
openedai-speech
An OpenAI API compatible text to speech server using Coqui AI's xtts_v2 and/or piper tts as the backend.
Stars: 243

OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.
README:
An OpenAI API compatible text to speech server.
- Compatible with the OpenAI audio/speech API
- Serves the /v1/audio/speech endpoint
- Not affiliated with OpenAI in any way, does not require an OpenAI API Key
- A free, private, text-to-speech server with custom voice cloning
Full Compatibility:
-
tts-1:alloy,echo,fable,onyx,nova, andshimmer(configurable) -
tts-1-hd:alloy,echo,fable,onyx,nova, andshimmer(configurable, uses OpenAI samples by default) - response_format:
mp3,opus,aac,flac,wavandpcm - speed 0.25-4.0 (and more)
Details:
- Model
tts-1via piper tts (very fast, runs on cpu)- You can map your own piper voices via the
voice_to_speaker.yamlconfiguration file
- You can map your own piper voices via the
- Model
tts-1-hdvia coqui-ai/TTS xtts_v2 voice cloning (fast, but requires around 4GB GPU VRAM)- Custom cloned voices can be used for tts-1-hd, See: Custom Voices Howto
- 🌐 Multilingual support with XTTS voices, the language is automatically detected if not set
- Custom fine-tuned XTTS model support
- Configurable generation parameters
- Streamed output while generating
- Occasionally, certain words or symbols may sound incorrect, you can fix them with regex via
pre_process_map.yaml - Tested with python 3.9-3.11, piper does not install on python 3.12 yet
If you find a better voice match for tts-1 or tts-1-hd, please let me know so I can update the defaults.
Version 0.18.2, 2024-08-16
- Fix docker building for amd64, refactor github actions again, free up more disk space
Version 0.18.1, 2024-08-15
- refactor github actions
Version 0.18.0, 2024-08-15
- Allow folders of wav samples in xtts. Samples will be combined, allowing for mixed voices and collections of small samples. Still limited to 30 seconds total. Thanks @nathanhere.
- Fix missing yaml requirement in -min image
- fix fr_FR-tom-medium and other 44khz piper voices (detect non-default sample rates)
- minor updates
Version 0.17.2, 2024-07-01
- fix -min image (re: langdetect)
Version 0.17.1, 2024-07-01
- fix ROCm (add langdetect to requirements-rocm.txt)
- Fix zh-cn for xtts
Version 0.17.0, 2024-07-01
- Automatic language detection, thanks @RodolfoCastanheira
Version 0.16.0, 2024-06-29
- Multi-client safe version. Audio generation is synchronized in a single process. The estimated 'realtime' factor of XTTS on a GPU is roughly 1/3, this means that multiple streams simultaneously, or
speedover 2, may experience audio underrun (delays or pauses in playback). This makes multiple clients possible and safe, but in practice 2 or 3 simultaneous streams is the maximum without audio underrun.
Version 0.15.1, 2024-06-27
- Remove deepspeed from requirements.txt, it's too complex for typical users. A more detailed deepspeed install document will be required.
Version 0.15.0, 2024-06-26
- Switch to coqui-tts (updated fork), updated simpler dependencies, torch 2.3, etc.
- Resolve cuda threading issues
Version 0.14.1, 2024-06-26
- Make deepspeed possible (
--use-deepspeed), but not enabled in pre-built docker images (too large). Requires the cuda-toolkit installed, see the Dockerfile comment for details
Version 0.14.0, 2024-06-26
- Added
response_format:wavandpcmsupport - Output streaming (while generating) for
tts-1andtts-1-hd - Enhanced generation parameters for xtts models (temperature, top_p, etc.)
- Idle unload timer (optional) - doesn't work perfectly yet
- Improved error handling
Version 0.13.0, 2024-06-25
- Added Custom fine-tuned XTTS model support
- Initial prebuilt arm64 image support (Apple M-series, Raspberry Pi - MPS is not supported in XTTS/torch), thanks @JakeStevenson, @hchasens
- Initial attempt at AMD GPU (ROCm 5.7) support
- Parler-tts support removed
- Move the *.default.yaml to the root folder
- Run the docker as a service by default (
restart: unless-stopped) - Added
audio_reader.pyfor streaming text input and reading long texts
Version 0.12.3, 2024-06-17
- Additional logging details for BadRequests (400)
Version 0.12.2, 2024-06-16
- Fix :min image requirements (numpy<2?)
