
bootcamp_machine-learning
Bootcamp to learn the basics for Machine Learning
Stars: 212
Bootcamp Machine Learning is a one-week program designed by 42 AI to teach the basics of Machine Learning. The curriculum covers topics such as linear algebra, statistics, regression, classification, and regularization. Participants will learn concepts like gradient descent, hypothesis modeling, overfitting detection, logistic regression, and more. The bootcamp is ideal for individuals with prior knowledge of Python who are interested in diving into the field of artificial intelligence.
README:
![]()
This project is a Machine Learning bootcamp created by 42 AI.
As notions seen during this bootcamp can be complex, we very strongly advise students to have previously done the following bootcamp:
42 Artificial Intelligence is a student organization of the Paris campus of the school 42. Our purpose is to foster discussion, learning, and interest in the field of artificial intelligence, by organizing various activities such as lectures and workshops.
The pdf files of each module can be downloaded from our realease page: https://github.com/42-AI/bootcamp_machine-learning/releases
Get started with some linear algebra and statistics
Sum, mean, variance, standard deviation, vectors and matrices operations.
Hypothesis, model, regression, loss function.
Implement a method to improve your model's performance: gradient descent, and discover the notion of normalization
Gradient descent, linear regression, normalization.
Extend the linear regression to handle more than one features, build polynomial models and detect overfitting
Multivariate linear hypothesis, multivariate linear gradient descent, polynomial models.
Training and test sets, overfitting.
Discover your first classification algorithm: logistic regression!
Logistic hypothesis, logistic gradient descent, logistic regression, multiclass classification.
Accuracy, precision, recall, F1-score, confusion matrix.
Fight overfitting!
Regularization, overfitting. Regularized loss function, regularized gradient descent.
Regularized linear regression. Regularized logistic regression.
- Amric Trudel ([email protected])
- Maxime Choulika ([email protected])
- Pierre Peigné ([email protected])
- Matthieu David ([email protected])
- Benjamin Carlier ([email protected])
- Pablo Clement ([email protected])
- Amir Mahla ([email protected])
- Mathieu Perez ([email protected])
- Richard Blanc ([email protected])
- Solveig Gaydon Ohl ([email protected])
- Quentin Feuillade--Montixi ([email protected])
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for bootcamp_machine-learning
Similar Open Source Tools
bootcamp_machine-learning
Bootcamp Machine Learning is a one-week program designed by 42 AI to teach the basics of Machine Learning. The curriculum covers topics such as linear algebra, statistics, regression, classification, and regularization. Participants will learn concepts like gradient descent, hypothesis modeling, overfitting detection, logistic regression, and more. The bootcamp is ideal for individuals with prior knowledge of Python who are interested in diving into the field of artificial intelligence.
AI6127
AI6127 is a course focusing on deep neural networks for natural language processing (NLP). It covers core NLP tasks and machine learning models, emphasizing deep learning methods using libraries like Pytorch. The course aims to teach students state-of-the-art techniques for practical NLP problems, including writing, debugging, and training deep neural models. It also explores advancements in NLP such as Transformers and ChatGPT.
ai_all_resources
This repository is a compilation of excellent ML and DL tutorials created by various individuals and organizations. It covers a wide range of topics, including machine learning fundamentals, deep learning, computer vision, natural language processing, reinforcement learning, and more. The resources are organized into categories, making it easy to find the information you need. Whether you're a beginner or an experienced practitioner, you're sure to find something valuable in this repository.
