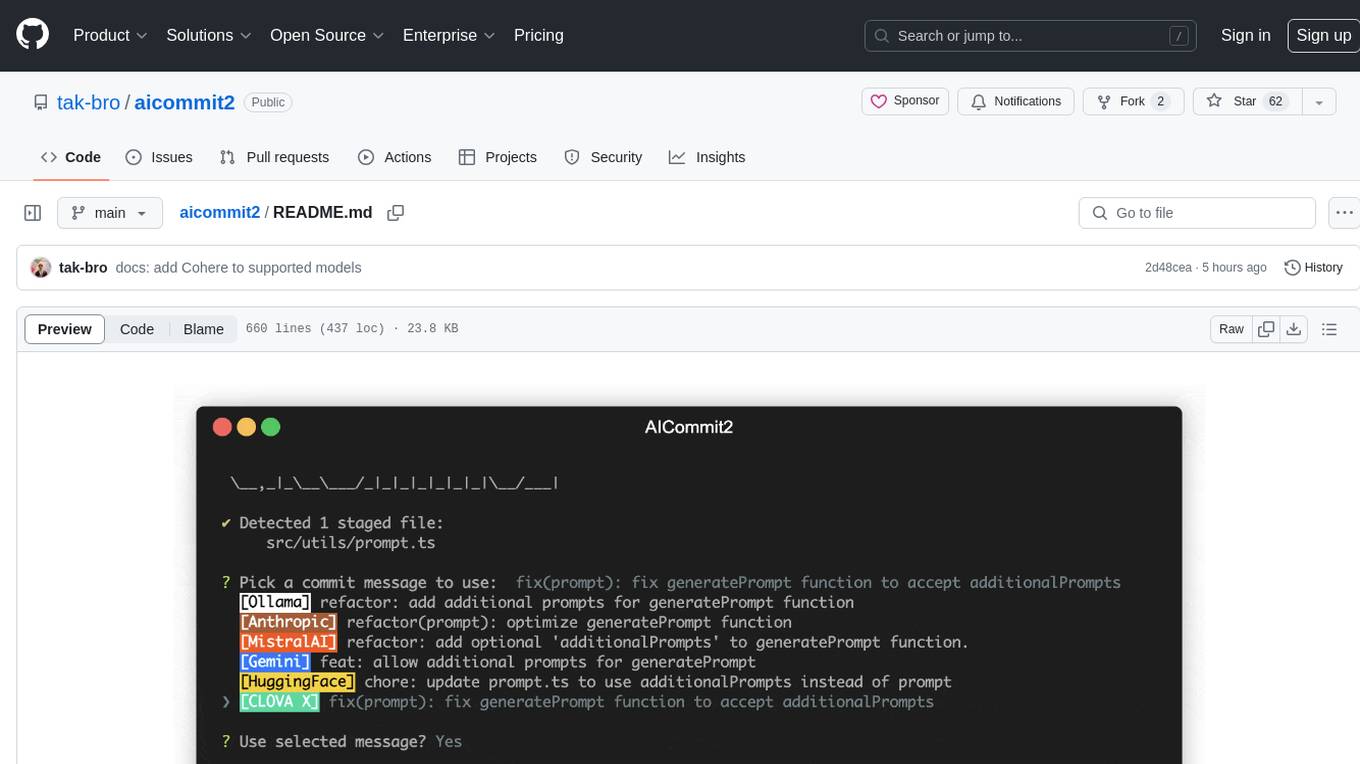
aicommit2
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.
stable-diffusion-webui
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.
openmcp-client
OpenMCP is an integrated plugin for MCP server debugging in vscode/trae/cursor, combining development and testing functionalities. It includes tools for testing MCP resources, managing large model interactions, project-level management, and supports multiple large models. The openmcp-sdk allows for deploying MCP as an agent app with easy configuration and execution of tasks. The project follows a modular design allowing implementation in different modes on various platforms.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students
x-hiring
X-Hiring is a job search tool that uses Google AI to extract summaries of the latest job postings. It is easy to install and run, and can be used to find jobs in a variety of fields. X-Hiring is also open source, so you can contribute to its development or create your own custom version.
listen
Listen is a Solana Swiss-Knife toolkit for algorithmic trading, offering real-time transaction monitoring, multi-DEX swap execution, fast transactions with Jito MEV bundles, price tracking, token management utilities, and performance monitoring. It includes tools for grabbing data from unofficial APIs and works with the $arc rig framework for AI Agents to interact with the Solana blockchain. The repository provides miscellaneous tools for analysis and data retrieval, with the core functionality in the `src` directory.

TalkWithGemini
Talk With Gemini is a web application that allows users to deploy their private Gemini application for free with one click. It supports Gemini Pro and Gemini Pro Vision models. The application features talk mode for direct communication with Gemini, visual recognition for understanding picture content, full Markdown support, automatic compression of chat records, privacy and security with local data storage, well-designed UI with responsive design, fast loading speed, and multi-language support. The tool is designed to be user-friendly and versatile for various deployment options and language preferences.