Version 0.12.0, 2024-06-16
- Improved error handling and logging
- Restore the original alloy tts-1-hd voice by default, use alloy-alt for the old voice.
Version 0.11.0, 2024-05-29
- 🌐 Multilingual support (16 languages) with XTTS
- Remove high Unicode filtering from the default
config/pre_process_map.yaml - Update Docker build & app startup. thanks @justinh-rahb
- Fix: "Plan failed with a cudnnException"
- Remove piper cuda support
Version: 0.10.1, 2024-05-05
- Remove
runtime: nvidiafrom docker-compose.yml, this assumes nvidia/cuda compatible runtime is available by default. thanks @jmtatsch
Version: 0.10.0, 2024-04-27
- Pre-built & tested docker images, smaller docker images (8GB or 860MB)
- Better upgrades: reorganize config files under
config/, voice models undervoices/ -
Compatibility! If you customized your
voice_to_speaker.yamlorpre_process_map.yamlyou need to move them to theconfig/folder. - default listen host to 0.0.0.0
Version: 0.9.0, 2024-04-23
- Fix bug with yaml and loading UTF-8
- New sample text-to-speech application
say.py - Smaller docker base image
- Add beta parler-tts support (you can describe very basic features of the speaker voice), See: (https://www.text-description-to-speech.com/) for some examples of how to describe voices. Voices can be defined in the
voice_to_speaker.default.yaml. Two example parler-tts voices are included in thevoice_to_speaker.default.yamlfile.parler-ttsis experimental software and is kind of slow. The exact voice will be slightly different each generation but should be similar to the basic description.
...
Version: 0.7.3, 2024-03-20
- Allow different xtts versions per voice in
voice_to_speaker.yaml, ex. xtts_v2.0.2 - Quality: Fix xtts sample rate (24000 vs. 22050 for piper) and pops
Copy the sample.env to speech.env (customize if needed)
cp sample.env speech.envTTS_HOME=voices
HF_HOME=voices
#PRELOAD_MODEL=xtts
#PRELOAD_MODEL=xtts_v2.0.2
#EXTRA_ARGS=--log-level DEBUG --unload-timer 300
#USE_ROCM=1# install curl and ffmpeg
sudo apt install curl ffmpeg
# Create & activate a new virtual environment (optional but recommended)
python -m venv .venv
source .venv/bin/activate
# Install the Python requirements
# - use requirements-rocm.txt for AMD GPU (ROCm support)
# - use requirements-min.txt for piper only (CPU only)
pip install -U -r requirements.txt
# run the server
bash startup.shOn first run, the voice models will be downloaded automatically. This might take a while depending on your network connection.
docker compose updocker compose -f docker-compose.rocm.yml upXTTS only has CPU support here and will be very slow, you can use the Nvidia image for XTTS with CPU (slow), or use the piper only image (recommended)
For a minimal docker image with only piper support (<1GB vs. 8GB).
