
private-ml-sdk
Run LLMs and agents on TEEs leveraging NVIDIA GPU TEE and Intel TDX technologies.
Stars: 80
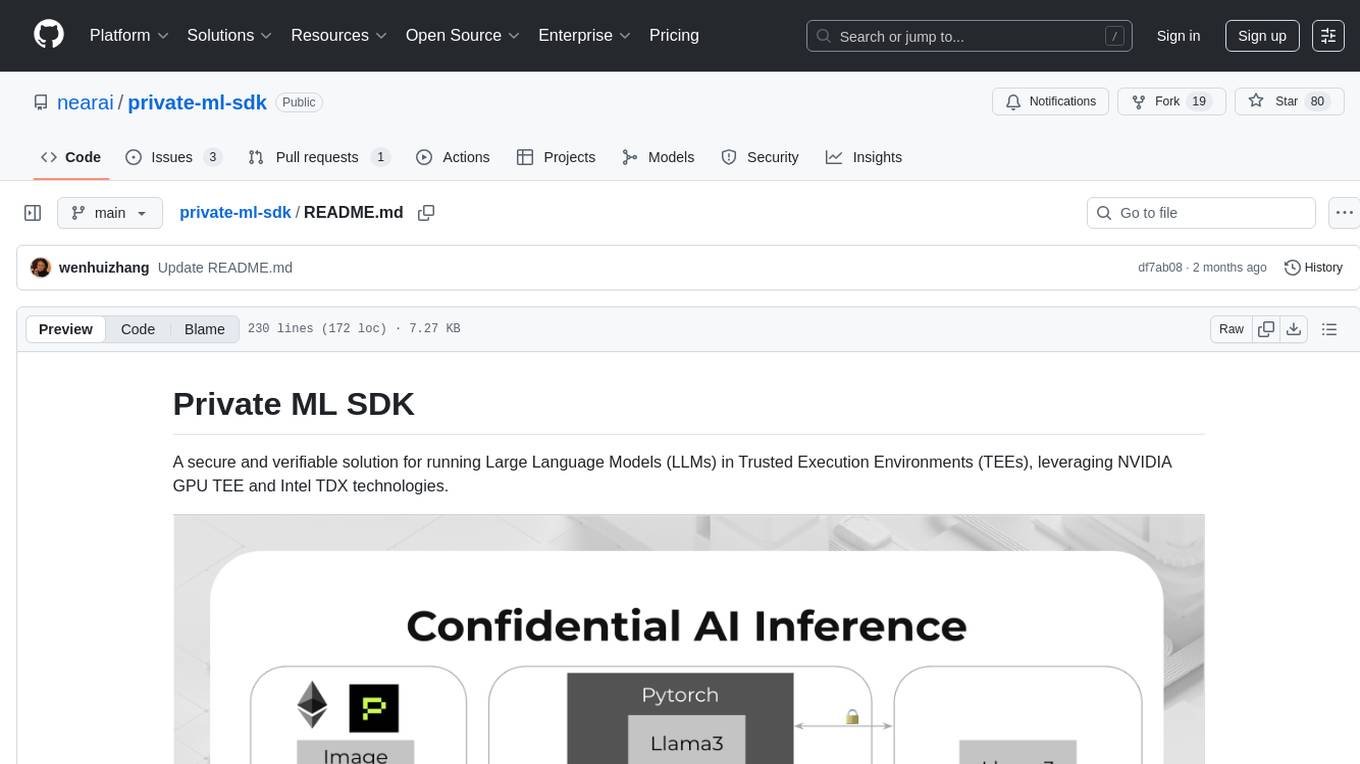
Private ML SDK is a secure solution for running Large Language Models (LLMs) in Trusted Execution Environments (TEEs) using NVIDIA GPU TEE and Intel TDX technologies. It provides a tamper-proof data processing environment with secure execution, open-source builds, and nearly native speed performance. The system includes components like Secure Compute Environment, Remote Attestation, Secure Communication, and Key Management Service (KMS). Users can build TDX guest images, run Local KMS, and TDX guest images on TDX host machines with Nvidia GPUs. The SDK offers verifiable execution results and high performance for LLM workloads.