r2ai
r2ai is a tool designed to run a language model locally without internet access. It can be used to entertain users or assist in answering questions related to radare2 or reverse engineering. The tool allows users to prompt the language model, index large codebases, slurp file contents, embed the output of an r2 command, define different system-level assistant roles, set environment variables, and more. It is accessible as an r2lang-python plugin and can be scripted from various languages. Users can use different models, adjust query templates dynamically, load multiple models, and make them communicate with each other.
pr-pilot
PR Pilot is an AI-powered tool designed to assist users in their daily workflow by delegating routine work to AI with confidence and predictability. It integrates seamlessly with popular development tools and allows users to interact with it through a Command-Line Interface, Python SDK, REST API, and Smart Workflows. Users can automate tasks such as generating PR titles and descriptions, summarizing and posting issues, and formatting README files. The tool aims to save time and enhance productivity by providing AI-powered solutions for common development tasks.
ai-elements
AI Elements is a component library built on top of shadcn/ui to help build AI-native applications faster. It provides pre-built, customizable React components specifically designed for AI applications, including conversations, messages, code blocks, reasoning displays, and more. The CLI makes it easy to add these components to your Next.js project.
vicinity
Vicinity is a lightweight, low-dependency vector store that provides a unified interface for nearest neighbor search with support for different backends and evaluation. It simplifies the process of comparing and evaluating different nearest neighbors packages by offering a simple and intuitive API. Users can easily experiment with various indexing methods and distance metrics to choose the best one for their use case. Vicinity also allows for measuring performance metrics like queries per second and recall.
ruby-nano-bots
Ruby Nano Bots is an implementation of the Nano Bots specification supporting various AI providers like Cohere Command, Google Gemini, Maritaca AI MariTalk, Mistral AI, Ollama, OpenAI ChatGPT, and others. It allows calling tools (functions) and provides a helpful assistant for interacting with AI language models. The tool can be used both from the command line and as a library in Ruby projects, offering features like REPL, debugging, and encryption for data privacy.
ruler
Ruler is a tool designed to centralize AI coding assistant instructions, providing a single source of truth for managing instructions across multiple AI coding tools. It helps in avoiding inconsistent guidance, duplicated effort, context drift, onboarding friction, and complex project structures by automatically distributing instructions to the right configuration files. With support for nested rule loading, Ruler can handle complex project structures with context-specific instructions for different components. It offers features like centralised rule management, nested rule loading, automatic distribution, targeted agent configuration, MCP server propagation, .gitignore automation, and a simple CLI for easy configuration management.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.

nano-graphrag
nano-GraphRAG is a simple, easy-to-hack implementation of GraphRAG that provides a smaller, faster, and cleaner version of the official implementation. It is about 800 lines of code, small yet scalable, asynchronous, and fully typed. The tool supports incremental insert, async methods, and various parameters for customization. Users can replace storage components and LLM functions as needed. It also allows for embedding function replacement and comes with pre-defined prompts for entity extraction and community reports. However, some features like covariates and global search implementation differ from the original GraphRAG. Future versions aim to address issues related to data source ID, community description truncation, and add new components.
For similar tasks
scrape-it-now
Scrape It Now is a versatile tool for scraping websites with features like decoupled architecture, CLI functionality, idempotent operations, and content storage options. The tool includes a scraper component for efficient scraping, ad blocking, link detection, markdown extraction, dynamic content loading, and anonymity features. It also offers an indexer component for creating AI search indexes, chunking content, embedding chunks, and enabling semantic search. The tool supports various configurations for Azure services and local storage, providing flexibility and scalability for web scraping and indexing tasks.
500
Simple Config GeoIP for Quantumult X is a pre-configured file package containing rules for unlocking Apple News, ad blocking, TikTok unlock Rewrite, machine routing rules, and VIP video resolution rewriting. It integrates multiple rewrite configurations using Quantumult X and GeoIP features to remove most rules to save resources, and provides corresponding shortcuts for rule and configuration simplification through Vercel redirection.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.
AudioNotes
AudioNotes is a system built on FunASR and Qwen2 that can quickly extract content from audio and video, and organize it using large models into structured markdown notes for easy reading. Users can interact with the audio and video content, install Ollama, pull models, and deploy services using Docker or locally with a PostgreSQL database. The system provides a seamless way to convert audio and video into structured notes for efficient consumption.
dom-to-semantic-markdown
DOM to Semantic Markdown is a tool that converts HTML DOM to Semantic Markdown for use in Large Language Models (LLMs). It maximizes semantic information, token efficiency, and preserves metadata to enhance LLMs' processing capabilities. The tool captures rich web content structure, including semantic tags, image metadata, table structures, and link destinations. It offers customizable conversion options and supports both browser and Node.js environments.

open-deep-research
Open Deep Research is an open-source tool designed to generate AI-powered reports from web search results efficiently. It combines Bing Search API for search results retrieval, JinaAI for content extraction, and customizable report generation. Users can customize settings, export reports in multiple formats, and benefit from rate limiting for stability. The tool aims to streamline research and report creation in a user-friendly platform.

DevDocs
DevDocs is a platform designed to simplify the process of digesting technical documentation for software engineers and developers. It automates the extraction and conversion of web content into markdown format, making it easier for users to access and understand the information. By crawling through child pages of a given URL, DevDocs provides a streamlined approach to gathering relevant data and integrating it into various tools for software development. The tool aims to save time and effort by eliminating the need for manual research and content extraction, ultimately enhancing productivity and efficiency in the development process.
mcp-omnisearch
mcp-omnisearch is a Model Context Protocol (MCP) server that acts as a unified gateway to multiple search providers and AI tools. It integrates Tavily, Perplexity, Kagi, Jina AI, Brave, Exa AI, and Firecrawl to offer a wide range of search, AI response, content processing, and enhancement features through a single interface. The server provides powerful search capabilities, AI response generation, content extraction, summarization, web scraping, structured data extraction, and more. It is designed to work flexibly with the API keys available, enabling users to activate only the providers they have keys for and easily add more as needed.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.