RAGEN
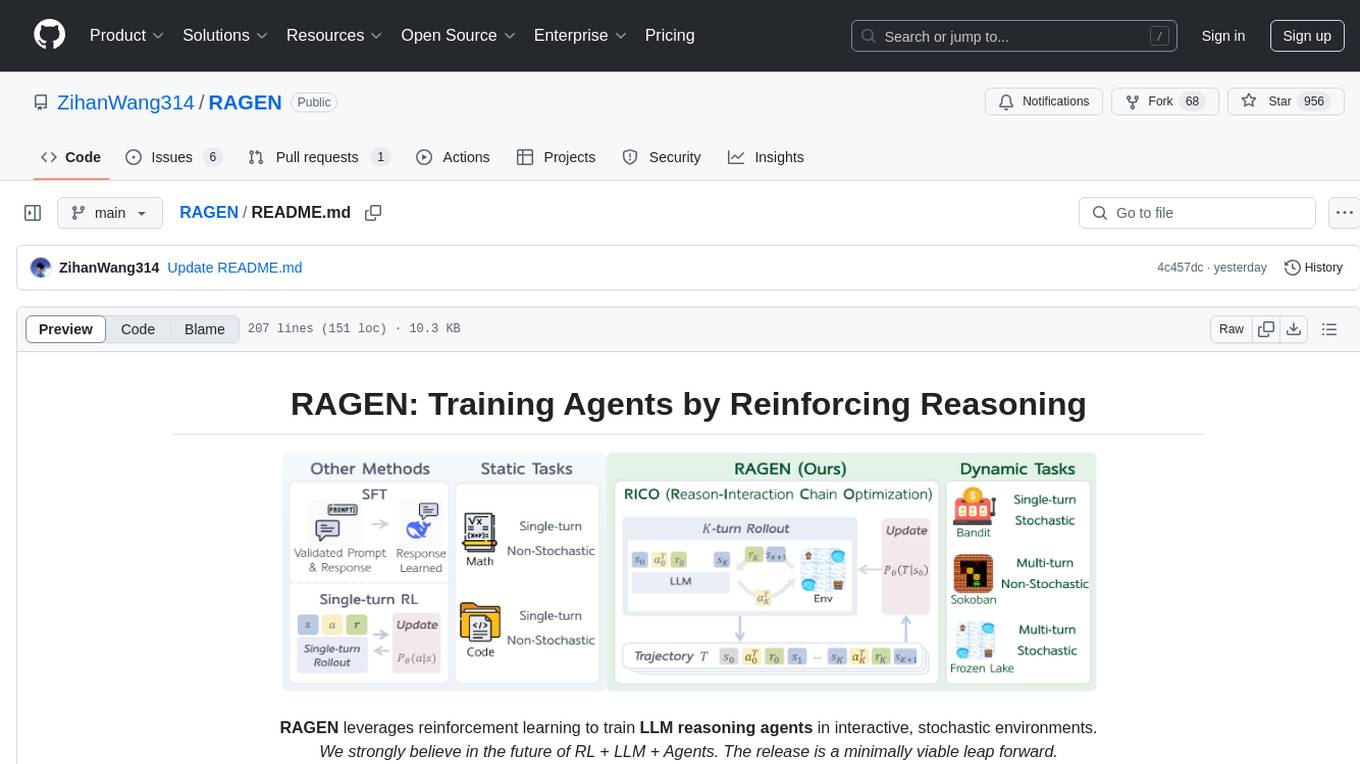
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.
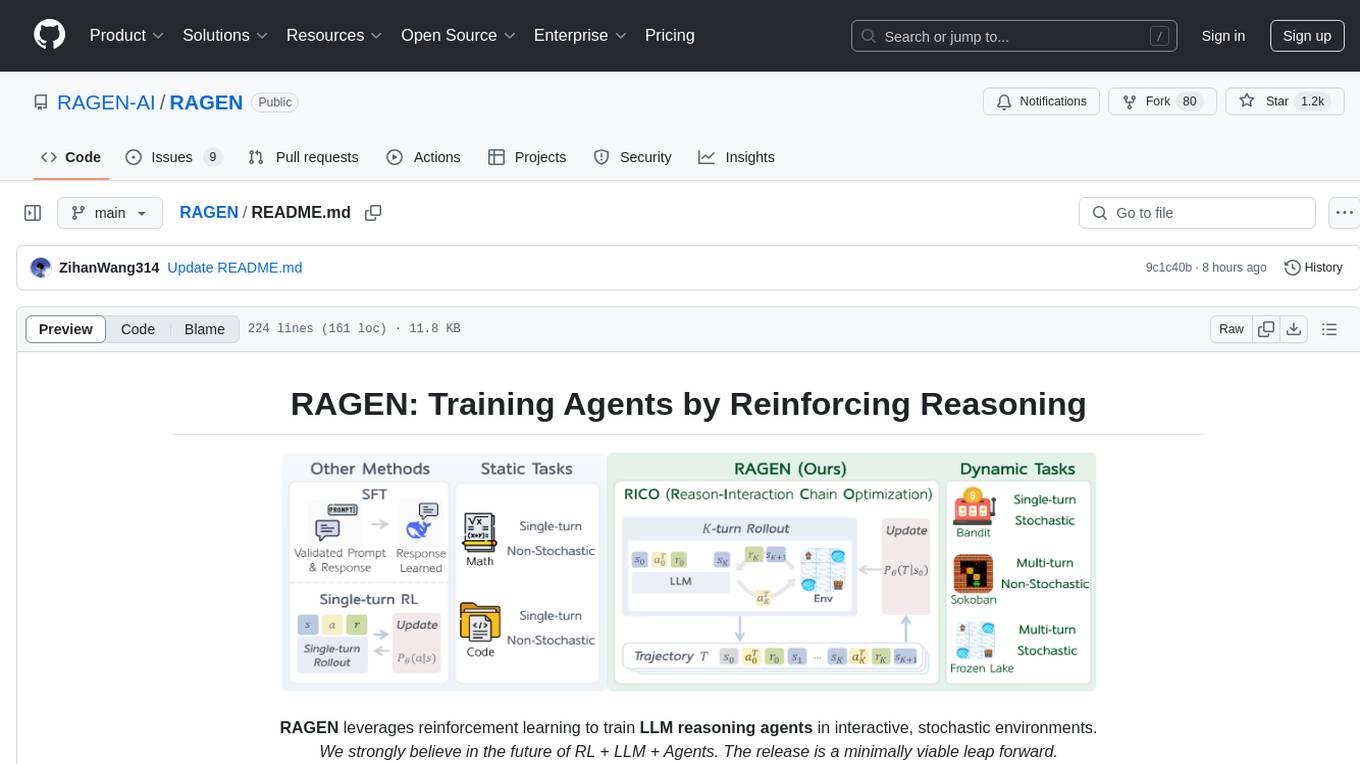
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework consists of MDP formulation, RICO algorithm with rollout and update stages, and reward normalization strategies to stabilize training. RAGEN aims to optimize reasoning and action strategies for LLM agents operating in complex environments.