README:
A secure and verifiable solution for running Large Language Models (LLMs) in Trusted Execution Environments (TEEs), leveraging NVIDIA GPU TEE and Intel TDX technologies.

Private ML SDK provides a secure environment for running LLM workloads with guaranteed privacy and security, preventing unauthorized access to both the model and user data during inference operations. The solution leverages NVIDIA's TEE GPU technology (H100/H200/B100) and Intel CPUs with TDX support to ensure that AI model execution and data processing remain fully protected within secure enclaves.
Key features:
- Tamper-proof data processing
- Secure execution environment
- Open source and reproducible builds
- Verifiable execution results
- Nearly native speed performance (up to 99% efficiency)
The system consists of several core components:
- Secure Compute Environment: TEE-based execution environment
- Remote Attestation: Verification of the TEE environment
- Secure Communication: End-to-end encryption between users and LLM
- Key Management Service (KMS): Key management service to manage keys for encryption and decryption
Prerequisites:
- Install Docker:
curl -fsSL https://get.docker.com -o get-docker.sh sudo sh get-docker.sh
- Add the current user to the docker group:
sudo usermod -aG docker $USER newgrp docker # Apply group changes without logout
- Verify Docker installation:
docker --version docker run hello-world
Clone the repository and build the TDX guest image:
git clone https://github.com/nearai/private-ml-sdk --recursive
cd private-ml-sdk/
./build.sh
If everything goes well, you should see the images files in private-ml-sdk/images/.
There are two image directories:
-
dstack-nvidia-0.5.3/: the production image without developer tools. -
dstack-nvidia-dev-0.5.3/: the development image with developer tools, such assshd,strace.
Before launching the CVM, ensure that the Local KMS is operational, as it provides the essential keys required for the proper initialization of the CVM. These keys are derived from the local TEE hardware environment.
The Local KMS service can be launched by following commands:
cd private-ml-sdk/meta-dstack-nvidia/dstack/key-provider-build/
./run.shThis requires a TDX host machine with the TDX driver installed and Nvidia GPU what support GPU TEE installed.
# Add the scripts/bin directory to the PATH environment variable
pushd private-ml-sdk/meta-dstack-nvidia/scripts/bin
PATH=$PATH:`pwd`
popd
# List the Available GPUs
dstack lsgpu
# Output like the following:
# Available GPU IDs:
# ID Description
# 18:00.0 3D controller: NVIDIA Corporation GH100 [H200 SXM 141GB] (rev a1)
# 2a:00.0 3D controller: NVIDIA Corporation GH100 [H200 SXM 141GB] (rev a1)
# 3a:00.0 3D controller: NVIDIA Corporation GH100 [H200 SXM 141GB] (rev a1)
# 5d:00.0 3D controller: NVIDIA Corporation GH100 [H200 SXM 141GB] (rev a1)
# 9a:00.0 3D controller: NVIDIA Corporation GH100 [H200 SXM 141GB] (rev a1)
# ab:00.0 3D controller: NVIDIA Corporation GH100 [H200 SXM 141GB] (rev a1)
# ba:00.0 3D controller: NVIDIA Corporation GH100 [H200 SXM 141GB] (rev a1)
# db:00.0 3D controller: NVIDIA Corporation GH100 [H200 SXM 141GB] (rev a1)
# Choose one or more GPU IDs and run the following command to create a CVM instance
dstack new app.yaml -o my-gpu-cvm \
--local-key-provider \
--gpu 18:00.0 \
--image images/dstack-nvidia-dev-0.5.3 \
-c 2 -m 4G -d 100G \
--port tcp:127.0.0.1:10022:22 \
--port tcp:0.0.0.0:8888:8888
# Run the CVM:
sudo -E dstack run my-gpu-cvm
An example of the app.yaml file is as follows:
# app.yaml
services:
jupyter:
image: kvin/cuda-notebook
privileged: true
ports:
- "8888:8888"
volumes:
- /var/run/tappd.sock:/var/run/tappd.sock
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
runtime: nvidia-
SSH into the CVM Note: SSH access is only available when using the development image
images/dstack-nvidia-dev-*.Execute the following command to establish an SSH connection:
ssh -p 10022 root@localhost
Note: Port 10022 is mapped to the CVM's port 22 during the creation of the CVM.