docker compose -f docker-compose.min.yml upusage: speech.py [-h] [--xtts_device XTTS_DEVICE] [--preload PRELOAD] [--unload-timer UNLOAD_TIMER] [--use-deepspeed] [--no-cache-speaker] [-P PORT] [-H HOST]
[-L {DEBUG,INFO,WARNING,ERROR,CRITICAL}]
OpenedAI Speech API Server
options:
-h, --help show this help message and exit
--xtts_device XTTS_DEVICE
Set the device for the xtts model. The special value of 'none' will use piper for all models. (default: cuda)
--preload PRELOAD Preload a model (Ex. 'xtts' or 'xtts_v2.0.2'). By default it's loaded on first use. (default: None)
--unload-timer UNLOAD_TIMER
Idle unload timer for the XTTS model in seconds, Ex. 900 for 15 minutes (default: None)
--use-deepspeed Use deepspeed with xtts (this option is unsupported) (default: False)
--no-cache-speaker Don't use the speaker wav embeddings cache (default: False)
-P PORT, --port PORT Server tcp port (default: 8000)
-H HOST, --host HOST Host to listen on, Ex. 0.0.0.0 (default: 0.0.0.0)
-L {DEBUG,INFO,WARNING,ERROR,CRITICAL}, --log-level {DEBUG,INFO,WARNING,ERROR,CRITICAL}
Set the log level (default: INFO)You can use it like this:
curl http://localhost:8000/v1/audio/speech -H "Content-Type: application/json" -d '{
"model": "tts-1",
"input": "The quick brown fox jumped over the lazy dog.",
"voice": "alloy",
"response_format": "mp3",
"speed": 1.0
}' > speech.mp3Or just like this:
curl -s http://localhost:8000/v1/audio/speech -H "Content-Type: application/json" -d '{
"input": "The quick brown fox jumped over the lazy dog."}' > speech.mp3Or like this example from the OpenAI Text to speech guide:
import openai
client = openai.OpenAI(
# This part is not needed if you set these environment variables before import openai
# export OPENAI_API_KEY=sk-11111111111
# export OPENAI_BASE_URL=http://localhost:8000/v1
api_key = "sk-111111111",
base_url = "http://localhost:8000/v1",
)
with client.audio.speech.with_streaming_response.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
) as response:
response.stream_to_file("speech.mp3")Also see the say.py sample application for an example of how to use the openai-python API.
# play the audio, requires 'pip install playsound'
python say.py -t "The quick brown fox jumped over the lazy dog." -p
# save to a file in flac format
python say.py -t "The quick brown fox jumped over the lazy dog." -m tts-1-hd -v onyx -f flac -o fox.flacYou can also try the included audio_reader.py for listening to longer text and streamed input.
Example usage:
python audio_reader.py -s 2 < LICENSE # read the software license - fast- Select the piper voice and model from the piper samples
- Update the
config/voice_to_speaker.yamlwith a new section for the voice, for example:
...
tts-1:
ryan:
model: voices/en_US-ryan-high.onnx
speaker: # default speaker- New models will be downloaded as needed, of you can download them in advance with
download_voices_tts-1.sh. For example:
bash download_voices_tts-1.sh en_US-ryan-highCoqui XTTS v2 voice cloning can work with as little as 6 seconds of clear audio. To create a custom voice clone, you must prepare a WAV file sample of the voice.
- Mono (single channel) 22050 Hz WAV file
- 6-30 seconds long - longer isn't always better (I've had some good results with as little as 4 seconds)
- low noise (no hiss or hum)
- No partial words, breathing, laughing, music or backgrounds sounds
- An even speaking pace with a variety of words is best, like in interviews or audiobooks.
- Audio longer than 30 seconds will be silently truncated.
You can use FFmpeg to prepare your audio files, here are some examples:
# convert a multi-channel audio file to mono, set sample rate to 22050 hz, trim to 6 seconds, and output as WAV file.
ffmpeg -i input.mp3 -ac 1 -ar 22050 -t 6 -y me.wav
# use a simple noise filter to clean up audio, and select a start time start for sampling.
ffmpeg -i input.wav -af "highpass=f=200, lowpass=f=3000" -ac 1 -ar 22050 -ss 00:13:26.2 -t 6 -y me.wav
# A more complex noise reduction setup, including volume adjustment
ffmpeg -i input.mkv -af "highpass=f=200, lowpass=f=3000, volume=5, afftdn=nf=25" -ac 1 -ar 22050 -ss 00:13:26.2 -t 6 -y me.wavOnce your WAV file is prepared, save it in the /voices/ directory and update the config/voice_to_speaker.yaml file with the new file name.
For example:
...
tts-1-hd:
me:
model: xtts
speaker: voices/me.wav # this could be youYou can also use a sub folder for multiple audio samples to combine small samples or to mix different samples together.
For example:
...
tts-1-hd:
mixed:
model: xtts
speaker: voices/mixedWhere the voices/mixed/ folder contains multiple wav files. The total audio length is still limited to 30 seconds.