awesome-hallucination-detection
This repository provides a curated list of papers, datasets, and resources related to the detection and mitigation of hallucinations in large language models (LLMs). Hallucinations refer to the generation of factually incorrect or nonsensical text by LLMs, which can be a significant challenge for their use in real-world applications. The resources in this repository aim to help researchers and practitioners better understand and address this issue.
llm_benchmark
The 'llm_benchmark' repository is a personal evaluation project that tracks and tests various large models in areas such as logic, mathematics, programming, and human intuition. The evaluation consists of a private question bank with around 30 questions and 240 test cases, updated monthly. The scoring method involves assigning points based on correct deductions and meeting specific requirements, with scores normalized to a scale of 10. The repository aims to observe the long-term evolution trends of different large models from a subjective perspective, providing insights and a testing approach for individuals to assess large models.
interpret
InterpretML is an open-source package that incorporates state-of-the-art machine learning interpretability techniques under one roof. With this package, you can train interpretable glassbox models and explain blackbox systems. InterpretML helps you understand your model's global behavior, or understand the reasons behind individual predictions. Interpretability is essential for: - Model debugging - Why did my model make this mistake? - Feature Engineering - How can I improve my model? - Detecting fairness issues - Does my model discriminate? - Human-AI cooperation - How can I understand and trust the model's decisions? - Regulatory compliance - Does my model satisfy legal requirements? - High-risk applications - Healthcare, finance, judicial, ...

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.
AI2BMD
AI2BMD is a program for efficiently simulating protein molecular dynamics with ab initio accuracy. The repository contains datasets, simulation programs, and public materials related to AI2BMD. It provides a Docker image for easy deployment and a standalone launcher program. Users can run simulations by downloading the launcher script and specifying simulation parameters. The repository also includes ready-to-use protein structures for testing. AI2BMD is designed for x86-64 GNU/Linux systems with recommended hardware specifications. The related research includes model architectures like ViSNet, Geoformer, and fine-grained force metrics for MLFF. Citation information and contact details for the AI2BMD Team are provided.

MathCoder
MathCoder is a repository focused on enhancing mathematical reasoning by fine-tuning open-source language models to use code for modeling and deriving math equations. It introduces MathCodeInstruct dataset with solutions interleaving natural language, code, and execution results. The repository provides MathCoder models capable of generating code-based solutions for challenging math problems, achieving state-of-the-art scores on MATH and GSM8K datasets. It offers tools for model deployment, inference, and evaluation, along with a citation for referencing the work.
GOLEM
GOLEM is an open-source AI framework focused on optimization and learning of structured graph-based models using meta-heuristic methods. It emphasizes the potential of meta-heuristics in complex problem spaces where gradient-based methods are not suitable, and the importance of structured models in various problem domains. The framework offers features like structured model optimization, metaheuristic methods, multi-objective optimization, constrained optimization, extensibility, interpretability, and reproducibility. It can be applied to optimization problems represented as directed graphs with defined fitness functions. GOLEM has applications in areas like AutoML, Bayesian network structure search, differential equation discovery, geometric design, and neural architecture search. The project structure includes packages for core functionalities, adapters, graph representation, optimizers, genetic algorithms, utilities, serialization, visualization, examples, and testing. Contributions are welcome, and the project is supported by ITMO University's Research Center Strong Artificial Intelligence in Industry.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.
AlphaFold3
AlphaFold3 is an implementation of the Alpha Fold 3 model in PyTorch for accurate structure prediction of biomolecular interactions. It includes modules for genetic diffusion and full model examples for forward pass computations. The tool allows users to generate random pair and single representations, operate on atomic coordinates, and perform structure predictions based on input tensors. The implementation also provides functionalities for training and evaluating the model.
rlhf_thinking_model
This repository is a collection of research notes and resources focusing on training large language models (LLMs) and Reinforcement Learning from Human Feedback (RLHF). It includes methodologies, techniques, and state-of-the-art approaches for optimizing preferences and model alignment in LLM training. The purpose is to serve as a reference for researchers and engineers interested in reinforcement learning, large language models, model alignment, and alternative RL-based methods.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.