After logging in, check the status of the Docker Compose services by running:
docker ps -a
-
Verify the Jupyter Service Status To confirm that the Docker Compose services are running correctly, access the Jupyter service through your web browser:
-
For local access, navigate to: http://localhost:8888 (Port 8888 is mapped to the CVM's port 8888 during the creation of the CVM.)
-
For remote access, use the following URL: http://:8888 (Replace
<public-ip>with the actual public IP address of your CVM.)
-
To update the environment variables for the TDX CVM, execute the following command:
cp env-file <your-cvm-path>/shared/env-fileThe env-file is a text file that contains the necessary environment variables for the Docker Compose services. An example of the contents of the env-file is as follows:
# env-file
REDPILL_API_KEY=sk-1234567890
REDPILL_MODEL=phala/llama-3.3-70b-instruct
After copying the env-file, restart the CVM. The environment variables specified in the env-file will be accessible within the Docker Compose service YAML. During the boot process, this env-file is copied to the /tapp/env-file directory within the CVM.
For instance, in your docker-compose.yaml, you can reference the env-file as shown below:
# docker-compose.yaml, using the Jupyter service as an example
services:
jupyter:
env_file:
- /tapp/env-fileThis approach ensures that your environment variables are properly configured and accessible to your services.
- Install the SDK package:
pip install dstack-sdk- Get TDX quote using Python:
from dstack_sdk import TappdClient
# Initialize the client
client = TappdClient()
# Get quote for a message
result = client.tdx_quote('test')
print(result.quote)Based on benchmarks running LLMs in NVIDIA H100 and H200:
- Efficiency approaches 99% as input size grows
- Minimal overhead for larger models (e.g., Phi3-14B-128k and Llama3.1-70B)
- Performance scales well with increased input sizes and model complexities
- I/O overhead becomes negligible in high-computation scenarios
This project is licensed under the MIT License - see the LICENSE file for details.
Contributions are welcome! Please feel free to submit a Pull Request.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for private-ml-sdk
Similar Open Source Tools
private-ml-sdk
Private ML SDK is a secure solution for running Large Language Models (LLMs) in Trusted Execution Environments (TEEs) using NVIDIA GPU TEE and Intel TDX technologies. It provides a tamper-proof data processing environment with secure execution, open-source builds, and nearly native speed performance. The system includes components like Secure Compute Environment, Remote Attestation, Secure Communication, and Key Management Service (KMS). Users can build TDX guest images, run Local KMS, and TDX guest images on TDX host machines with Nvidia GPUs. The SDK offers verifiable execution results and high performance for LLM workloads.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.