Multilingual cloning support was added in version 0.11.0 and is available only with the XTTS v2 model. To use multilingual voices with piper simply download a language specific voice.
Coqui XTTSv2 has support for multiple languages: English (en), Spanish (es), French (fr), German (de), Italian (it), Portuguese (pt), Polish (pl), Turkish (tr), Russian (ru), Dutch (nl), Czech (cs), Arabic (ar), Chinese (zh-cn), Hungarian (hu), Korean (ko), Japanese (ja), and Hindi (hi). When not set, an attempt will be made to automatically detect the language, falling back to English (en).
Unfortunately the OpenAI API does not support language, but you can create your own custom speaker voice and set the language for that.
- Create the WAV file for your speaker, as in Custom Voices Howto
- Add the voice to
config/voice_to_speaker.yamland include the correct Coquilanguagecode for the speaker. For example:
xunjiang:
model: xtts
speaker: voices/xunjiang.wav
language: zh-cn- Don't remove high unicode characters in your
config/pre_process_map.yaml! If you have these lines, you will need to remove them. For example:
Remove:
- - '[\U0001F600-\U0001F64F\U0001F300-\U0001F5FF\U0001F680-\U0001F6FF\U0001F700-\U0001F77F\U0001F780-\U0001F7FF\U0001F800-\U0001F8FF\U0001F900-\U0001F9FF\U0001FA00-\U0001FA6F\U0001FA70-\U0001FAFF\U00002702-\U000027B0\U000024C2-\U0001F251]+'
- ''These lines were added to the config/pre_process_map.yaml config file by default before version 0.11.0:
- Your new multi-lingual speaker voice is ready to use!
Adding a custom xtts model is simple. Here is an example of how to add a custom fine-tuned 'halo' XTTS model.
- Save the model folder under
voices/(all 4 files are required, including the vocab.json from the model)
openedai-speech$ ls voices/halo/
config.json vocab.json model.pth sample.wav
- Add the custom voice entry under the
tts-1-hdsection ofconfig/voice_to_speaker.yaml:
tts-1-hd:
...
halo:
model: halo # This name is required to be unique
speaker: voices/halo/sample.wav # voice sample is required
model_path: voices/halo- The model will be loaded when you access the voice for the first time (
--preloaddoesn't work with custom models yet)
The generation of XTTSv2 voices can be fine tuned with the following options (defaults included below):
tts-1-hd:
alloy:
model: xtts
speaker: voices/alloy.wav
enable_text_splitting: True
length_penalty: 1.0
repetition_penalty: 10
speed: 1.0
temperature: 0.75
top_k: 50
top_p: 0.85For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for openedai-speech
Similar Open Source Tools
openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.

shellChatGPT
ShellChatGPT is a shell wrapper for OpenAI's ChatGPT, DALL-E, Whisper, and TTS, featuring integration with LocalAI, Ollama, Gemini, Mistral, Groq, and GitHub Models. It provides text and chat completions, vision, reasoning, and audio models, voice-in and voice-out chatting mode, text editor interface, markdown rendering support, session management, instruction prompt manager, integration with various service providers, command line completion, file picker dialogs, color scheme personalization, stdin and text file input support, and compatibility with Linux, FreeBSD, MacOS, and Termux for a responsive experience.
openai-edge-tts
This project provides a local, OpenAI-compatible text-to-speech (TTS) API using `edge-tts`. It emulates the OpenAI TTS endpoint (`/v1/audio/speech`), enabling users to generate speech from text with various voice options and playback speeds, just like the OpenAI API. `edge-tts` uses Microsoft Edge's online text-to-speech service, making it completely free. The project supports multiple audio formats, adjustable playback speed, and voice selection options, providing a flexible and customizable TTS solution for users.

agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.