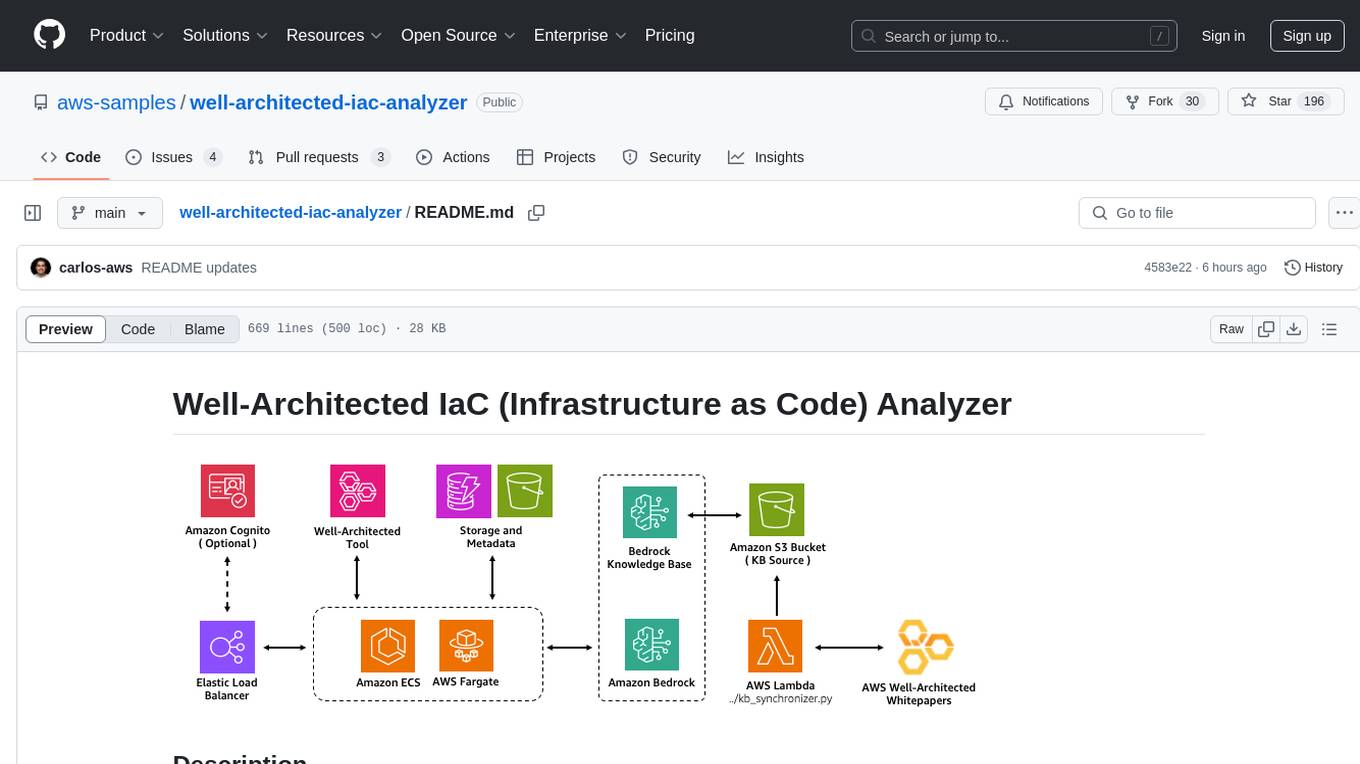
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
mcpd
mcpd is a tool developed by Mozilla AI to declaratively manage Model Context Protocol (MCP) servers, enabling consistent interface for defining and running tools across different environments. It bridges the gap between local development and enterprise deployment by providing secure secrets management, declarative configuration, and seamless environment promotion. mcpd simplifies the developer experience by offering zero-config tool setup, language-agnostic tooling, version-controlled configuration files, enterprise-ready secrets management, and smooth transition from local to production environments.
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
tgpt
tgpt is a cross-platform command-line interface (CLI) tool that allows users to interact with AI chatbots in the Terminal without needing API keys. It supports various AI providers such as KoboldAI, Phind, Llama2, Blackbox AI, and OpenAI. Users can generate text, code, and images using different flags and options. The tool can be installed on GNU/Linux, MacOS, FreeBSD, and Windows systems. It also supports proxy configurations and provides options for updating and uninstalling the tool.
sandvault
SandVault is a tool that manages a limited user account to sandbox shell commands and AI agents on macOS, providing a lightweight alternative to application isolation using virtual machines. It allows for running Claude Code, OpenAI Codex, Google Gemini, and shell commands safely within a sandboxed environment. SandVault offers features like fast context switching, passwordless account switching, shared workspace access, and clean uninstallation. The tool operates with limited access to the user's computer, ensuring security by restricting access to certain directories and system files.