yzma
yzma is a tool that allows you to write Go applications integrating llama.cpp for local inference using hardware acceleration. It supports running Vision Language Models (VLM) and Large/Small/Tiny Language Models (LLM) on Linux, macOS, or Windows with hardware acceleration like CUDA, Metal, or Vulkan. yzma uses purego and ffi packages, eliminating the need for CGo. It works with the latest llama.cpp releases, enabling users to leverage the newest features and model support.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.
aidermacs
Aidermacs is an AI pair programming tool for Emacs that integrates Aider, a powerful open-source AI pair programming tool. It provides top performance on the SWE Bench, support for multi-file edits, real-time file synchronization, and broad language support. Aidermacs delivers an Emacs-centric experience with features like intelligent model selection, flexible terminal backend support, smarter syntax highlighting, enhanced file management, and streamlined transient menus. It thrives on community involvement, encouraging contributions, issue reporting, idea sharing, and documentation improvement.
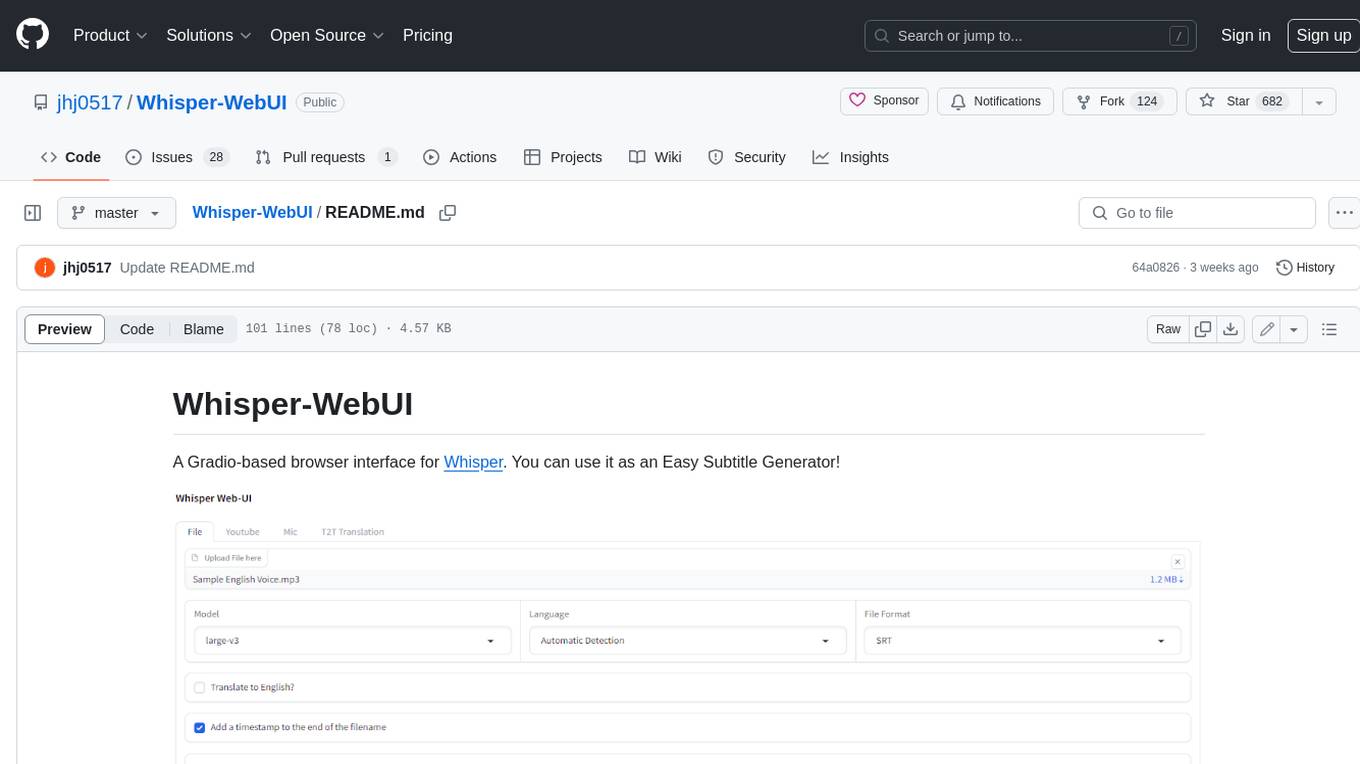
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.

react-native-fast-tflite
A high-performance TensorFlow Lite library for React Native that utilizes JSI for power, zero-copy ArrayBuffers for efficiency, and low-level C/C++ TensorFlow Lite core API for direct memory access. It supports swapping out TensorFlow Models at runtime and GPU-accelerated delegates like CoreML/Metal/OpenGL. Easy VisionCamera integration allows for seamless usage. Users can load TensorFlow Lite models, interpret input and output data, and utilize GPU Delegates for faster computation. The library is suitable for real-time object detection, image classification, and other machine learning tasks in React Native applications.
org-ai
org-ai is a minor mode for Emacs org-mode that provides access to generative AI models, including OpenAI API (ChatGPT, DALL-E, other text models) and Stable Diffusion. Users can use ChatGPT to generate text, have speech input and output interactions with AI, generate images and image variations using Stable Diffusion or DALL-E, and use various commands outside org-mode for prompting using selected text or multiple files. The tool supports syntax highlighting in AI blocks, auto-fill paragraphs on insertion, and offers block options for ChatGPT, DALL-E, and other text models. Users can also generate image variations, use global commands, and benefit from Noweb support for named source blocks.

r2ai
r2ai is a tool designed to run a language model locally without internet access. It can be used to entertain users or assist in answering questions related to radare2 or reverse engineering. The tool allows users to prompt the language model, index large codebases, slurp file contents, embed the output of an r2 command, define different system-level assistant roles, set environment variables, and more. It is accessible as an r2lang-python plugin and can be scripted from various languages. Users can use different models, adjust query templates dynamically, load multiple models, and make them communicate with each other.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
podscript
Podscript is a tool designed to generate transcripts for podcasts and similar audio files using Language Model Models (LLMs) and Speech-to-Text (STT) APIs. It provides a command-line interface (CLI) for transcribing audio from various sources, including YouTube videos and audio files, using different speech-to-text services like Deepgram, Assembly AI, and Groq. Additionally, Podscript offers a web-based user interface for convenience. Users can configure keys for supported services, transcribe audio, and customize the transcription models. The tool aims to simplify the process of creating accurate transcripts for audio content.
For similar tasks
openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.

izwi
Izwi is a local-first audio inference engine for text-to-speech (TTS), automatic speech recognition (ASR), and voice AI workflows. It operates on your machine without relying on cloud services or API keys, ensuring data privacy. Izwi offers core capabilities such as real-time voice conversations with AI, generating natural speech from text, converting audio to text accurately, identifying multiple speakers, voice cloning, creating custom voices, word-level audio-text alignment, and text-based AI conversations. The server provides OpenAI-compatible API routes under `/v1`.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.
MeloTTS
MeloTTS is a high-quality multi-lingual text-to-speech library by MyShell.ai. It supports various languages including English (American, British, Indian, Australian), Spanish, French, Chinese, Japanese, and Korean. The Chinese speaker also supports mixed Chinese and English. The library is fast enough for CPU real-time inference and offers features like using without installation, local installation, and training on custom datasets. The Python API and model cards are available in the repository and on HuggingFace. The community can join the Discord channel for discussions and collaboration opportunities. Contributions are welcome, and the library is under the MIT License. MeloTTS is based on TTS, VITS, VITS2, and Bert-VITS2.

call-gpt
Call GPT is a voice application that utilizes Deepgram for Speech to Text, elevenlabs for Text to Speech, and OpenAI for GPT prompt completion. It allows users to chat with ChatGPT on the phone, providing better transcription, understanding, and speaking capabilities than traditional IVR systems. The app returns responses with low latency, allows user interruptions, maintains chat history, and enables GPT to call external tools. It coordinates data flow between Deepgram, OpenAI, ElevenLabs, and Twilio Media Streams, enhancing voice interactions.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
cgft-llm
The cgft-llm repository is a collection of video tutorials and documentation for implementing large models. It provides guidance on topics such as fine-tuning llama3 with llama-factory, lightweight deployment and quantization using llama.cpp, speech generation with ChatTTS, introduction to Ollama for large model deployment, deployment tools for vllm and paged attention, and implementing RAG with llama-index. Users can find detailed code documentation and video tutorials for each project in the repository.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.