mcpm.sh
MCPM is an open source CLI tool for managing MCP servers, providing a simplified global configuration approach to install servers once, organize them with profiles, and integrate them into any MCP client. Features include server discovery, direct execution, sharing capabilities, and client integration tools. It eliminates the complexity of v1's target-based system in favor of a clean global workspace model. The tool is designed to be AI agent friendly with comprehensive automation support and a rich CLI interface.
Notate
Notate is a powerful desktop research assistant that combines AI-driven analysis with advanced vector search technology. It streamlines research workflow by processing, organizing, and retrieving information from documents, audio, and text. Notate offers flexible AI capabilities with support for various LLM providers and local models, ensuring data privacy. Built for researchers, academics, and knowledge workers, it features real-time collaboration, accessible UI, and cross-platform compatibility.
shinkai-apps
Shinkai apps unlock the full capabilities/automation of first-class LLM (AI) support in the web browser. It enables creating multiple agents, each connected to either local or 3rd-party LLMs (ex. OpenAI GPT), which have permissioned (meaning secure) access to act in every webpage you visit. There is a companion repo called Shinkai Node, that allows you to set up the node anywhere as the central unit of the Shinkai Network, handling tasks such as agent management, job processing, and secure communications.
pastemax
PasteMax is a modern file viewer application designed for developers to easily navigate, search, and copy code from repositories. It provides features such as file tree navigation, token counting, search capabilities, selection management, sorting options, dark mode, binary file detection, and smart file exclusion. Built with Electron, React, and TypeScript, PasteMax is ideal for pasting code into ChatGPT or other language models. Users can download the application or build it from source, and customize file exclusions. Troubleshooting steps are provided for common issues, and contributions to the project are welcome under the MIT License.
backend.ai
Backend.AI is a streamlined, container-based computing cluster platform that hosts popular computing/ML frameworks and diverse programming languages, with pluggable heterogeneous accelerator support including CUDA GPU, ROCm GPU, TPU, IPU and other NPUs. It allocates and isolates the underlying computing resources for multi-tenant computation sessions on-demand or in batches with customizable job schedulers with its own orchestrator. All its functions are exposed as REST/GraphQL/WebSocket APIs.
RoboMatrix
RoboMatrix is a skill-centric hierarchical framework for scalable robot task planning and execution in an open-world environment. It provides a structured approach to robot task execution using a combination of hardware components, environment configuration, installation procedures, and data collection methods. The framework is developed using the ROS2 framework on Ubuntu and supports robots from DJI's RoboMaster series. Users can follow the provided installation guidance to set up RoboMatrix and utilize it for various tasks such as data collection, task execution, and dataset construction. The framework also includes a supervised fine-tuning dataset and aims to optimize communication and release additional components in the future.
exo
Run your own AI cluster at home with everyday devices. Exo is experimental software that unifies existing devices into a powerful GPU, supporting wide model compatibility, dynamic model partitioning, automatic device discovery, ChatGPT-compatible API, and device equality. It does not use a master-worker architecture, allowing devices to connect peer-to-peer. Exo supports different partitioning strategies like ring memory weighted partitioning. Installation is recommended from source. Documentation includes example usage on multiple MacOS devices and information on inference engines and networking modules. Known issues include the iOS implementation lagging behind Python.
For similar tasks
private-ml-sdk
Private ML SDK is a secure solution for running Large Language Models (LLMs) in Trusted Execution Environments (TEEs) using NVIDIA GPU TEE and Intel TDX technologies. It provides a tamper-proof data processing environment with secure execution, open-source builds, and nearly native speed performance. The system includes components like Secure Compute Environment, Remote Attestation, Secure Communication, and Key Management Service (KMS). Users can build TDX guest images, run Local KMS, and TDX guest images on TDX host machines with Nvidia GPUs. The SDK offers verifiable execution results and high performance for LLM workloads.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.